栈Stack
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
栈(stack)是一种遵循先入后出逻辑的线性数据结构。我们可以将栈类比为桌面上的一摞盘子,如果想取出底部的盘子,则需要先将上面的盘子依次移走。我们将盘子替换为各种类型的元素(如整数、字符、对象等),就得到了栈这种数据结构。我们把堆叠元素的顶部称为“栈顶”,底部称为“栈底”。将把元素添加到栈顶的操作叫作“入栈”,删除栈顶元素的操作叫作“出栈”。
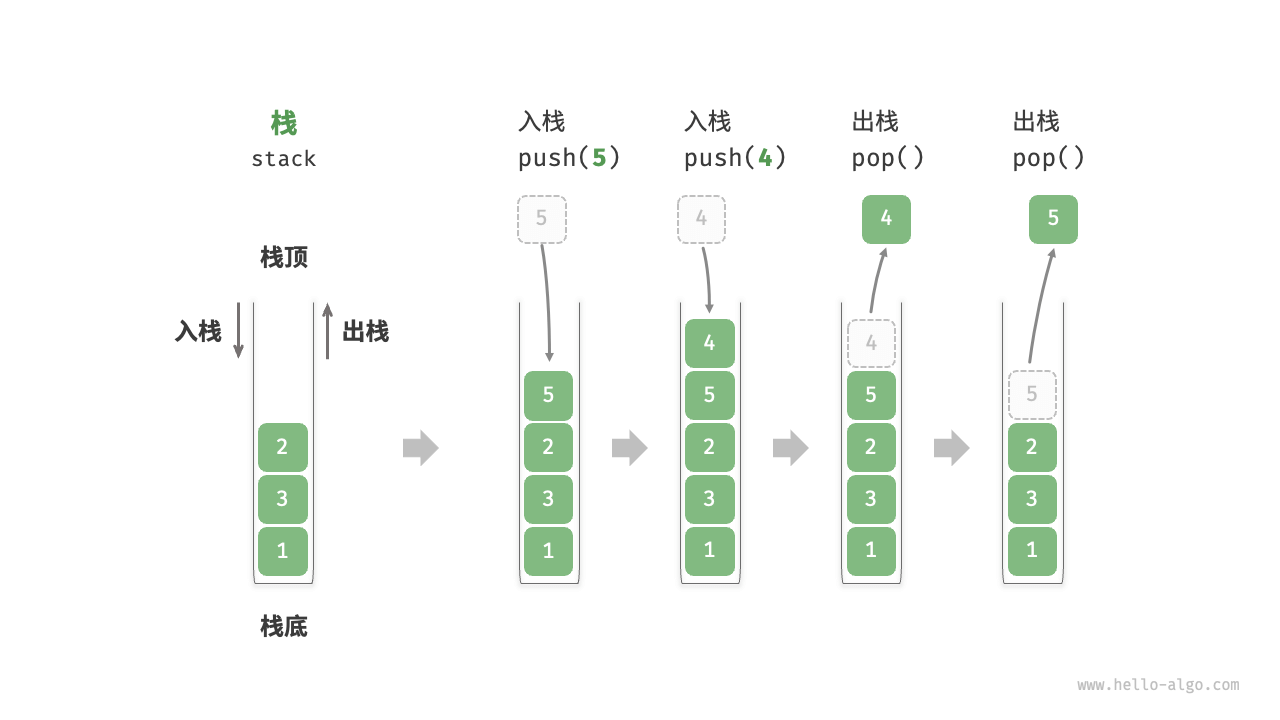
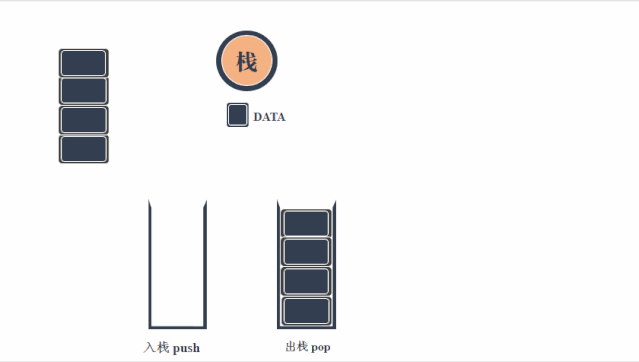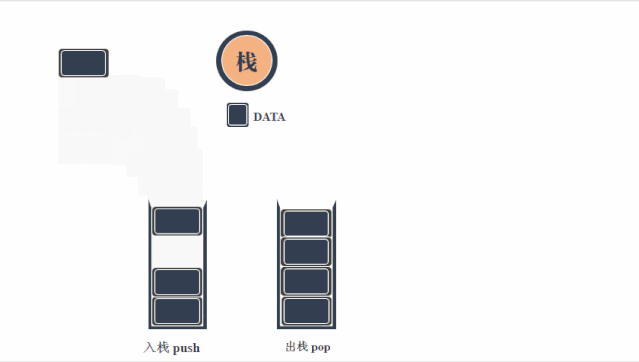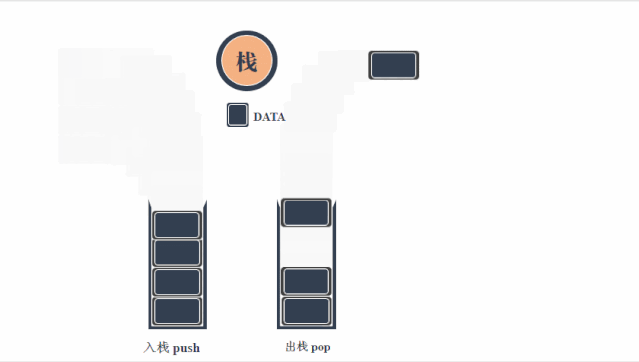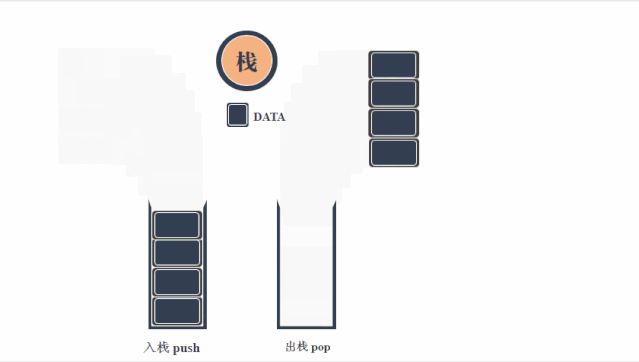
栈的操作
栈的常用操作如表所示,具体的方法名需要根据所使用的编程语言来确定。在此,我们以常见的 push()、pop()、peek() 命名为例。
