Ajax异步请求
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
目前我们已经能够爬取并保存一些网页的数据了,但并不是每个网页都能乖乖的将数据直接给你,有一部分网页,它会将数据展示在网页上,但在网页的源代码中却找不到数据的影子,原因就在于这部分网页使用了 Ajax 技术。
Ajax 技术:即异步的 JavaScript 和 XML,它不需要任何插件,在保证页面不被刷新、页面链接不改变的情况下,使用 JavaScript 与服务器交换数据并更新网页部分内容的技术(网页局部刷新技术)。简单地说,不需要刷新页面的情况下,通过异步请求加载后台数据并在网页上呈现出来。
Ajax 流程:最初的原始页面最初不会包含任何数据,当原始页面加载完后,会再向服务器的某个接口发送一个 Ajax 异步请求,然后返回的数据处理后呈现到网页上。
Ajax 优势:用较少网络数据的传输量,提高用户体验。
Ajax 应用:在网页上输入需要翻译的短文,输入过程中翻译的结果不断变化,而网页并没有全部刷新。从 Web 发展的趋势来看,这种形式的页面越来越多,网页的原始 HTML 文档不会包含任何数据,数据都是通过 Ajax 加载后再呈现出来的,这样在 Web 开发上可以做到前后端分离,还能降低服务器直接渲染页面带来的压力。
建议
Ajax 运行的前提是用户允许 JavaScript 在浏览器上执行。
Ajax响应
