JS混淆
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
服务器接收 JS 加密参数或返回 JS 加密数据,就一定会把 JS 文件给到客户端执行,所以客户端一定是可以看到 JS 代码。但安全公司,为了防止 JS 代码被他人使用或分析,会对 JS 的代码进行混淆,就是在不改变 JS 代码逻辑的情况下,对变量名称、函数名称等进行改变,让 JS 代码的阅读性变得很差,代码混淆越厉害,还原的难度就越高,以此来达到保护代码的目的。
混淆简介
ob混淆
ob混淆:**[全称是 obfuscator,它是一款免费、开源的 JavaScript 混淆工具,用以保护你的核心 JS 代码不轻易被破解,是目前常见的混淆之一。**代码经过 ob 混淆后的代码由五部分组成:
- 第一段(特征):第一行可以看到明显的一个数组;

- 第二段(特征):通常会有一个数组移位方法(有内存泄露风险、建议不格式化);

第三段:解密函数(有内存泄露风险、建议不格式化);
第四段:实际代码+控制流平坦化(整体ob的强度几乎完全取决于这段的代码强度,这里面是加密前的逻辑);
第五段:控制流平坦化+无限debugger自执行函数+死代码注入。一般情况下不会有业务逻辑
反混淆
针对混淆的 JS 代码,我们有四种处理方法:
- 硬刚混淆的 JS 代码,混淆的 JS 代码也是可以执行的代码,因此我们可以通过调试一步步还原执行流程,只不过这个过程比较艰辛,会掉不少头发;
- **使用反混淆的线上工具(地址:http://tool.yuanrenxue.com/deobfuscator)**,通常反混淆的效果不理想,如果混淆的 JS 代码中多了些空格、分号、冒号是反混淆不了的,另外如果 JS 代码比较多,反混淆的时间也会比较长。
- 使用 AST 反混淆 JS 代码,AST(Abstract Syntax Tree),中文抽象语法树,简称语法树(Syntax Tree),是源代码的抽象语法结构的树状表现形式,树上的每个节点都表示源代码中的一种结构。语法树不是某一种编程语言独有的,JavaScript、Python、Java、Golang 等几乎所有编程语言都有语法树。通过 AST 解析,我们可以像童年时拆解玩具一样,深入了解 JS 这台机器的各个零部件,然后重新按照我们自己的意愿来组装,所以不要问,ob 混淆、sojson 如何破解,这些东西只是一层壳,破解强度完全取决于网站作者写的代码强度,但如果你掌握了 AST,将这些代码进行还原,则可以大大降低硬刚 JS 代码的难度,非常的nice!
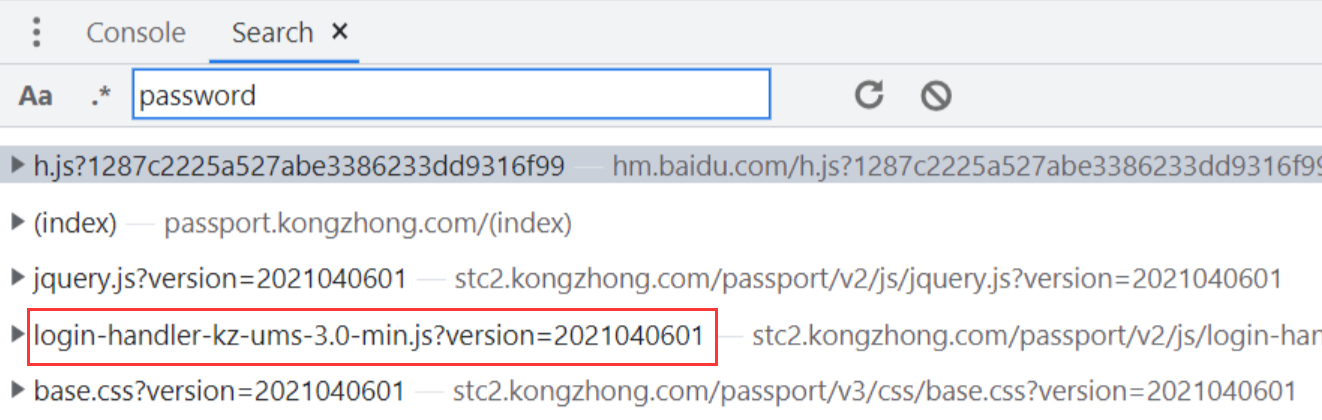
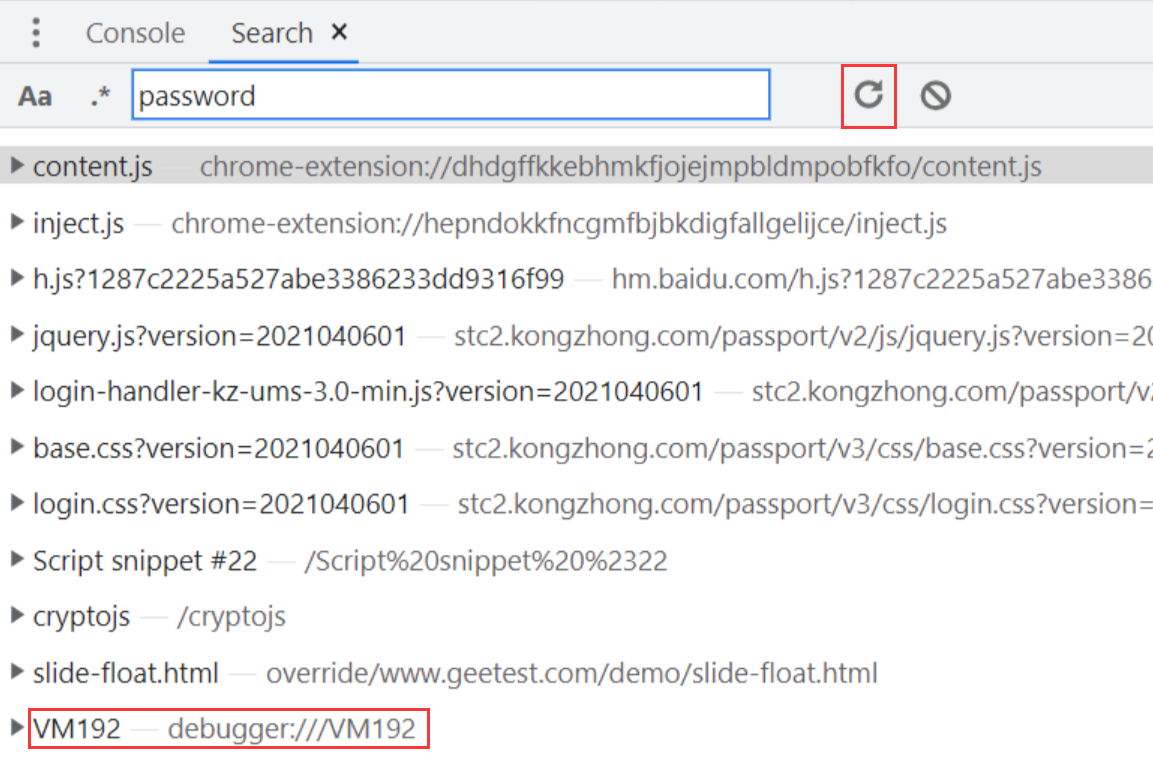
