JavaScript逆向调试
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
JavaScript 简称 JS,是一种脚本语言。我们在网页里还可能会看到一些交互和动画效果,如下载进度条、提示框、轮播图等,这通常就是 JavaScript 的功劳。JavaScript 的出现使得用户与信息之间不只是一种浏览与显示的关系,还实现了一种实时、动态,交互的页面功能。例举一个引入 JS 文件的实例:在网页中,JavaScript 通常是单独的后缀为 .js 的文件形式,通过 HTML 中的 script 节点引入的。
因此,许多网站针对爬虫设置了许多的反爬措施,例如,请求头必须是浏览器,同一个 IP 不能高频率访问,各式各样的验证码等,其中 JS 加密成为了许多网站反爬的选择,理由如下:
- 通用性:JS 全称 JavaScript(虽然名称有 Java,但和 Java 没有半毛关系),是一种运行在浏览器里的前端语言,几乎所有的浏览器都支持运行 JS。
- 便捷性:JS 是在本地浏览器客户端中进行加载和解析,不会消耗服务器资源,最重要的是 JS 有改变网页内容的能力,而且能及时响应用户的操作,增加网页互动性。比如,鼠标滑过弹出下拉菜单、新闻图片的轮换等;
- 加密性:JS 可以对前端参数进行加密,以便服务器后台验证。比如,对用户名和密码进行加密,后端可以判断是否是用户的请求还是爬虫的请求。普通的爬虫只是负责拿着你给的 URL 传递一些参数来获取网页源码,它们不能运行 JS,也就无法对服务器需要验证的参数进行加密,从而导致服务器拒绝你的请求,给你返回一个不是你所期望的网页内容,这时 JS 也就起到了反爬的作用。
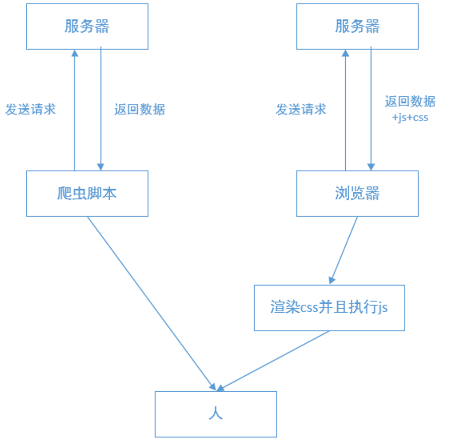
