组织、导入、内置、环境
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
目前,我们已经学习了 Python 的部分语法,可以编写代码来实现一些简单的功能了,那这是否意味着很多简单功能需要我们从零开始开发?当然不是,Python 的一大特色就是拥有丰富的生态,许多常见的编程任务已经有人用更高效、更稳定的方式实现了,而且经过时间验证的代码通常意味着更少的错误和更高的质量。因此,我们只要复用别人的代码,就能极大地加速开发过程,避免重复造轮子。
组织单位
在学习 Python 的过程中,我们可能听到或看到过模块(Module)、包(Package)和库(Library)之类的术语,其实它们指的是组织和复用代码的基本单位。
模块(Module)
模块(Module)是一种用于组织和复用代码的基本单位。在 Python 中,模块是指扩展名为 .py 结尾的文件,文件中封装了相关 Python 代码片段,能够被其他 Python 文件导入和使用。模块分为以下几种类型:
- 内置模块(Built-in Module):随 Python 解释器启动而自动加载到内存中的一组模块,属于 Python 解释器的一部分。它们对于 Python 的运行至关重要,而且通常是用 C 语言编写,以提高效率。
- 作用:内置模块提供了 Python 语言的核心功能,比如
__builtins__模块提供了基本的数据类型(如int、str、list)、内置函数(如len()、print())、内置异常等。 - 使用:大多数内置模块中定义的名称(如函数名、类名等),已经被直接放置在了 Python 的全局命名空间中,因此我们可以直接使用内置模块中定义的变量、函数和类,而无需显式地通过关键字来导入它们。
- 更新:内置模块的更新通常需要通过更新 Python 解释器来获得。
- 作用:内置模块提供了 Python 语言的核心功能,比如
- 标准库模块(Standard Library Module):随 Python 解释器一同安装的用于执行各种任务的一系列模块。虽然它们不是 Python 解释器的一部分,但它们是 Python 编程中不可或缺的一部分。
- 作用:标准库模块提供了广泛的编程功能,用于执行各种任务,如文件操作、网络编程、数据编码解码、数据库接口等。
- 使用:标准库模块随 Python 解释器一起发布和安装,因此无需再额外下载,不过在使用标准库模块时,需要先通过关键字导入后才能使用。
- 更新:标准库模块的更新则随着 Python 版本的发布而更新,可以通过升级 Python 版本来获取最新功能。
- 第三方模块(Third-party Module):也称为扩展库、外部库或非标准库,这些模块都不是 Python 官方提供的,而是由 Python 社区或第三方开发者提供。虽然它们不是官方提供的,但它们是 Python 的一大特色,庞大的数量和丰富的生态覆盖了几乎所有的开发需求,从数据分析、科学计算、Web 开发到人工智能等领域。
- 作用:第三方模块通常包含了一组预定义的函数、类或方法,用于实现特定的功能或解决特定的问题。
- 使用:使用第三方模块时,需要通过包管理工具(如 pip)从网络仓库中将第三方模块下载安装到本地,然后通过关键字导入第三方库才能使用。
- 更新:第三方模块的更新需要模块提供者先发布新版本,然后通过包管理工具(如 pip)执行命令进行更新。
- 自定义模块(Custom Module):用户创建的用于封装和复用特定代码的