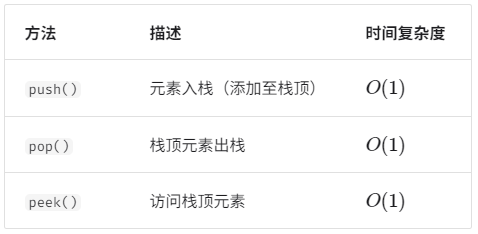
通常情况下,我们可以直接使用编程语言内置的栈类。然而,某些语言可能没有专门提供栈类,这时我们可以将该语言的“数组”或“链表”当作栈来使用,并在程序逻辑上忽略与栈无关的操作。
python
# 初始化栈
# Python 没有内置的栈类,可以把 list 当作栈来使用
stack: list[int] = []
# 元素入栈
stack.append(1)
stack.append(3)
stack.append(2)
stack.append(5)
stack.append(4)
# 访问栈顶元素
peek: int = stack[-1]
# 元素出栈
pop: int = stack.pop()
# 获取栈的长度
size: int = len(stack)
# 判断是否为空
is_empty: bool = len(stack) == 0栈的实现
栈遵循先入后出的原则,因此我们只能在栈顶添加或删除元素。然而,数组和链表都可以在任意位置添加和删除元素,因此栈可以视为一种受限制的数组或链表。换句话说,我们可以“屏蔽”数组或链表的部分无关操作,使其对外表现的逻辑符合栈的特性。
基于链表