因此这张图就很好的展示了爬虫的本质,爬虫的本质就是欺骗服务器,各种的反爬手段就是增强信任的过程,最终让服务器相信是真人通过浏览器在访问网页,如果被反爬了,就是你“骗术不精”被服务器发现了。
准备工作
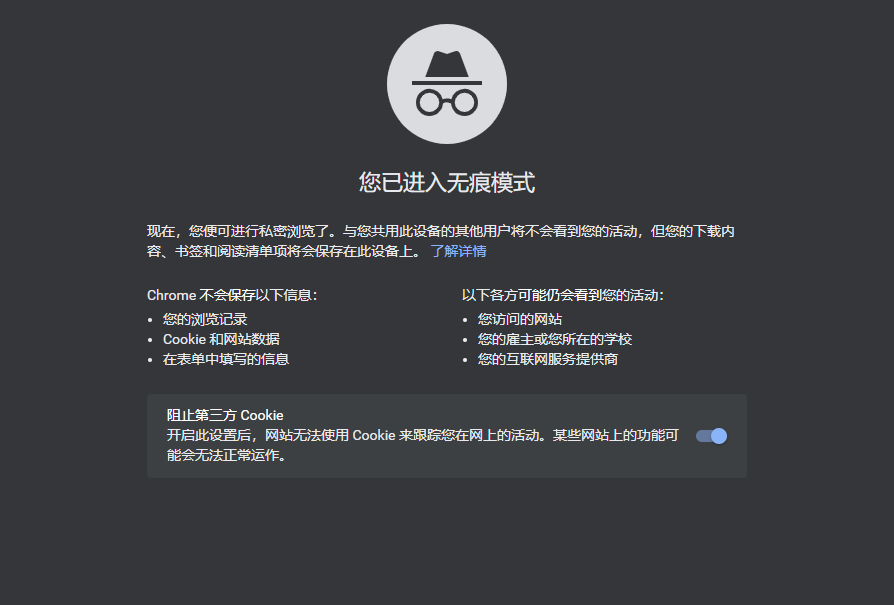
Chrome无痕
Chrome(谷歌浏览器)是我们分析网络请求的最常用的工具之一,其实 Chrome 提供了一种黑色窗口的无痕模式,这种模式下网站无法使用 Cookie 来跟踪我们在网上的活动,这一点对于我们进行分析网络很有用,因此后期我们分析爬虫请求一律在无痕模式下进行(这点很重要)。打开 Chrome 无痕模式有三种方法:
方法一:点击浏览器右上方的菜单按钮,选择“打开新的无痕窗口”。
方法二:右键单击任务栏中的谷歌浏览器,点击“打开新的无痕窗口”。
方法三:快捷键 Ctrl+Shift+N 。
提醒
Chrome 无痕模式旨在提供私密的浏览体验,它会忽略用户的代理设置,也不会使用任何代理服务器,而是直接连接到目标服务器,这样就可以确保你的浏览记录、cookie等个人数据不会被代理服务器记录。如果你希望在无痕模式中也使用代理服务器,可以通过配置系统代理来实现。
安装JS环境
首先,我们按以下步骤初始化项目:
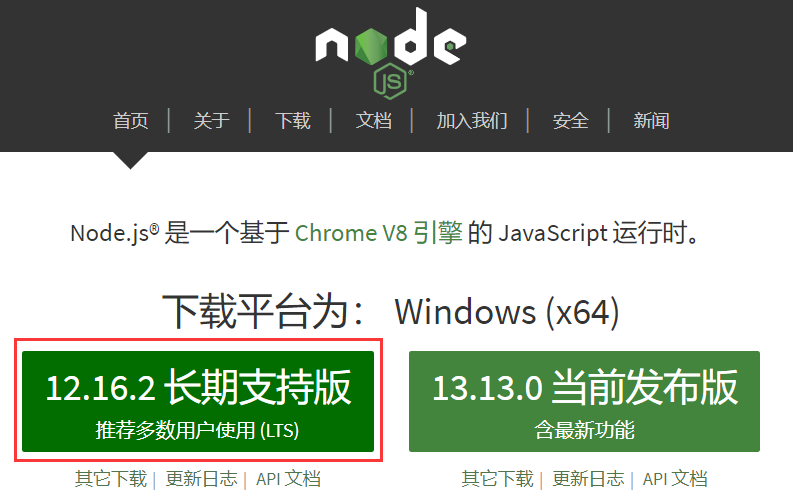
- 安装 Node.js,一个基于 Chrome V8 引擎的 JavaScript 运行环境。
- 安装好 Node.js 后,配置其环境变量。
- 修改用户变量
PATH,在其内容后面添加Node安装路径\node。 - 新增系统变量
NODE_PATH,变量值为Node安装路径\node\node_modules。
- 打开命令行,输入下面命令,出现版本号,则说明安装成功。
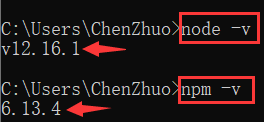