.py文件。- 作用:自定义模块里面包含了用户定义的函数、类和变量,以便在多个程序或脚本之间共享。
- 使用:比如,我们自定义开发了一个名为
math_utils.py的文件,里面定义了一些数学工具函数,那么这个文件就是一个模块,模块名称就是math_utils,其他的文件就可以通过关键字导入该模块名称调用其中的代码。需要注意的是,自定义模块在命名时,最好具有唯一性,以避免与其它模块相互冲突。 - 更新:自定义模块的更新需要用户自己来更新其中的代码。
总结来说,使用模块可以提高代码的可维护性和复用性,同时减少代码冗余。因此可以说,模块是 Python 编程中组织代码、复用代码和共享代码的重要手段。
提醒
由于 Python 拥有生态完善且数量庞大的第三方模块,很多 Python 开发者都会利用第三方库(通常被称为“包”)来快速开发应用程序或解决特定问题,所以 Python 的开发者或用户有时会被称为“Python 调包侠”(这个称呼不是一个官方术语)。
包(Package)
包(Package)是一个包含名为 __init__.py 文件的特殊目录,在目录里面可以包含多个模块或子包。例如,有一个名为 mylib 的目录,其中包含了一个 __init__.py 文件以及多个模块(如 module1.py、module2.py)和子包(如 subpackage),那么 mylib 就是一个包。
初始化文件
首先,我们来了解一下 __init__.py 文件,该文件也叫“包的初始化文件”,虽然文件里面可以不用写任何内容,但这个文件必须有,而且必须在包的根路径下,它的存在就表示当前文件夹是一个包。具体作用如下:
- 标识包,在新建文件夹中创建一个
__init__.py文件,这样 Python 解释器就会将该文件夹视为一个包。 - 初始化操作,当我们在使用包的时候,
__init__.py文件里面的代码会自动执行。如果包需要在加载时进行一些初始化操作,比如连接数据库,就可以在__init__.py文件中编写响应的代码来建立数据连接,一边在其它模块中可以直接使用该连接。 - 导入模块,如果包中有多个模块,可以在
__init__.py文件中导入这些模块,以便其它模块可以直接引用它们,而无需指定完整的路径。 - 定义包级别接口,如果需要提供一些公共接口,可以在
__init__.py文件中将这些接口导出,以便其它模块可以直接使用。 - 定义包级别的常量或配置,如果包需要定义一些常量或配置信息,可以在
__init__.py文件中定义它们,并在其他模块中使用。
建议
包提供了一种组织相关模块的方式,使得模块查找和复用更加方便,同时也体现了 Python 结构化管理思想。
新建包
在 PyChram 中新建一个包,需要进行如下操作:
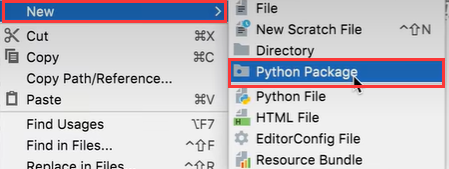
- 在左侧栏中选择一个目录,点击鼠标右键,选择
New选项,选择Python Package选项。 - 在弹出的输入框中输入包的名称,这里我们输入名称
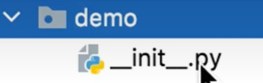
demo,按回车键进行确认。 - 在选择的目录路径下就会出现一个名称为
demo的目录,这个目录的图标上面有一个圆点,而且目录里面默认还有一个__init__.py文件,这就表明了当前的demo目录是一个包
::: image-group

:::
建议
如果我们删除 demo 包里面的 __init__.py 文件,那么 demo 包将会变回普通的 demo 目录,目录图标上面的圆点也会消失。
