Softmax回归
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
Softmax 回归是机器学习一个非常经典的模型,虽然它的名字中带有回归,但它其实是一个分类问题。
Softmax简介
在解决多分类问题时,我们可以只构建一个 Softmax 回归模型,同时对所有类别进行识别。
模型特点
**Softmax 回归模型的优势在于模型的简洁和高效,我们只需要一次训练,就可以得到同时识别所有类别的多分类模型。另外,Softmax 回归也可以很好的处理类别间的互斥问题,Softmax 函数可以确保预测结果的总和为 1,这在某些使用类别互斥的场景下,非常有用。**不过使用 Softmax 回归也存在着一些问题,例如在需要优化模型中的某个类别时,或者增加新的类别时,会影响到其他所有类别,这样就会产生较高的评估与维护成本。
回归步骤
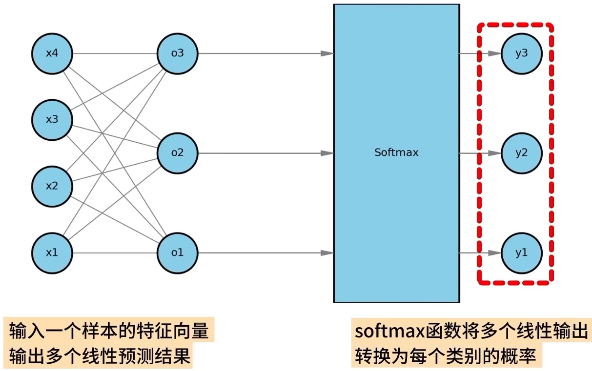
在 Softmax 回归中包括了两个步骤:
- 输入一个样本的特征向量,输出多个线性预测结果;
- Softmax 函数将多个线性输出转换为每个类别的概率;
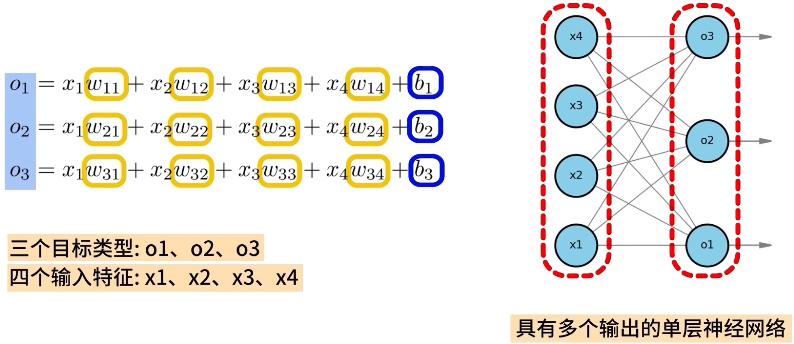
例如,在某多分类问题中,有三个目标类别 o1、o2、o3,有四个输入特征 x1、x2、x3、x4,Softmax 回归会基于输入 x,计算 o1、o2、o3 三个线性输出,在计算每一个线性输出 o 时,都会依赖一组 w 和 b 参数,我们可以将 Softmax 回归看做是一个具有多个输出的单层神经网络。
计算出线性输出 o1、o2、o3 后,将其输入到 Softmax 函数转换为对每个类别的预测概率 y1、y2、y3,这些概率都是 0 到 1 之间的实数,并且这些实数之和结果恰好为 1。
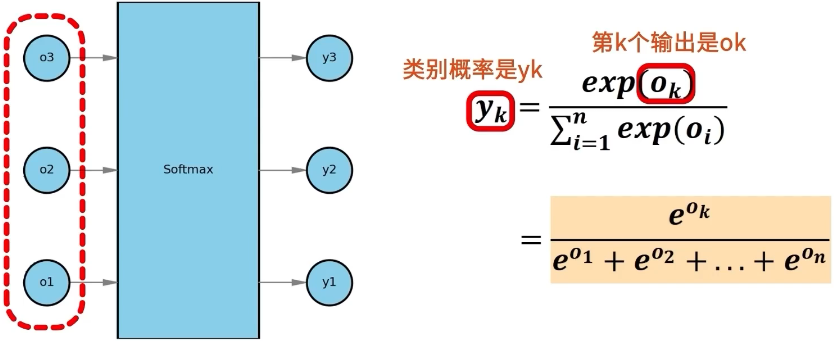
预测概率 y1、y2、y3 之间是可以相互比较的,y 值越大的类别对应的概率越高,因此最后输出的预测类别就是 y 值最大的类别。

提醒
Softmax 函数不会改变线性输出 o 之间的大小顺序,只会为每个类别分配相应的概率。
两者区别
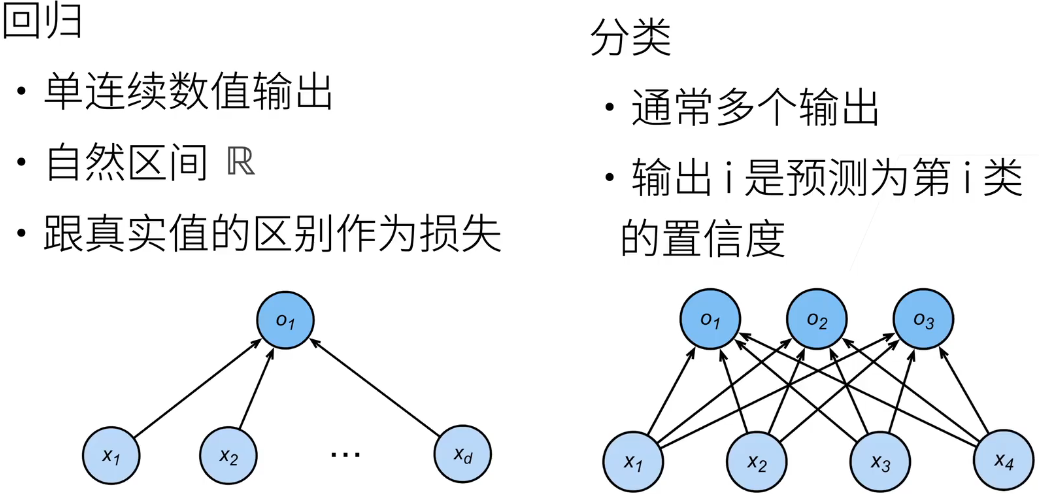
回归和分类的区别在于:
- 回归估计一个连续值,也就是说通过模型估计一个值,例如估计一个房子的房价;
- 分类预测一个离散类别,也就是说通过模型判断一个类别,例如判断图片中数字是多少;
进行过渡
从回归过渡到分类,有以下步骤:
- 既然要区分类别,就说明类别肯定是有多个的,因此我们要对类别进行编码,假设我们有 n 个类别,我们可以用一位有效编码对类别进行编码;
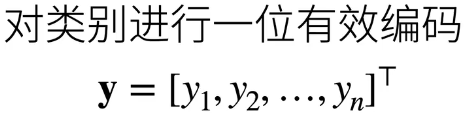
- 假设类别中的第 个就是真实类别,那么 其他的元素全部等于 0,就是说我们的向量当中只有一个元素为 1,这个元素的下标对应的是第 个类别,其他的全部为 0;
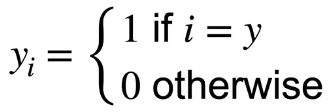
- 假设我们训练出来了一个模型,进行预测的时候,就是选取 使得最大化 置信度值作为模型的预测;

- 在分类问题中,我们关心的重点不是它们的值,而是相对值,即对于正确类的置信度是不是特别大,能否与其他类别的置信度拉开差距。简单讲,就是设定一个阈值,正确类的置信度减去其他类别的置信度必须要大于等于阈值,这样就能保证模型能够将正确类和其他类拉开距离。

- 现在我们的输出是 到 的一个 向量,那我们希望输出是一个概率,就可以引入一个 新的操作子,将其作用在 向量上面,得到一个长度为 的 向量,里面的每个元素都大于 0,而且它们的和为1,可以说 就是一个预测概率,回顾前面我们对真实标号的 也是一个概率,只有一个元素为 1,其他的全部为 0;

- 现在我们就可以使用 预测概率和 真实概率之间的区别作为损失,一般使用交叉熵用来衡量两个概率的区别;