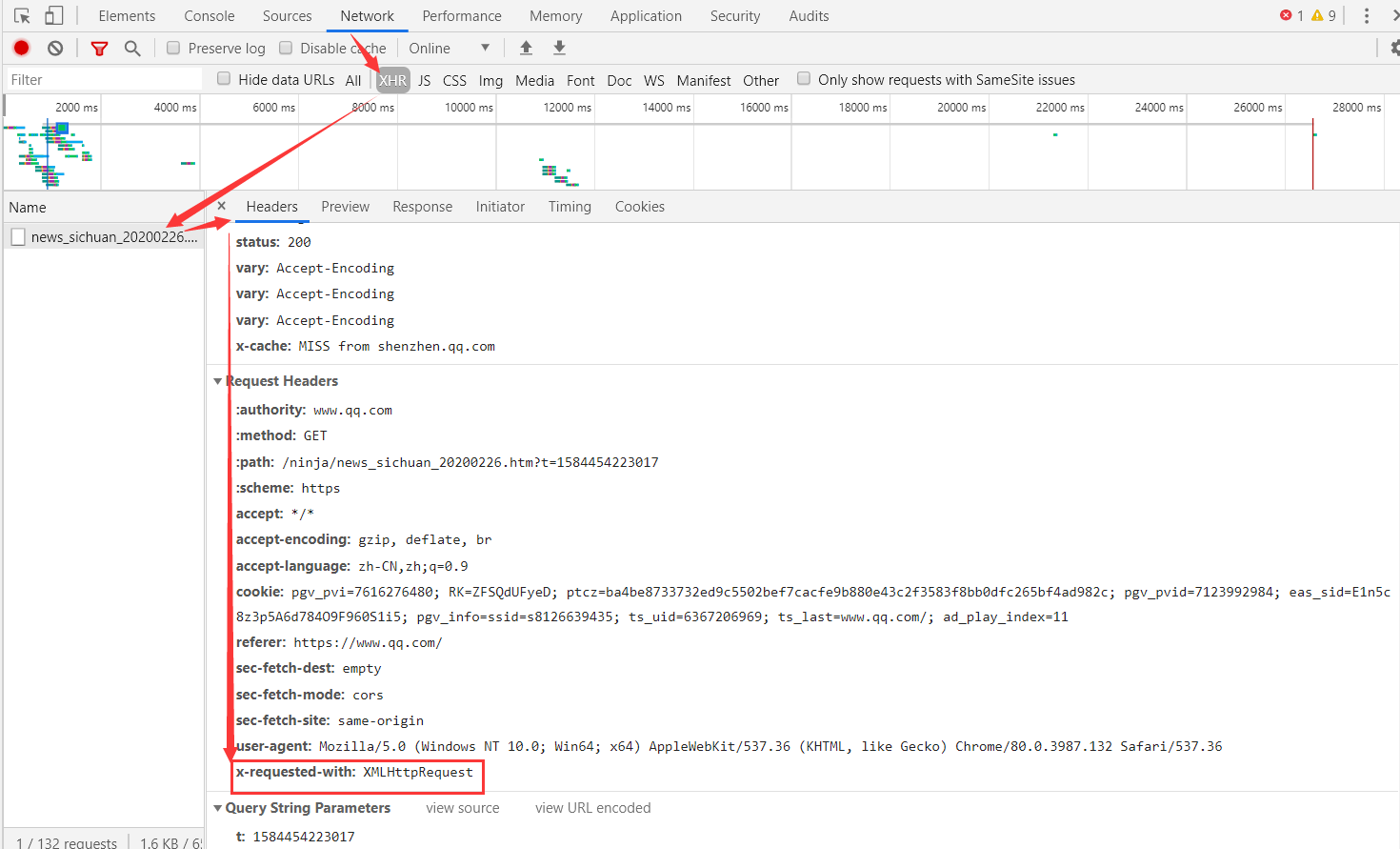
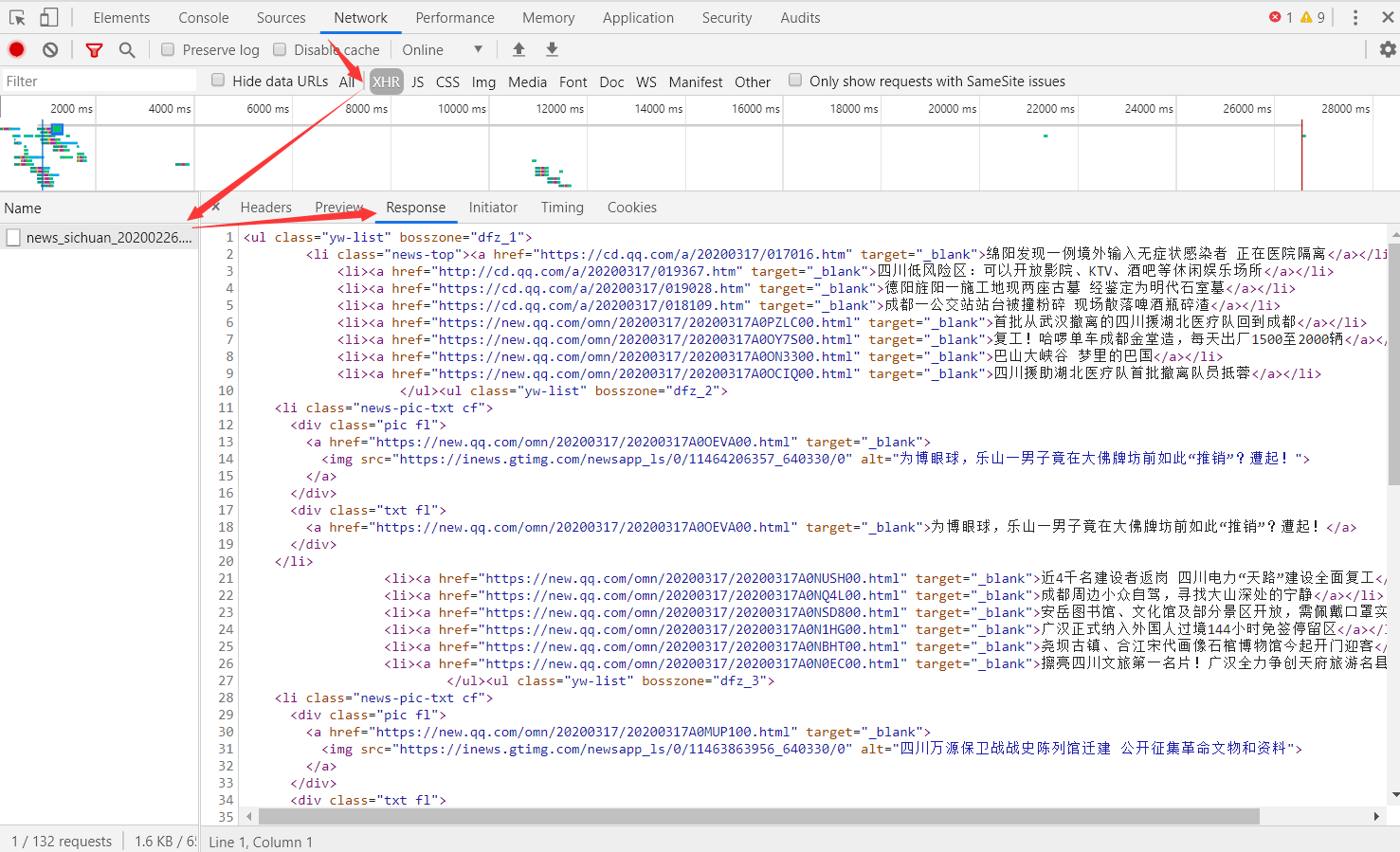
打开 Chrome 浏览器的“开发者工具”进行抓包,访问一个有局部刷新功能的网页(能发送 Ajax 请求),点击“Network“选项卡(查看浏览器和服务器所有的请求和响应),再点击“XHR“选项卡(Ajax的核心是XMLHttpRequest对象,简称XHR)筛选出 Ajax 请求:
- 点击 Ajax 请求的 Headers 选项,其中 Request Headers 的一个信息为
X-Requested-With:XMLHttpRequest,这就标记了此请求是 Ajax 请求; - 点击 Ajax 请求的 Response 选项,这里就显示了 Ajax 请求的响应。
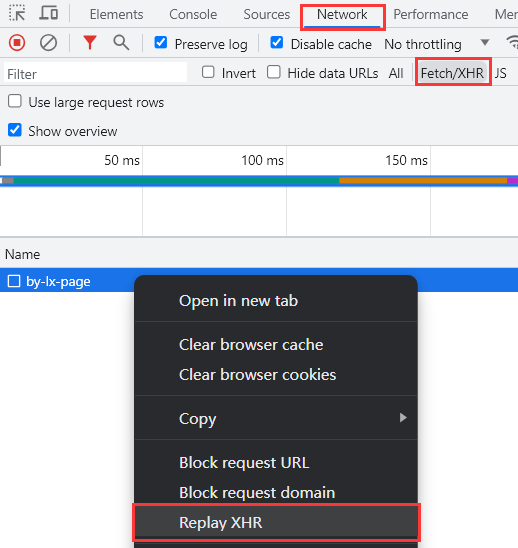
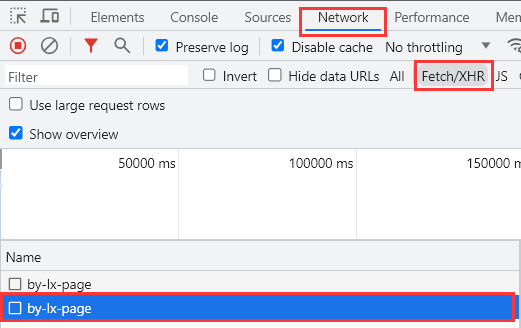
Ajax重放
**Chrome 浏览器的“开发者工具”针对Ajax请求设置了重放功能,该功能可以让我们再发起一次和当前 Ajax 请求相同参数的 Ajax 请求,也就是发起第二次相同的 Ajax 请求。**首先点击“Network“选项卡,再点击“XHR“选项卡筛选出Ajax请求,右键Ajax请求点击“Replay XHR”选项,就重放了一次相同的 Ajax 请求:
Ajax代码