标记包
在 PyChram 中把已有目录标记为包,需要进行如下操作:
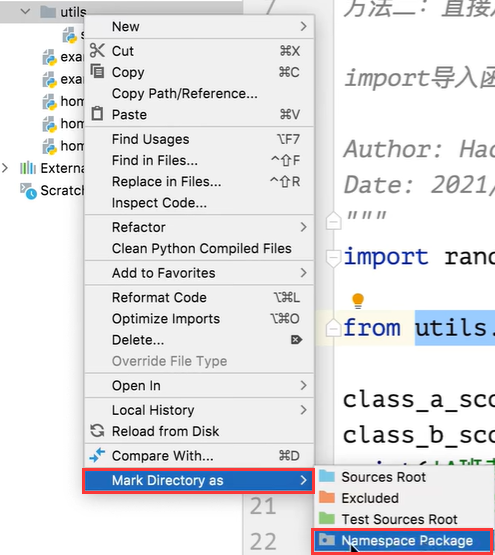
- 在左侧栏中选择一个目录,右键选择
Mark Directory as选择Namespace Package选项,将文件夹标记为一个包,称为“命名空间包”。 - 被标记为“包”后的文件夹,中间就会出现一个原点,只要是这个路径里面的文件夹,中间都会出现一个原点。
::: image-group

:::
库(Library)
库(Library)是一组模块和包的集合,用于执行一组特定的任务或提供某种功能。关于库就不过多介绍了,因为它的概念和模块的类似,而且在实际使用中,我们往往不会严格区分“模块”和“库”这两个概念,经常会把“标准库模块”称之为“标准库”,把“第三方模块”称之为“第三方库”。
导入代码
上面我们已经了解了 Python 中组织和复用代码的基本单位,接下来就是学习如何导入并使用它们。根据导入时机和方式的不同,我们可以将导入方式划分为“静态导入”和“动态导入”。
警告
注意,在 Python 中并没有直接称为“静态导入”和“动态导入”的术语,只是我们按导入时机和方式进行的分类。
静态导入
“静态导入”通常指的是在代码文件顶部(或者某个作用域的开始处)直接使用关键字语句导入模块或库。这种方式在程序启动时就会执行,被导入的模块会被加载到内存中,并在当前命名空间中创建相应的名称引用。这种导入方式简单直接,但在某些情况下可能会导致不必要的模块加载或名称冲突。
关键字 import
关键字 import 是导入模块或包的声明,后面一般跟模块名或包名。需要注意,在导入的时候不要添加 .py 后缀,Python 解释器会自动在当前目录、Python 的标准库目录以及通过环境变量指定的其他目录中查找相应的 .py 文件或包。使用关键字 import 的注意事项和案例如下:
- 同一项目:关键字
import导入的模块和使用这些模块的脚本或模块最好位于同一个项目(或称为工作区、包等)下,这样做有如下几个好处。- 组织性:将相关的模块和脚本放在同一个项目下有助于保持项目的组织性和可管理性。你可以更容易地找到和使用项目中的其他模块。
- 依赖性管理:将模块保持在同一个项目中可以帮助你更好地管理项目之间的依赖关系。如果你将模块分散在多个不同的位置,那么管理这些依赖关系可能会变得更加复杂。
- 版本控制:如果你使用版本控制系统(如 Git)来管理你的项目,那么将所有相关的模块和脚本放在同一个项目下可以更容易地跟踪和管理它们的更改。
- 可移植性:将项目中的所有文件放在一起还可以提高项目的可移植性。你可以更容易地将整个项目复制到另一台计算机上,并在那里继续工作,而无需担心缺少某些模块或文件。
- 导入标准库:使用
import关键字后跟库名,就可以导入整个库。
python
# 导入math标准库
import math
# 使用math标准库中的sqrt方法,计算整型数值的平方根。
result = math.sqrt(25)
print(result) # 输出:5.0- 导入模块或包:对于同一个包内的模块,使用
import 模块名导入。对于包外的模块,可以先使用import 包名导入整个包,再到代码中通过包名.模块名来选择模块。另外需要记住的是,在导入模块时,Python 会执行模块中的顶层代码(缩进为 0 个空格的代码,包括任何全局变量定义、函数定义、类定义等),而非顶层代码(缩进不为 0 个空格的代码,包括函数体、类方法体内的代码)会被加载到内存中,等待被引用或调用执行。
