ASP动态网页
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
网页类型
静态网页
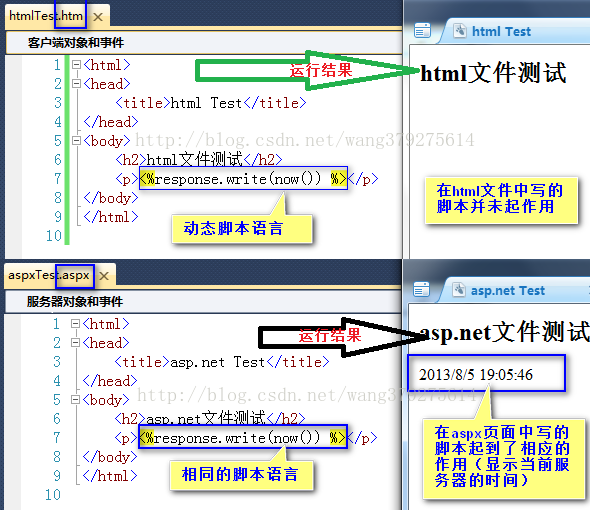
**前面我们所爬取的网页都是使用 HTML 超文本标记语言开发、设计的后缀为 .htm、.html 的静态网页。它可以包含文本、图像、声音、客户端脚本和 ActiveX 控件及 JAVA 小程序等,但不能自行处理数据,没有后台数据库且不含程序和不可交互,因此静态网页更新起来相对比较麻烦,适用于一般更新较少的展示型网站。**但不要误解成静态网页只能展示静态内容,它也可以展示各种动态的效果,如 GIF 格式的动画、Flash 动画、滚动字幕等。这类网页也是网站建设的基础,早期的网站一般都是由静态网页制作的。
动态网页
有静态网页自然就有动态网页,即后缀为 ASP(Active Server Pages)的动态服务器页面,这类网页能自行接收、处理数据,并给客户端回复数据,主要用于创建和运行动态的交互式Web服务器应用程序。
类型区别
- 更新方式:
.html静态页面不具备连接数据库功能,每次更新就是更改整个页面或通过 Ajax 请求更新部分页面;.asp动态网页可以连接数据库,更新网站内容只需要在后台增删内容就可以了。 - 文件后缀:
.html与.htm均是静态网页文件后缀名,唯一的区别就是文件后缀的长度,它们实际上代表相同的类型,即 HTML(Hypertext Markup Language)文件;.asp与.aspx均是动态网页文件后缀名,其中.aspx编写效率更高,安全性也更高。 - 代码兼容:
.html的文件改成.asp的后缀没有任何影响,因为asp动态语言允许插入html代码,反过来完全不行。
网页请求
**ASP 是动态网页,在一个网站中从一个动态网页访问到另一个动态网页时,需要保持控件的状态,即保持更新控件的 __ViewState 参数、__EventValidation 参数,来达到正常访问的目的。**具体访问流程如下:
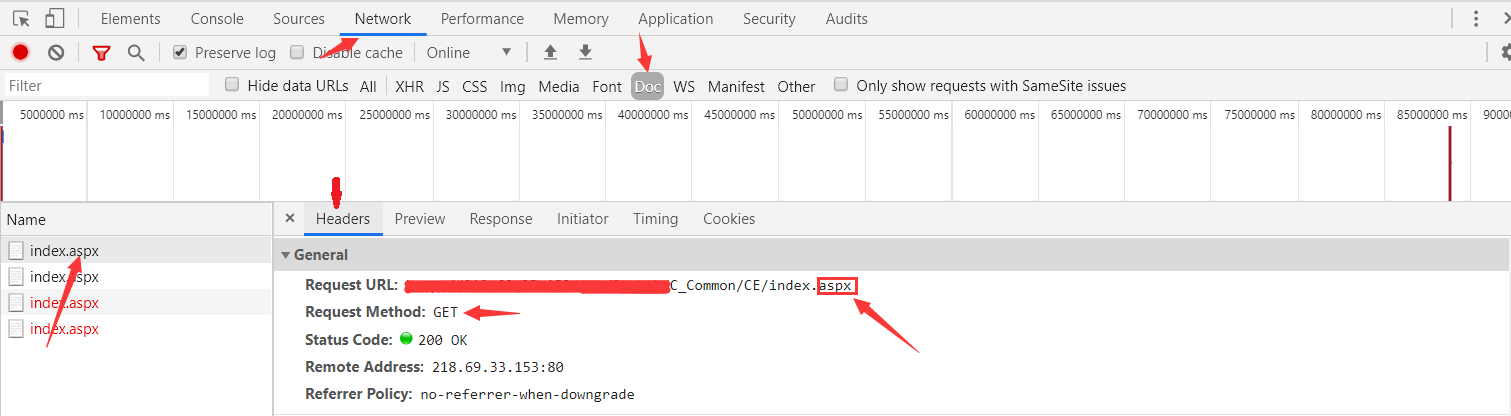
- 先 GET 请求动态页面的网址(一般是网站的首页或者网站板块的第一页):
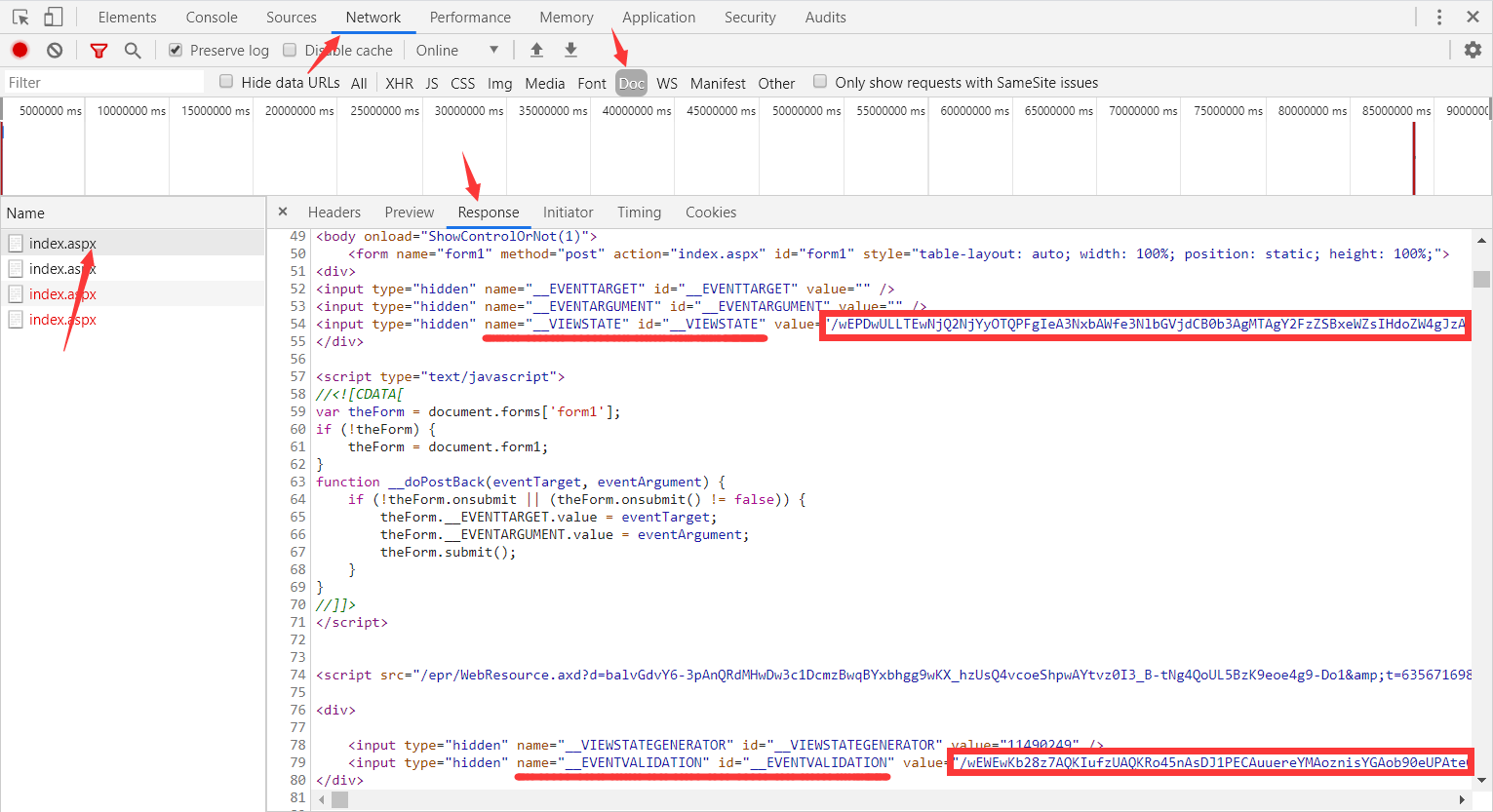
- 在网页代码中获取