总结归纳

分类数据集
MNIST手写
MNIST 手写数据集来自美国国家标准与计算机研究所,是由 250 个不同的人手写数字构成的,其中的人员构成 50% 是美国的高中学生,剩下 50% 是美国人口普查局的工作人员。该数据集常用来识别图片里面的数字,由于数字总共就 10 个,因此它就是一个 10 类问题。

ImageNet物体
ImageNet 自然物体分类也是一个非常经典的数据集,该数据集包含 100 万张图片,每张图片里面是一个物体,物体总共分为 1000 个类别,因此这个就是一个 1000 类的分类问题。

回归项目实现
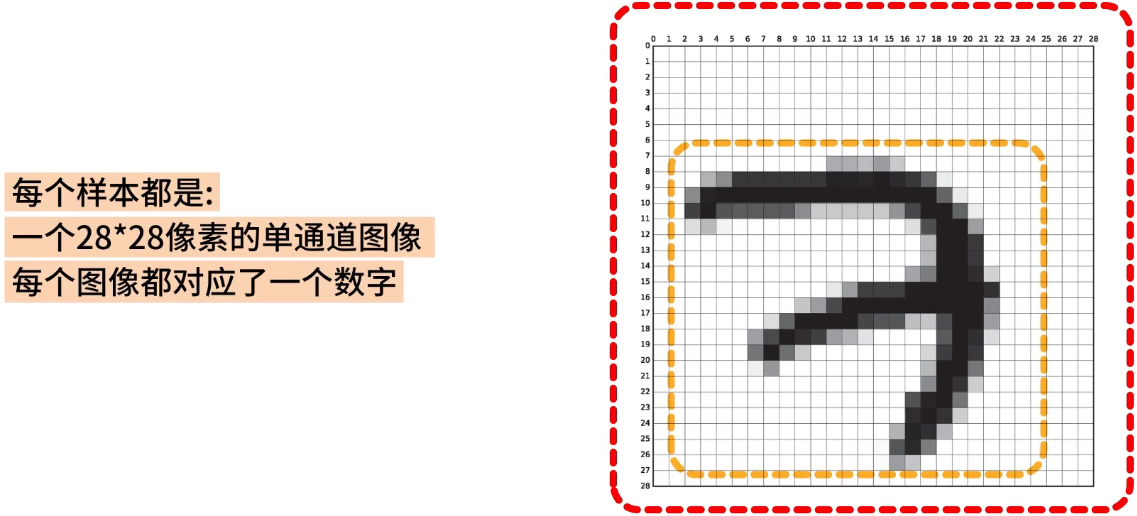
我们选择使用 MNIST 手写数据集来实现 Softmax 回归,它是一个公开的数据集,里面的每个样本都是一个 28 x 28 像素的单通道图像,每个图像都对应了一个数字。
下载数据
官方文档 https://pytorch.org/vision/stable/datasets.html
在 PyTorch 中,有一个集成的 API 可以获取 MNIST 数据集。参数如下:

root指定下载的目录;train指定读取的是训练集还是测试集;download = True当指定下载的目录没有文件时,会下载数据集;transform对图片进行预处理操作(提高效率);target_transform对图片进行预处理的目标;
python
# torchvision是pytorch对于计算机视觉模型实现的一个库
# 从datasets数据集中导入MNIST
from torchvision.datasets import MNIST
# root下载路径,download=True确定下载
mnist_down = MNIST(root='./MNIST_data', download=True)运行代码,文件栏会多出一个 MNIST_data 文件夹,里面就是数据集的四部分文件:
t10k-images-idx3-ubyte.gz测试集使用的图片;t10k-labels-idx1-ubyte.gz测试集使用的标签;train-images-idx3-ubyte.gz训练集使用的图片;train-labels-idx1-ubyte.gz训练集使用的标签;
python
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
# train=False读取测试集
mnist_test = MNIST(root='./MNIST_data', train=False)
print(len(mnist_test)) # 输出:10000。注释:测试集有10000样本。
# train=True读取训练集
mnist_train = MNIST(root='./MNIST_data', train=True)
print(len(mnist_train)) # 输出:60000。注释:训练集有60000样本。
# 获取训练集中第一个样本对象
print(mnist_train[0]) # 输出:(<PIL.Image.Image image mode=L size=28x28 at 0x1D355C2C4F0>, 5)。注释:返回一个28x28大小的PIL图像对象,标签是5。
# 将PIL图像对象展示出来(图片上展示的5,这也恰好对应了标签5)
image = mnist_train[0][0]
plt.imshow(image)
plt.show()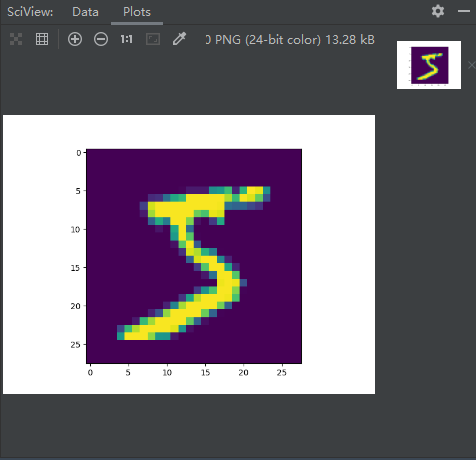
图像处理
官方文档:https://pytorch.org/vision/stable/transforms.html
**虽然我们已经得到了 MNIST 数据的实例化对象,但对象是 <class 'PIL.Image.Image'> 类型,并不是我们前面学习 tensor 张量,而且加载器只能加载 tensors、numpy arrays、numbers、dicts、lists 类型的数据。因此需要将图片转换一下,幸运的是 MNIST 为我们提供了 transform 参数用于数据处理。**代码如下:
python
from torchvision.datasets import MNIST
# 引入transforms方法
from torchvision import transforms
# 图片处理方案流
my_transforms = transforms.Compose(
[
transforms.ToTensor(), # ToTensor()将图像数据从PIL类型变换成32位浮点数的张量格式,并除以255使得所有像素的数值均在0到1之间
transforms.Normalize(mean=(0.1307, ), std=(0.3081, )) # 计算数据标准化参数可以使用官方提供的均值0.1307与标准差 0.3081,都是元组。
]
)
# 读取训练集,将图像用transforms进行处理,转化为张量。
mnist_train = MNIST(root='./MNIST_data', train=True, transform=my_transforms)警告
MNIST数据集图片包含 高度(h) X 宽度(w) X 通道(c) = 28 X 28 X 1 三个属性,经过 transforms 处理过后,会把通道移到最前边,属性变为了 c X h X w = 1 X 28 X 28 ,这样做是因为矩阵加减乘除以及卷积等运算是需要调用CUDA和 cudnn 函数,而这些接口都是设计成了 chw 格式。
数据加载
官方文档:https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
**现在得到了 MNIST 数据的实例化对象,下一步就是使用加载器对数据进行加载,这里我们使用 PyTorch 已经封装好的 DataLoader 加载器,这个在前面实现线性回归有使用到过。**详细参数介绍如下:
from torch.utils.data import DataLoader
DataLoader参数选解:
- dataset 需要加载器加载的数据集;
- batch_size 批量大小,即一次性加载数据量(整体值越大,收敛速度越慢);
- shuffle 是否打乱加载数据的顺序;
- num_workers 工作进程数(在Windows上支持并不好,默认等于0);
- pin_memory 是否需要先把数据加载到内存以便GPU进行运算;
- drop_last 假如100张图片,batch_size等于99,若开启参数,只会训练99张图片一次;若关闭参数,则会训练99张图片和剩下1张图片各一次(默认关闭);将加载 MNIST 数据集的代码如下:
python
# DataLoader数据加载器类
from torch.utils.data import DataLoader
# 将训练集放入DataLoader中,每个一个小批量是1张图片,加载顺序进行打乱
dataloader = DataLoader(dataset=mnist_train, batch_size=1, shuffle=True)
# 从DataLoader中输出一个图片对象
for image, labels in dataloader_2:
print(image, labels) # 输出:tensor([[[[0...]]]], dtype=torch.uint8) tensor([5])。注释:image图片的tensor格式数据,labels图片的标签。
print(image.shape) # 输出:torch.Size([1, 1, 28, 28])。注释:1代表batch_size每次加载的数量,1代表图片的通道数,28代表图片的高度,28代表图片的宽度。
exit()我们也可以改变批量大小,多张图片一起训练,修改代码如下:
python
# batch_size=3一次加载3张图片
dataloader = DataLoader(dataset=mnist_train, batch_size=3, shuffle=True)
for image, labels in dataloader:
print(labels) # 输出:tensor([0, 6, 7])。注释:三个标签。
# 合并三张图像的tensor格式数据,permute(1, 2, 0)还原图片通道位置,numpy()转为numpy数组
images = make_grid(image).permute(1, 2, 0).numpy()
# 将图像对象展示出来(图片上展示的067,这也恰好对应了标签067)
plt.imshow(images)
plt.show()
exit()
网络设计
官方文档:https://pytorch.org/docs/stable/nn.html
识别 MNIST 手写数据集,需要设计一个三层神经网络(双层全连接层+激活函数),因为相比两层神经网络(单一全连接层),三层神经网络在开始训练时表现更好:
- 更强大的表示学习能力: 双层全连接层提供了更多的参数和更丰富的表示学习能力。这使得模型能够更好地适应训练数据,捕捉更复杂的特征和模式。相比之下,单一全连接层的模型可能在表达能力上受到限制。
- 非线性激活函数: 加入激活函数引入了非线性变换,使得模型能够学习更复杂的映射关系。某些任务中,特别是涉及到非线性关系的情况下,使用激活函数可以提高模型的表达能力。
- 更好的特征提取: 双层全连接层可以通过多个层次的变换更好地提取数据的层次化特征。这对于复杂的任务来说是很重要的,而在简单任务上,单一全连接层可能已经足够。
- 更好的拟合能力: 双层结构可能更有能力拟合训练数据,特别是在初始阶段,这有助于更快地收敛到一个相对较低的训练误差。
- 初始化效果: 对于深层网络,适当的参数初始化很关键。如果使用了有效的初始化方法,深层网络可能更容易收敛并学到有用的表示。
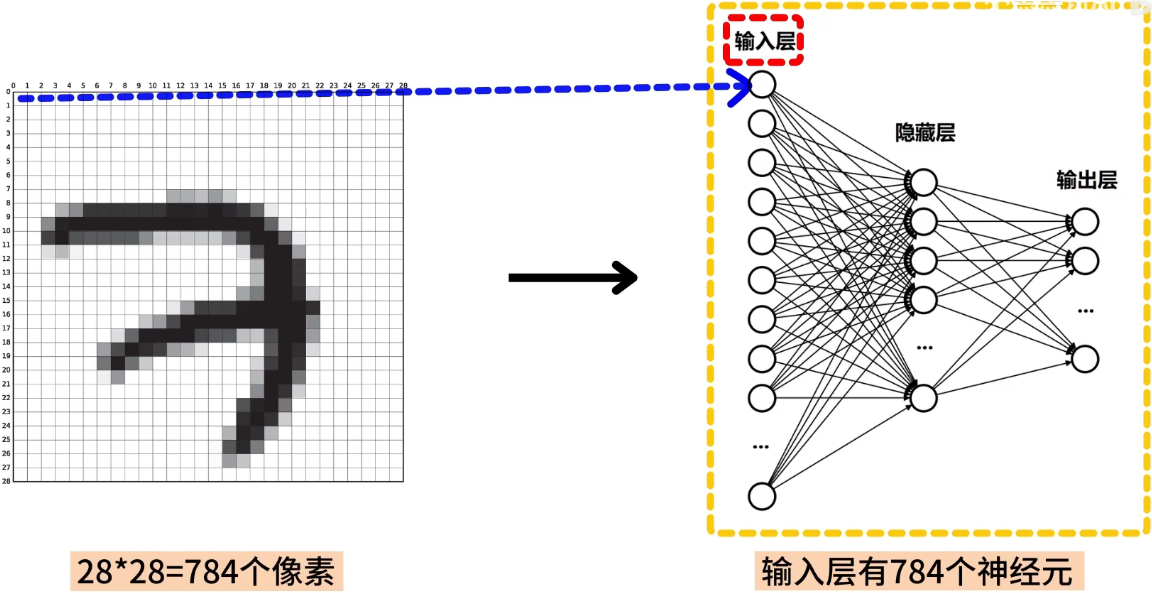
输入层
由于每个样本的大小包含 28 x 28 = 784 个像素,因此神经网络的输入层需要有 784 个神经元,每个神经元接收一个像素信息。
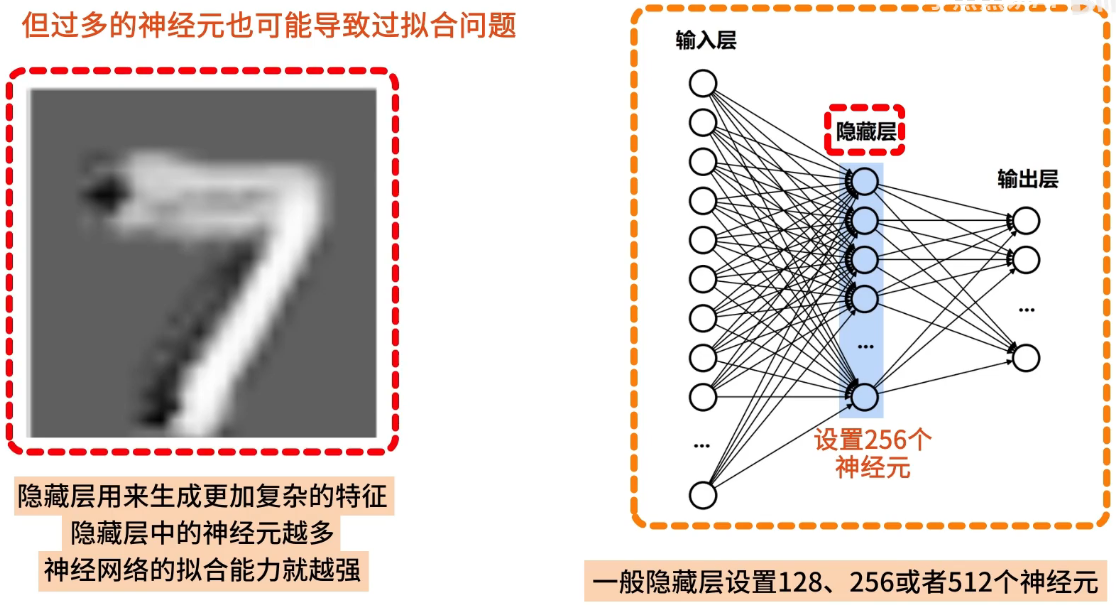
隐藏层
隐藏层用来生成更加复杂的特征,对于简单的三层神经网络,一般会在隐藏层设置 128、256 或 512 个神经元,隐藏层的神经元越多,神经网络的拟合能力就越强,但过多的神经元也可能导致过拟合问题,这里我们设置 256 个神经元,用来提取数字的高级特征。
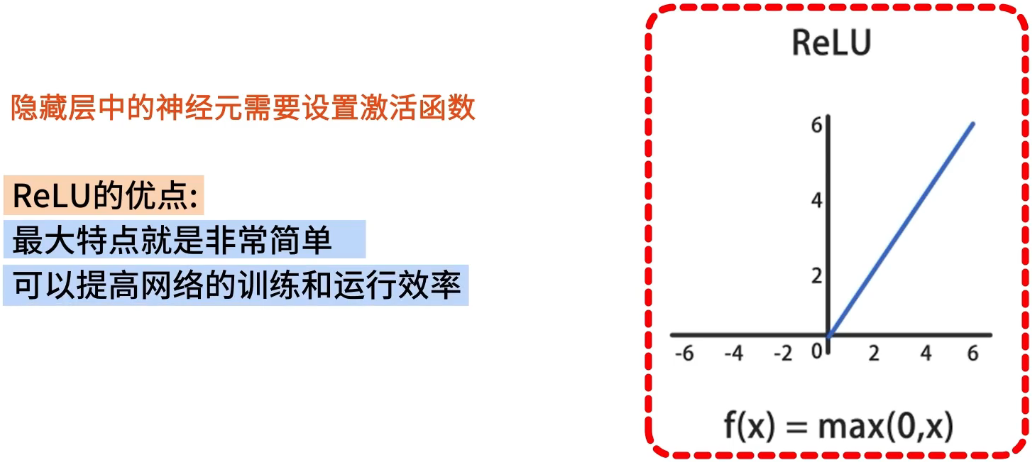
隐藏层中的神经元需要设置激活函数,我们选择使用 ReLU 函数,其最大的优点就是非常的简单,可以提高网络的训练和运行效率。
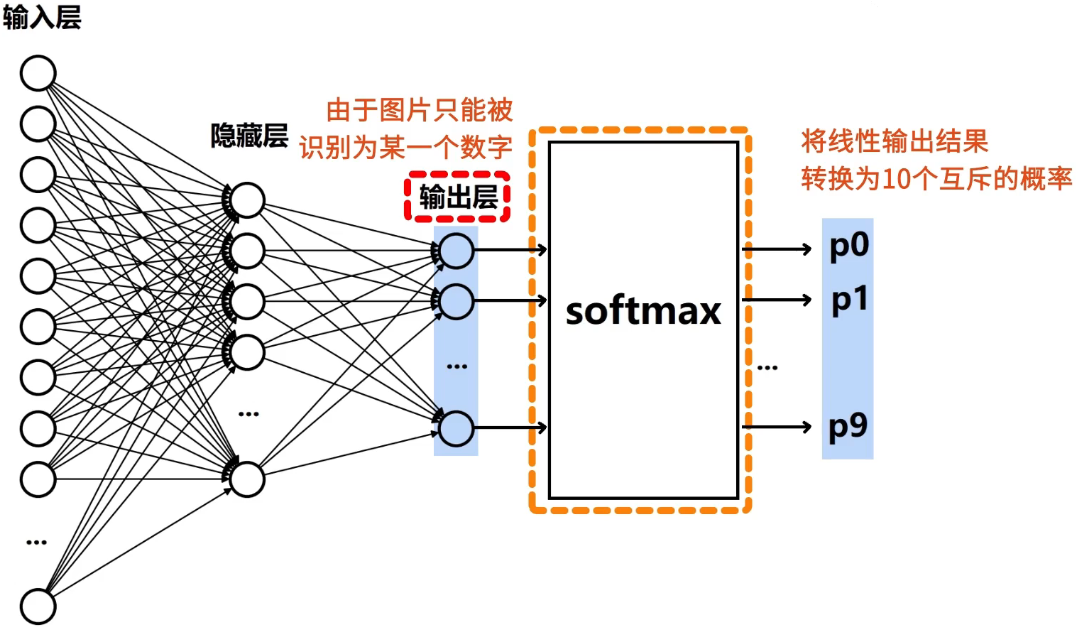
输出层
由于样本只能被识别为 0~9 这 10 个数字中的某一个数字,因此神经网络的输出层需要设置 10 个神经元,在输出层后加上 Softmax 函数,将线性输出结果转换为 10 个互斥的概率,对应 10 个不同的数字。
代码实现
python
import torch
from torch import nn
# 定义神经网络类Network,它继承nn.Module类
class Network(nn.Module):
# 神经网路中的神经元数量是固定的,所以init不用传入参数
def __init__(self):
# 调用父类的初始化函数
super().__init__()
# layer1是输入层与隐藏层之间的线性层,(28 * 28, 256)分别表示输入层、隐藏层的神经元数量。
self.layer1 = nn.Linear(28 * 28, 256)