python
"""item包中的other.py文件"""
print(123) # 注释:输出语句(顶层代码)
n = 10 # 注释:定义变量(顶层代码)
def f(): # 注释:定义函数(顶层代码)
print('f') # 注释:输出语句(函数体,非顶层代码)
global a # 注释:声明全局变量a(函数体,非顶层代码)
a = 1 # 注释:变量a赋值整型1(函数体,非顶层代码)python
"""item包中的work.py文件"""
# work.py和other.py在同一个item包中,可以使用import关键字直接导入other模块。
import other # 输出:123。注释:导入other模块会执行里面的顶层代码。
print(other.n) # 输出:10。注释:调用other模块里面的变量n。
print(other.a) # 报错:模块里面没有定义变量a。
other.f() # 输出:f。注释:调用other模块里面的f函数,输出f,并定义了other模块中的变量a。
print(other.a) # 输出:1。注释:因为上面调用函数f,定义了other模块中的变量a,因此这里才能输出other模块里面的变量a。python
"""item包外的job.py文件"""
# job.py在item包外,直接导入item包。
import item # 注释:导入整个item包。
item.other # 输出:123。注释:调用item包中的other模块会执行里面的顶层代码。
item.other.f() # 输出:f。注释:调用item包中的other模块中的f函数。重要
需要注意,Python 中的模块只会被导入一次(除非使用了特定的技术,如重新加载模块),这意味着如果你多次导入同一个模块,Python 实际上只会执行该模块的顶层代码一次,并返回已经加载的模块对象。
关键字 from
关键字 from 和关键字 import 通常一起使用,作用是从包或模块中导入指定的功能或内容。使用关键字 from 的案例和优点如下:
- 导入所有内容:使用
from 模块/包 import *导入模块或包中的所有内容。
python
"""item包中的other.py文件"""
a = 123 # 注释:定义变量(顶层代码)
b = 456 # 注释:定义变量(顶层代码)
c = 789 # 注释:定义变量(顶层代码)python
"""item包中的work.py文件"""
from other import * # 注释:导入other模块中的全部内容
print(a) # 输出:123
print(b) # 输出:456
print(c) # 输出:789注意
注意,使用星号导入(*)通常不是一个好的做法,因为它会导致命名空间污染,使当前命名空间中充斥着来自其他模块的名字,增加了命名冲突的风险,并且降低了代码的可读性。因此,在项目代码中应尽量避免使用 from...import * 语句。
- 导入指定内容:使用
from 模块/包 import 内容1, 内容2...导入模块或包中指定的具体内容(可以是函数、类、变量等)。
python
"""item包中的other.py文件"""
a = 123 # 注释:定义变量(顶层代码)
b = 456 # 注释:定义变量(顶层代码)
c = 789 # 注释:定义变量(顶层代码)python
"""item包中的work.py文件"""
from other import a, b # 注释:导入other模块中的变量a、变量b
print(a) # 输出:123
print(b) # 输出:456
print(c) # 报错:没有导入other模块中的变量c,因此变量c未定义的。建议
通过导入模块或包中指定内容的具体方式可以减少资源浪费,使代码更清晰,是推荐的导入方式。
关键字 as
关键字 as:给被导入的内容重新命名。
- 命名模块或包:通过
import 模块/包 as 新的名称给被导入的模块或包重新命名。
python
# 将导入的math模块重命名为m
import math as m
result = m.sqrt(25)
print(result) # 输出: 5.0建议
如果包名或模块名较长,可以使用 as 关键字为它们指定别名,以提高代码的可读性。
- 命名导入内容:通过
from 模块/包 import 内容 as 新的名称给从模块或包中导入的具体内容(可以是函数、类、变量等)重新命名。
python
"""item包中的other.py文件"""
a = 123 # 注释:定义变量(顶层代码)python
"""item包中的work.py文件"""
from other import a as b # 注释:导入other模块中的变量a重命名为b
print(b) # 输出:123
print(a) # 报错:变量a重命名为b了,以前的变量名称a就不能再使用了。警告
重新的命名后的内容,就只能使用新的名称,以前的名称就不能再使用了。
解决命名冲突
做工程化项目开发时,如果项目中的代码文件很多,我们可以使用“包”来管理“模块”,再通过“模块”来管理“函数”,这样就可以很好的解决大型项目中经常遇到的命名冲突的问题。常见的三种方式如下:
python
"""使用完全限定名"""
import utils.foo
import utils.bar
utils.foo.say_heelo()
utils.bar.say_heelo()python
"""使用部分限定名"""
from utils import foo
from utils import bar
foo.say_heelo()
bar.say_heelo()python
"""使用别名"""
from utils.foo import say_heelo as s1
from utils.bar import say_heelo as s2
s1()
s2()动态导入
“动态导入”则指的是在程序运行时根据需要动态地导入模块。这通常通过使用 __import__ 函数或者 importlib 模块来实现。动态导入允许你在程序的不同部分、或者根据程序运行时的条件来决定是否导入某个模块,这可以提供更高的灵活性和控制力。
__import__()是一个内置函数,可以在运行时根据需要动态地导入模块。这种方式灵活性高,但使用较为复杂,不够直观。
python
# 动态导入math模块
module = __import__('math')
result = module.sqrt(25) # 使用math模块中的sqrt函数
print(result) # 输出: 5.0importlib是 Python 的标准库之一,提供了更高级的模块导入功能。importlib.import_module()函数可以在运行时动态地导入模块,与__import__()类似,但更加标准和推荐使用。
python
import importlib
# 动态导入math模块
module = importlib.import_module('math')
result = module.sqrt(25) # 使用math模块中的sqrt函数
print(result) # 输出: 5.0适用场景
总的来说,静态导入简单直接,适合大多数情况;而动态导入则提供了更高的灵活性和控制力,适用于需要动态决定模块加载的复杂场景。
内置变量
内置变量指的是 Python 解释器自动定义的、以双下划线开头和结尾命名的一些特殊变量。内置变量在 Python 的命名空间中具有特定的用途,用户通常不需要显式定义它们,直接拿来使用即可。
__name__ 变量
__name__ 内置变量,用于表示当前模块的名字,也常用于判断模块是被直接运行还是被导入到其他模块中。
- 模块名字:当模块被直接运行时,
__name__的值为"__main__";当模块被导入到其他模块中时,__name__的值为该模块的名称。
python
"""item包中的other.py文件"""
print(__name__) # 输出:__main__。注释:说明模块是直接运行的。python
"""item包中的work.py文件"""
import other # 输出:other。注释:说明模块是被导入到其他模块中运行的。- 导入判断:使用
if __name__ == "__main__":可以判断模块是被直接运行还是被导入的,同时也可以来防止在导入时执行。
python
"""item包中的other.py文件"""
if __name__ == '__main__':
print(123) # 输出:123。注释:if条件语句成立,说明模块是直接运行的。python
"""item包中的work.py文件"""
import other # 注释:没有输出,if条件语句不成立,说明模块是被导入直接运行的。__file__ 变量
__file__ 内置变量,用来表示所在模块的绝对路径和文件名称,且不受模块导入的影响。
python
"""item包中的other.py文件"""
print(__file__) # 输出:C:/Users/item/other.pypython
"""item包中的work.py文件"""
import other # 输出:C:\Users\item\other.py。注释:输出的仍是__file__变量所在的源文件位置和源文件名称。__all__ 变量
__all__ 内置变量,用于控制模块的导出接口,定义了使用 from module import * 语句时应该导入哪些名字(即变量、函数、类等)。
python
"""item包中的other.py文件"""
__all__ = ["name1", "name2"] # 注释:定义一个列表里面包含模块中所有可被导入的名称字符串。
def name1():
print('name1')
def name2():
print('name2')
def name3():
print('name3')python
"""item包中的work.py文件"""
from other import *
name1() # 输出:name1
name2() # 输出:name2
name3() # 报错:other模块限制的可导出内容中,没有名称name3。建议