我们来看看 Ajax 具体是怎么样实现的,点击左侧的 Initiator 选项,它主要是标记请求是由哪个对象或进程发起的(请求源),重点关注里面的 request 请求,显示从一个名称为“12”的文件的第 723 行代码发送了当前请求,点击后面的地址进行跳转:
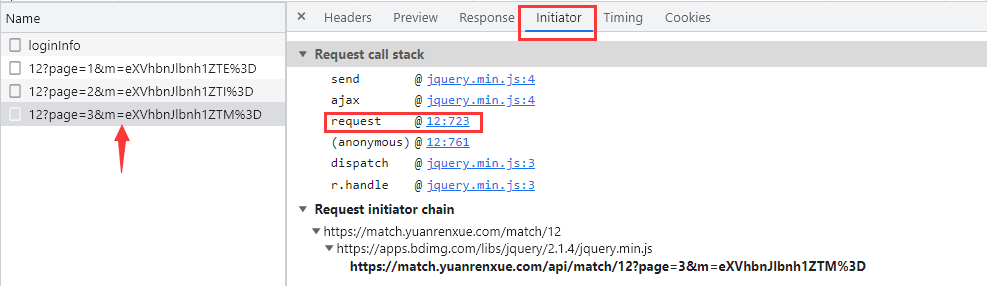
跳转到了名称为“12”的文件的第 723 行,可以看到 $.ajax 请求中有 success、complete、error 这三个字段,分别代表请求成功执行、不管请求是否成功请求都执行、请求不成功执行的含义:

Ajax模拟
直接利用 requests 等库来抓取原始页面,是无法获取到有效数据的,这时需要分析网页后台向哪个接口发送的 Ajax 请求,再利用 requests 来模拟 Ajax 请求,那么就可以成功抓取了。
python
import requests
from fake_useragent import UserAgent
# 构造随机请求头
headers = {'User-Agent':UserAgent().random}
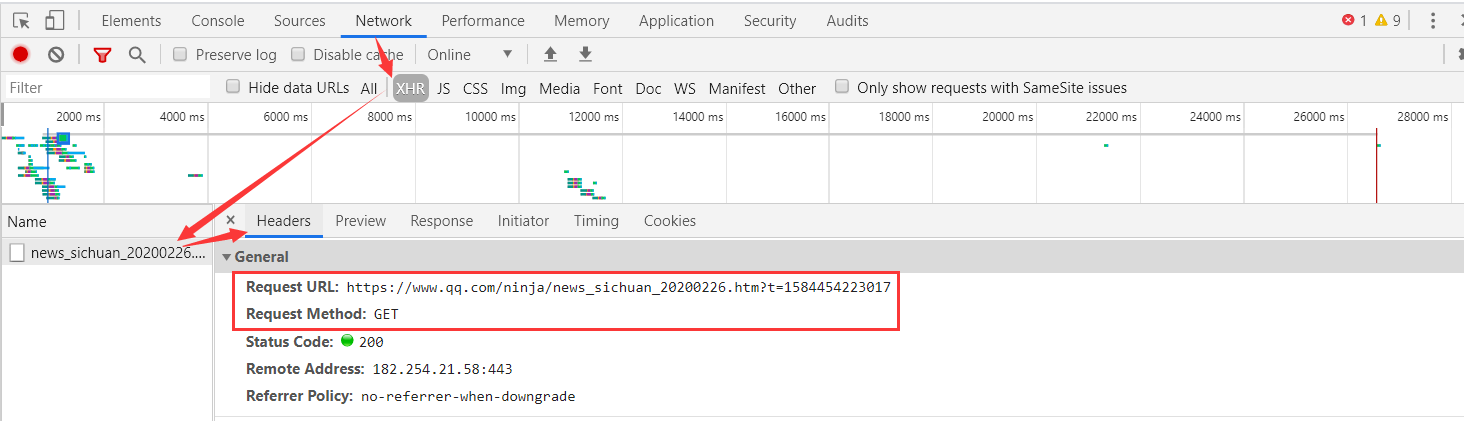
# Ajax请求的接口
url = 'https://www.qq.com/ninja/news_sichuan_20200226.htm?t=1584454223017'
# 发送GET请求
response = requests.get(url=url,headers=headers)
# 编码为GBK
response.encoding = 'GBK'
# 响应内容
print(response.text)
# 获取标题
title = re.findall(r'<a.*?>(.*?)</', response.text)
print(title)
# 获取链接
href = re.findall(r'<a.*?href="(.*?)"', response.text)
print(href)
'''
输出的响应:
<li><a href="https://new.qq.com/omn/20200317/20200317A0MFD200.html" target="_blank">刚刚,英雄凯旋!再看一眼“川军”战斗过的方舱医院</a></li>
<li><a href="https://new.qq.com/omn/20200317/20200317A0MF7M00.html" target="_blank">成都持枪斗殴案引出“GMI”传销大案 被打者是骨干人员</a></li>
<li><a href="https://new.qq.com/omn/20200317/20200317A0M4G000.html" target="_blank">四川日报整版刊发:春望甘孜 奏响奋发追赶动人乐章</a></li>...