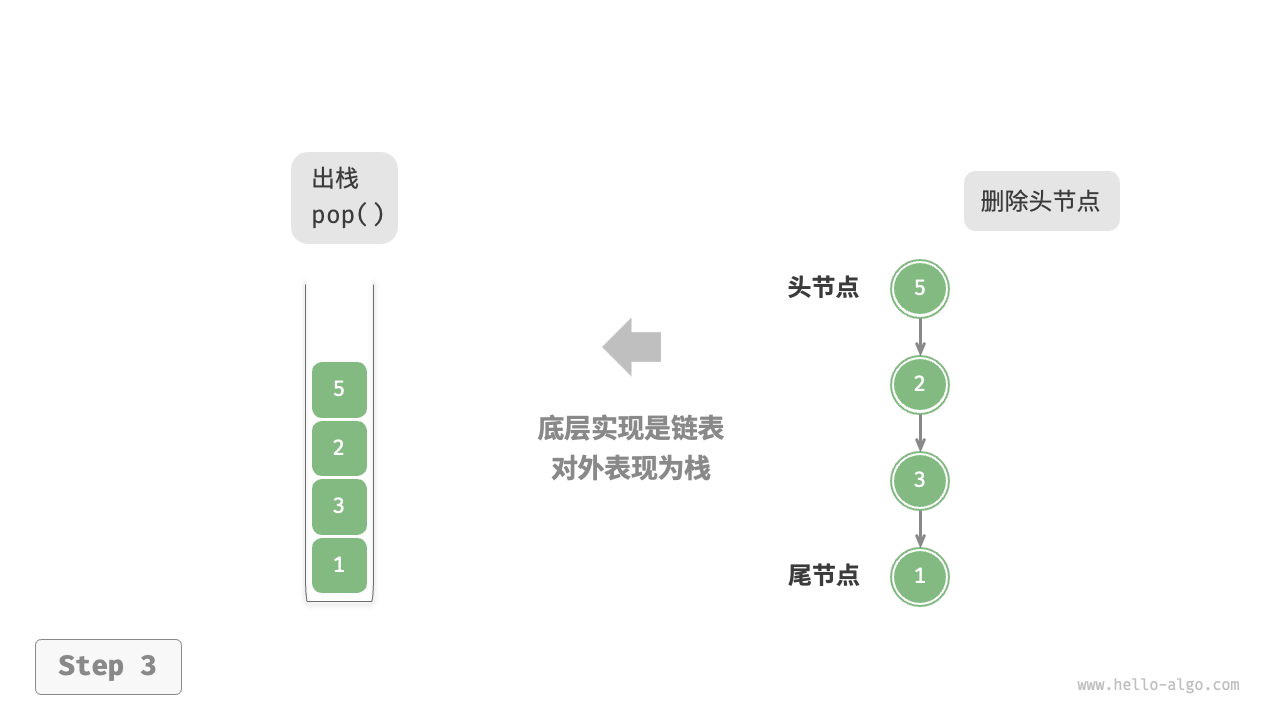
使用链表实现栈时,我们可以将链表的头节点视为栈顶,尾节点视为栈底。对于入栈操作,我们只需将元素插入链表头部,这种节点插入方法被称为“头插法”。而对于出栈操作,只需将头节点从链表中删除即可。
::: image-group
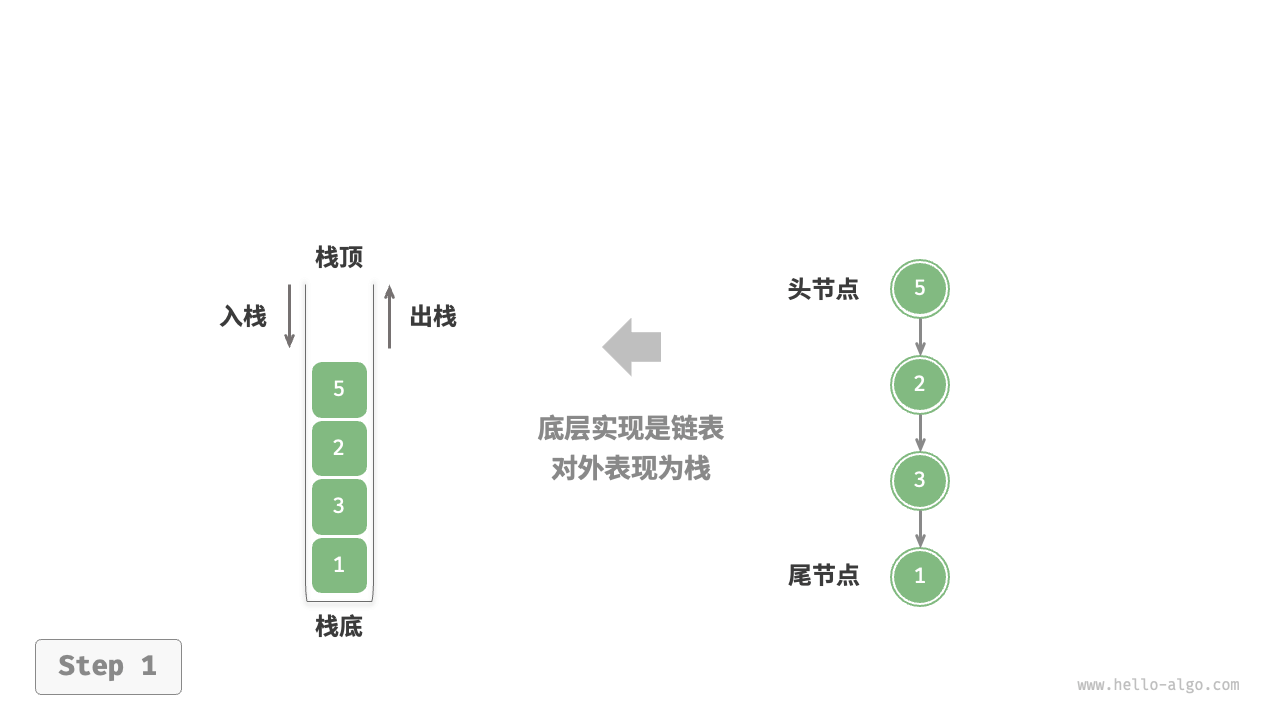
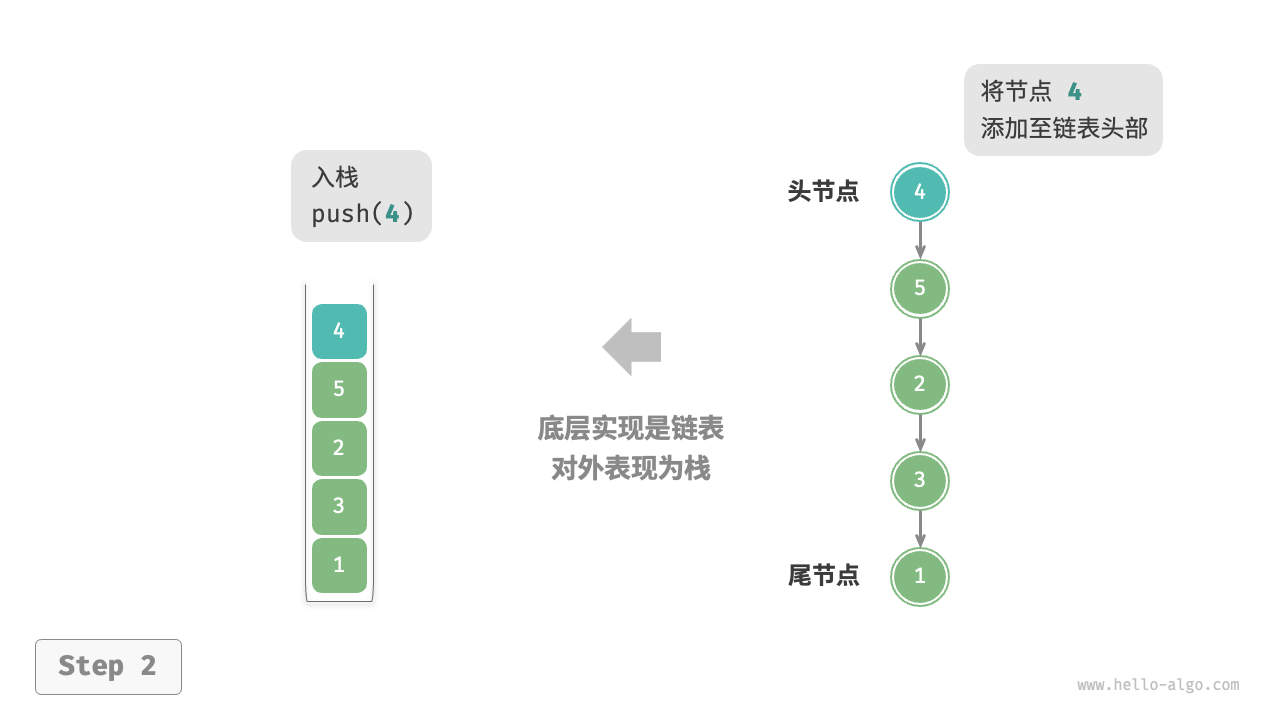
:::
以下是基于链表实现栈的示例代码:
python
class LinkedListStack:
"""基于链表实现的栈"""
def __init__(self):
"""构造方法"""
self._peek: ListNode | None = None
self._size: int = 0
def size(self) -> int:
"""获取栈的长度"""
return self._size
def is_empty(self) -> bool:
"""判断栈是否为空"""
return not self._peek
def push(self, val: int):
"""入栈"""
node = ListNode(val)
node.next = self._peek
self._peek = node
self._size += 1
def pop(self) -> int:
"""出栈"""
num = self.peek()
self._peek = self._peek.next
self._size -= 1
return num
def peek(self) -> int:
"""访问栈顶元素"""
if self.is_empty():
raise IndexError("栈为空")
return self._peek.val
def to_list(self) -> list[int]:
"""转化为列表用于打印"""
arr = []
node = self._peek
while node:
arr.append(node.val)
node = node.next
arr.reverse()
return arr基于数组
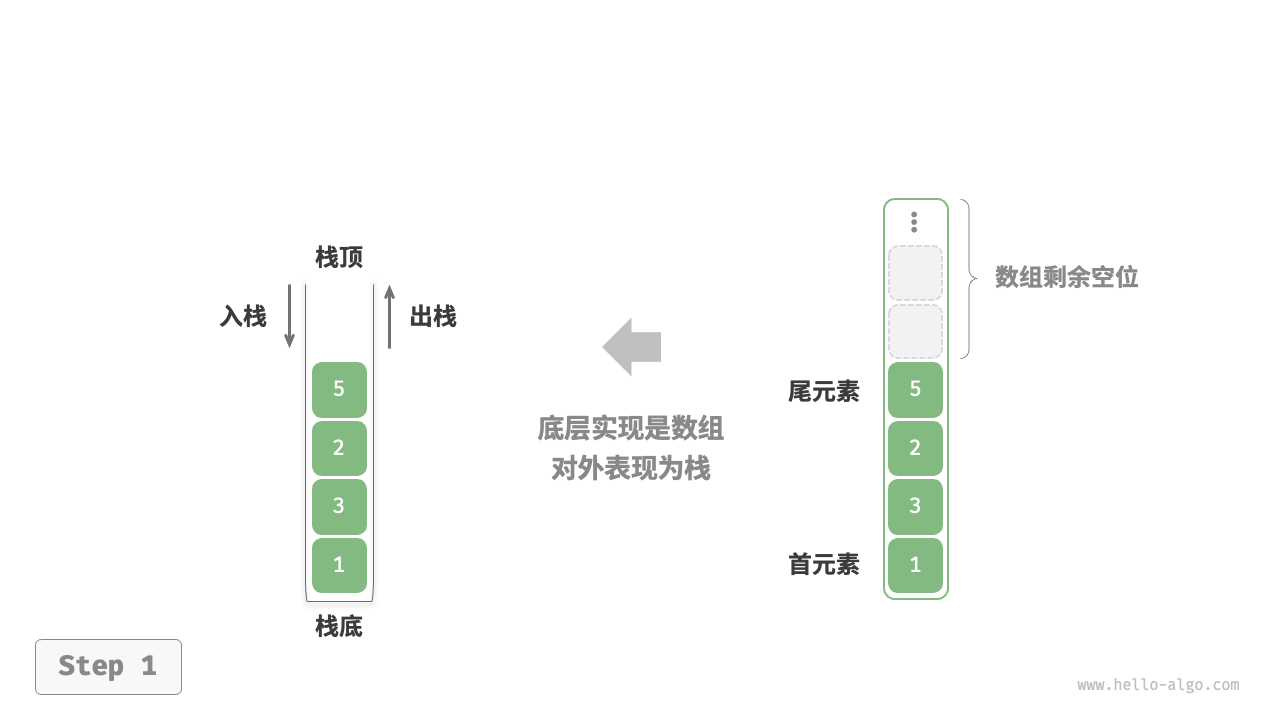
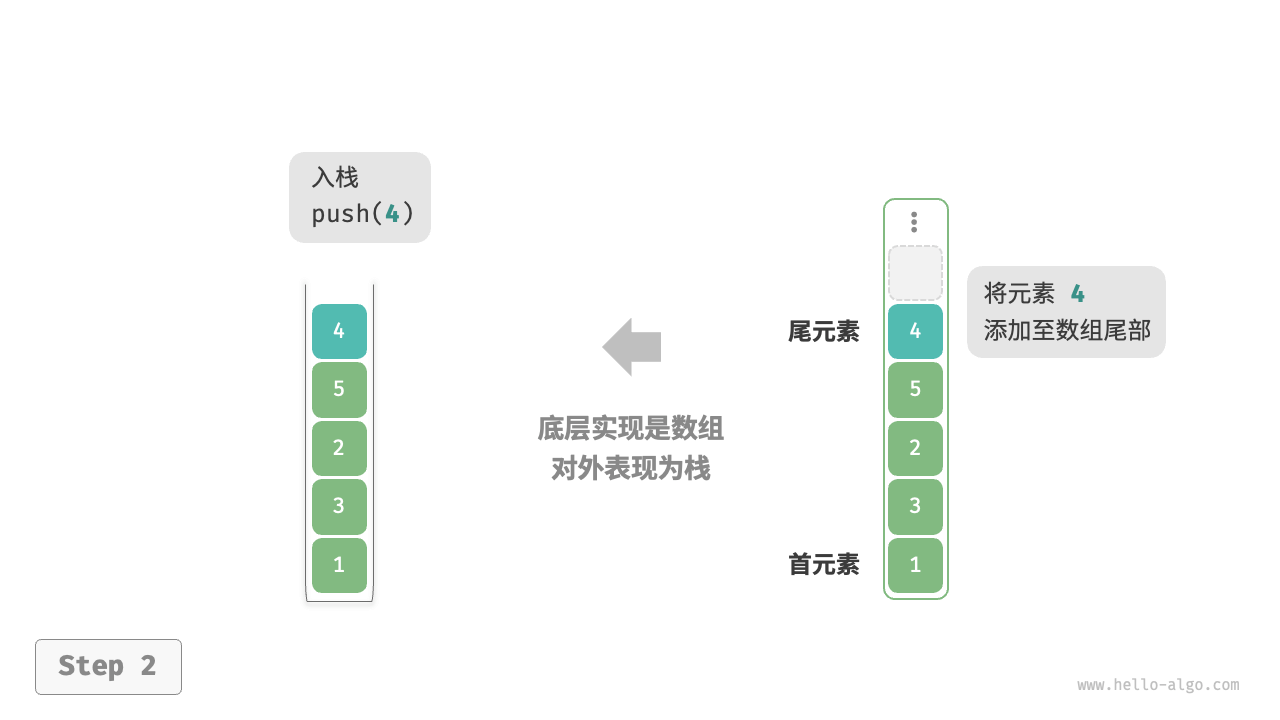