如果没有定义 __all__ 变量,则 from module import * 语句会导入模块中定义的所有公共名字(即不以单下划线 _ 开头的名字)。
环境变量
环境变量(Environment Variables)是用于指定操作系统运行环境的一些参数,它们对于操作系统中的程序和系统服务非常重要。这些变量可以是任何字符串,它们被操作系统用来定位文件、目录、库函数等。这些变量可以被操作系统中的任何程序或进程访问,并且可以在程序运行时被修改或新增。
常用环境变量
环境变量通常用于以下几个方面:
- 系统路径:例如,
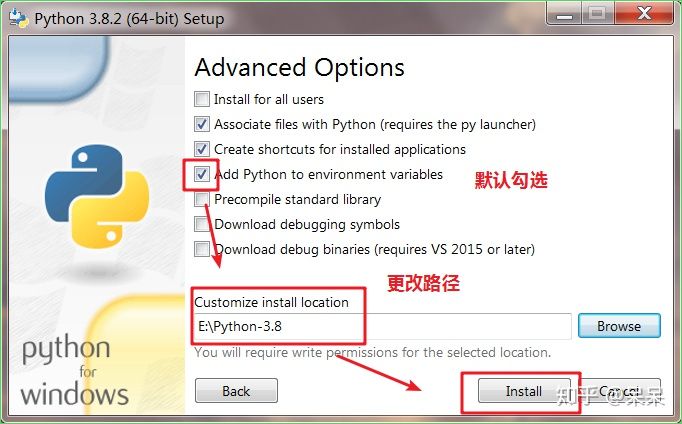
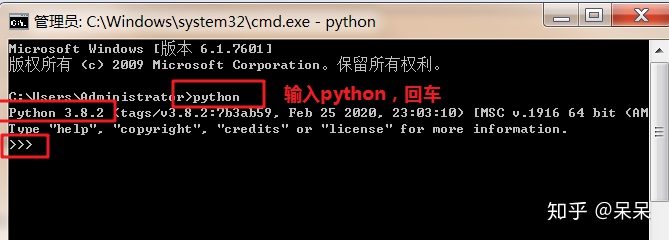
PATH环境变量在 Unix、Linux 和 Windows 系统中都存在,它指定了操作系统查找可执行文件的目录。当你在命令行中输入一个命令时,系统会按照PATH环境变量中定义的目录顺序去查找这个命令的可执行文件。前面我们安装 Python 解释器的时候,就勾选了将 Python 添加到PATH环境变量中,所以我们在才能在 Terminal 终端中执行 Python 命令。
::: image-group
:::
- 用户配置:环境变量可以存储用户的特定配置信息,比如用户的家目录、临时文件目录等。
- 应用程序设置:应用程序可以使用环境变量来存储配置信息,如数据库连接信息、日志文件路径等。这样,应用程序就可以在不同的环境下灵活运行,而无需修改代码中的硬编码路径。
总的来说,环境变量是操作系统和应用程序之间传递配置信息的一种机制,它们对于系统的运行和应用程序的灵活性至关重要。
建议
在 Unix、Linux 系统中,环境变量通常通过shell(如bash、zsh等)进行管理,可以使用 export 命令来设置环境变量,使用 echo $VARIABLE_NAME 来查看环境变量的值。
查看环境变量
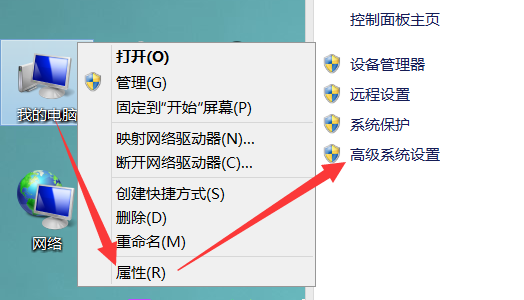
在 Windows 系统中,查看环境变量需要进行如下操作:
- 右键点击“我的电脑”,点击“属性”选项,点击“高级系统设置”按钮。
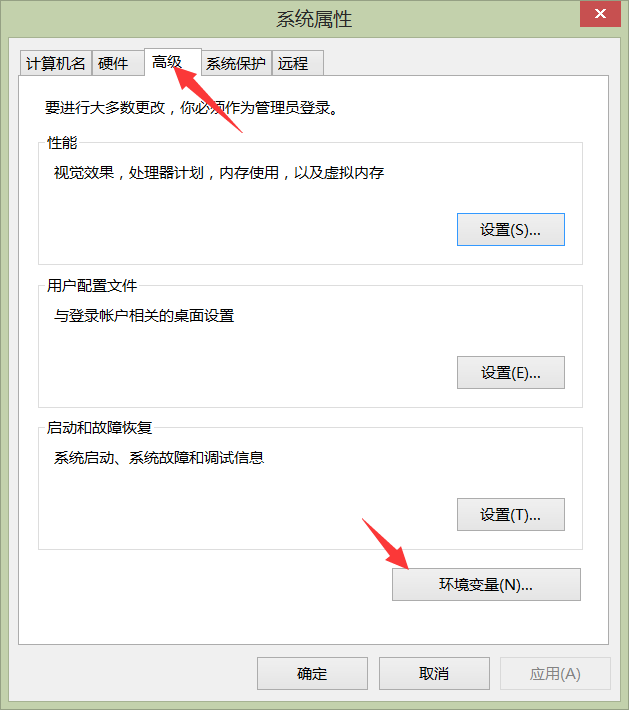
- 点击“高级”选项卡,点击“环境变量”按钮。
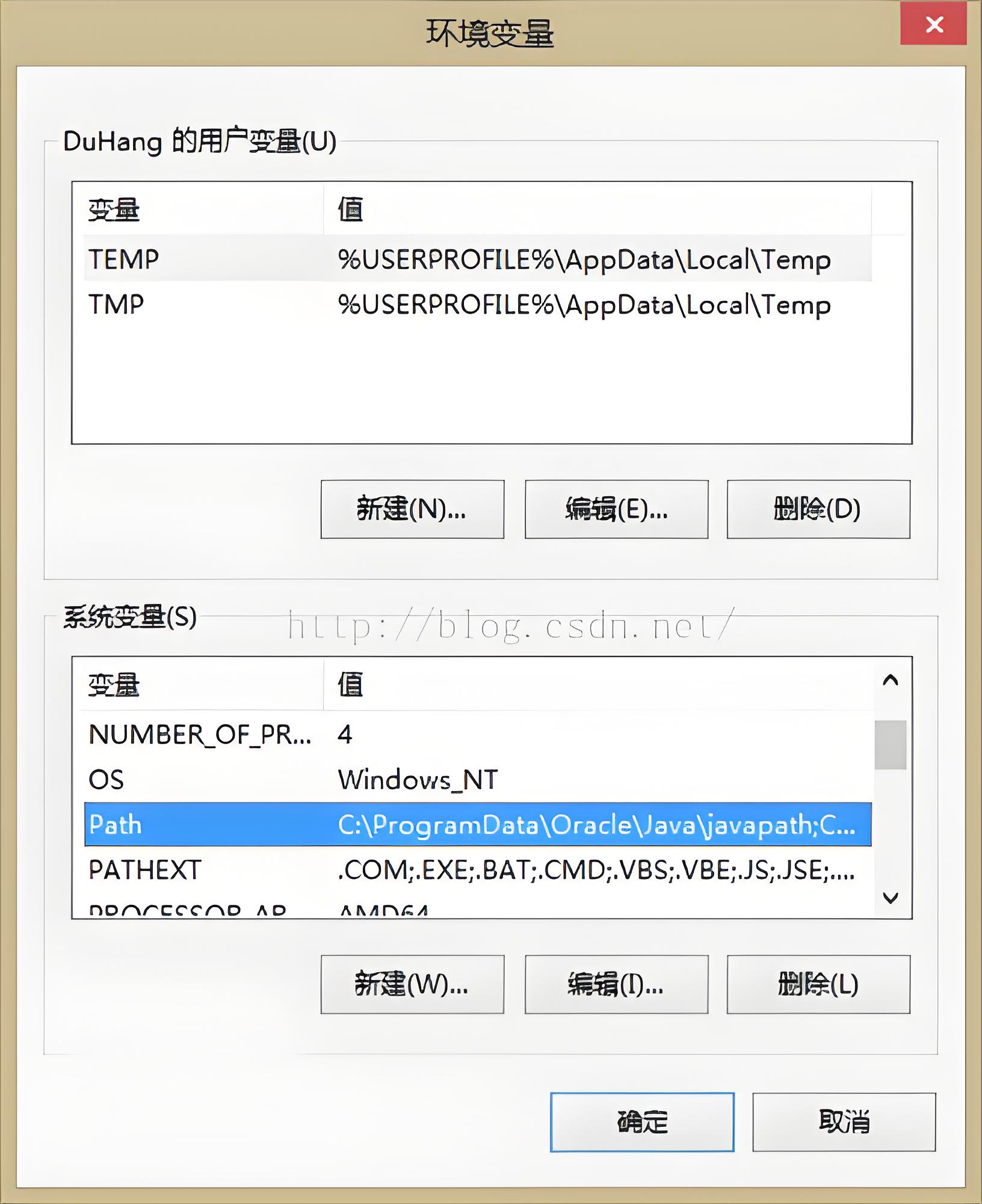
- 在弹出的环境变量界面中,就展示了两个部分的环境变量。
- 用户变量(User Variables):用户变量是针对当前登录系统的用户而设置的。每个用户都可以有自己的一组用户变量,这些变量仅对当前用户有效。用户变量中存储的信息通常包括个人偏好设置、应用程序配置等,它们仅在当前用户的会话中起作用。用户通常有权限修改和管理自己的用户变量,这使得用户可以根据自己的需求调整个人设置。对用户变量的更改通常在用户注销或重新登录后才会生效。这是因为用户变量是存储在用户个人配置文件中的,只有在用户重新登录时才会重新加载这些配置。
- 系统变量(System Variables):系统变量则是针对整个操作系统而设置的,对系统上的所有用户都是可见的。系统变量中存储的信息通常是全局性的,如系统路径、环境配置等,它们影响整个系统的运行。修改系统变量通常需要管理员权限。这是因为系统变量对整个系统的配置产生影响,需要确保在系统级别上的修改是受限制的,以防止系统不稳定或安全问题。对系统变量的更改通常需要重新启动系统或者至少重新启动相应的应用程序或服务才能生效。这是因为系统变量是全局性的,它们的更改需要系统重新加载这些配置才能生效。
