堆栈、对象操作、可变性
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
我们所写程序一定会使用到各种数据类型,而且在程序运行的过程中一定会与内存打交道,因此理解内存管理对于编写高效程序至关重要。
堆栈
计算机内存从逻辑上可以分为如下三个区域:
- 代码区:存储程序的机器代码,包括函数、方法的二进制代码。这些代码在程序执行时被载入内存并执行。高级调度、中级调度和低级调度控制着代码区的执行代码的切换,确保程序能够按照预期的顺序执行。
- 静态数据区:存储全局变量、静态变量和常量。全局变量和静态变量在程序启动时分配内存,并且在程序的整个执行过程中保持有效,直到程序结束时才被释放。常量通常是指在程序执行过程中其值不可改变的数据,它们的存储方式可能依赖于编译器和运行时环境,有些语言中常量可能在程序启动时分配,也可能在需要时动态分配。
- 动态数据区:内部包括堆和栈。堆用于存储动态分配的内存,比如通过
new或malloc分配的对象和数据。栈用于存储函数的局部变量、函数参数和函数调用的返回地址等。堆和栈的管理由操作系统和编程语言的运行时环境共同负责。
栈(Stack)
在动态数据区中有一块区域称之为“栈(Stack)”,也叫“调用栈”,它只占整个内存中极小的一块空间,主要负责存储正在运行的程序的相关消息。可以说,几乎所有计算机程序运行都依赖于栈。其特点如下:
- 占用空间极小:栈的大小取决于系统和程序设置,通常只占用极小的一部分内存空间,比如几百 KB 或几兆字节。因为它的空间小且大小固定,这使得栈非常高效。
- 访问操作速度快:由于栈是固定的小空间,使得 CPU 访问栈的速度非常快。此外,CPU 针对栈提供了专门的指令集,而且栈操作相对简单,不涉及复杂的内存管理操作。因此,栈操作通常是 CPU 访问内存中最快的操作之一。
- 先进后出的数据结构:栈是一种先进后出(FILO,First-In/Last-Out)的数据结构,只能在一端(称为栈顶)对数据项进行插入和删除。这意味着最先插入的数据项将最后被删除,而最后插入的数据项将首先被删除。栈常用于函数调用、表达式求值、内存分配等场景,保证了程序执行的顺序和正确性。
堆(Heap)
由于栈被设计的特别小,这就注定了栈只能存放极少量的数据,如果要处理超出栈大小的数据,就要利用动态数据区中另一部分更大的一块区域叫“堆(Heap)”。堆在程序的运行中承担着重要的角色,主要用于动态分配内存以存储程序运行期间的数据。和栈一样,几乎所有计算机程序运行都依赖于堆。其特点如下:
- 与计算机内存大小无关:堆的大小和计算机的内存大小没有任何关系,它的大小是程序运行期间动态分配的。理论上只要系统中有可用的内存空间,堆就可以不断扩展,这使得堆成为存储动态分配数据的理想场所。
- 无序的内存空间:堆是一种无序的内存空间,专门用于动态分配和管理对象内存。堆的操作通常包括插入(分配内存)和删除(释放内存),在堆中分配的内存通常由程序员负责手动释放,或者由垃圾回收机制自动回收。
提醒
堆和栈在程序运行中起着不同的作用,栈通常用于存储函数调用和局部变量等临时数据,而堆则用于存储动态分配的数据,如对象、数组等。这两种数据区域的不同特性和用途,使得它们在程序设计和内存管理中发挥着各自的重要作用。
对象操作
标识(id)
在 Python 中一切皆对象,所有的对象都放在了计算机内存中,每个对象都由标识(identity)、类型(type)、值(value)这三个属性组成。可以这么说,对象的本质就是一个存储着特定值且支持特定类型相关操作的内存块。
- 标识(identity):表示对象的唯一属性。使用
id(对象)内置函数可以返回对象的标识符,这个标识符是由 Python 解释器为每个对象生成的一个唯一的整数值,用于标识对象的身份。 - 类型(type):表示对象的数据类型。使用
type(对象)内置函数返回对象的所属类型,类型可以限制对象的取值范围以及可执行的操作。 - 值(value):表示对象所的数据信息。使用
print(对象)内置函数可以直接打印值。
python
a = 3 # 注释:变量a是对象3的一个引用。
print(a) # 输出:3。注释:返回变量a所引用对象的值。
print(type(a)) # 输出:<class 'int'>。注释:返回变量a所引用对象的类型。
print(id(a)) # 输出:1531372336。注释:返回变量a所引用对象的标识符。
b = '我爱你' # 注释:变量b是对象'我爱你'的一个引用。
print(b) # 输出:我爱你。注释:返回变量b所引用对象的值。
print(type(b)) # 输出:<class 'str'>。注释:返回变量b所引用对象的类型。
print(id(b)) # 输出:46806816。注释:返回变量b所引用对象的标识符。建议