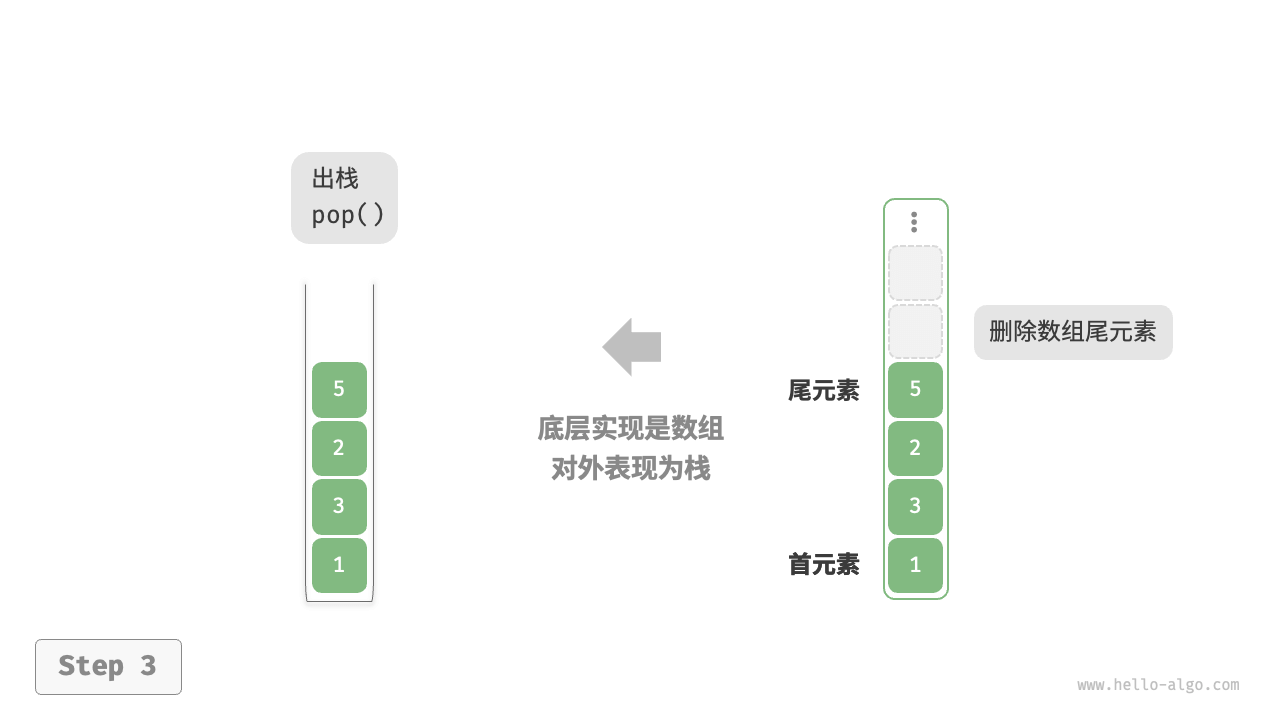
使用数组实现栈时,我们可以将数组的尾部作为栈顶。入栈与出栈操作分别对应在数组尾部添加元素与删除元素,时间复杂度都为 。
::: image-group
:::
由于入栈的元素可能会源源不断地增加,因此我们可以使用动态数组,这样就无须自行处理数组扩容问题。以下为示例代码:
python
class ArrayStack:
"""基于数组实现的栈"""
def __init__(self):
"""构造方法"""
self._stack: list[int] = []
def size(self) -> int:
"""获取栈的长度"""
return len(self._stack)
def is_empty(self) -> bool:
"""判断栈是否为空"""
return self._stack == []
def push(self, item: int):
"""入栈"""
self._stack.append(item)
def pop(self) -> int:
"""出栈"""
if self.is_empty():
raise IndexError("栈为空")