- **使用浏览器自带的设置,可以一定程度的反混淆。**先来看看没打开设置之前的状态,全局搜索加密字段
password结果如下:只有login-handler-kz-ums-3.0-min.js文件是最有可能与加密字段password相关的。
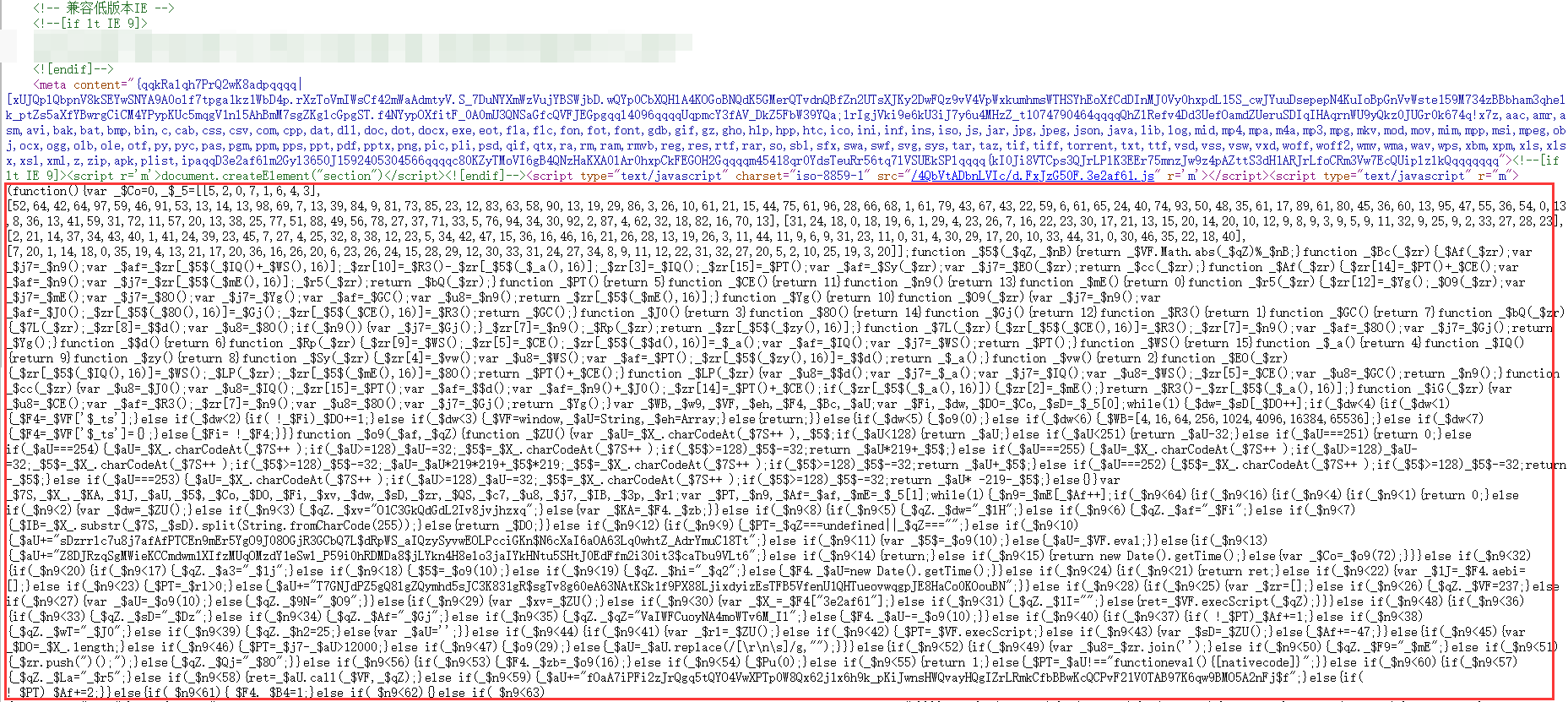
但是点开后发现是 eval 函数和一段混淆的字符串,这种混淆后的字符串,被执行后,会生成一个虚拟文件(VM + 数字结尾),此时我们通过全局搜索也是搜索不到的。

现在我们打开浏览器的设置,流程如下:开发者工具——Sources——Settings——Preferences——打勾”Search in anonymous and content scripts“选项(在匿名脚本和内容脚本中搜索,此时就会搜索所有已加载的脚本)。
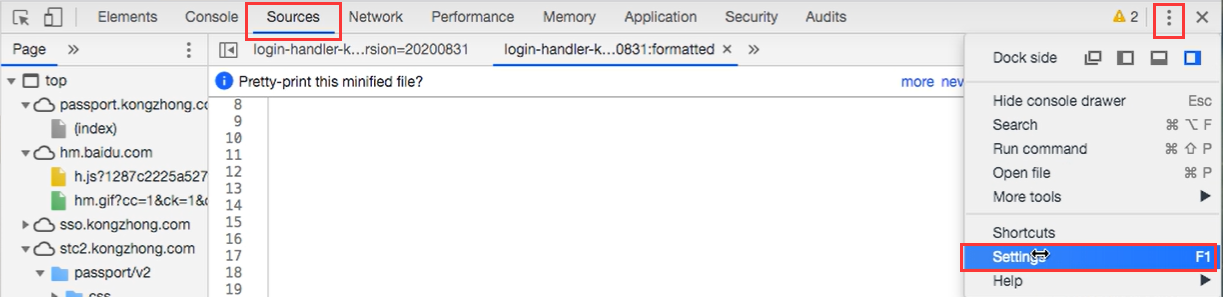
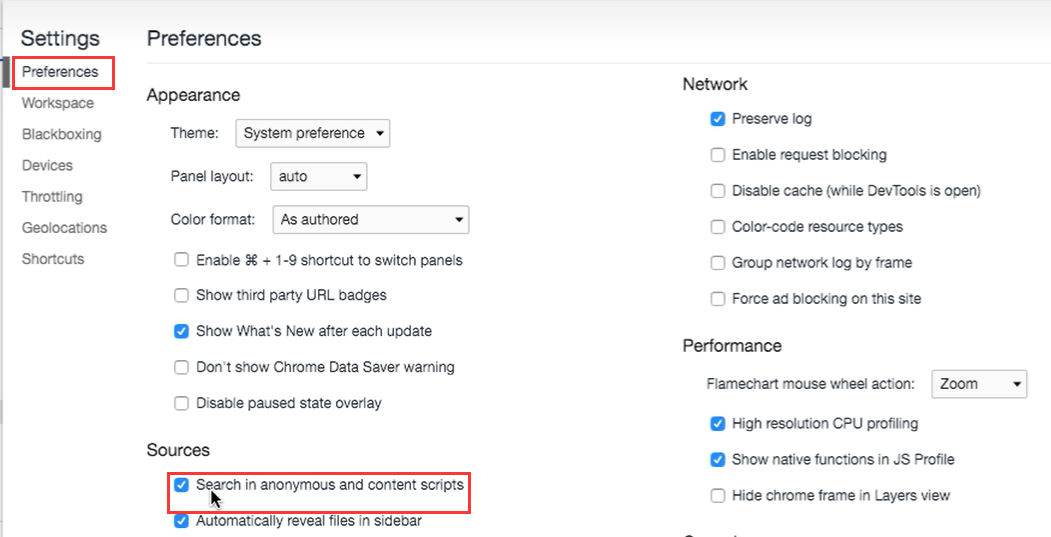
设置好以后,再次进行关键字的全局搜索,会多出几个文件,其中就包括 VM192 文件,里面就是执行 eval 后的虚拟文件的代码,这样可以一定程度上的反混淆:
猿人学第1题
题目难度:简单
进入题目后按 F12 打开开发者工具,出现 setInterval 定时器函数,直接禁用断点,然后就可以继续执行了,F5 刷新一下:
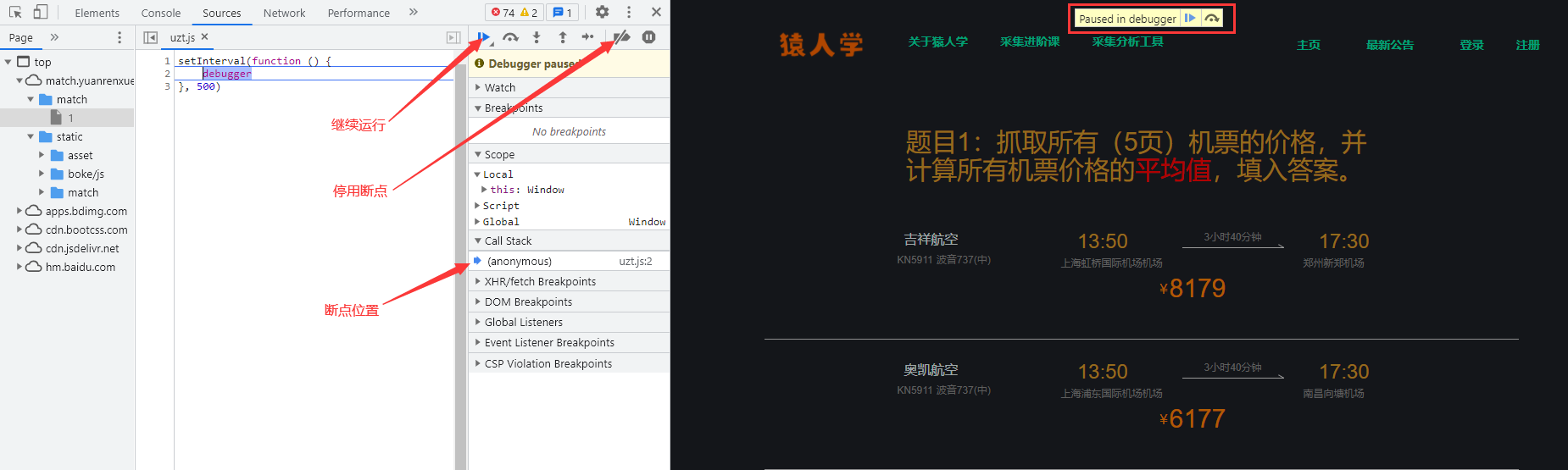
但为了后面打断点不受 debugger 影响,我们还需要在 debugger 这里打断点,然后在蓝色断点位置,点击鼠标右键,选择 Edit breakpoint:
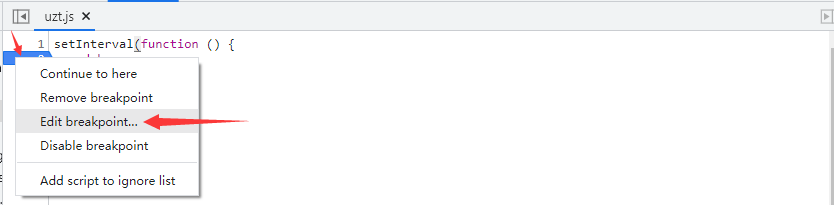
输入属性 false:

蓝色断点变黄:

定位到网页的数据来源:
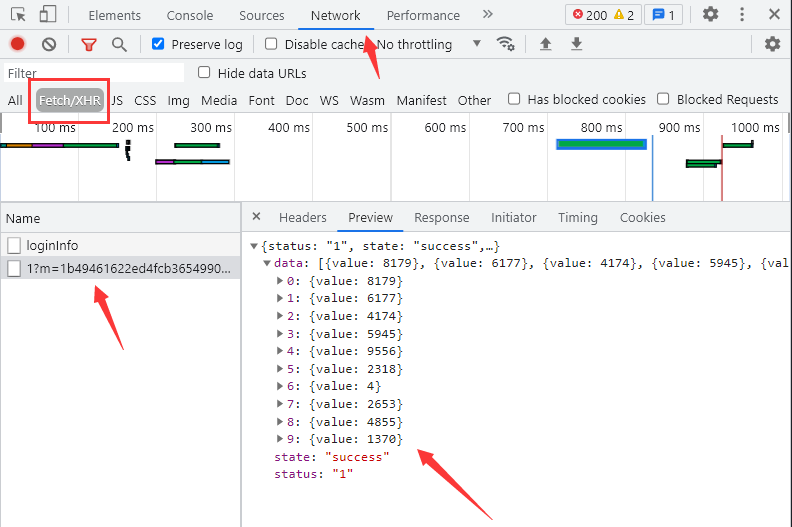
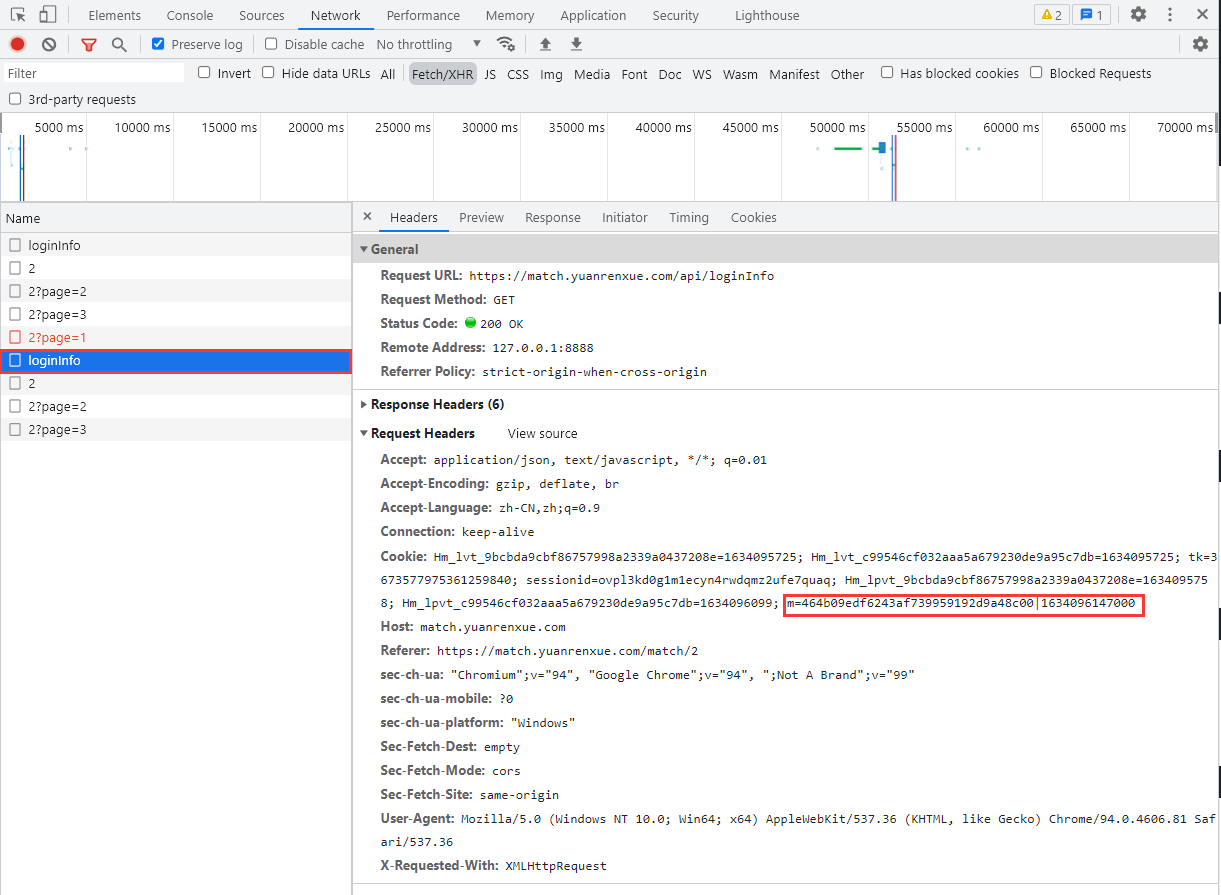
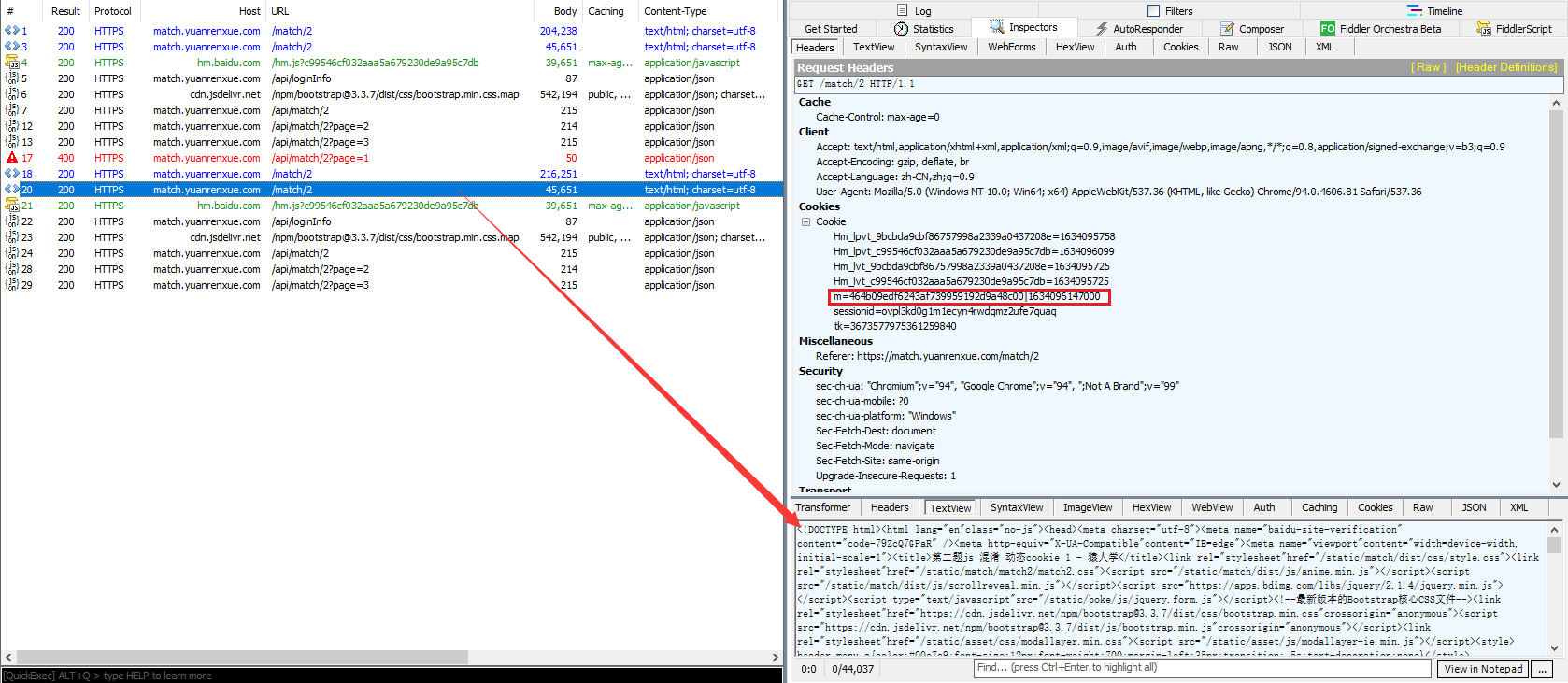
查看请求头和请求参数,总体上没有什么特别,但有一个参数m是加密的,结合经验判断m的值组成形式为:加密参数丨时间戳
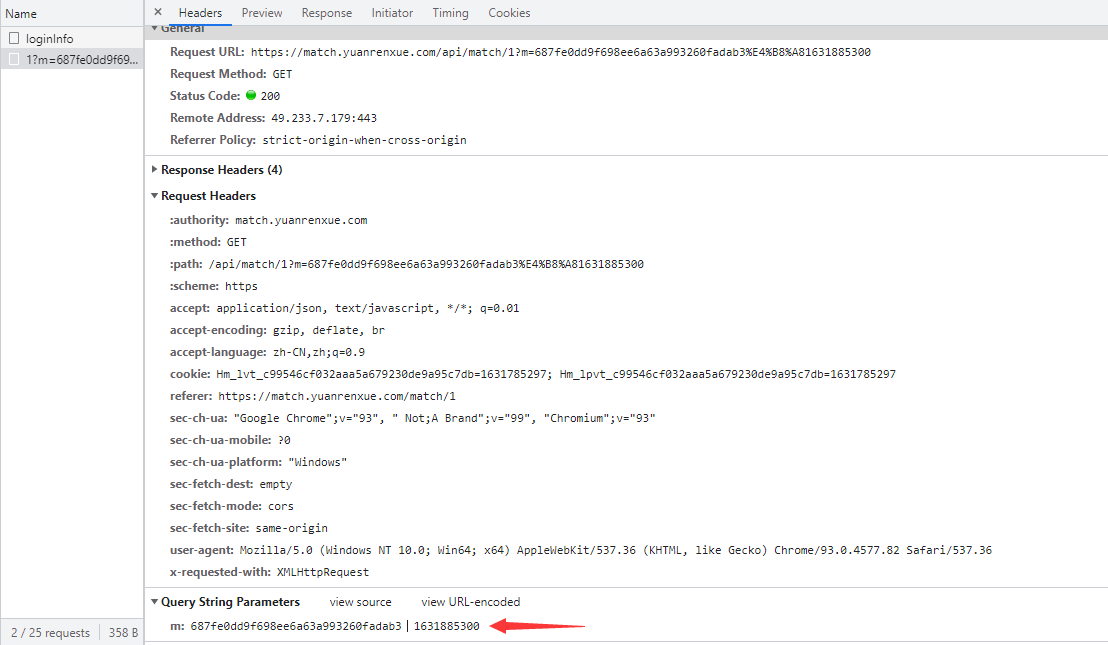
接下就是定位加密参数的生成方式,点击左侧的 Initiator 选项,它主要是标记请求是由哪个对象或进程发起的(请求源),重点关注里面的 request 请求,显示从一个名称为 VM73951 的文件的第 6 行代码发送了当前请求,点击后面的地址:
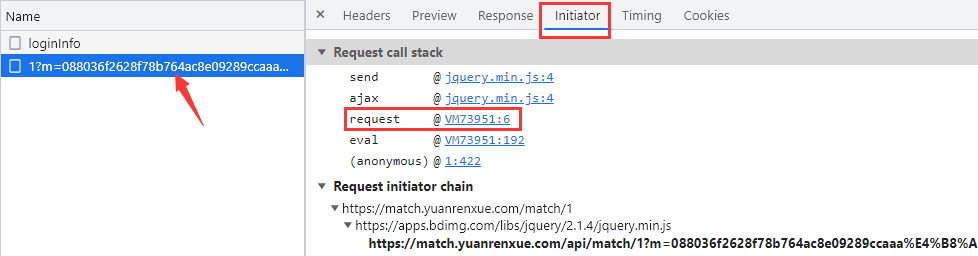
跳转到了该文件的第 6 行,可以看到文件的内容不那么直观了,代码进行了一定的编码,熟悉字符编码格式的人就能看出来,这其实就是将一部分字符进行了 utf-8 编码,另一部分字符进行了 unicode 编码。
好在网上有对这类简单的编码还原的工具(地址:http://tool.yuanrenxue.com/deobfuscator),我们可以将编码内容直接粘贴过去进行还原,得到更加容易阅读的代码:
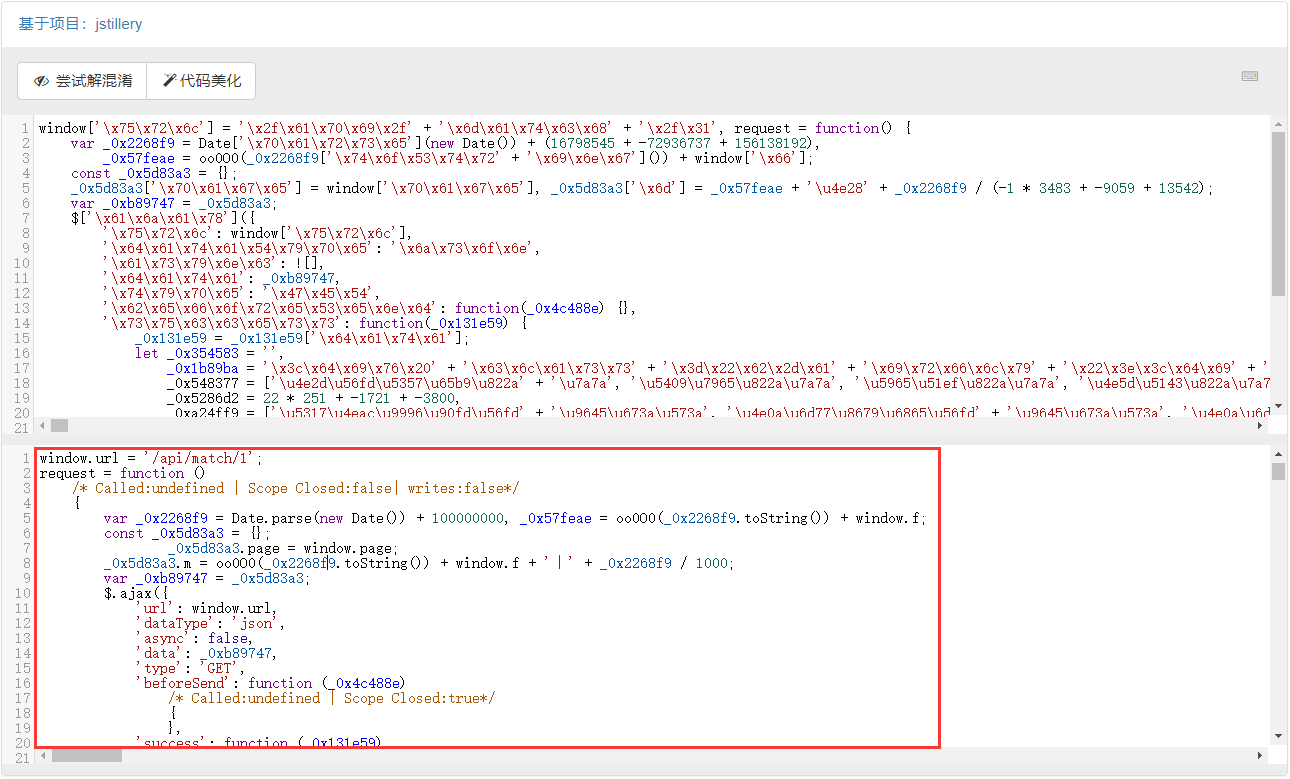
其实看着还原后的代码格式化后,进行折叠,可以看到两部分几乎一样的 Ajax 请求代码:
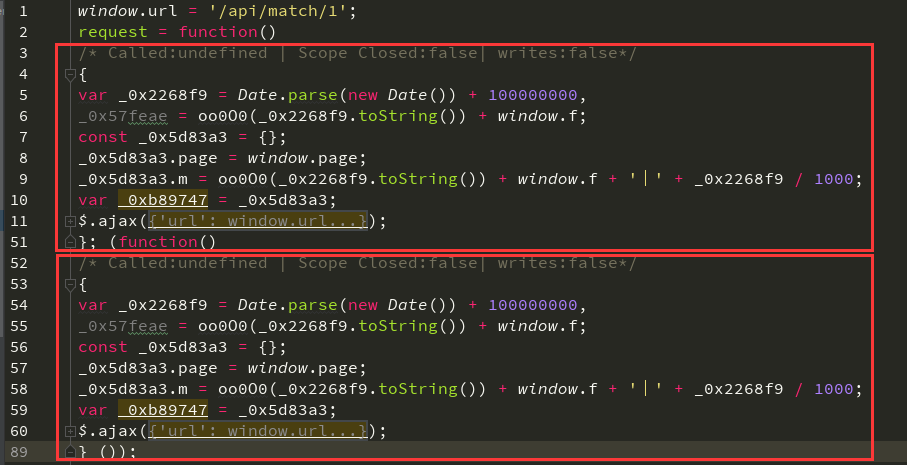
在 Ajax 请求中有 success、complete、error 这三个字段,分别代表请求成功执行、不管是否成功请求都执行、请求不成功执行:
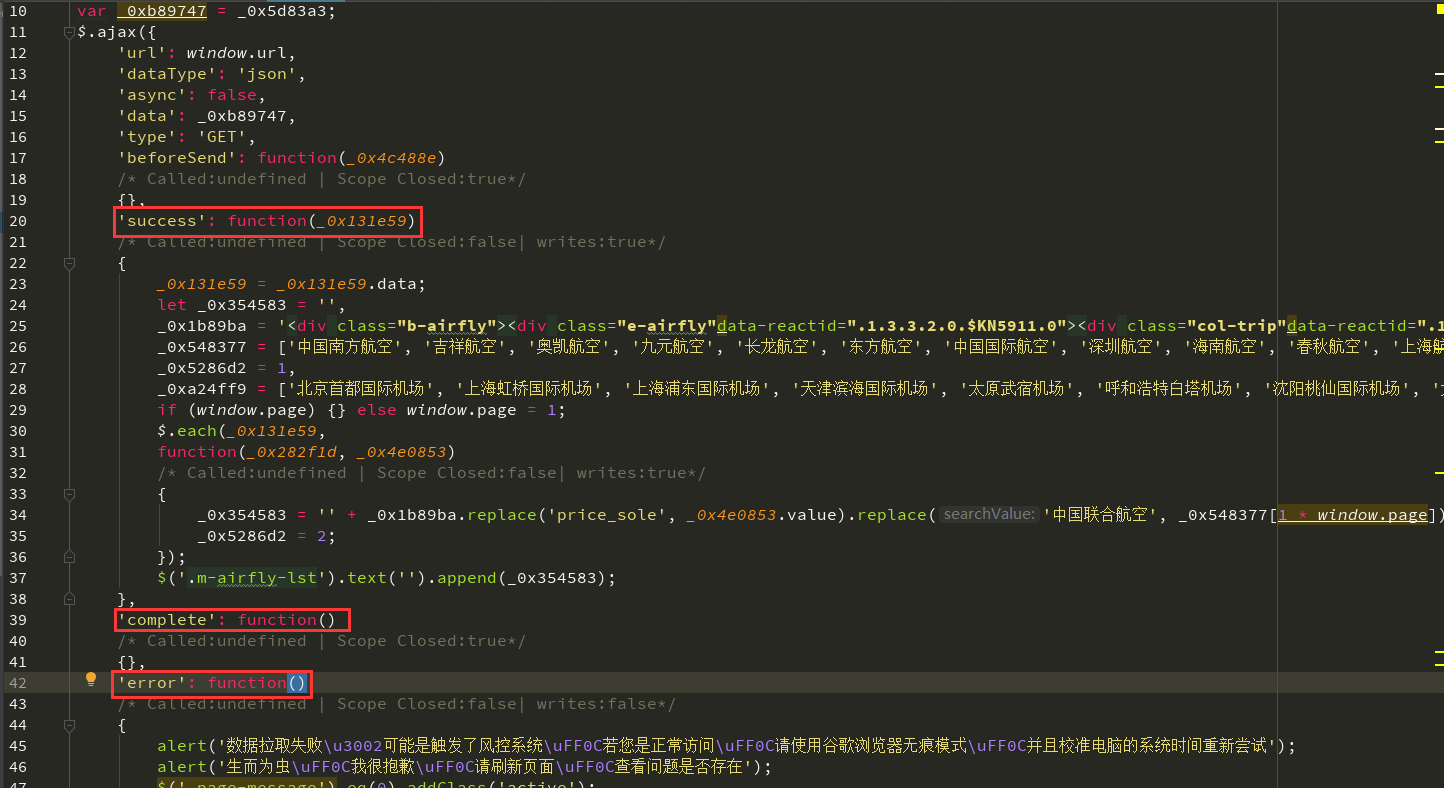
**然而这三部分,我们都不需要关心,因为爬虫只模拟请求的参数和过程。**因此我们可以将这三部分干掉,这下看代码就清清爽爽了:
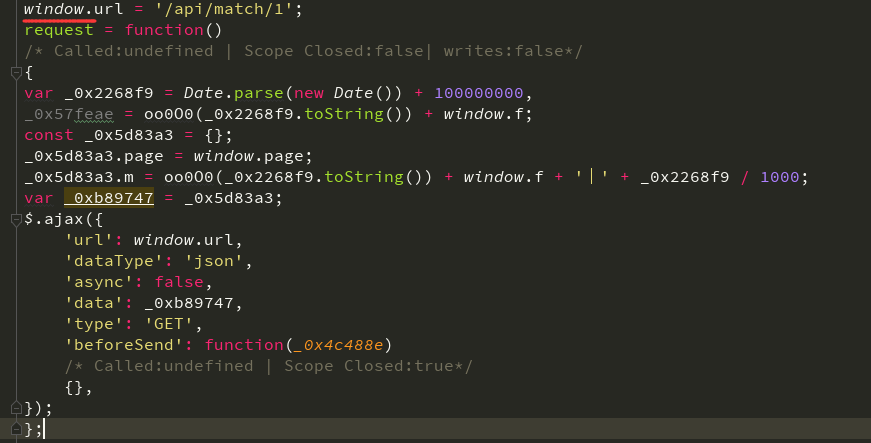
**这里有一个 window.url = '/api/match/1' 赋值过程,因此可以将 window.url 替换为 /api/match/1;还有一个 window.page 根据经验就是访问的页码数,可以暂时给个定值;除此之外还有 window.f 是一个我们未知的变量,经过全局搜索以后未发现给该变量赋值,就暂时先放下。**将整个代码优化替换后,得到了更加简化的样子,但其中还有一个 oo0O0 函数我们未知:
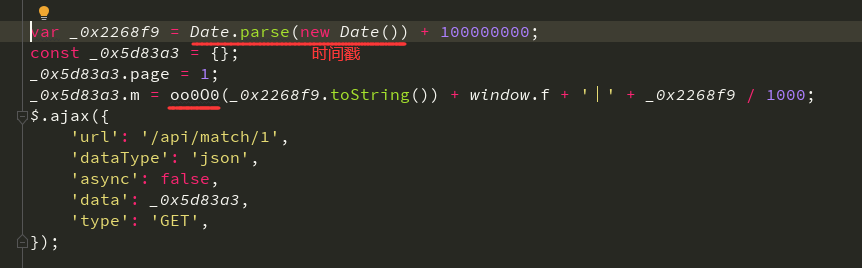
将 oo0O0 定义赋值后其在输出栏中打印出来,可以看到结果函数内容,点击后跳转到名称为 1 的文件当中的该函数位置:
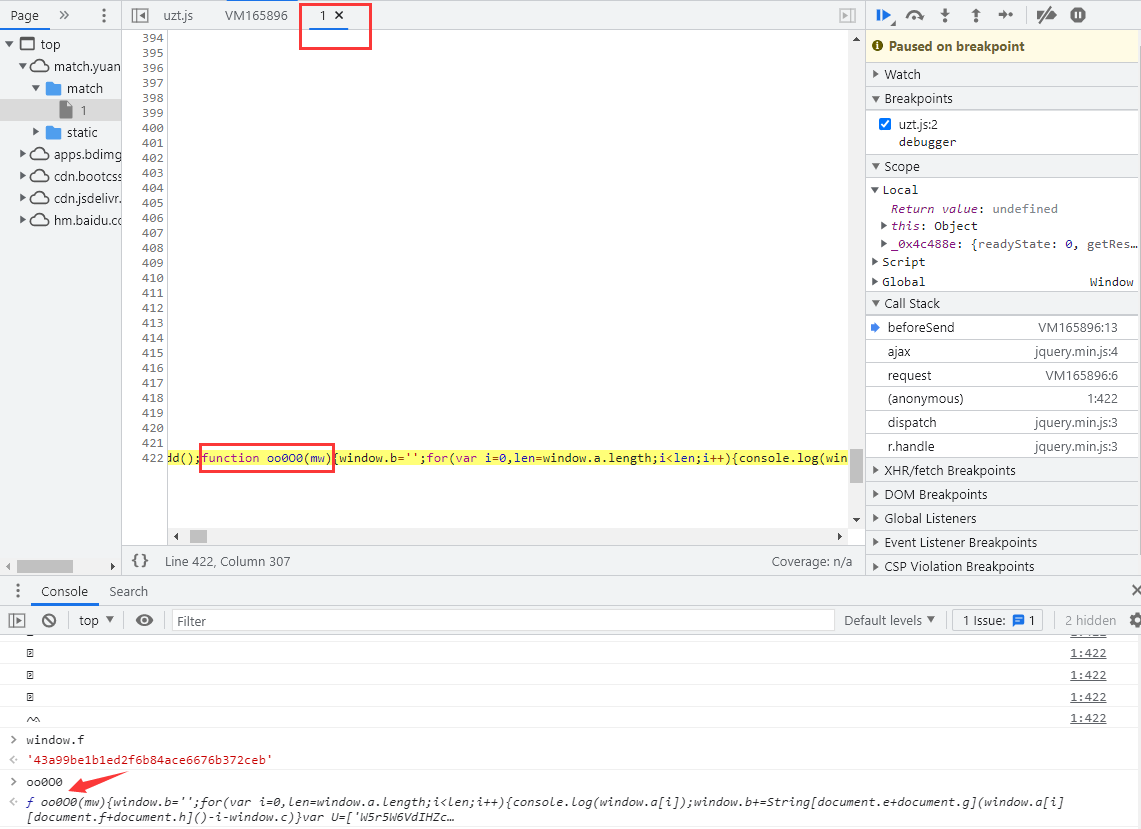
将 oo0O0 函数格式化后拷贝出来,还是按照上面的步骤,该打印的打印,该替换的替换,不用关注函数内部实现了怎样的功能,在函数的最后给出了我们想要的东西:
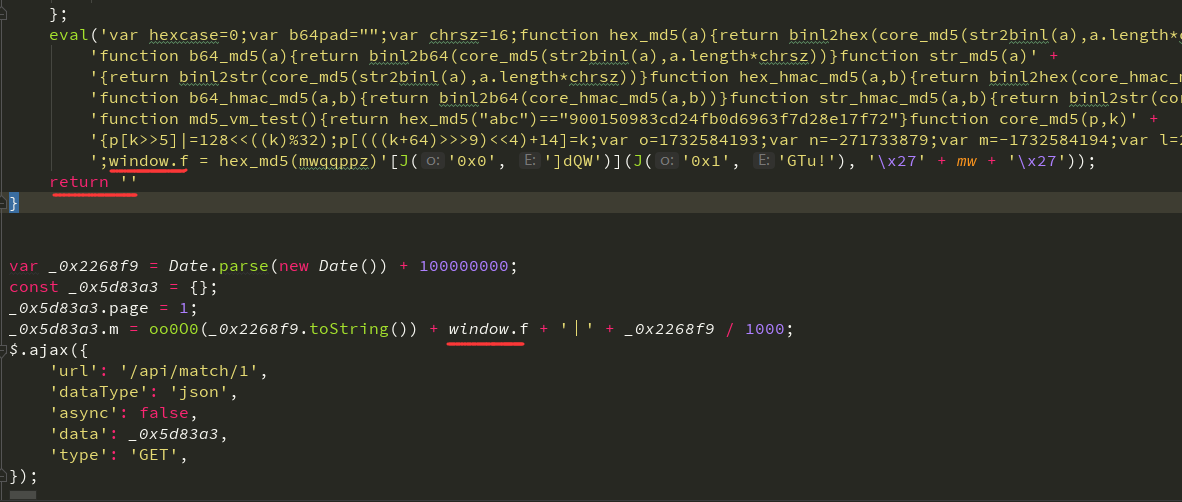
**在 oo0O0 函数最后返回了空,也就是上面 oo0O0(_0x2268f9.toString()) 的值为空,主要就是 window.f 这个值,但这个值又是在 oo0O0 函数内部所定义,且受到时间戳的影响。**分析到这里,我们就可以做最后一波优化了,将 window 全局对象都给去掉,对代码进行简化如下:
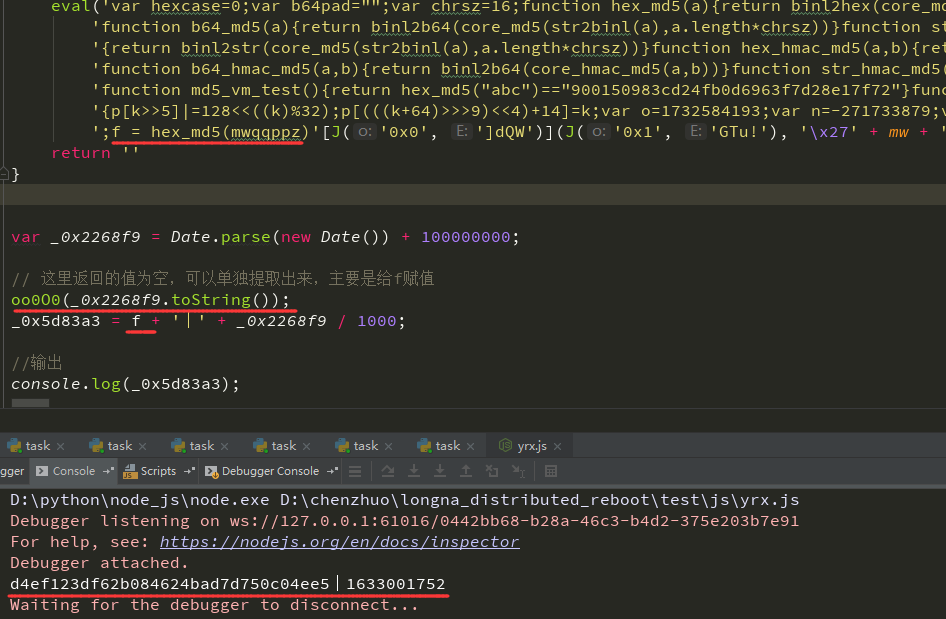
猿人学第2题
难度:简单
访问网址获取任务,在 Network 里面的 Fetch/XHR 选项中定位到了该网页数据的来源请求:
多次访问前面 3 页的页面,发现一个规律,如果访问之间的间隔时间稍微长一点,下次访问就要求强制访问 loginfo 页面,**说明该页面设置的 Cookie 的过期时间较短。**分析比较请求头参数,结合经验得出初步接结论:Cookie 的加密参数为 m,其中 m 的值有两部分组成,前半部分为加密值,后半部分为时间戳相关的参数。
回到 Fiddler 抓包工具,看看所抓到的数据包:在每次请求 loginfo 页面时,前面都会有两次请求,我们分别来看看两次请求分别返回了什么。
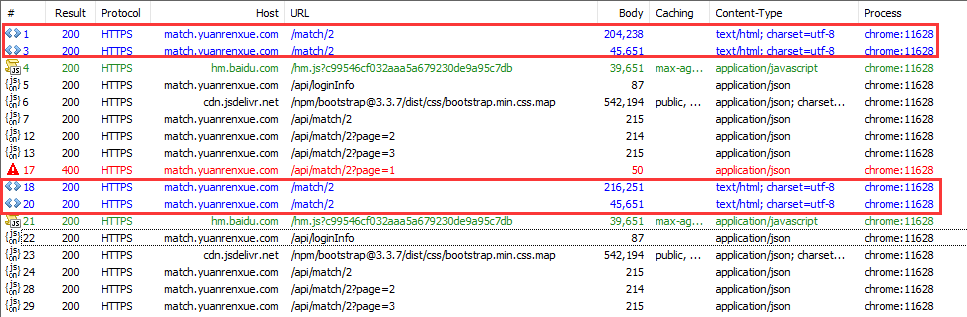
第一次请求,可以看到返回了一段混淆后的 JS 代码,注意这个时候加密参数 m 的值还是上一次请求的值:
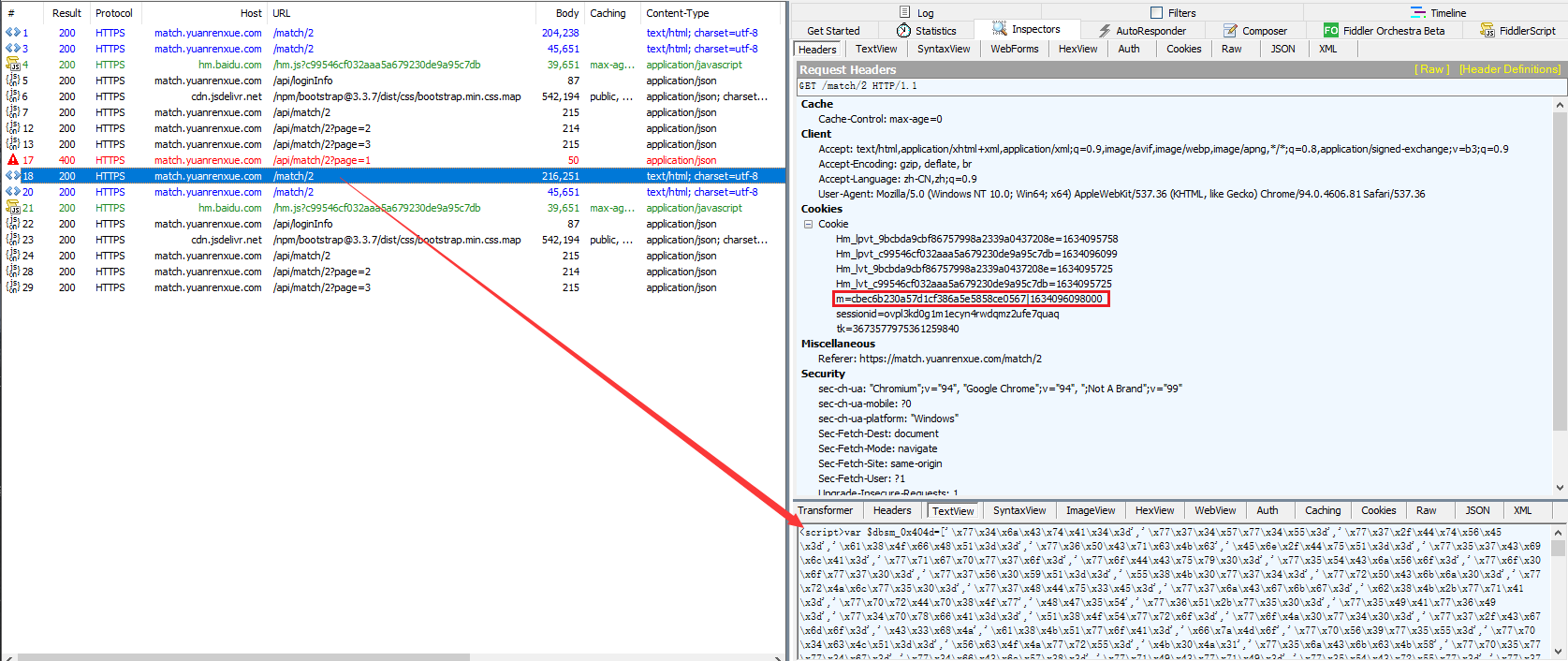
第二次请求,看里面的内容就是这道题所要使用的前端代码,分析作用不大。但这个时候加密参数 m 的值已经发生改变,那就只能说明浏览器加载了第一次请求返回的混淆的 JS 代码,从而改变了 m 的值。
我们把第一次请求返回的混淆 JS 拷贝出来,将去掉首尾的 <script> 标签,使用前面给的ob反混淆工具进行反混淆:
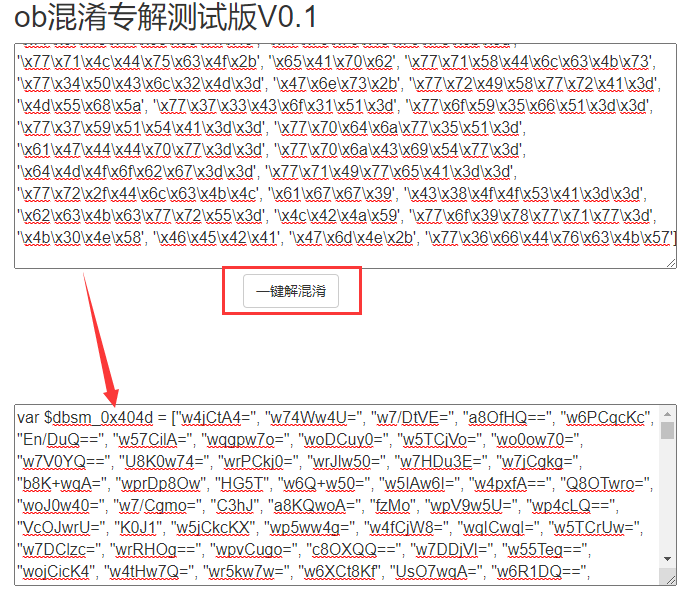
警告
该题的 JS 代码过长,该工具可能只会返回部分的代码,因此最好分段反混淆代码,最后拼接。
反编码后的第一行可以看到明显的一个数组,这就是 ob 混淆的常见特性:
再将完整的反混淆后的代码格式化,美化,折叠,得到如下代码:当中有一个名称为 setInterval ,这是个定时函数,后面的 timeout 参数给的 4000,意味着每 4 秒调用一次该函数:

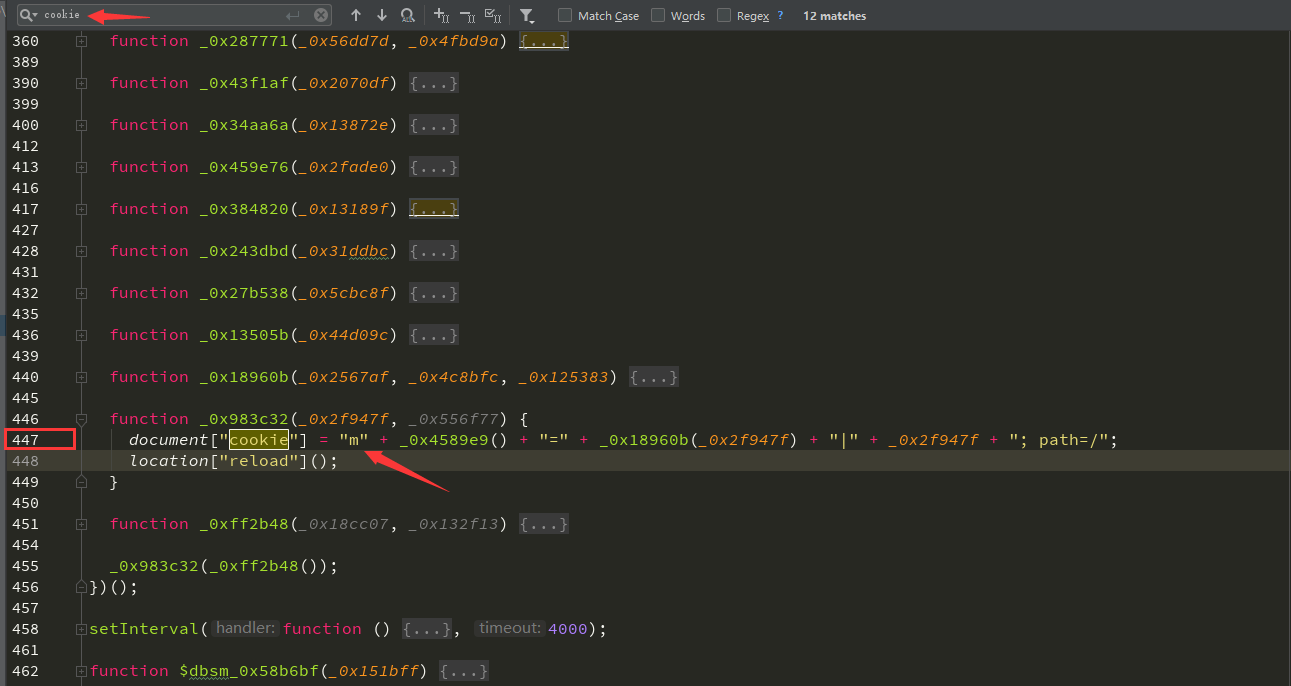
**我们搜索关键词 cookie 发现在 447 行出现了 m 并且后面加上了一个字符 |,再结合前面的 document["cookie"] 基本可以判定该 m 就是 cookie 里面的加密参数了。**结合请求中的 m 的值进行比较可以得出下面关系:
浏览器请求中:m=73321de886f7efd22801e07ec312cdc6|1634197698000
js代码中:document["cookie"] = "m" + _0x4589e9() + "=" + _0x18960b(_0x2f947f) + "|" + _0x2f947f + "; path=/";
结论:
_0x4589e9():返回为空
_0x18960b(_0x2f947f):返回加密的部分
_0x2f947f:返回时间戳的部分