# layer2是隐藏层与输出层之间的线性层,(256, 10)分别表示隐藏层、输出层的神经元数量。
self.layer2 = nn.Linear(256, 10)
# 实现神经网络的前向传播,函数传入输入数据x
def forward(self, x):
# 使用view函数将n*28*28的x张量,转换为n*784的张量,从而使得x可以被全连接层layer1计算
x = x.view(-1, 28 * 28)
x = self.layer1(x) # 计算layer1的结果
x = torch.relu(x) # 进行relu激活
# 计算layer2的结果,并返回
return self.layer2(x)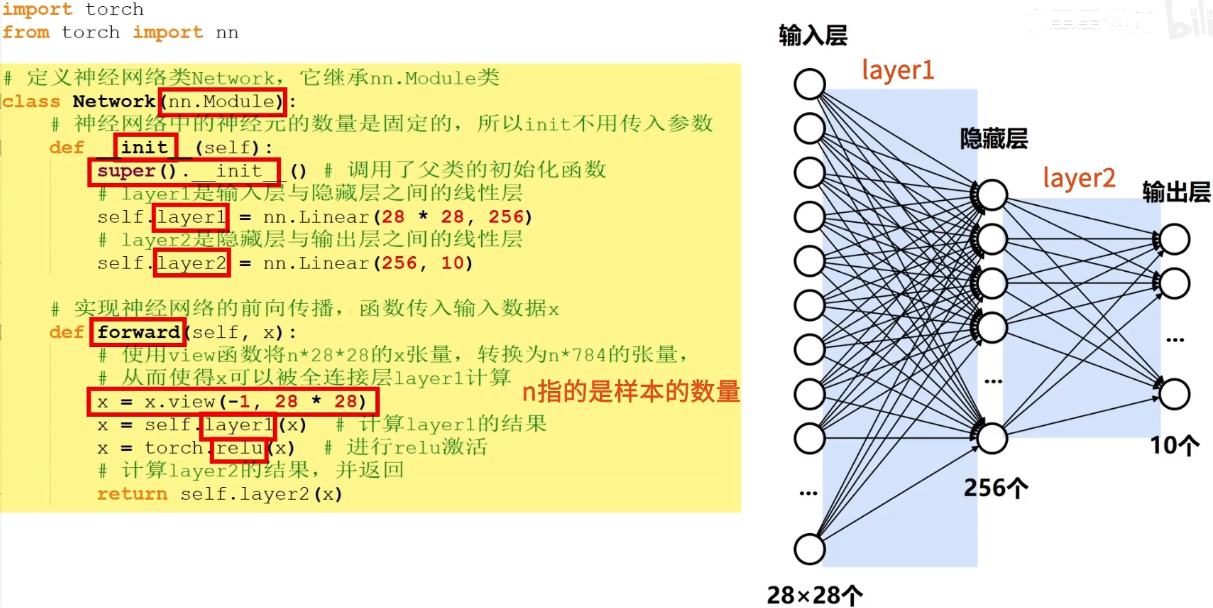
python
model = Network() # 定义一个Network模型
print(model) # 将其打印,观察打印结果可以了解模型结构从下图的输出结果中可以看到,该模型中包含 layer1 和 layer2 两个线性层,其中 layer1 有 784 个输入特征和 256 个输出特征,layer2 有 256 个输入特征和 10 个输出特征。

优化器
官方文档:https://pytorch.org/docs/stable/optim.html
python
# 引入optim优化器
from torch import optim
# 引用Network模型
model = Network()
# Adam自适应优化,lr学习率为1e-3,即10的-3次方,即0.001。
optimizer = optim.Adam(model.parameters(), lr=1e-3)损失函数
交叉熵损失函数(Cross Entropy Loss Function):评估模型输出的概率分布和真实概率分布的差异情况,一般用于解决分类问题。
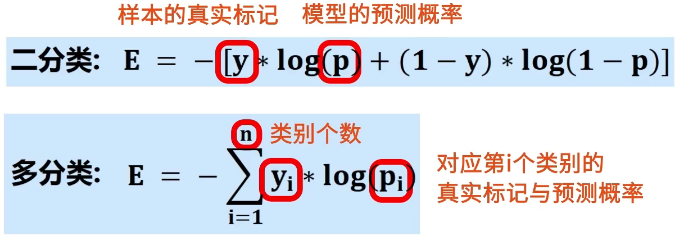
python
from torch import nn
# 交叉熵损失函数
loss_function = nn.CrossEntropyLoss()提醒
在交叉熵损失函数中,只有真实类别对应的那一项会被计算在内,其他类别的项在求和过程中均为0,所以即便模型对其他类别的预测概率不准确,但只要对真实类别的预测概率较高,损失函数的值仍然较低
训练过程
一轮训练
**新建一个名称为 MNIST 的文件夹,进入里面新建一个名称为 models 的文件夹以及一个名称为 train.py 的文件。**训练代码如下:
python
from torch.utils.data import DataLoader
from torch import nn, optim, save
from tqdm import tqdm
# 实例化模型,启用train训练模式,
model = Network()
model.train()
# 将训练集放入DataLoader中,每个一个小批量是8张图片,加载顺序进行打乱
train_loader = DataLoader(dataset=mnist_train, batch_size=8, shuffle=True)
# 将加载器包装进tqdm进度条
train_loader = tqdm(iterable=train_loader, total=len(train_loader))
# 一次训练
for images, labels in train_loader:
# 前向传播
output = model(images)
# 通过结果计算损失
loss = loss_function(output, labels)
# 梯度计算
loss.backward()
# 优化器更新参数
optimizer.step()
# 梯度置0,实质把损失和权重的导出变成0
optimizer.zero_grad()
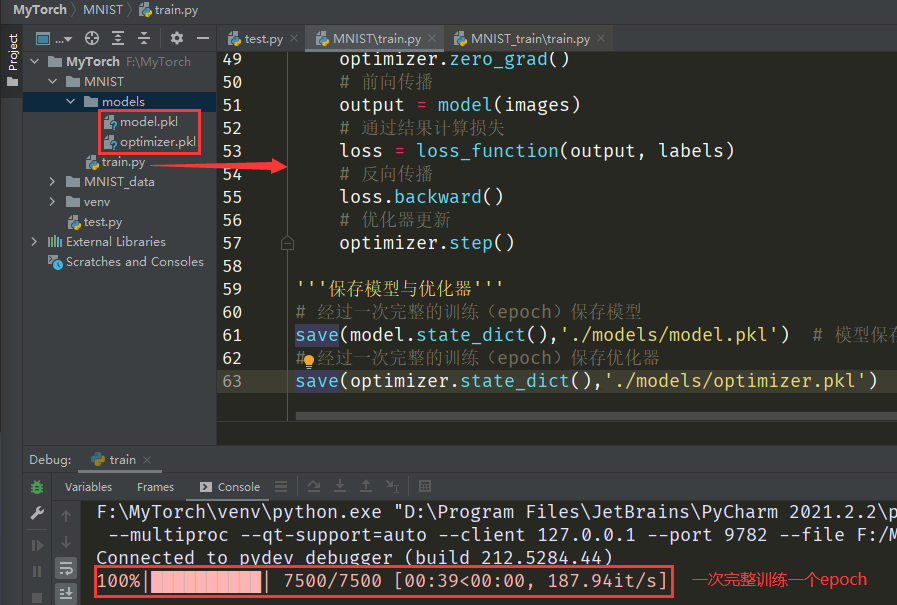
# 经过一次完整的训练(epoch)保存模型
save(model.state_dict(), './models/model.pkl')
# 经过一次完整的训练(epoch)保存优化器
save(optimizer.state_dict(), './models/optimizer.pkl')经历过一次完整的训练(epoch),在 models 文件夹下就会多出两个文件,正是我们所保存的模型与优化器。界面如下:
提醒
在深度学习中,模型有两种运行模式:训练模式和评估模式。通过调用 model.train(),你告诉模型现在处于训练模式。在训练模式下,模型会考虑使用了一些训练特定的技巧,比如启用了 Dropout(随机失活)层,这有助于防止过拟合。
模型测试
现在我们得到了一个训练模型,但我们不清楚模型的识别效果怎么样,这时训练集就起作用了。**我们在 MNIST 文件夹中新建一个名称为 test.py 的文件来测试训练的模型。**代码如下:
python
import os
import numpy as np
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn, load, no_grad
from tqdm import tqdm
# train=False改用测试集,transform和训练集一样
mnist_test = MNIST(root='../MNIST_data', train=False, transform=my_transforms)
# 导入加载器
test_loader = DataLoader(dataset=mnist_test, batch_size=8, shuffle=True)
# 加载器用tqdm进度条包装
test_loader = tqdm(iterable=test_loader, total=len(test_loader))
# 实例化模型,通过路径加载模型,启用eval评估模式
model = Network()
model.load_state_dict(load('./models/model.pkl'))
model.eval()
# 识别率列表
success = []
# 清空所管理参数的梯度,不需要计算梯度以及反向传播了。
with no_grad():
for images, labels in test_loader:
# 获取结果(10分类中每个分类的可能性)
output = model(images)
# 获取结果最小维度中可能性最大的下标
result = output.max(dim=1).indices
# 识别率(result.eq(labels)比较识别与标签是否相等,返回一组True、False结果,float()转换为浮点型,mean()计算平均值,item()获取里面的值)
rate = result.eq(labels).float().mean().item()
# 添加当前组的识别率
success.append(rate)
# 计算识别率列表的平均值
print(f'模型识别率:{np.mean(success)*100}%') # 模型识别率:91.2%提醒
在PyTorch深度学习框架中,你可以通过调用模型的 .eval() 方法将模型切换到评估模式。评估模式通常用于在模型已经训练好后进行推断、验证或测试。
多轮训练
上面我们可以看到,经过一轮的训练,模型的整体识别率已经达到了 91.2%,应该说很不错了。**但是只有一个 epoch 是不行的,我们还需要在现有模型和优化器上继续进行多个 epoch 的训练。**修改 train.py 文件内容如下:
python
'''多轮训练'''
# 因为前面已经有一个epoch了,因此这里从2开始,再训练9个epoch。
for epoch in range(2, 11):
# 加载模型,启用train训练模式
model = Network()
model.load_state_dict(load('./models/model.pkl'))
model.train()
# 加载现有优化器
optimizer = optim.Adam(model.parameters(), lr=1e-4)
optimizer.load_state_dict(load('./models/optimizer.pkl'))
# 损失列表
total_loss = []
# 遍历训练集数据加载器
for images, labels in train_loader:
# 前向传播
output = model(images)
# 通过结果计算损失
loss = loss_function(output, labels)
# 将计算的损失值添加进损失列表中
total_loss.append(loss.item())
# 梯度计算
loss.backward()
# 优化器更新参数
optimizer.step()
# 梯度置0,实质把损失和权重的导出变成0
optimizer.zero_grad()
# 模型切换为eval评估模式
model.eval()
# 识别率率列表
success = []
# 不需要计算梯度以及反向传播了
with no_grad():
# 遍历测试集数据加载器
for images, labels in test_loader:
# 获取结果
output = model(images)
# 获取结果值最大的
result = output.max(dim=1).indices
# 识别率(item获取里面的值)
rate = result.eq(labels).float().mean().item()
# 添加当前组的识别率
success.append(rate)
print(f'第{epoch}个epoch,模型识别率:{np.mean(success) * 100}%,模型损失:{np.mean(total_loss)}')
# 覆盖保存模型
save(model.state_dict(),'./models/model.pkl')
# 覆盖保存优化器
save(optimizer.state_dict(),'./models/optimizer.pkl')
'''
输出:
100%|██████████| 7500/7500 [00:50<00:00, 147.07it/s]
100%|██████████| 1250/1250 [00:05<00:00, 230.31it/s]
第8个epoch,模型识别率:93.36%,模型损失:0.37828088266067206
100%|██████████| 7500/7500 [00:48<00:00, 155.96it/s]
100%|██████████| 1250/1250 [00:05<00:00, 229.52it/s]
第9个epoch,模型识别率:95.15%,模型损失:0.1982135026258106
100%|██████████| 7500/7500 [00:46<00:00, 159.80it/s]
100%|██████████| 1250/1250 [00:05<00:00, 230.50it/s]
第10个epoch,模型识别率:96.15%,模型损失:0.14462864189787458
'''提醒
随着训练的epoch增多,模型识别率也在慢慢变高,模型损失也在慢慢降低,这也说明模型选择合适,这样训练的方法仍有提高的空间,当模型损失在一定范围内波动时我们就可以进行收敛了。假如说模型损失一直都不太理想,那么就要考虑更换模型重新训练了。
模型保存
**在训练的过程中,通常要保存两份模型,一份是效果最好的模型(Best),也是我们最终使用的模型,还有一份是最后一次训练的模型(Last),假如后期我们想继续提高模型精度,直接就可以在最后训练的模型基础上继续训练。**修改代码如下:
python