现在我们需要安装一个能执行 JS 代码的环境,推荐安装基于 Chrome V8 引擎的 JavaScript 运行环境 Node.js,进入下载链接,选择适合版本,下载解压文件,拷贝解压路径,添加环境变量,最后在命令行中输入 node --version 返回版本号就说明 Node 环境安装成功:

警告
有时候,在不同 JS 环境下执行某些 JS 代码,可能会得到不同的结果,因此建议统一使用 Node.js 为默认的 JS 运行环境。
安装JS插件
**这里安装一个能够独立运行 JS 代码的插件,前提是使用专业版的 PyCharm,如果使用的是社区版的 PyCharm,是找不到该插件的。**打开“PyCharm”——选择“File”——选择“Settings”:
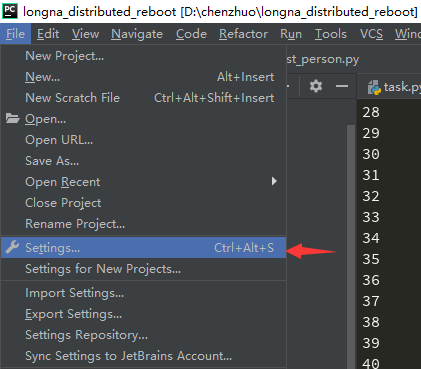
选择“Plugins”——选择“Marketplace”——输入“Node”——选择“Node.js”——点击“Install”(已经安装会显示“Installed”):
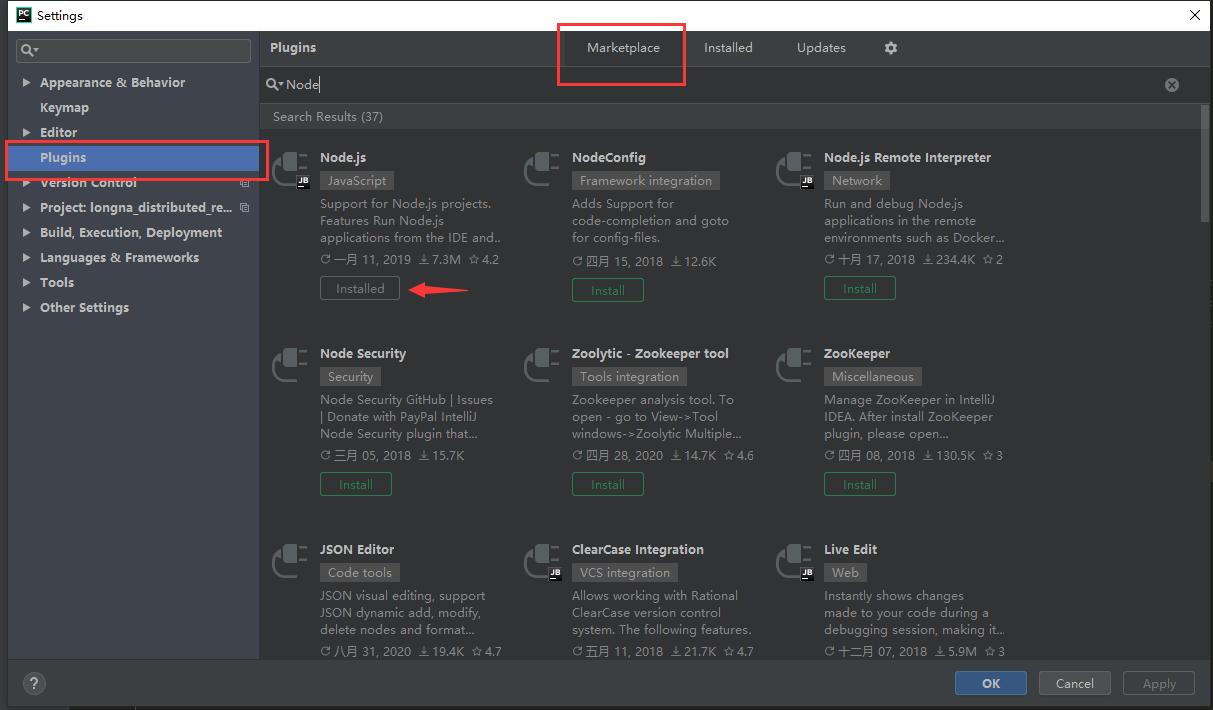
安装好了以后,我们在 PyCharm 中打开 JS 文件,右键就可以选择运行 JS 代码了:
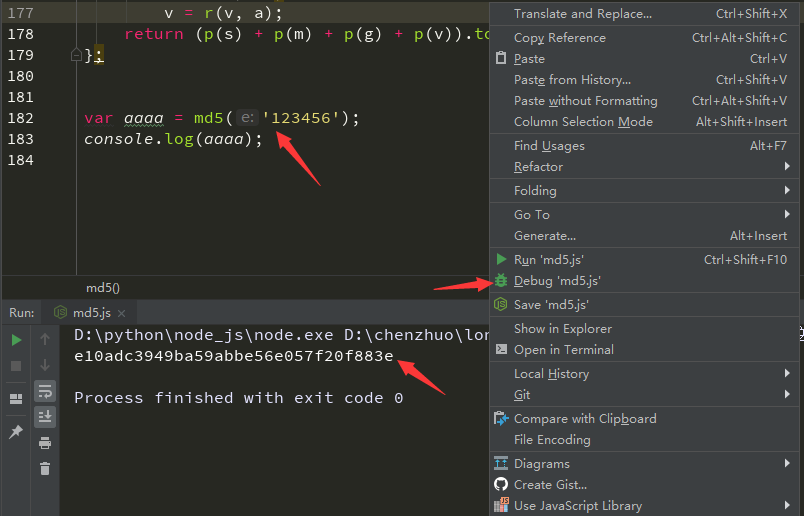
安装PyExecJS
**PyExecJS 是一个通过 Python 来调用模拟运行 JS 的三方库。**安装 PyExecJS 的命令如下:
pip install PyExecJS安装完成后需要检查一下运行环境,代码如下:
python
# 注意在导入的时候不是PyExecJS,而是execjs
import execjs
print(execjs.get().name) # 注释:只有输出Node.js (V8),才表示运行环境为Node.js,输出其他环境或者报错Could not find an available JavaScript runtime,都说明没有正确安装Node.js环境,需要重新安装。执行 JS 代码常用方法如下:
python
import execjs
# 读取JS文件,获取字符型的JS代码
with open("js_file.js", 'r', encoding='utf-8') as f:
js_code = f.read()
# 执行全部的JS代码,返回结果
js_res = execjs.eval(js_code)
# 指定JS代码中的函数,并传递参数,返回函数执行后的返回值
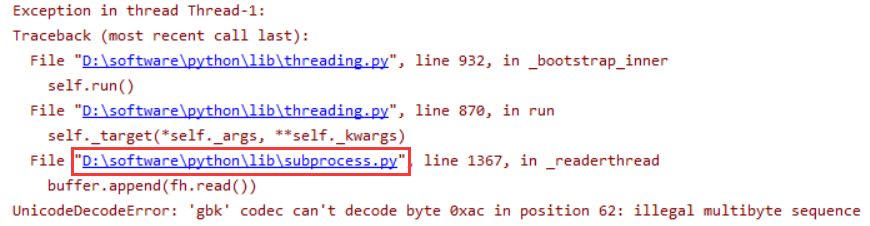
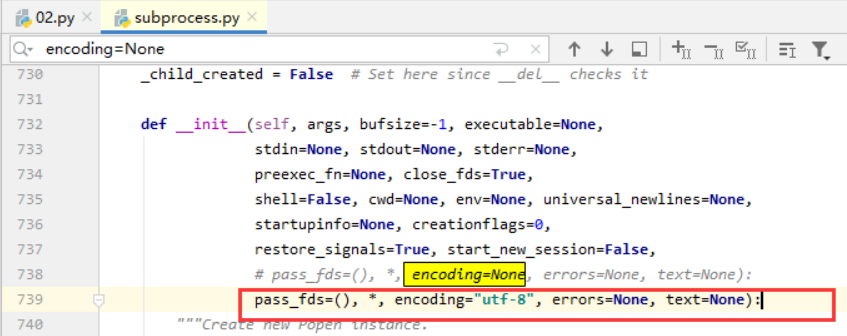
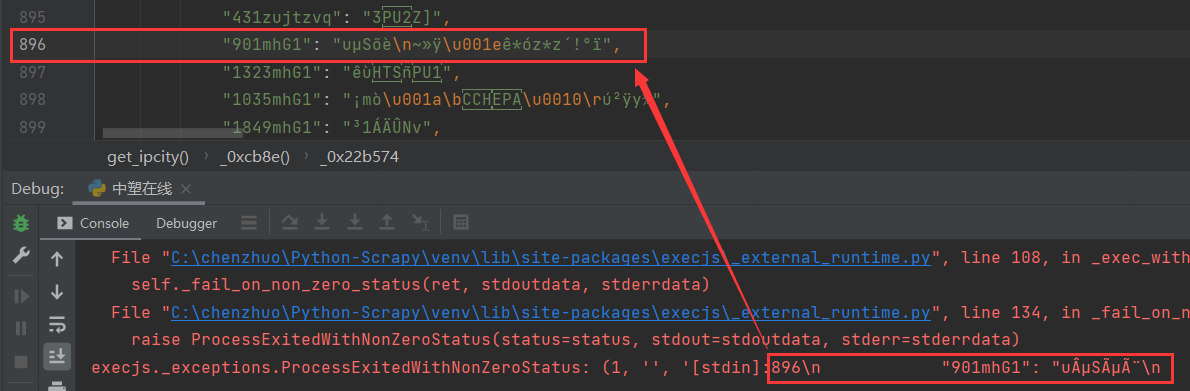
js_res = execjs.compile(js_code).call('函数', '参数1', '参数2'...)如果执行 JS 代码出现 "gbk" can't decode byte... 编码报错有两种解决方法:
- 修改源码:点击报错官方源码
subprocess.py,搜索encoding=None改成encoding='utf-8'即可成功运行;
- 不修改源码,在引入
import execjs之前,加入下面的代码,它能够展示 JS 代码中具体哪一行出现了编码错误。
python
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
# 引入execjs
import execjs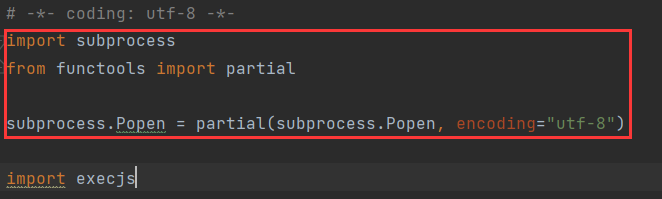
逆向核心
**JS 逆向的核心,其实就是对 JS 加密后的网页内容(POST参数、Cookie会话、网页内容等)进行解密的一个过程。**这个解密的过程大体上都是相似的:
- 访问网站,抓取数据包,并进行分析;
- 找出加密内容,全局搜索定位到 JS 代码加密的节点;
- 打断点跟栈调试,分析 JS 加密过程,在能运行 JS 代码的工具中进行逆向还原(抠代码,补环境);
- 完成 JS 逆向后,让爬虫在运行过程中加载逆向后的 JS,获取正确的网页内容。
打断点
在加密网页的逆向调试当中我们通常会使用两种断点方式:
- DOM 断点,对应执行某一个事件,断在“参数加密”之前,往下找加密点;
- XHR 断点,对应发送数据包,断在“参数加密”之后,往上找加密点;
抠代码
**首先,我们要知道有 JS 加密的网站,并不是所有 JS 代码都参与了加密,因此不用具体分析每一行 JS 代码的作用,只需要将参与加密的那一部分 JS 代码给摘取出来就可以了,俗称:抠代码。**特点如下:
抠代码流程:缺啥补啥,深度优先;见文知义,化繁为简;了然于胸,如履平地。
抠代码优势:1.执行效率高,并发能力强;2.能感受到进度(抠出一行是一行);3.只要有耐心,笨办法也能成大事。
抠代码劣势:**1.比较吃经验,只有勤学苦练才能更快;**2.若想精通则对 JS 基础要求较高(尤其是对于浏览器 API 的掌握程度);3.网站即使微调,之前抠的 JS 代码可能就会失效;4.做不到完全还原浏览器的某些值,对风控响应不够及时;
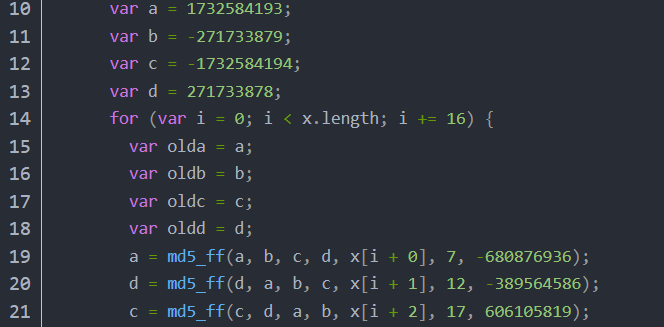