::: image-group
:::
建议
当同名的用户变量和系统变量都存在时,用户变量的优先级高于系统变量。这意味着,如果系统需要引用某个变量,并且该变量在用户变量和系统变量中都有定义,那么系统将优先使用用户变量中的值。
编辑环境变量
在编辑环境变量前,我们在 PyCharm 中执行下面的代码,来查看一下环境变量,代码如下:
python
# 导入sys标准库
import sys
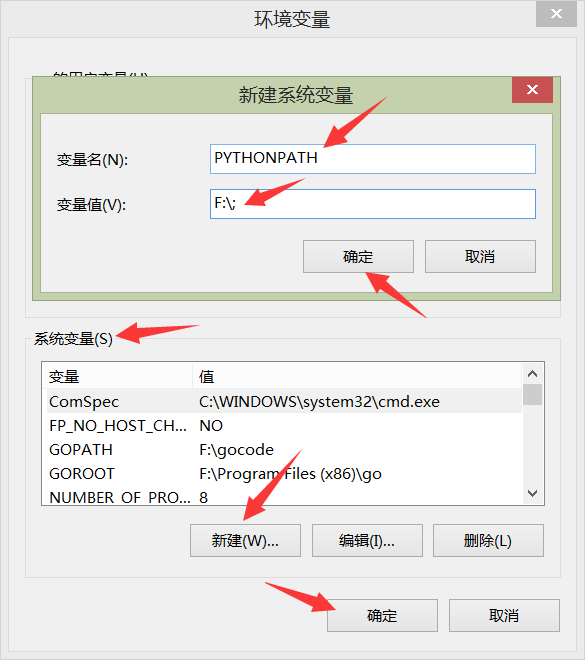
print(sys.path) # 输出:['F:\\Python3.6.5'...]。注释:查看当前的环境变量。现在我们来编辑环境变量,在上面打开环境变量界面中,点击“系统变量”下面的“新建”按钮,在弹出的输入框中“变量名”栏写入 PYTHONPATH(全部大写),在“变量值”栏写入 搜索模块或包的绝对路径,多个路径以英文 ; 符号分割,最后点击“确定”按钮进行保存。
重要
PYTHONPATH 是一个环境变量,用于定义 Python 解释器搜索模块的额外路径列表。通过修改这个环境变量,开发者可以告诉 Python 去哪里查找他们自定义的模块或第三方库。
在编辑环境变量后,我们重启 PyCharm 并执行同样的代码,来查看一下环境变量,代码如下:输出结果中新增了我们在上图环境变量中添加的 F:\ 路径。
python
# 导入sys标准库
import sys
print(sys.path) # 输出:['F:\\', 'F:\\Python3.6.5'...]。注释:出现了'F:\\',说明新增的环境变量已被添加。联系环境变量
现在我们对环境变量有一定的了解了,那么它和我们上面学习的导入模块或包有什么联系呢?上面我们讲关键字 import 导入模块或包时,提到 Python 解释器会自动在当前目录、Python 的标准库目录以及通过环境变量指定的其他目录中查找相应的 .py 文件或包。也就是说,Python 解释器在导入模块或包时,会按照一个特定的顺序来查找指定的模块或包,具体的顺序和流程如下:
- 在当前目录查找:当 Python 尝试导入一个模块时,它首先会在当前执行的脚本文件所在的目录中查找该模块。这允许开发者在项目的根目录下或任意子目录中组织他们的代码,并直接引用这些模块,而无需担心路径问题(只要它们位于当前工作目录中)。
- 查找 PYTHONPATH 环境变量指定的路径:如果在当前目录中没有找到模块,Python 接下来会检查环境变量 PYTHONPATH 中指定的目录。上面编辑环境变量,就是这样一个例子。
- 查找 Python 默认的安装路径:如果上述两个位置都没有找到模块,Python 会在其默认的库路径中查找。这些路径包括 Python 标准库的安装位置以及通过 pip 等工具安装的第三方库的位置。Python 解释器在启动时会自动确定这些路径,并在此后按照一定顺序搜索它们。
- 抛出
ModuleNotFoundError异常:如果在上述所有位置中都没有找到指定的模块,Python 将抛出一个ModuleNotFoundError异常,提示开发者该模块无法被找到,可能是因为模块名拼写错误,或者该模块尚未安装在当前环境中。
总之,了解这一查找顺序对于开发者来说非常重要,因为它可以帮助我们理解 Python 是如何导入模块的,以及如何在需要时调整这一行为(例如,通过修改 PYTHONPATH 环境变量或更改当前工作目录)。