# 定义全局变量识别为0和损失为1
rate_value, loss_value = 0, 1
# 每经过一次完整的训练(epoch)就保存最后的模型与优化器
save(model.state_dict(),'./models/last_model.pkl')
save(optimizer.state_dict(),'./models/last_optimizer.pkl')
# 如果模型识别率越来越高和模型损失越来越小就保存最好的模型与优化器
if np.mean(success) > rate_value and np.mean(total_loss) < loss_value:
rate_value, loss_value = np.mean(success), np.mean(total_loss)
save(model.state_dict(),'./models/best_model.pkl')
save(optimizer.state_dict(),'./models/best_optimizer.pkl')手写识别
经过上面的流程,我们已经保存了最优的模型和优化器。为了探究模型和优化器的效果到底怎么样,我们手写一个数字来进行识别。**首先,我们建立一张像素为 28 x 28 的图片(这是因为训练集的图片宽度和高度都是 28),接下来将图片填充为黑色,用白色的笔写上数字“0”(这是因为训练集的图片都是黑底白字的图片),最后保存为 test.jpg。**效果如下:

现在我们用训练好的模型对他进行推理识别,在 MNIST 的文件夹中新建名称为 inferring.py 文件。代码如下:
python
from torchvision import transforms
from torch import nn, optim, load, no_grad
from PIL import Image
def inferring(img):
# 实例化模型,加载最优模型,启用eval评估模式
model = Network()
model.load_state_dict(load('./models/best_model.pkl'))
model.eval()
# 创建Adam优化器实例,加载最优优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
optimizer.load_state_dict(load('./models/best_optimizer.pkl'))
# 图片处理方案流
my_transforms = transforms.Compose(
[
transforms.Grayscale(), # 由于保存的图片是3通道,这里转为1通道。
transforms.ToTensor(), # 变为float类型的tensor格式数据(因为下面的输入tensor必须是float类型)
transforms.Normalize(mean=(0.1307, ), std=(0.3081, )) # 标准化,mean均值0.1307(官方),std标准差0.3081(官方),都是元组。
]
)
image = my_transforms(img)
# 不需要计算梯度以及反向传播了
with no_grad():
# 获取结果
output = model(image)
# 获取结果值最大的
result = output.max(dim=1).indices
# 输出识别结果
print(result.item()) # 输出:0。注释:可以看输出和图片的内容一致。
if __name__ == '__main__':
# 打开手写图像
img = Image.open('test.jpg')
# 调用方法,传入参数
inferring(img)建议
以上就是整个深度学习训练流程里面所有的内容,将上面所有的内容组合在一起,就是一个项目了。后期要训练自己的数据集时,就需要把MNIST数据集换成我们自己的数据集。