输出的标题:
['刚刚,英雄凯旋!再看一眼“川军”战斗过的方舱医院', '成都持枪斗殴案引出“GMI”传销大案 被打者是骨干人员', '四川日报整版刊发:春望甘孜 奏响奋发追赶动人乐章'...']
输出的链接:
['https://new.qq.com/omn/20200317/20200317A0MFD200.html', 'https://new.qq.com/omn/20200317/20200317A0MF7M00.html', 'https://new.qq.com/omn/20200317/20200317A0M4G000.html',
...']
'''Ajax校验
有的网站会对 Ajax 请求的头部进行检测,例如现在我们需要采集页面中的这部分信息:
根据关键字直接搜索内容,发现有匹配 Json 格式内容,点击匹配的定位到接口:
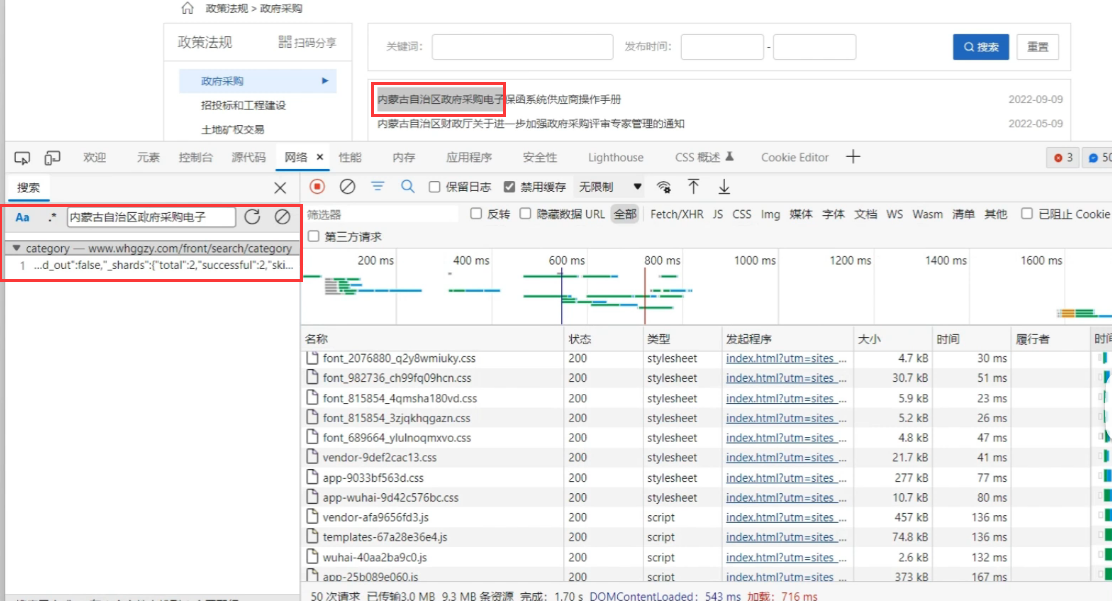
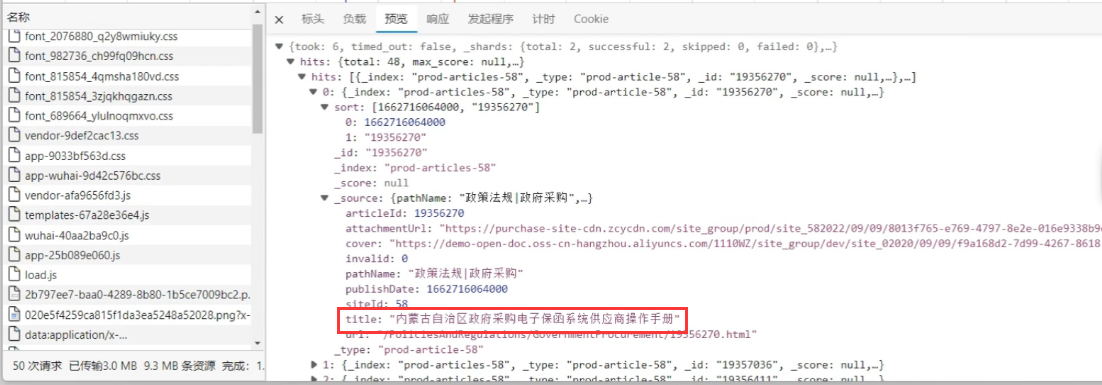
经过检查 json 内容并不包含在 HTML 标签内容,说明是一个动态的数据,其来源就是 Ajax 请求。在确认请求头参数没有加密信息后,我们拷贝 URL 接口编写一个标准的爬虫:
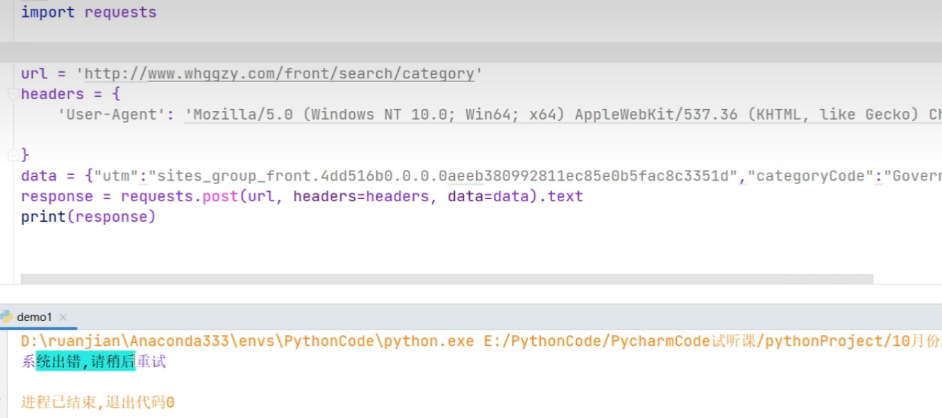
可以看到在请求头参数、请求参数、请求方式都看似没有问题的情况下,响应出错了,但是网站目前是能正常访问的,为什么会响应错误呢?首先我们来校验一下 URL 接口,将 URL 中域名后半部分路径进行拷贝,由于是 Ajax 请求,我们将其添加到浏览器中 XHR 断点中:
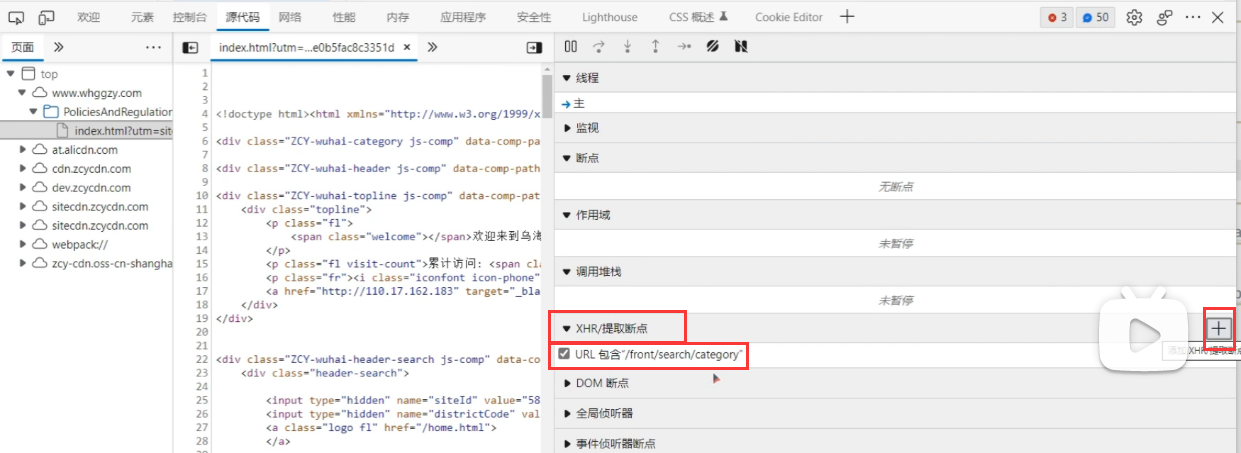
**刷新页面后,断点会断在浏览器发送包含 URL 接口路径的 XHR 请求的地方,通常是 xhr.send(),我们称这里为“请求对象的发送”。这时回看右侧边栏作用域的地方,就可以看到当前浏览器发送 Ajax 请求所带的 headers 请求头。**我们继续单击下一步:
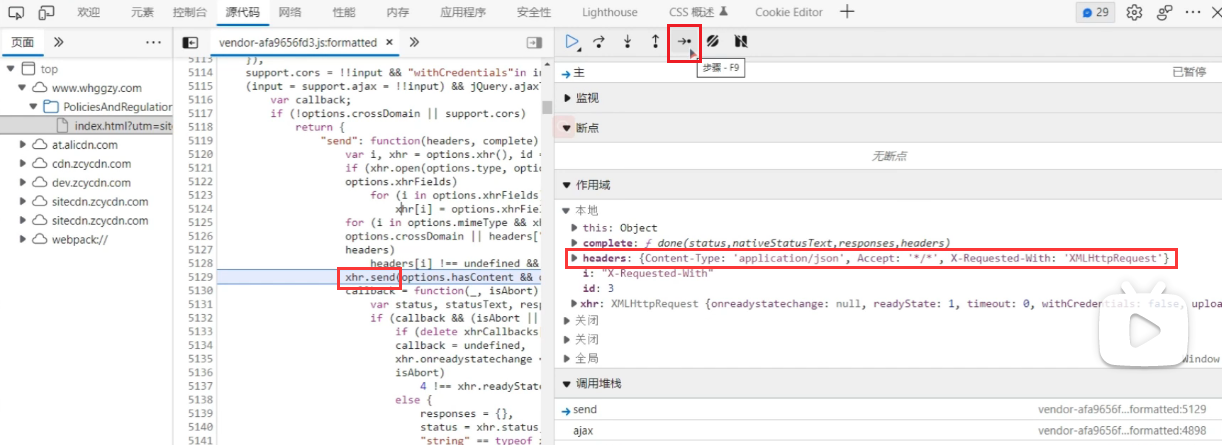
进入下一步,在 URL 接口路径当中,我们可以找到它的配置信息,其中包含了 XHR 请求的表单、请求方式、请求头等信息:
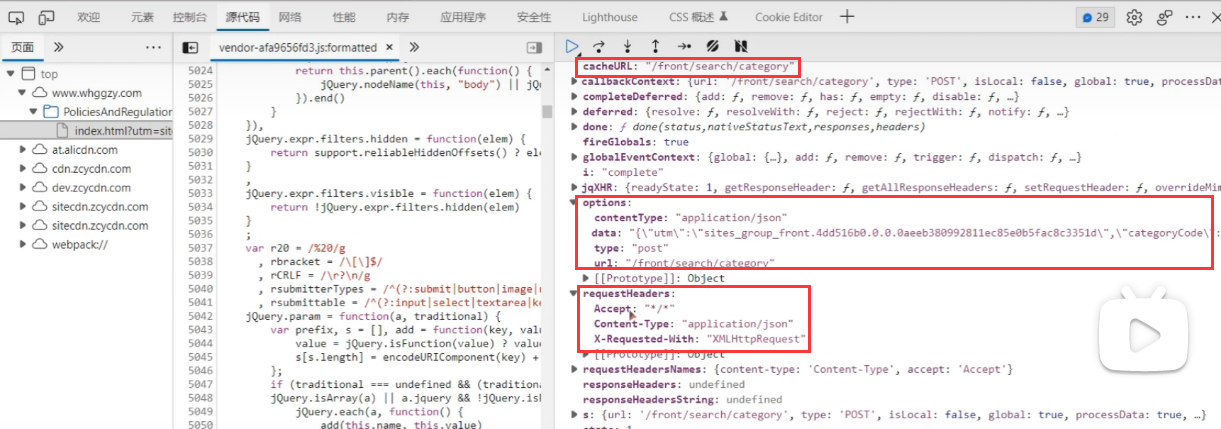
我们将其拷贝到爬虫当中进行请求,结果就能成功获取到数据: