M3U8视频采集
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
在这之前我们先来了解一下视频是如何在网页上播放的。通常情况下,前端程序员会通过一个 <video src="视频地址"></video> 标签将视频嵌入到网页当中,用户点击视频即可播放观看。
但是并不是每一个视频都适合用 <video> 标签嵌入,原因如下:
<video>标签默认会把整个视频传输给用户,如果是短视频到还无所谓,但如果是码率很高、清晰度很高的长电影视频,加载给用户就会特别慢,因为一次加载就要加载几个 G 的文件;<video>标签不支持断点播放,假如用户在观看视频的时候拖动进度条,默认还是会加载前面未观看的部分视频;- 浪费流量,假如一个电影 10G 大小,及时用户只观看了末尾片段,也要加载整个电影文件,看一次 10G 的流量就没有了,因此这无论对公司还是对用户来说都是不友好的。
长视频处理
那么对于一些长视频,网站是如何处理的呢?大体流程如下:
- 首先上传一段 2K 的长视频。
- 进行转码,将视频进行转码成(2K 超清、1080P、高清、标清)四个码率的视频。
- 切片处理,将转码后的视频进行切片,每个切片视频长度大概 10 秒左右。
假如现在用户观看一个由 60 个切片组成的长视频,这时用户拖动进度条到 57 切片的范围内时,那么网站只用加载 57、58、59、60 这几个切片的视频给用户即可,这样网站和用户都节省了巨大的流量,还提升了用户体验。
M3U8 文件