__EventValidation参数的value值、__ViewState参数的value值:
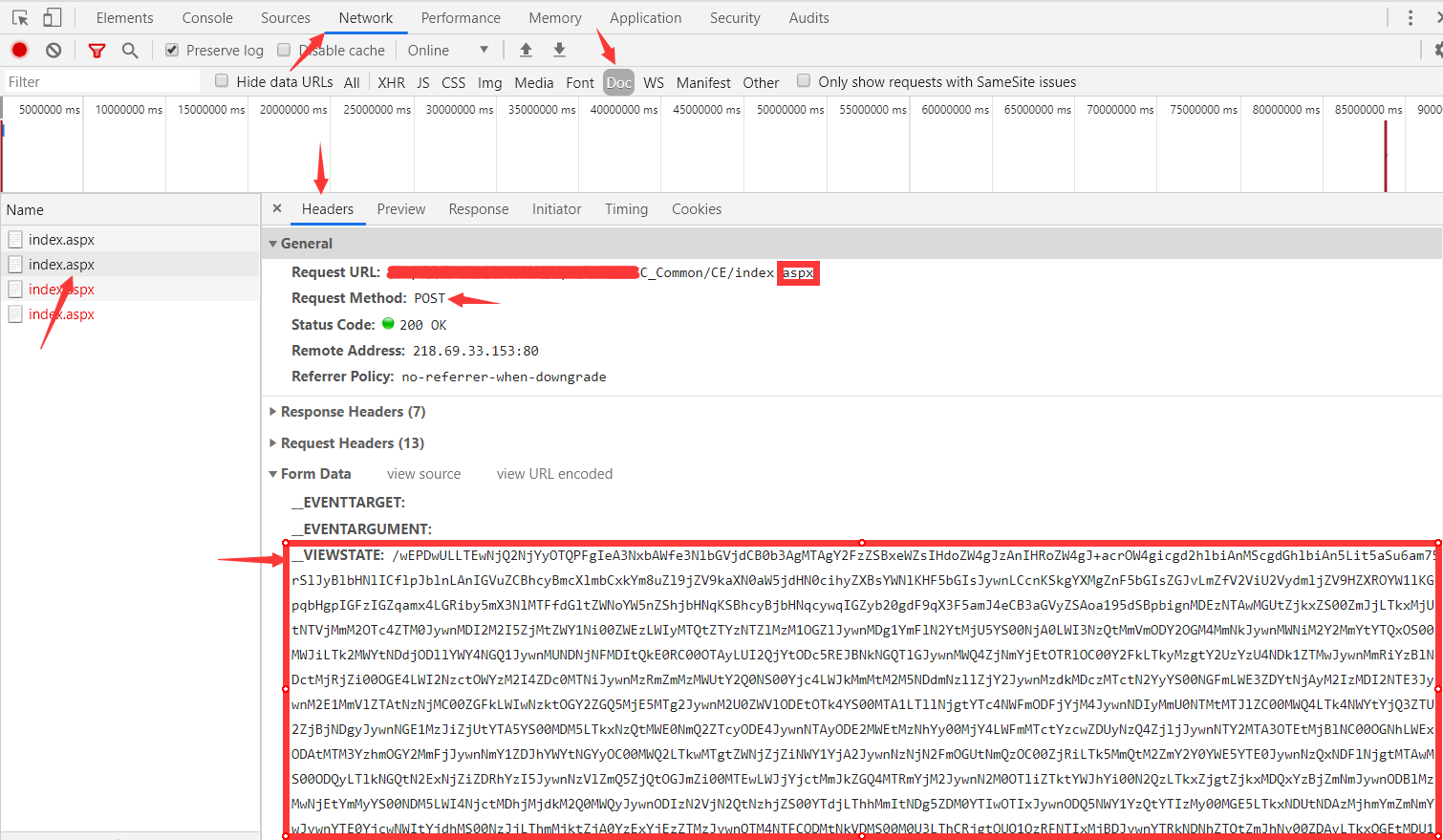
- 带上获取的两个
value值,再 POST 请求下一个动态页面网址:
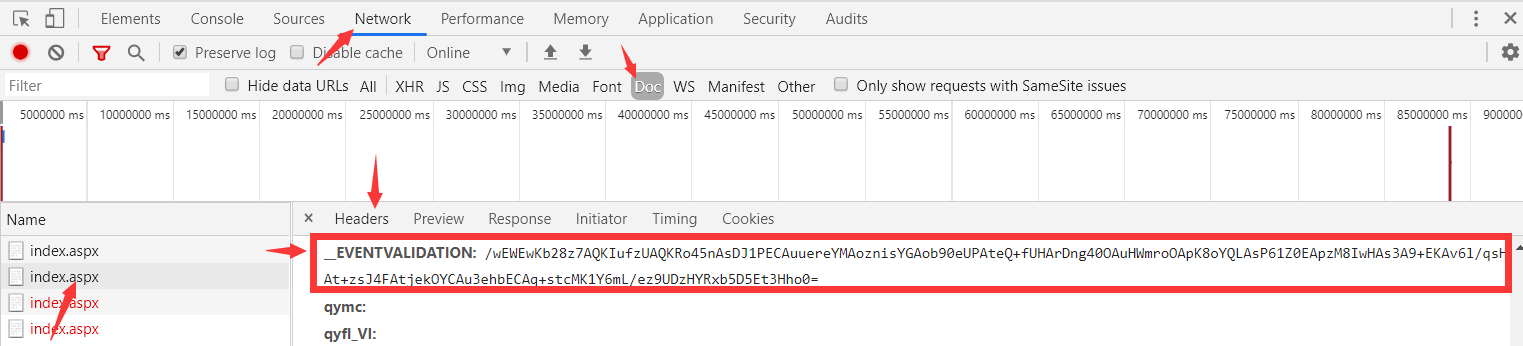
- 重复上面的步骤,即可不断向后翻页,直到访问所有页面。
网页爬虫
python
import re
import requests
# 请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'}
# 地址
url = '...asp'
# 获取第一页响应
response1 = requests.get(url=url, headers=headers)
# 除去空格
Match = re.sub(r'\s*', '', response1.text)
# 获取网页代码中ViewState的value值
ViewState = re.findall(r'(?<=<inputtype="hidden"name="__VIEWSTATE"id="__VIEWSTATE"value=").*?(?=")|(?<=__VIEWSTATE\|).*?(?=\|)|(?<=<inputtype="hidden"name="__VIEWSTATE"value=").*?(?=")', Match)[0]
# 获取网页代码中EventValidation的value值
EventValidation = re.findall(r'(?<=<inputtype="hidden"name="__EVENTVALIDATION"id="__EVENTVALIDATION"value=").*?(?=")|(?<=__EVENTVALIDATION\|).*?(?=\|)', Match)[0]
# 构造表单
data = {
'...':'...',
'__VIEWSTATE':ViewState,
'__EVENTVALIDATION':EventValidation
}
# post请求发送表单进行验证
response2 = requests.post(url=url, headers=headers, data=data)
# 输出下一页的内容
print(response2.text)