**有时候当我们代码算法抠多了以后,看到一些 JS 代码的样子,就大概能猜到使用的什么算法。**例如下图一是 MD5 哈希算法的部分 JS 源码,下图二是某乎网站部分 JS 加密代码:可以看到图二的 JS 代码和图一的 MD5 哈希源码极其相似,只是一些变量名发生,其实它实现的功能就是 MD5 哈希,于是这里我们就不用去一行行抠代码了,直接调用算法库中现成的 MD5 哈希算法,这样可以节省我们大量的时间。
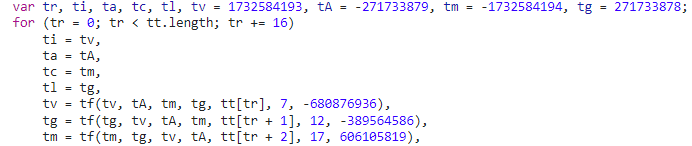
补环境
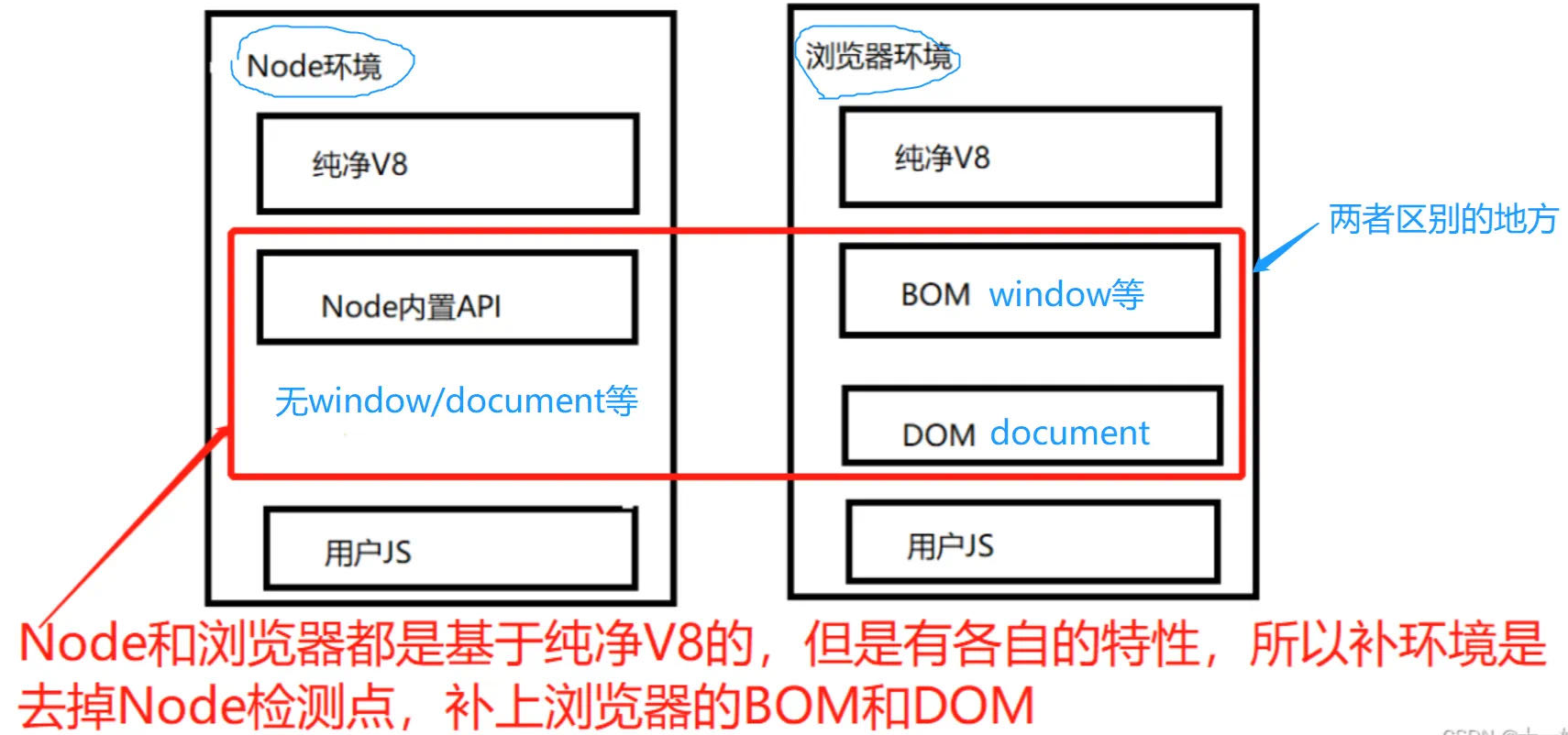
浏览器环境和我们本地的 Node 环境是运行 JS 两种完全不同的环境,平台有很多的检测点来检测 JS 是在浏览器环境下运行还是在 Node 环境下运行,所以“补环境”做的就是,让本地的 Node 环境尽可能的模拟浏览器环境。
补环境优点:1.复用性强、开发速度快;2.有现成的库可供调用(如 jsdom);3.简单网站,相对于抠代码,对熟练度要求更低;4.仅需对服务器的混淆代码做少量处理即可。
补环境缺点:**1.占用资源大,计算速度可能慢;**2.若想高并发可能需要开发多种浏览器环境,增加时间成本;3.对于极复杂的网站,可能更靠玄学;4.无法感受到进度的变化;5.若想精通则对需 Node 指纹和浏览器 API 都足够熟悉。
安全产品
基于一些法律风险的原因,任何时候我都不会教大家如何破解其他公司的安全产品,但是我们可以学习一下他们在前端的代码,看看他们前端的逻辑是怎么样的。
一线产品
一线产品(值得学习的对手):阿里滑块、Akamai、自家产品(京东虚拟机、拼多多、各种银行等金融支付接口)、谷歌验证码(含无感验证码)。
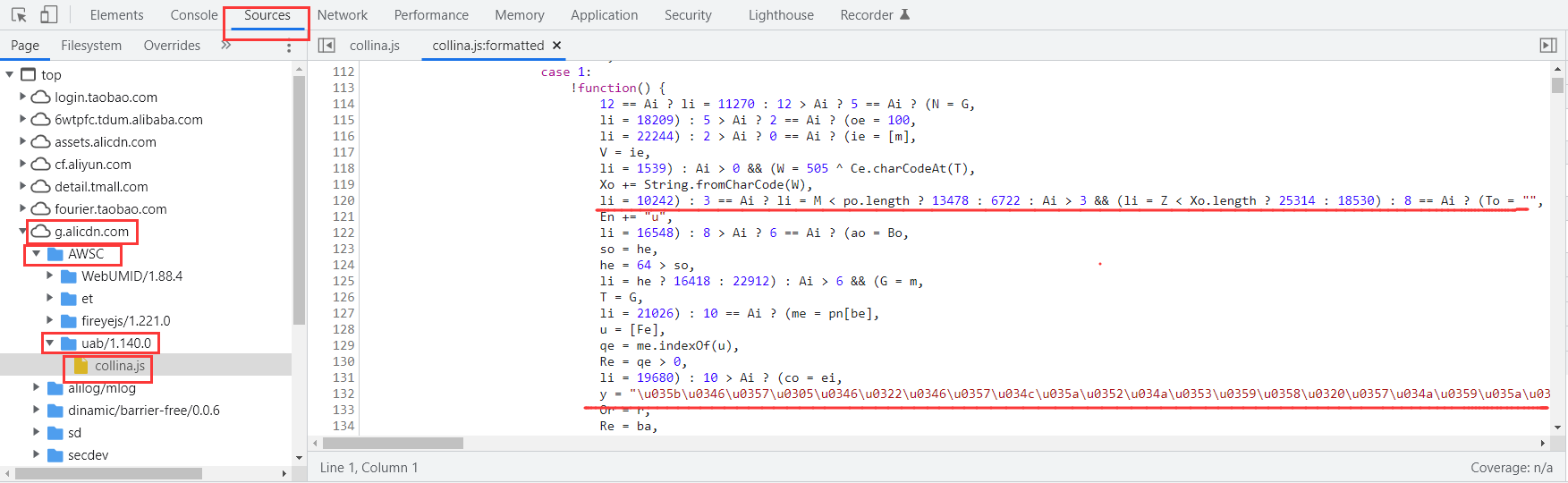
- 阿里滑块:也叫淘宝滑块,即阿里自家研发的滑块验证。当我们频繁的翻页商品评论时,就会触发该阿里对爬虫的检测,从而弹出滑块进行验证。该滑块的核心内容在Chrome开发者工具中的Sources中可以看到,其路径为:
g.alicdn.com\AWSC\uab/1.140.0\collina.js(注释:1.140.0是版本号);文件内容特点就是:使用了大量的三元表达式以及编码。
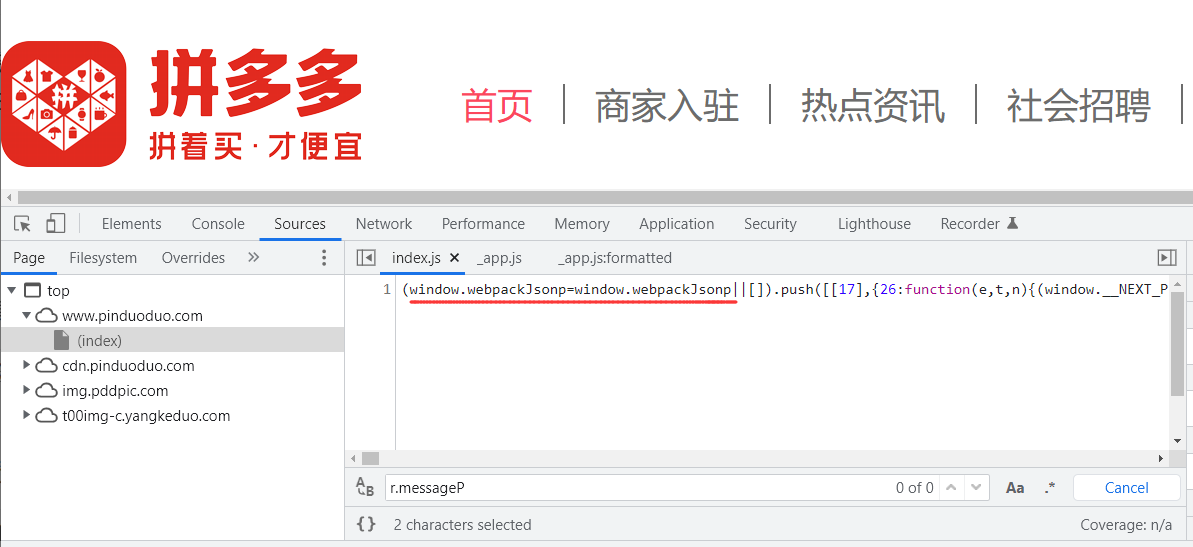
- 拼多多:拼多多商城,里面不仅使用了webpack打包,还有强混淆。现在的对抗不仅限于JS了,对风控的要求更高了,例如:高质量的代理IP、访问逻辑要求很高等。
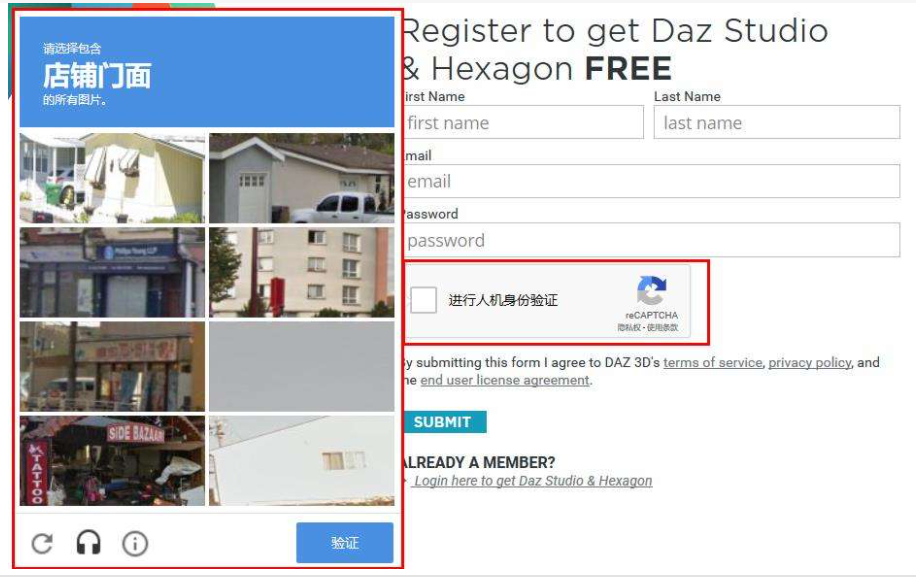
- 谷歌验证码:即谷歌自己开发的人机身份验证码,其实就是图片识别,这个难度颇高,有时候真人都不一定能通过。
- Akamai:是一款国外的反爬产品,国内产品很少使用,这里就看一下简介即可。

二线产品
二线产品(值得尊敬的对手):瑞数安全、极验、数美、创宇超防(也叫加速乐)、五秒盾(新)、易盾、顶象。
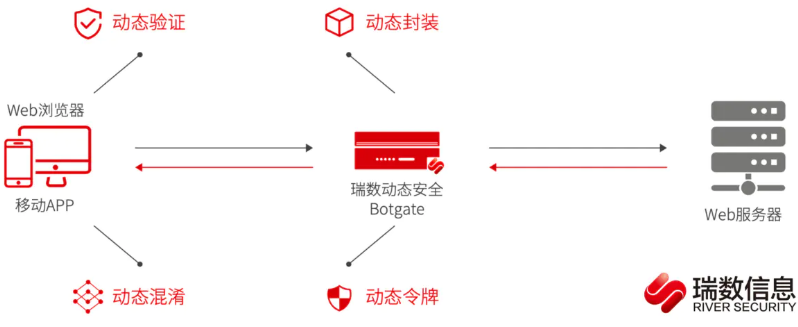
瑞数:由瑞数安全公司研发的以“动态安全”技术为核心产品,通过动态封装、动态验证、动态混淆、动态令牌等技术对服务器网页底层代码持续动态变换,增加服务器行为的“不可预测性”,实现了对网站的安全保护,其多用于政企、金融、运营商行业,曾一度被视为反爬天花板,由于产品的更新频率并不是特别高,随着近年来逆向大佬越来越多,相关的逆向文章也层出不穷,总结的经验让后来人少走了不少弯路,真正到了人均瑞数的时代了,后面我们也会讲解。
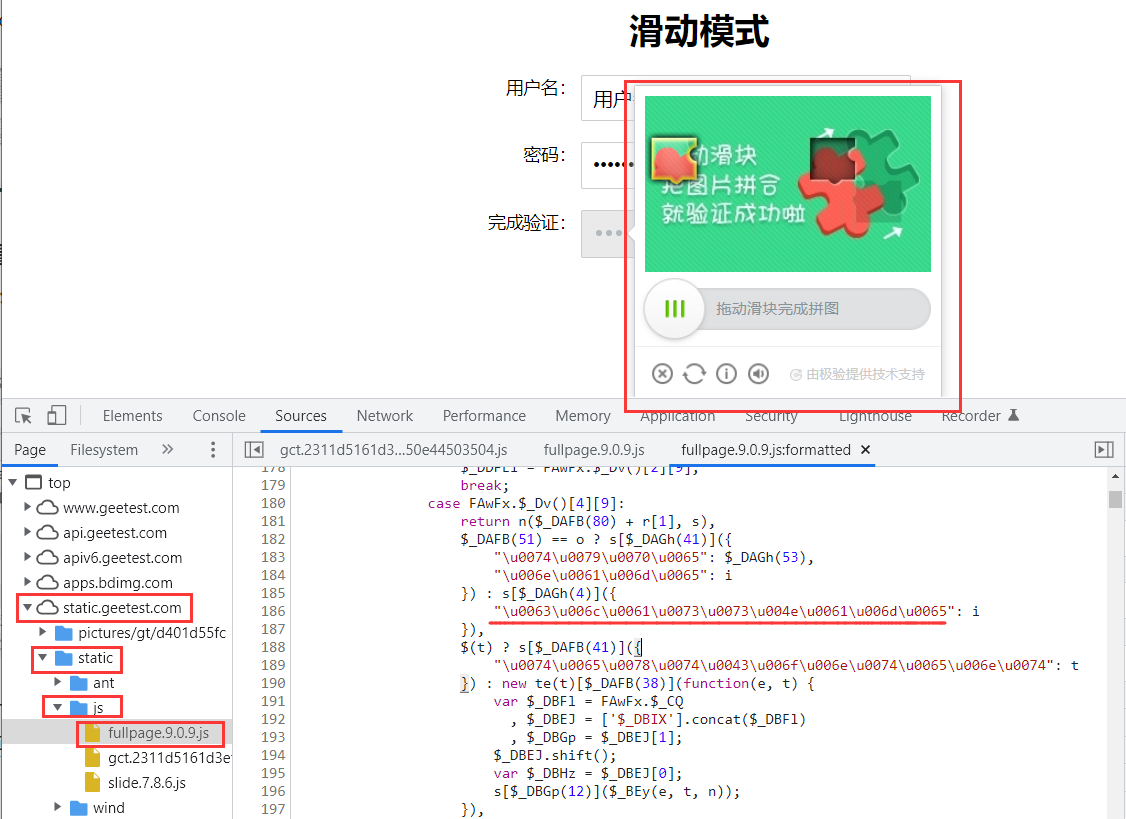
极验:是一家专门做反爬验证的公司,主要的产品之一就是缺口滑块验证码,使用 Selenium 驱动浏览器是可以通过的,但这种方式效率低下,还有一种方法效率更高的方式就是通过 JS 来通过。验证码的主要文件路径:https://static.geetest.com/static/js/fullpage.版本号.js;文件内容特点就是:许多值被编码成了 \u**** 这样的形式。
数美:更新频率很高的验证码,基本一天一改。主要文件路径:https://castatic.fengkongcloud.com/pr/v1.0.3/smcp.min.js ,文件内容特点就是长的很像 ob 混淆。
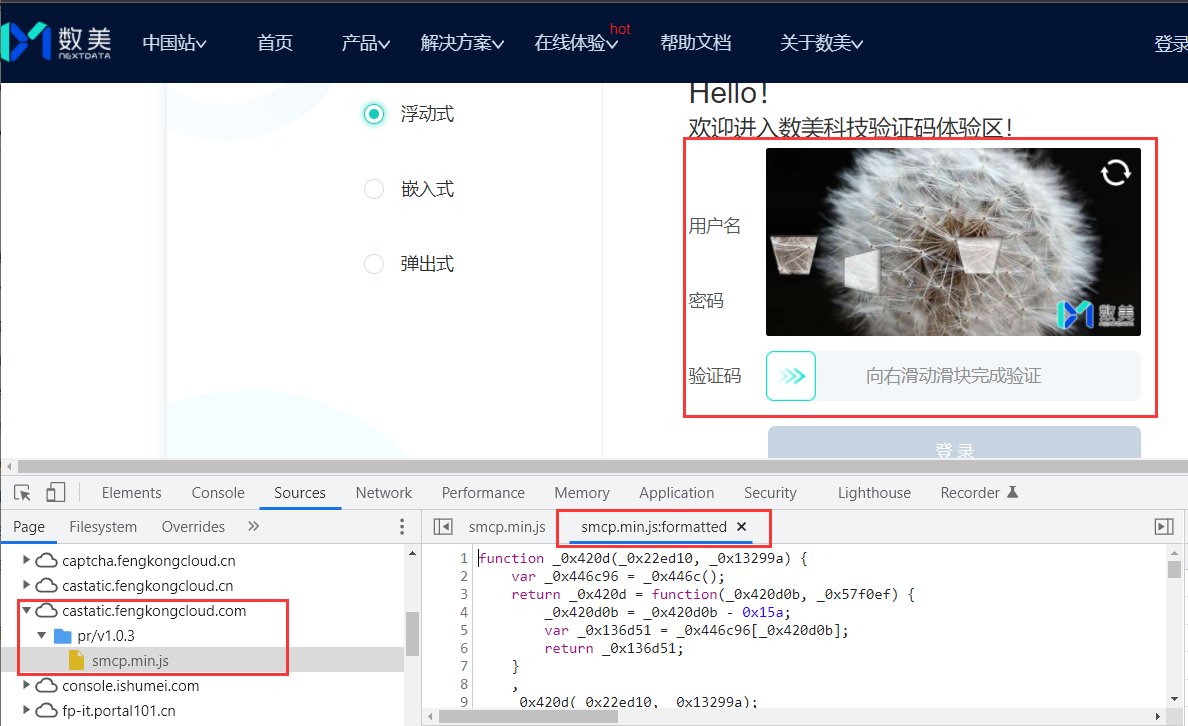
创宇超防(也叫加速乐):**这里首先解释一下为什么叫加速乐,其原因就是设置的Cookie字段当中带有 jsl 字符串,相当于是它的一个特点。**里面有三层访问逻辑,但都不难,特色是一个纯动态的访问过程,后面会讲解。
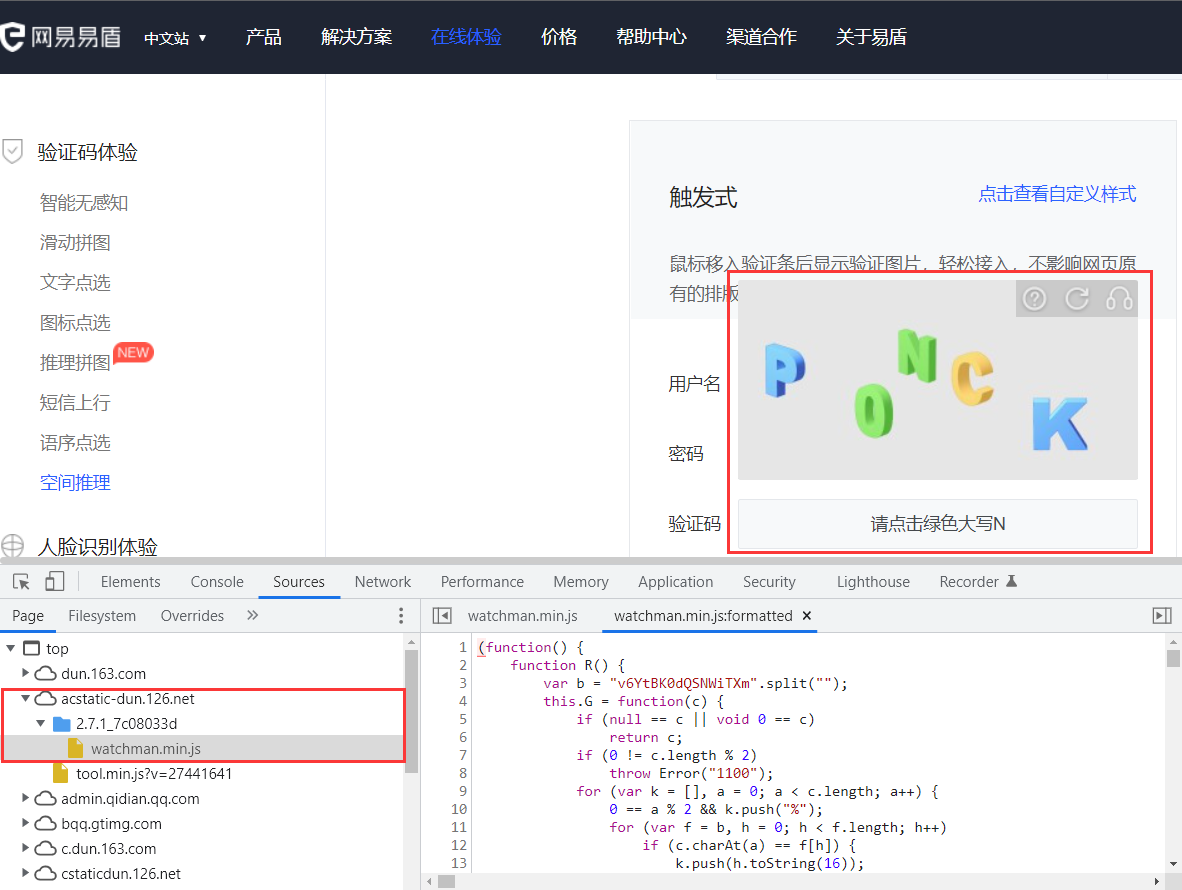
网易易盾:这个是网易公司自己旗下的验证码产品,这个验证码其实也不太好处理,有的甚至包含空间推理。主要文件路径:https://acstatic-dun.126.net/2.7.1_7c08033d/watchman.min.js
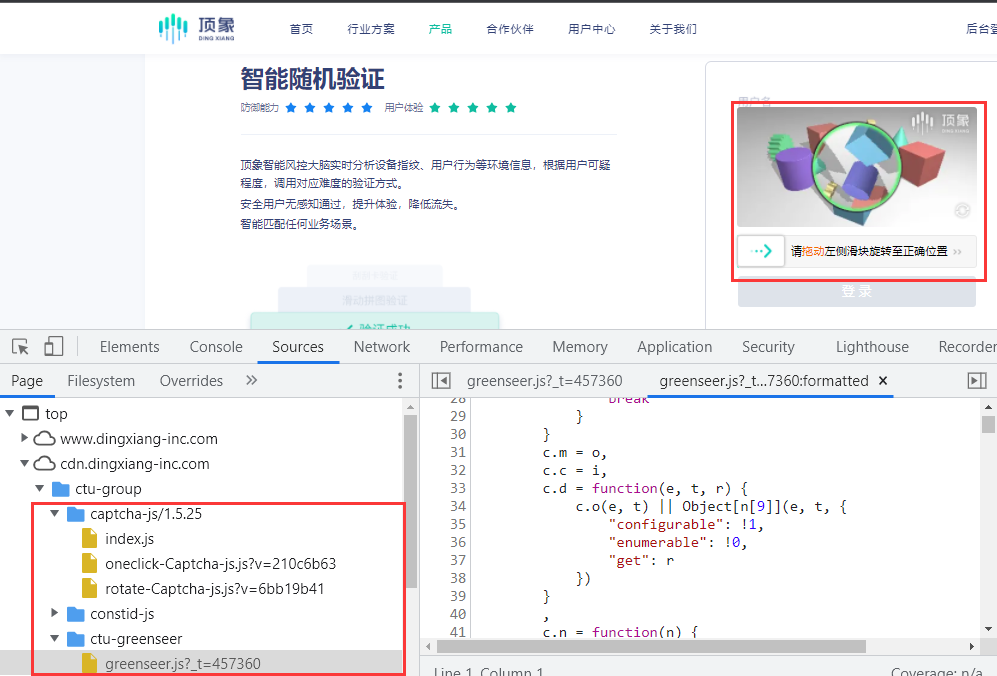
顶象:也是一款验证码产品,且更新频率很高几乎也是一天一变,对抗的话也是一个长期对抗的过程。
三线产品
三线产品(多数为开源框架/混淆了,不能叫产品,这个后面会仔细讲):ob 混淆系(obfuscator.io、sojson v5.0 v6.0、JShaman)、jsfuck、JJEncode、AAEncode、eval 类等,还有一些容易被误认为是产品,但是实际上是前端框架的东西:webpack、vue、react、angular 等打包后(实际上有些也是基于 webpack),后面都会讲到的。