将一个长视频切片成为多个视频文件后,我们还需要一个文件来记录切片文件的序列,否则播放该视频就会出现乱序的现象,除此之外我们还要记录下该切片文件的存放地址。现在大家有一个约定俗成的规则,将存放切片的信息的文件统一存储在后缀为 M3U 格式的文本文件里面,最后经过一道 UTF-8 编码,就变成了 M3U8 格式的文件。其文件内容如下:
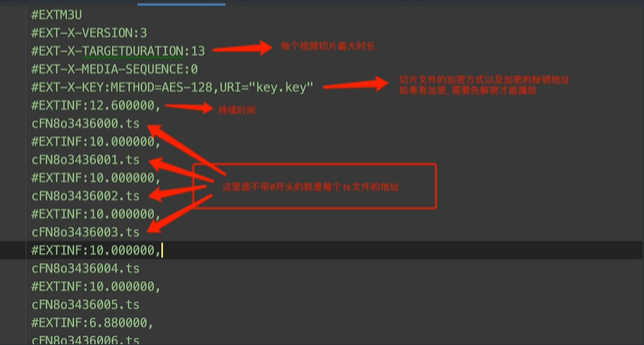
#EXTM3U:文件的类型
#EXT-X-VERSION:使用版本号
#EXT-X-TARGETDURATION:切片视频的最大时长
#EXT-X-KEY:METHOD=AES-128,URI="key.key":加密方式AES,密钥存放URI在key.key中
# EXTINF:视频持续时间
cFN8o3436000.ts:切片文件URL的末尾地址
#EXT-X-ENDLIST:文件内容结束重要
切片视频的播放顺序就是 M3U8 文件从上到下的切片文件顺序。
采集视频
了解了长视频的处理机制,那么我们采集视频就可以分为以下步骤:
- 找到 M3U8 文件。
- 通过 M3U8 文件下载里面的 ts 文件。
- 按照 M3U8 文件里面的顺序将所有的 ts 文件合并为 1 个 MP4 文件。
91看剧同步案例
我们选择一个网站名叫 91 看剧的简单案例来练练手,地址:https://www.91kanju.com/
分析流程
首先我们随机选择一部剧开始播放:
点击右键,选择“查看页面源代码”,搜索 <video> 标签发现并没有:那就说明在页面所看到的视频是通过脚本控制动态生成的。
现在我们查看开发者工具的 Network 选项中的 XHR 选项,会发现一个以 m3u8 结尾的 URL 链接:
https://m3api.awenhao.com/index.php?note=kkRchfb7ynt3sgp2jqdkx&raw=1&n.m3u8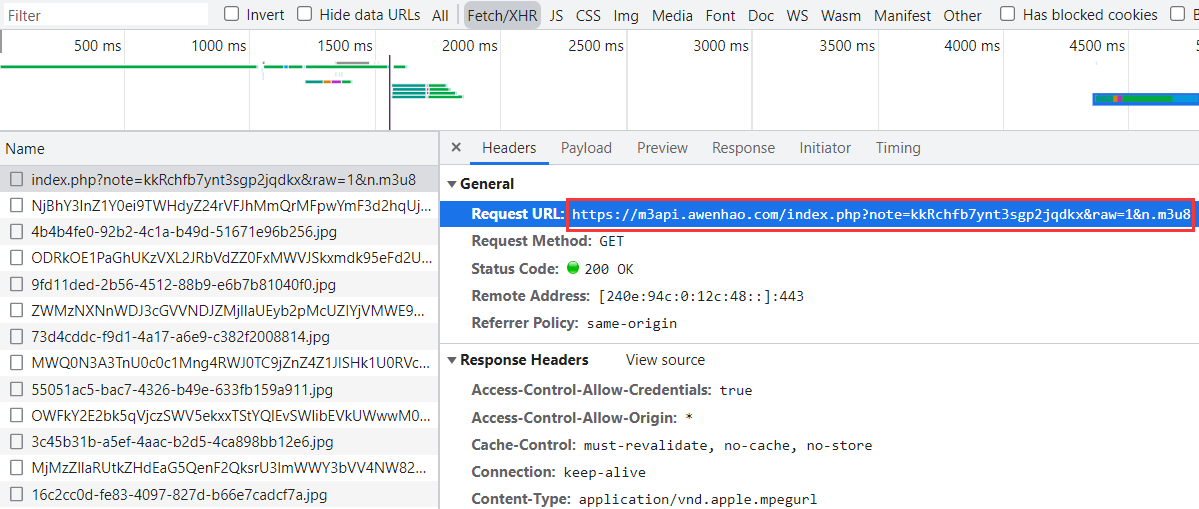
查看响应内容,和我们上面讲述的 M3U8 文件格式一模一样,而且下面的请求都是通过该文件来规定的:
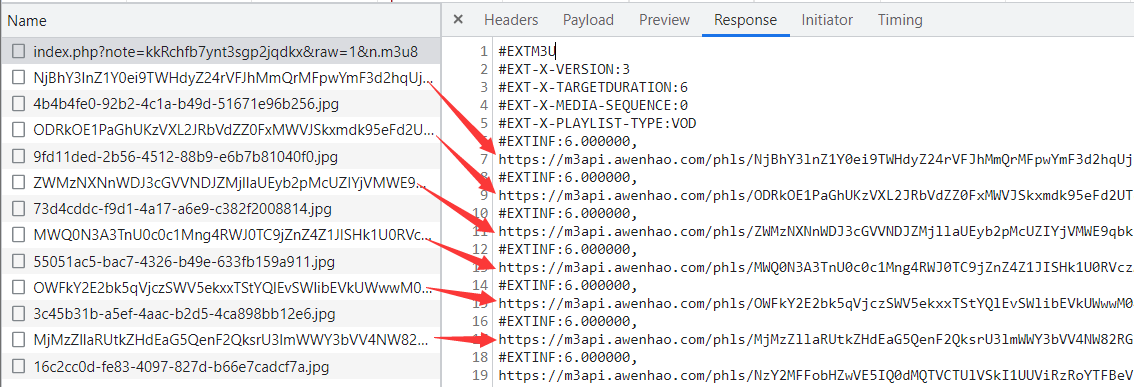
接下来我们就要寻找 m3u8 的 URL 链接来源了,在链接当中有一个 note=kkRchfb7ynt3sgp2jqdkx 值,全局搜索发现来源于网页的响应:
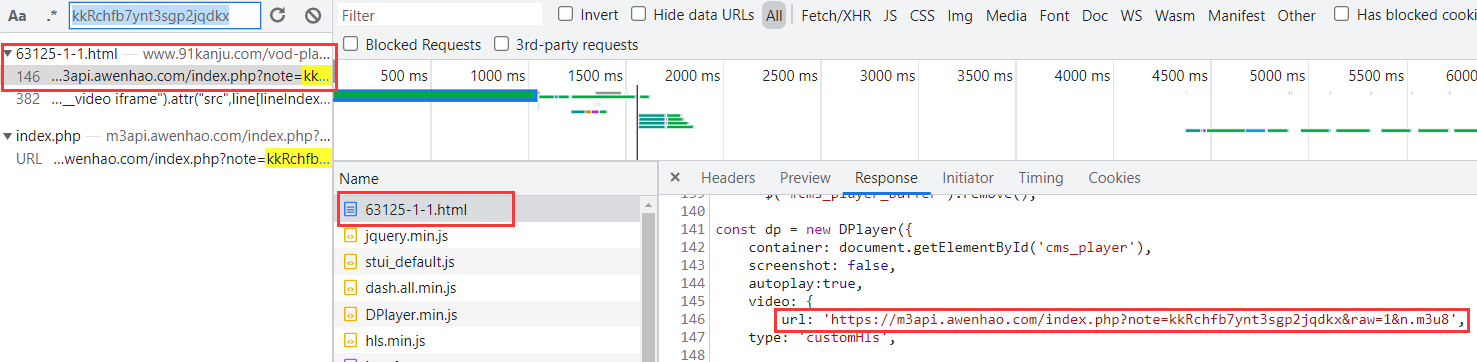
下载合并
现在我们已经找到了 m3u8 的 URL 链接来源了,就相当于找到了所有切片视频的来源,接下来我们就要将所有的切片视频下载下来合并成一个视频:
python
import re
import requests
# 获取页面源码
url = 'https://www.91kanju.com/vod-play/63125-1-1.html'
res = requests.get(url=url, verify=False)
# 获取m3u8链接
m3u8_url = re.findall(r"url: '(https:.*?m3u8)',", res.text, re.S)[0]
m3u8_res = requests.get(url=m3u8_url, verify=False)
# 筛选出里面的视频链接
video_list = re.findall(r'(https://m3api.awenhao.*?)\n#', m3u8_res.text, re.S)
print(f'总共:{len(video_list)}个切片视频')
# 下载合并视频
video_all = b''
for video_url in video_list:
video = requests.get(url=video_url)
video_all += video.content
# 写入视频
with open(f'./video/新居之约.mp4', 'wb') as f:
f.write(video_all)
print(f'写入视频完成')最终我们得到了一个和网页上差不多长的视频:这里额外提醒一点就是,无论是切片视频还是合并后的视频,用系统自带的播放器就能播放,用其他的播放器(暴风影音)反而播放不出来。
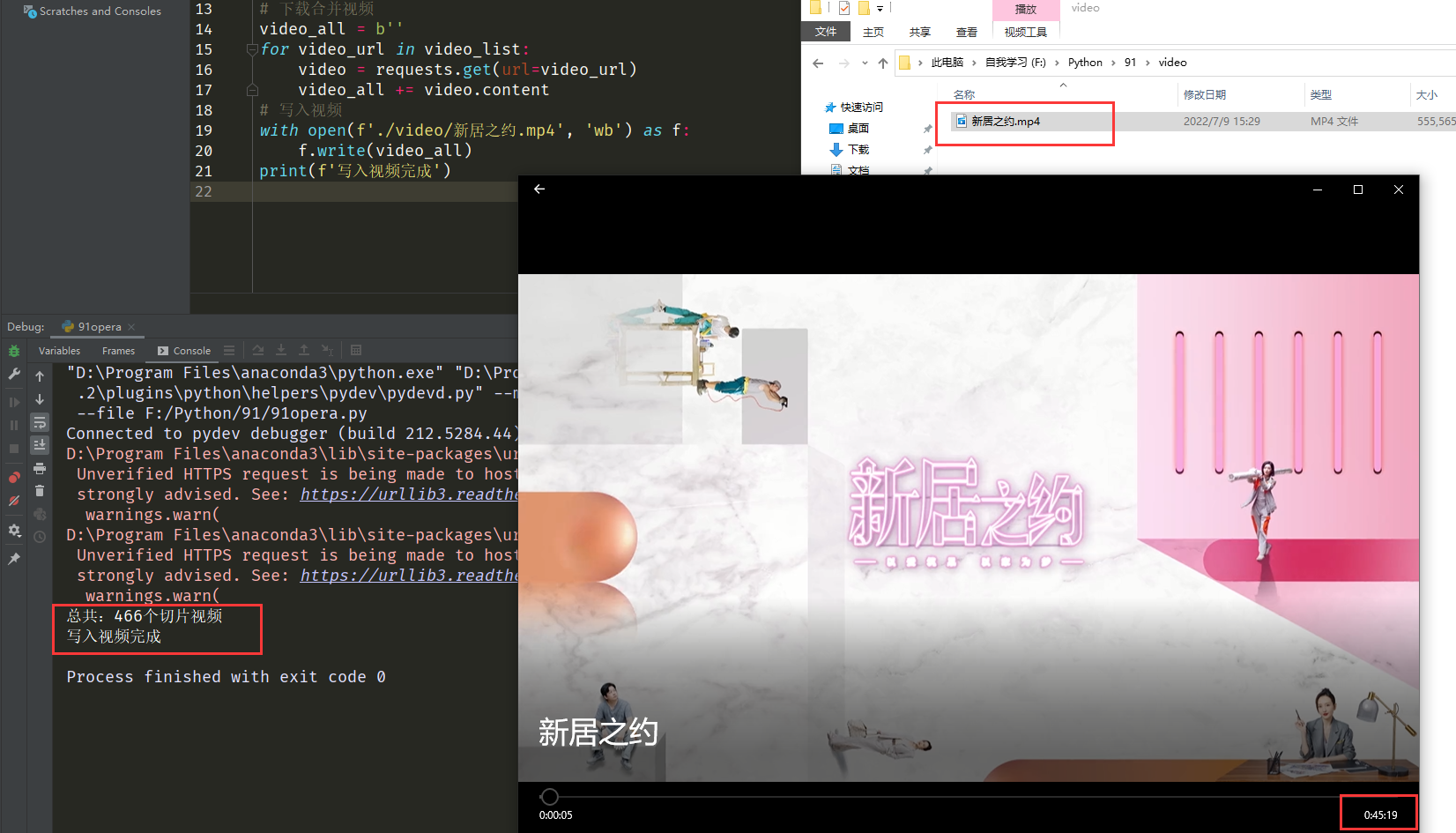
重要
这里补充一点就是上面 m3u8 的 url 中有一个 note 值,注意这个值是有时效性的,也就是说当获取到了这个 note 值后,必须要马上使用,否则 m3u8 的 url 就会失效。假如浏览器进入网页后,视频一直处于加载的状态,那么就有可能是 m3u8 的 url 已经失效,这时我们只需要刷新网页即可正常观看。
91看剧异步案例
同样的我们还是选择 91 看剧这个网站来练练手,地址:https://www.91kanju.com/
分析流程
这次我们随机选择一部电影开始播放:

现在我们查看开发者工具的 Network 选项中的 XHR 选项,会发现两个以 m3u8 结尾的 URL 链接,查看第一个请求的 URL 如下:
https://www.ldxmcloud.com/20220508/InBGlxJj/index.m3u8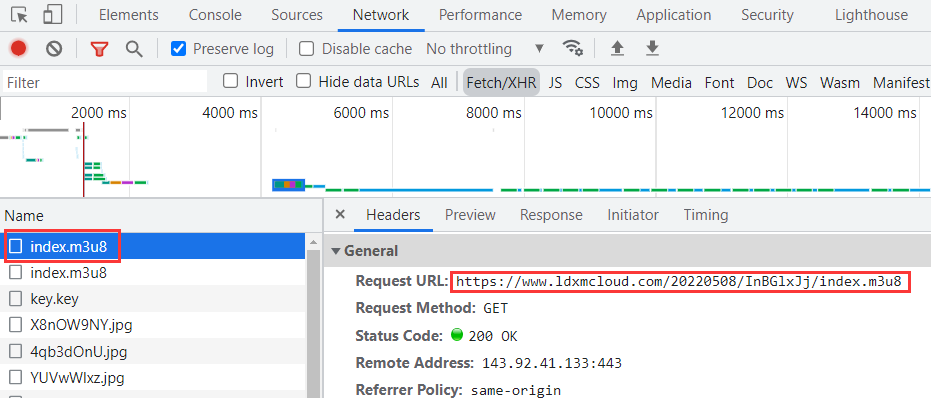
查看第一个响应的内容如下:在最后一行返回了一个以 m3u8 结尾的 URL。
/20220508/InBGlxJj/2000kb/hls/index.m3u8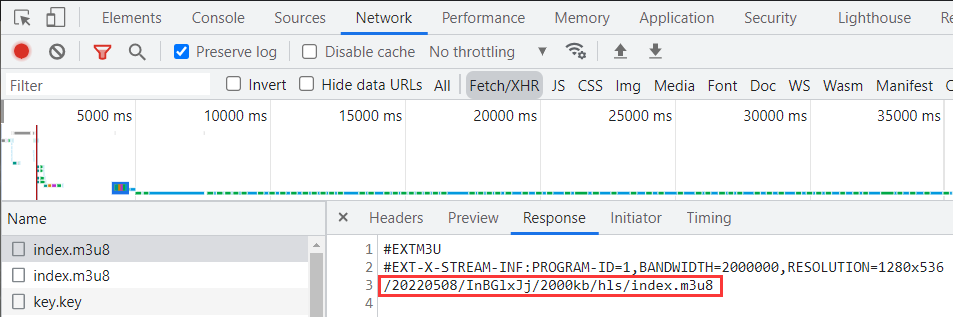
接着查看第二个以 m3u8 结尾的 URL 链接请求内容如下:可以看到这次请求 URL 的后半段来源于第一个响应内容中 URL。
https://www.ldxmcloud.com/20220508/InBGlxJj/2000kb/hls/index.m3u8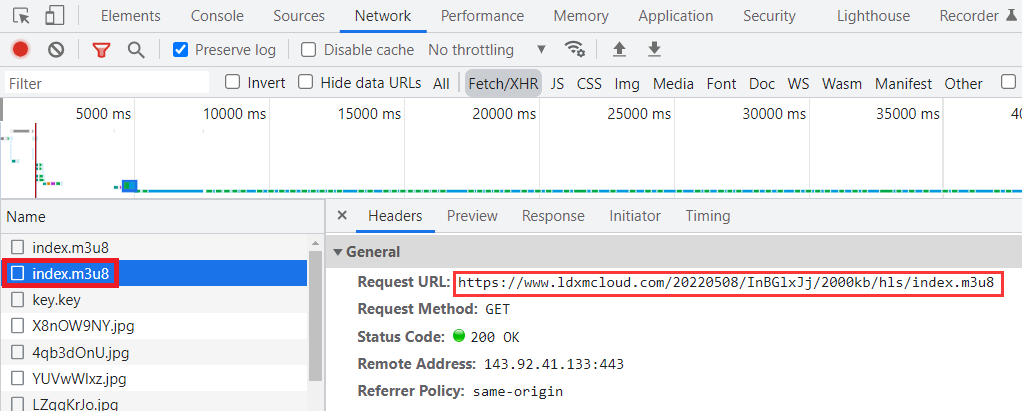
查看第二个响应的内容如下:可以看到这次的响应内容就是 M3U8 文件内容格式,说明这是记录切片视频信息的响应。但是和前面例子中 M3U8 返回的内容又有点不同,在里面多了如下加密内容,说明切片的视频信息经过 AES 加密,密钥就放在 URI 当中。
#EXT-X-KEY:METHOD=AES-128,URI="https://www.ldxmcloudcdn.com/20220508/InBGlxJj/2000kb/hls/key.key"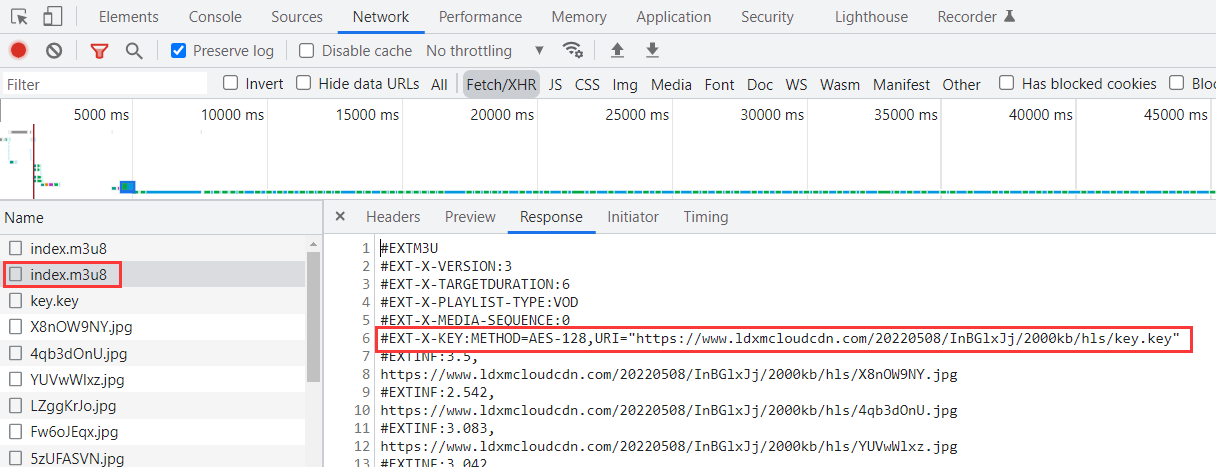
接下来,我们查看第三个请求内容如下:可以看到这次请求的 URL 就是第二个请求返回内容中的 URI。
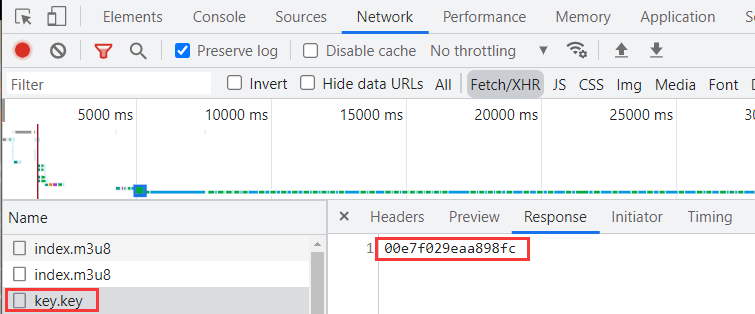
https://www.ldxmcloudcdn.com/20220508/InBGlxJj/2000kb/hls/key.key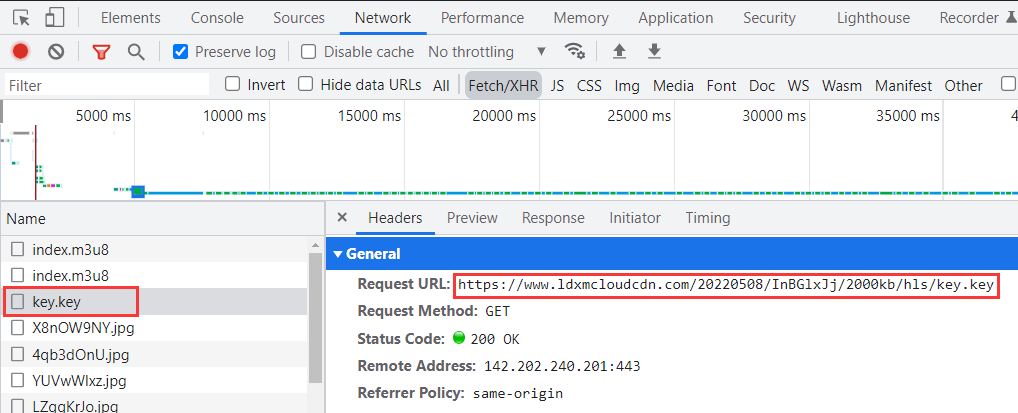
第三个请求响应内容如下:返回的响应是一个 16 位的 AES 密钥,通过该密钥来解密返回的视频信息,从而播放视频。
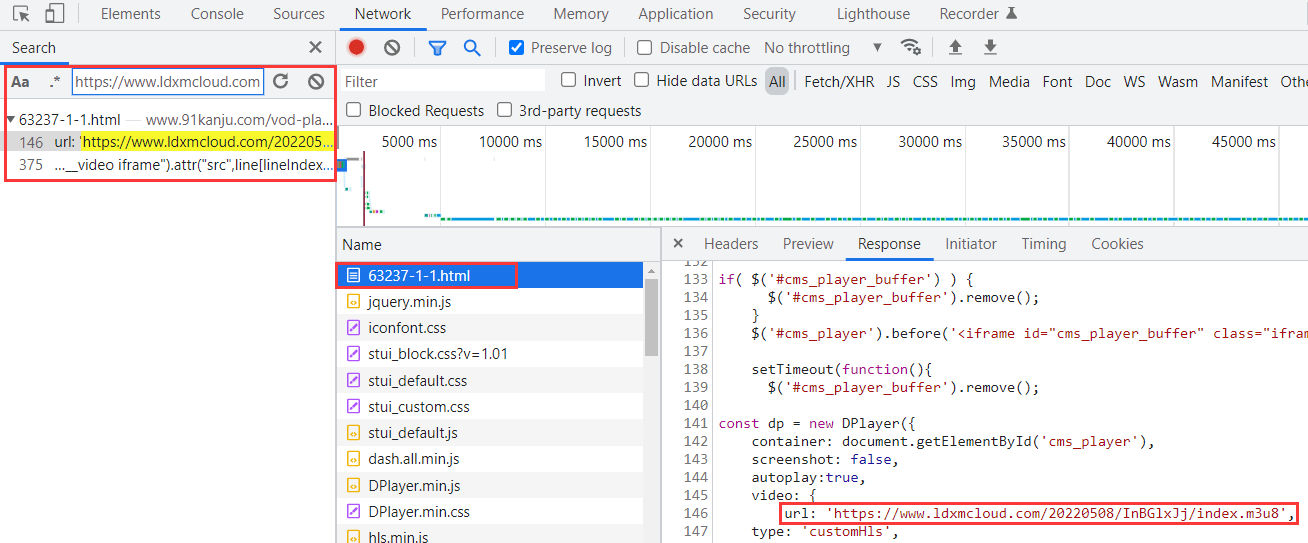
最后我们回到第一个请求的 URL 产生:通过全局搜索发现,该URL来源于网页返回的源码当中。
下载合并
python
import re
import requests
import asyncio
import aiohttp
# 从Crypto.Cipher模块中导入AES函数
from Crypto.Cipher import AES
def page_source(url):
response = requests.get(url, verify=False)
return response.text
async def download_one(url, key):
# 链接太多,大概率有下载失败的,因此需要下载重试
for i in range(10):
try:
aes = AES.new(key=key.encode(), mode=AES.MODE_CBC, IV=b"0000000000000000")
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
result = await response.content.read()
return aes.decrypt(result)
except:
print(f"{url}下载失败,正在重试...")
await asyncio.sleep(i + 1)
async def download_all(urls, key):
tasks = []
for url in urls:
task = asyncio.create_task(download_one(url, key))
tasks.append(task)
all_result = await asyncio.gather(*tasks)
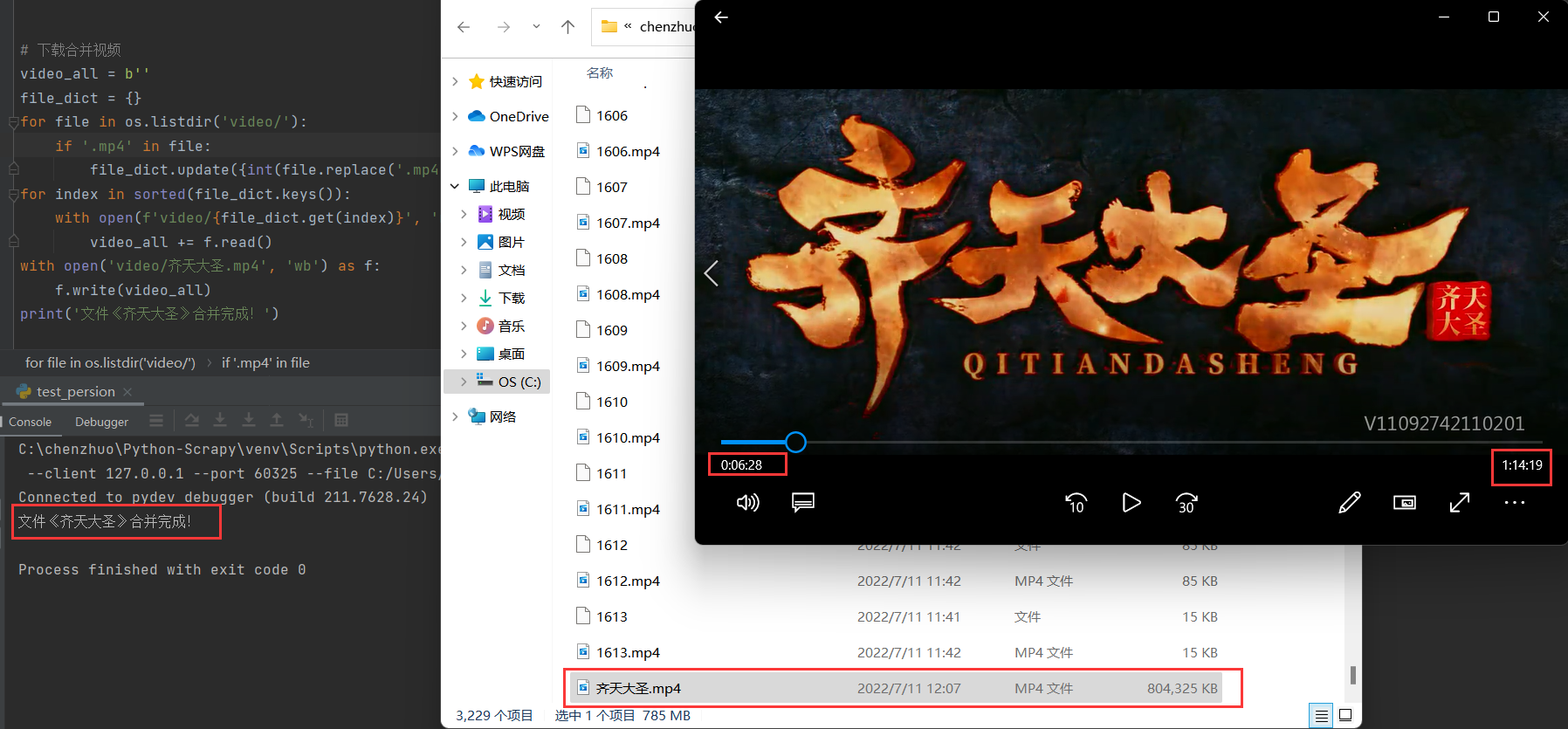
with open('齐天大圣.mp4', 'wb') as f:
f.write(b''.join(all_result))
print('文件《齐天大圣》合并完成!')
def main():
# 获取页面源码
first_url = 'https://www.91kanju.com/vod-play/63237-1-1.html'
first_res = page_source(first_url)
# 获取第一个m3u8链接及响应
m3u8_one_url = re.findall(r"url: '(https:.*?m3u8)',", first_res, re.S)[0]
m3u8_one_res = page_source(m3u8_one_url)
# 获取第二个m3u8链接及响应
m3u8_two_url = 'https://www.ldxmcloud.com' + re.findall(r"(/.*)\n", m3u8_one_res, re.S)[0]
m3u8_two_res = page_source(m3u8_two_url)
# 获取AES链接密钥
aes_url = re.findall(r'URI="(.*?)"', m3u8_two_res, re.S)[0]
aes_key = page_source(aes_url)
# 筛选出里面的视频链接
video_list = re.findall(r'(https:.*?)\n', m3u8_two_res, re.S)[1:]
print(f'总共:{len(video_list)}个切片视频')
# 建立事件循环
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(download_all(video_list, aes_key))
if __name__ == '__main__':
main()经过合并,最终我们得到了一个和网页上所播放的一模一样的电影:
建议
这里需要说明一下的是,我们这里得到的电影时长和网页展示的电影时长可能是有差距的,因为网页的时长是按照 M3U8 文件中 EXTINF 后面的视频秒数加和计算的,而我们得到的电影时长是 ts 切片视频合并后的总时长。