return self._stack.pop()
def peek(self) -> int:
"""访问栈顶元素"""
if self.is_empty():
raise IndexError("栈为空")
return self._stack[-1]
def to_list(self) -> list[int]:
"""返回列表用于打印"""
return self._stack效率对比
时间效率
下面是基于数组和基于链表的时间效率对比:
基于数组:在基于数组的实现中,入栈和出栈操作都在预先分配好的连续内存中进行,具有很好的缓存本地性,因此效率较高。然而,如果入栈时超出数组容量,会触发扩容机制,导致该次入栈操作的时间复杂度变为 。
基于链表:在基于链表的实现中,链表的扩容非常灵活,不存在上述数组扩容时效率降低的问题。但是,入栈操作需要初始化节点对象并修改指针,因此效率相对较低。不过,如果入栈元素本身就是节点对象,那么可以省去初始化步骤,从而提高效率。
综上所述,当入栈与出栈操作的元素是基本数据类型时,例如 int 或 double ,我们可以得出以下结论:基于数组实现的栈在触发扩容时效率会降低,但由于扩容是低频操作,因此平均效率更高。而基于链表实现的栈可以提供更加稳定的效率表现。
空间效率
下面是基于数组和基于链表的空间效率对比:
基于数组:在初始化数组时,系统会为数组分配“初始容量”,该容量可能超出实际需求,并且扩容机制通常是按照特定倍率(例如 2 倍)进行扩容的,扩容后的容量也可能超出实际需求。因此,基于数组实现的栈可能造成一定的空间浪费。
基于链表:由于链表节点需要额外存储指针,因此链表节点占用的空间相对较大。
综上所述,我们不能简单地确定哪种实现更加节省内存,需要针对具体情况进行分析。
栈的模块
在 Python 中内置的 queue 模块就可以实现一个栈:
python
import queue
# LifoQueue先进后出模式,maxsize设置栈最大长度(默认0,表示长度没有限制)。
stack = queue.LifoQueue(maxsize=4)
# empty判断栈是否为空,qsize获取栈的长度
print(stack.empty(), stack.qsize()) # 输出:True 0
# 饱和后消费
for i in range(5):
# put方法向栈中插入变量i,每次只能插一个数据
stack.put(i)
# full判断栈是否饱和
if stack.full():
# get方法从栈stack中获取数据,每次只能取一个数据
print(stack.get(), end=', ')
'''
输出:3, 4,
注释:当插入的数据达到栈长度上限后,继续插入就会发生阻塞,如果饱和后进行消费,所以不会发生阻塞,可以执行下面的print语句。
'''建议
在 stack.get()、stack.put() 方法中有 block、timeout 两个参数。其中 block 参数默认为 True,写入是阻塞式的,阻塞时间由 timeout 确定。当 block 为 False 时,写入是非阻塞式的,当栈满时会抛出 exception Queue.Full 的异常。
栈的应用
下面是栈的一些典型应用:
- 浏览器中的后退与前进、软件中的撤销与反撤销。每当我们打开新的网页,浏览器就会对上一个网页执行入栈,这样我们就可以通过后退操作回到上一个网页。后退操作实际上是在执行出栈。如果要同时支持后退和前进,那么需要两个栈来配合实现。
- 程序内存管理。每次调用函数时,系统都会在栈顶添加一个栈帧,用于记录函数的上下文信息。在递归函数中,向下递推阶段会不断执行入栈操作,而向上回溯阶段则会不断执行出栈操作。