对象的标识符在程序的整个生命周期内保持不变。反过来说,当程序重新启动时,对象的标识符会发生改变,这是因为内存为程序重新分配的内存地址和空间大小都可能发生了变化。另外,对象标识符通常与对象在内存中的地址相关,但并不完全等同于底层内存的物理地址。
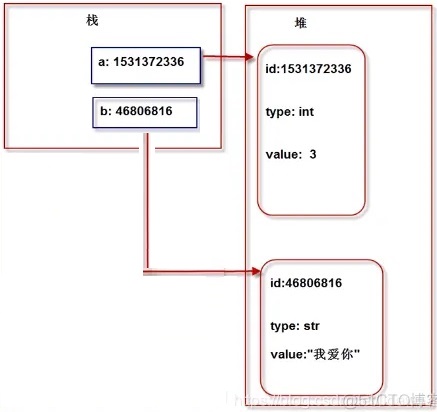
我们将上面的代码案例映射到下图,可以看到对象(无论是可变还是不可变)都存储在堆上,而栈上仅保存对这些对象的引用。当我们操作变量时,实际上是通过栈中的对象引用访问到堆中的对象本身。采用这种引用方式的原因如下:
- 动态大小: 一个对象的大小是不可估计的,或者说是可以动态变化的,而栈的空间大小是固定的,而且又是极其有限的,不适合存储动态大小的对象。而堆空间的大小可以动态调整,适合存储动态大小的对象。
- 节省空间:不管堆中对象所占空间的大小,在栈中的对象引用大小固定,通常是一个指针大小(比如 4 字节或 8 字节,取决于系统架构)。换句话说,栈中的对象引用比堆中的对象本身所占空间要小很多,这极大的节省了栈中的空间资源,也是堆栈分离的好处,使得 Python 在处理动态大小的对象时更加高效和灵活。
上面说过,对象标识符是 Python 解释器为每个对象生成的一个唯一的整数值,那么利用对象标识符,我们可以检查两个变量是否引用的是同一个对象。代码如下:
python
a = '天天开心,天天向上。'
b = '天天开心,天天向上。'
if id(a) == id(b):
print('a和b引用同一个对象')
else:
print('a和b引用不同的对象') # 输出:a和b引用不同的对象。注释:在命令行中执行该代码。重要
前面讲变量时提到,变量是某个对象的引用,也就是说变量存储的是一个指向对象的引用,而不是对象的内存地址或 id。具体来说,就是变量名在名称空间(如全局命名空间或函数/方法的局部命名空间)中绑定一个对象,当你查询变量的值时,Python 会查找与该变量名绑定的对象,并返回该对象(而不是它的内存地址或 id)。
身份(is)
上面我们通过 id 内置函数返回的对象标识符来检查两个变量是否引用的是同一个对象,其实我们在最前面学习的 Python 身份运算符 is 和 is not,它的作用就是判断两个变量是否引用的是同一个对象,其本质就是比较两个对象的标识符 id 是否相同。
python
a = 10
b = 10
if a is b:
print('a和b引用同一个对象') # 输出:a和b引用同一个对象
else:
print('a和b引用不同的对象')需要区别的是,前面我们学习了比较运算符,其中之一就是 ==,它的作用是比较两个对象的值是否相等,而 is 的作用是比较两个对象的标识符是否相同。代码如下:
python
a = 2 # 注释:变量a是对象2的引用。
b = 2.0 # 注释:变量b是对象2.0的引用。
if a == b:
print('a和b的值大小相等') # 输出:a和b的值大小相等
else:
print('a和b的值大小不等')
if a is b:
print('a和b引用同一对象')
else:
print('a和b引用不同对象') # 输出:a和b引用不同对象常量池
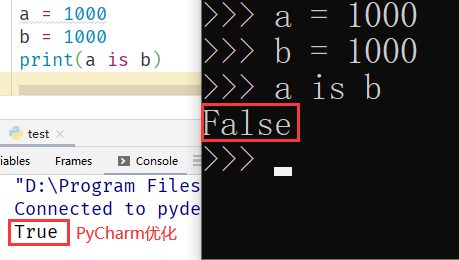
注意,以下例子需要在 Python 交互式环境下执行。因为 PyCharm 自带对变量和对象的“优化管理”,不是 Python 真正的内存管理效果。例如下图:
前面我们讲了堆中保存了对象,栈中保存了变量(对象的引用),需要注意的是并不所有的对象都放在了“堆空间”,比如说常用的字符串对象、整数对象等,它们有可能是放在一个叫“常量池”的地方,也就是上面提到的“静态数据区”。常量池分为 4 个区,具体作用如下:
- 首先了解一下“小对象整数池”,先来看下面的代码,可以看到运行结果中:在 CPython 的实现中,默认
[-5, 256]范围内,只要两个整数的值是一样,它们就是同一个对象,而大于 256 或小于 -5 的整数,就算两个整数的值是一样,它们也是不同的对象。出现这个结果的原因是 Python 出于对性能的考虑所做的一项优化,Python 认为在[-5, 256]范围内的整数对象会被频繁使用,因此将其保存到一个叫small_ints的链表中(小对象整数池)。在small_ints中每个整数对象都有独立的内存空间,在程序的整个生命周期内,任何需要引用这些整数对象的地方,就直接从small_ints中获取引用,而不是临时创建新的对象。
python
flage = 0
x = y = -7
while True:
x += 1
y += 1
if x is y:
print('%d is %d' % (x, y))
else:
print('Attention! %d is not %d' % (x, y))
flage += 1
if flage == 2:
break
'''
输出:
Attention! -6 is not -6
-5 is -5
... is ...
256 is 256
Attention! 257 is not 257
'''- 接下来是“短字符串缓存区”,如下面的例子:简单讲就是,Python 不会为相同的短字符串创建多个内存空间,而是只创建一个内存空间,但是长字符串不会如此。

- 最后是“匿名列表对象缓存区“和“匿名字典对象缓存区“,如下面的例子:没有对象引用的列表对象和字典对象会向外暴露一个内存地址,不论里面的内容怎么变,该地址不会变,所以下面的地址都一样的。但如果存在对象的引用,即非匿名对象,那么下面的地址都不一样。

垃圾回收
前面讲过 Python 内存管理是由 Python 解释器负责的,其中有一个机制叫“垃圾回收”,也就是当一个对象没有被引用时,Python 解释器将其视为“垃圾对象”。垃圾回收器会监控程序中的引用对象,如果找出不再被引用的对象,会将它们所占用的内存空间释放回内存池,以便其它对象使用。代码演示:
python
# 引入sys模块
import sys
print(sys.getrefcount('努力学习')) # 输出:2
a = '努力学习' # 注释:通过赋值变量a,增加对'努力学习'的引用。
print(sys.getrefcount('努力学习')) # 输出:3
b = '努力学习' # 注释:通过赋值变量b,增加对'努力学习'的引用。
print(sys.getrefcount('努力学习')) # 输出:4
del a # 注释:通过删除变量a,减少对'努力学习'的引用。
print(sys.getrefcount('努力学习')) # 输出:3
del b # 注释:通过删除变量b,减少对'努力学习'的引用。
print(sys.getrefcount('努力学习')) # 输出:2建议
在 Python 中,sys.getrefcount() 函数返回一个对象的引用计数,即指向该对象的引用的数量。但需要注意的是,sys.getrefcount() 本身也会创建一个对传入对象的引用,因此返回的引用计数会比预期多 1。因此,当调用 sys.getrefcount('努力学习') 时,实际上会创建一个额外的引用,所以返回值是 2。
可变性
根据对象标识符的可变性,我们还可以将对象分为:可变对象(Mutable)、不可变对象(Immutable)。
可变对象
可变对象(Mutable):在对象标识符不变的情况下,其内容可以被改变的对象。在 Python 中的列表(list)、字典(dict)、集合(set)都属于可变对象,其中赋值不会产生新的对象,而切片、拷贝之类的操作,会产生新的对象。
python
list_1 = [4] # 注释:变量list_1是列表对象的一个引用。
print(list_1, id(list_1)) # 输出:[4] 1095727791624
a = list_1 # 注释:变量list_1将列表对象的引用赋值给变量a,此过程没有新的对象产生,只是列表对象多了一个引用。
a.append(5) # 注释:变量a通过引用给列表对象增添元素。
print(a, id(a)) # 输出:[4, 5] 1095727791624
print(list_1, id(list_1)) # 输出:[4, 5] 1095727791624。注释:因为变量a和变量list_1都是引用的同一个列表对象,因此他们的输出都是相同的。
list_2 = list_1[:] # 注释:变量list_1引用了列表对象进行了切片操作产生了新对象,变量list_2成为了该新对象的一个引用。
print(list_2, id(list_2)) # 输出:[4] 871593557128。注释:这里对象标识符不一样,说明变量list_2引用的是新对象。不可变对象
不可变对象(Immutable):在对象标识符不变的情况下,其内容不能被改变的对象。在 Python 中整型(int)、浮点型(float)、布尔型(bool)、字符型(str)、元组(tuple)都属于不可变对象,其中只有赋值不会产生新的对象。
python
a = 10 # 注释:变量a是整型对象10的一个引用。
b = a # 注释:变量a将整型对象的引用赋值给变量b,此过程没有新的对象产生,只是整型对象多了一个引用。
print(a, id(a)) # 输出:10 1965911344
print(b, id(b)) # 输出:10 1965911344。注释:变量a、变量b引用的都是同一个对象,因此这里的输出和上面的输出相同。
a += 1 # 注释:变量a引用整型对象进行了算术运算和赋值运算,此过程中会开辟新的内存地址,因为整型对象是不可变的,所以在执行算术运算时会创建一个新的对象(整数 11),然后让变量a引用新的对象。
print(a, id(a)) # 输出:11 1965911376
print(b, id(b)) # 输出:10 1965911344。注释:变量a、变量b引用的是不同的对象,因此这里的输出和上面的输出不相同。