如何显示字符
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
当今数字化时代,信息交流已经成为人们生活中不可或缺的一部分,使用文字可以说是最基本、最普遍的交流方式之一。文字不仅能够跨越地域、文化的限制,还能将人们的思想、情感、观点、知识等信息精确地传递出去,而且具有极高的可保存性和可复制性,无论是电子邮件、社交媒体、即时通讯工具,还是博客、论坛、新闻网站,文字都是最主要的交流媒介。那么计算机是如何显示文字的呢?
原理介绍
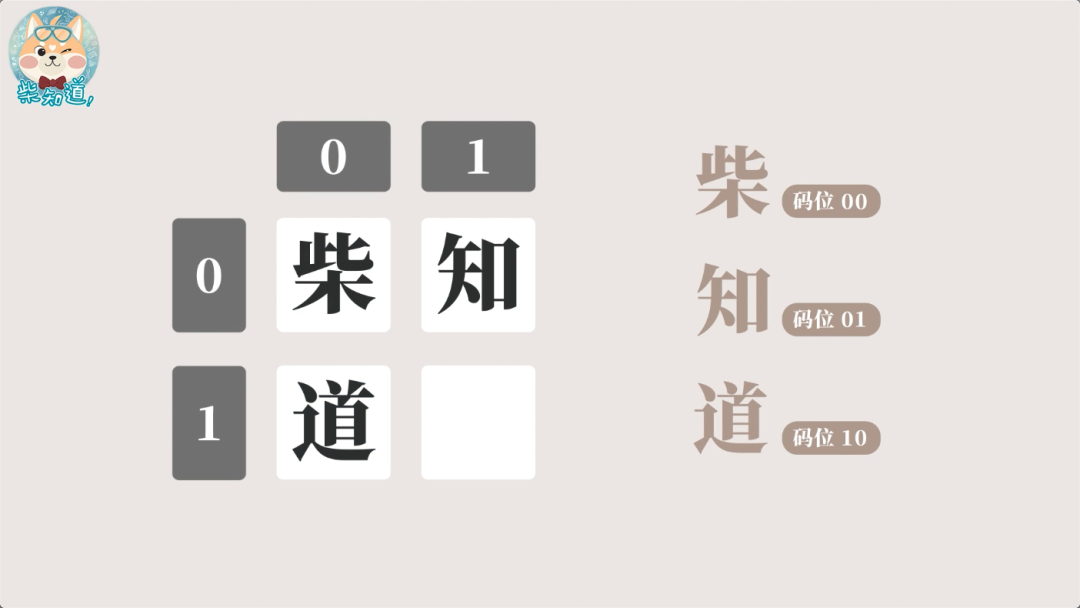
打个比方,假如这个世界上只有“柴”、“知”、“道”这三个字的话,那么每个字都是一个”字符“,把每个字符集合在一起叫做“字符集”,但这些字符对于计算机来说......一个都不认识,这是因为计算机只能处理 0 或 1 这样的二进制数字,为了让计算机能够显示字符,我们就需要把字符集中的每一个字符用 0 或 1 进行编码,这套字符的编码规则就叫做”字符编码“。首先我们将需要编码的字符排列出来,每个字符对应的座位序号叫做码位,座位的总数叫做码空间,码空间越大,能容纳的字符就越多。那我们就可以把“柴”编码 00,“知”编码为 01,“道”编码为 10。这样计算机一看到这些编码,就知道要显示哪个字了。因此计算机显示文字,涉及到如下三个重要的基本概念:
- 字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,也是构成文本信息的基本单元,它们用于表达语言、编码信息和构建文本文档。
- 字符集(Character Set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII 字符集、GB2312 字符集、Unicode 字符集等。
- 字符编码(Character Encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8 位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
建议
一个字符集可以对应一个或多个字符编码。例如,ASCII 字符集就对应一个 ASCII 编码,Unicode 字符集则对应 UTF-8、UTF-16、UTF-32 编码。
字符编码
在计算机中,存储数据的基本单位是字节(Byte),1 个字节等于 8 个比特(bit),每个比特有 0 和 1 两种状态,8 个比特就有 2 ^ 8 = 256 种不同的状态。所以如果只用一个字节长度来编码字符,那么这个字符集就能容纳 256 个字符。听起来很少,但对于 26 个英文字母来说已经够了。

ASCII
在上世纪 60 年代,美国人搞出了 《美国信息交换标准代码》,简称 ASCII,里面编码了 128 个字符,包括大小写英文字母、数字、常用标点,以及像 ESC、换行这种看不见的控制字符。上面说过,1 个比特有 0 和 1 两种状态,那么 7 个比特就能表示 2 ^ 7 = 128 种不同的状态,刚好就对应 ASCII 中的 128 个字符。例如,小写字母 a 在 ASCII 字符集中的编号是 97,用 7 个比特来表示就是 110 0001,这个就是小写字母 a 的 ASCII 编码,但为了便于以 1 个字节的方式存储,会在前面额外扩充 1 个比特 0,所以小写字母 a 存储的二进制编码就是 0110 0001。后面计算机需要展示该字符的时候,会先读取字符的二进制编码,再根据编码调用 ASCII 字符集中对应的字符,这样字符就能在屏幕上显示出来。
提醒
ASCII 占用了一个字节的前 128 个码位,西欧一些国家用剩下的 128 个空位搞了“扩展美国信息交换标准代码”,简称 EASCII,添加了比如有注音符号的法语字母,常用的 α、β 等希腊字母,以及一堆特殊符号等等。这个时候问题就开始显现了,由于各国搞的 EASCII 字符集和编码,后面 128 个字符都不太一样,因此就算是同样一串二进制数,在不同的 EASCII 中对应的字符也不同,所以同一份文本哪怕放到不同语言的计算机中打开,都可能会出现“乱码”。
GB2312
后来人们发现,EASCII 码仍然无法满足许多语言的字符数量要求。比如汉字有近十万个,光日常使用的就有几千个。于是中国国家标准总局于 1980 年发布了《GB 2312-80 信息交换用汉字编码字符集 基本集》,包含了 6763 个常用简体汉字,其中一级汉字 3755 个,二级汉字 3008 个,以及一些标点、符号、数字、拉丁字母等,基本满足了计算机处理汉字的需求。

不过,GB2312 字符集里这六千多个汉字,只是最常用的汉字,其实根本不够用,比如像 “喆”“頫”“旻”“祎” 这些人名中的常见字甚至都不包括在内。如果你的名字生僻一点,不在这个字符集中,计算机要么调用其他字体来显示,要么直接给你显示成个框框,总之就是显得格格不入。

像我们平常常用的公文字体之一「仿宋 GB2312」,意思就是说我只设计了 GB2312 字符集中的字符。

由于汉字有简体,有繁体,而且虽然起源于中国,但远不止中国一家用。日本用日本汉字、韩国用朝鲜汉字,大家都搞出了自己的字符集和编码规则,都优先考虑本地人使用方便,相互之间的兼容性很差。

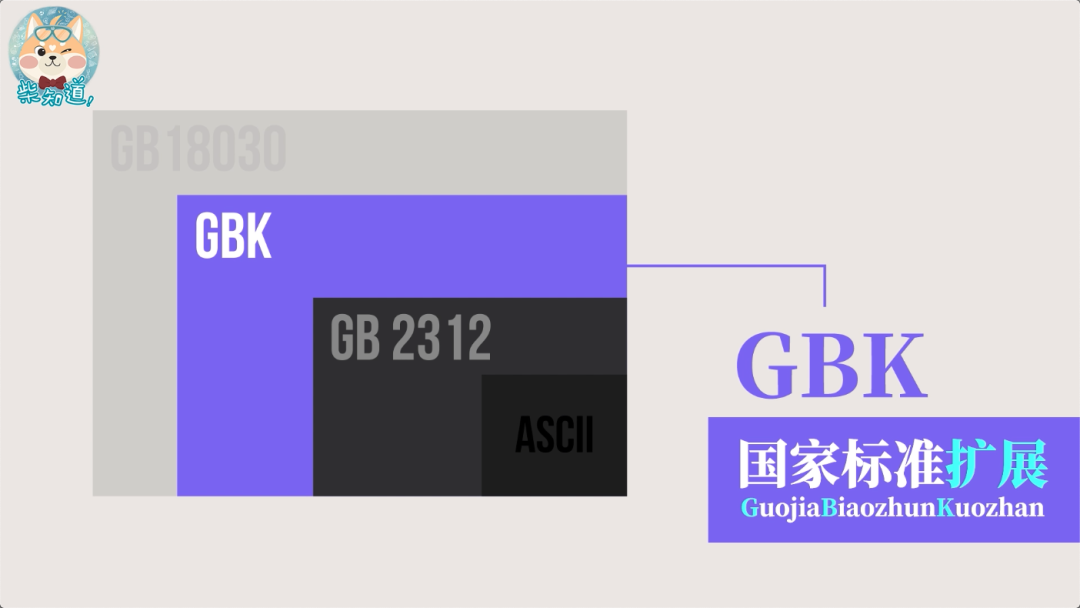
GBK
后来微软根据各地字符集和字符编码扩展了 GB2312 字符集,加入了一些繁体汉字,这份扩展的字符集后来成为了“汉字内码扩展规范 GBK”,这里的 K 就是“扩展”的意思。GBK 标准共收入 21886 个汉字和图形符号,简、繁体字融于一库。在 GBK 的编码方案中,ASCII 字符使用一个字节表示,汉字使用两个字节表示,总体编码范围为 8140-FEFE 之间,首字节在 81-FE 之间,尾字节在 40-FE 之间。
同样的,平常常用的公文字体之一「标宋 GBK」,意思就是说我只设计了 GBK 字符集中的字符。

建议
GBK 不是国家标准,只是一个普通的技术规范。
Unicode
随着计算机在全球迅速普及,全世界有上百种语言,各国有各国的标准,会不可避免的出现冲突。一方面,这些字符集一般只定义了特定语言的字符,无法在多语言环境下正常工作。另一方面,同一种语言存在多种字符集标准,如果两台计算机使用的是不同的编码标准,则在信息传递时就会出现乱码。于是人类就搞了一个超级大的能容纳 100 多万个字符的 Unicode 字符集,中文名叫“统一码”或“万国码”。它致力于将全球范围内各种语言的文字、符号等都纳入统一的字符集之中,提供一种通用的字符集来处理和显示各种语言文字,减少因为编码标准不同而产生的乱码问题。

建议
现代操作系统和大多数编程语言都直接支持 Unicode。
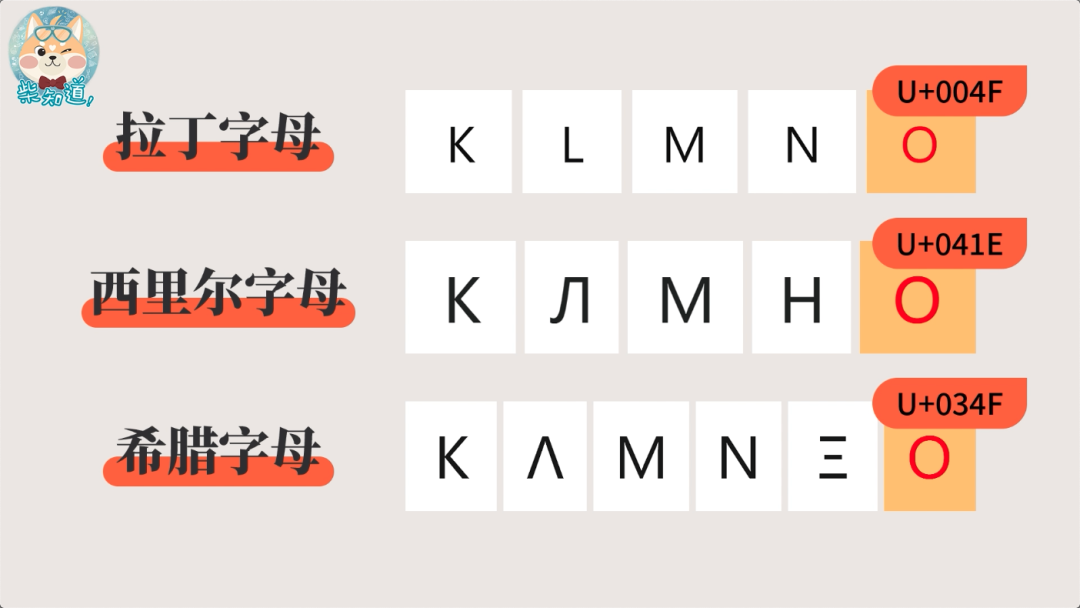
为了收纳这么多字符,Unicode 通过书写系统为标准来分类和收录字符。像英语、德语、法语、西班牙语……都属于同一套「书写系统」——拉丁字母。虽然拉丁字母里的“o”,和西里尔字母“о”,以及希腊字母“ο”,长得几乎一样,但既然属于三个不同的书写系统,而且过去各地都已经搞出了相应的字符编码,为了兼容性,就需要安排三个不同的码位。
至于我们中国的简体字、繁体字,以及日本汉字、朝鲜汉字等,则被归纳为「中日韩统一表意文字」。由于一些汉字在各地都用,只是长得略微有点区别,为了节省码位,Unicode 就让这些字共用一个码位。

Unicode 的这种分类收录方式,愿望是好的,但坑也是挖了不少的。比如下面这串网址,它看上去是苹果公司的官网,但这个字母,根本不是拉丁字母 a,而是西里尔字母。所以用这种方法,就可以轻而易举制作出钓鱼网站,诱骗你的帐号和密码。

在汉字世界,也有人利用 Unicode 玩出了类似的花招: Unicode 中收录了 214 个康熙部首,它们跟普通汉字长得几乎一模一样。

当初 Unicode 收录这些康熙部首,是为了方便词典和输入法能给汉字排序,并跟中国台湾的「中文标准交换码」兼容。当年就有人担心,这些部首跟常用汉字长得太像,可能会出显示问题。于是 Unicode 把它们列为了“兼容字符”,这样在正常情况下,用户很难输入这些部首。但人类的聪明才智是用不完的,下图中,就是利用康熙部首的“⼊”,替换了正常的“入”。

在诞生后的这些年里,Unicode 一直在不断地更新、扩展,包括一大堆你不认识的汉字,包括陕西 biáng biáng 面的 𰻝 (biáng,可能无法正常显示),你用的 emoji 表情,都已经被收纳进了 Unicode 字符集中。

其中甚至还有为各个国家、地区、甚至企业准备的“私用区”,可以供大家自定义使用。苹果就把自己的 logo 放进了私用区,只有用 macOS、iOS 等苹果操作系统的朋友才能看见这个字符,而 Windows 和 Android 拒绝显示。
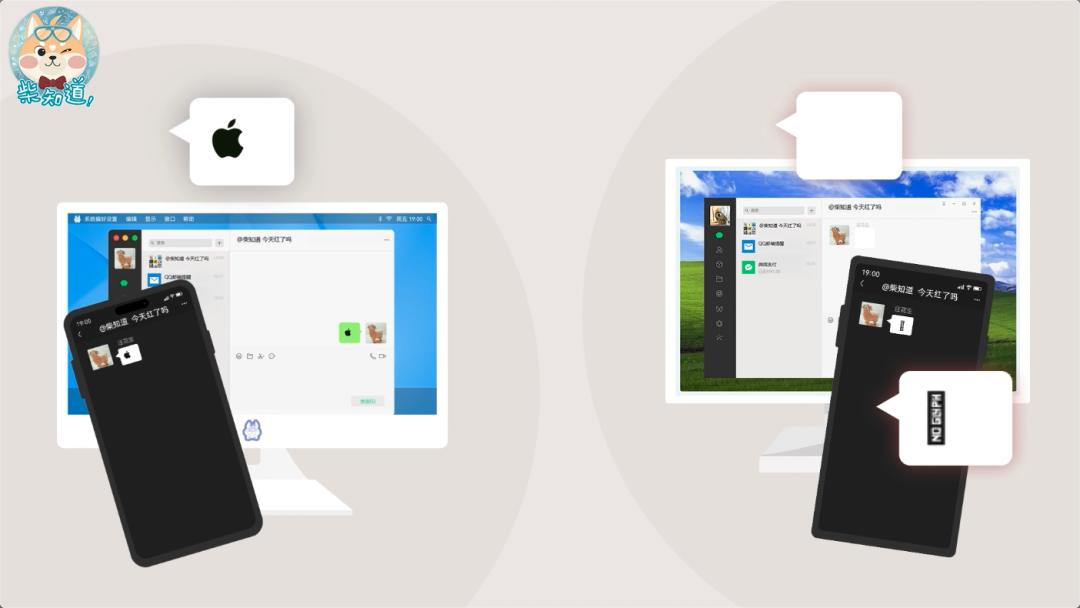
建议
Unicode 自 1991 年发布以来就不断扩充新的语言与字符,其包含的字符数量随着版本的更新而增加。截至 2023 年,Unicode 的最新版本是 Unicode 15.0,它包含了超过 150,000 个字符(确切的数量会根据具体版本和包含的扩展集而有所不同)。这些字符覆盖了多种语言、符号、表情符号(如 Emoji)等。
UTF-8
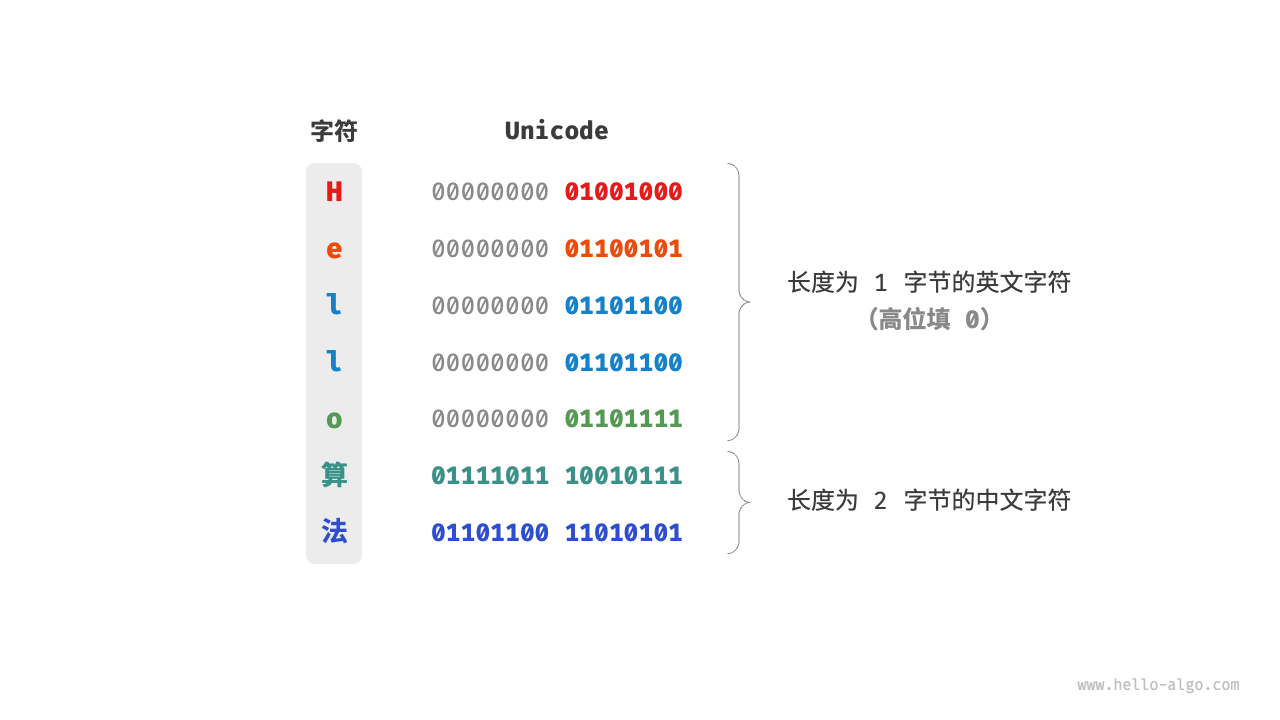
Unicode 是一个庞大且通用的字符集,里面常用的字符占用 2 字节,有些生僻的字符占用 3 字节甚至 4 字节。可以说,Unicode 本质上是给每个字符分配一个编号(称为“码点”),但它并没有规定在计算机中如何存储这些字符码点。我们不禁会问:当多种长度的 Unicode 码点同时出现在一个文本中时,系统如何解析字符?例如给定一个长度为 2 字节的编码,系统如何确认它是一个 2 字节的字符还是两个 1 字节的字符?对于以上问题,一种直接的解决方案是将所有字符存储为等长的编码。如下图所示,“Hello”中的每个字符占用 1 字节,“算法”中的每个字符占用 2 字节。我们可以通过高位填 0 将“Hello 算法”中的所有字符都编码为 2 字节长度。这样系统就可以每隔 2 字节解析一个字符,恢复这个短语的内容了。
然而 ASCII 码已经向我们证明,编码英文只需 1 字节。若采用上述方案,英文文本占用空间的大小将会是 ASCII 编码下的两倍,在存储和传输上就十分不划算。本着节约的精神,我们需要一种更加高效的 Unicode 编码方法,于是出现了**“UTF 可变长编码方式”**,主要实现方式有:
- UTF-8 编码:最短字节长度为 8 比特,即使用 1 到 4 字节来表示一个 Unicode 字符编号,ASCII 字符只需 1 字节,拉丁字母和希腊字母需要 2 字节,常用的中文字符需要 3 字节,其他的一些生僻字符需要 4 字节(最常用)。
- UTF-16 编码:最短字节长度为 16 比特,即使用 2 或 4 字节来表示一个字符。所有的 ASCII 字符和常用的非英文字符,都用 2 字节表示;少数字符需要用到 4 字节表示。对于 2 字节的字符,UTF-16 编码与 Unicode 码点相等。
- UTF-32 编码:最短字节长度为 32 比特,每个字符都使用 4 字节。这意味着 UTF-32 比 UTF-8 和 UTF-16 更占用空间,特别是对于 ASCII 字符占比较高的文本。
建议
从存储空间占用的角度看,使用 UTF-8 表示英文字符非常高效,因为它仅需 1 字节;使用 UTF-16 编码某些非英文字符(例如中文)会更加高效,因为它仅需 2 字节,而 UTF-8 可能需要 3 字节。从兼容性的角度看,UTF-8 的通用性最佳,许多工具和库优先支持 UTF-8 。
目前国际上使用最广泛的 Unicode 编码方法是 UTF-8 编码。我国一些政府机关进行信息化建设时,也会要求文档应使用 UTF-8 编码存储。

UTF-8 的编码规则并不复杂,分为以下两种情况:
- 对于长度为 1 字节的字符,将最高位设置为 0 ,其余 7 位设置为 Unicode 码点。这就带来了一个额外的好处,ASCII 字符在 Unicode 字符集中占据了前 128 个码点和 UTF-8 编码是一样的。也就是说,UTF-8 编码可以向下兼容 ASCII 码,将 ASCII 编码可以看成是 UTF-8 编码的一部分,这意味着大量只支持 ASCII 编码的历史遗留软件可以在 UTF-8 编码下继续工作,并且我们还可以使用 UTF-8 来解析年代久远的 ASCII 码文本。
- 对于长度为 字节的字符(其中 ),将首个字节的高 位都设置为 1 ,第 位设置为 0 ;从第二个字节开始,将每个字节的高 2 位都设置为 10 ;其余所有位用于填充字符的 Unicode 码点。
| 字节 | 格式 | 实际编码位 | 码点范围 |
|---|---|---|---|
| 1字节 | 0xxxxxxx | 7 | 0 ~ 127 |
| 2字节 | 110xxxxx 10xxxxxx | 11 | 128 ~ 2047 |
| 3字节 | 1110xxxx 10xxxxxx 10xxxxxx | 16 | 2048 ~ 65535 |
| 4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 | 65536 ~ 2097151 |
提醒
这里有一个问题,为什么 UTF-8 要将其余所有字节的高 2 位都设置为 10 呢?实际上,这个 10 能够起到校验符的作用。假设系统从一个错误的字节开始解析文本,字节头部的 10 能够帮助系统快速判断出异常,因为在 UTF-8 编码规则下,不可能有字符的最高两位是 10 。这个结论可以用反证法来证明:假设一个字符的最高两位是 10 ,说明该字符的长度为 1 ,对应 ASCII 码。而 ASCII 码的最高位应该是 0 ,与假设矛盾。
下图展示了“Hello算法”对应的 UTF-8 编码。观察发现,由于最高 位都设置为 1 ,因此系统可以通过读取最高位 1 的个数来解析出字符的长度为 。

另外,在浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF-8 编码再传输到浏览器,所以你看到很多网页的源码上会有类似 <meta charset="UTF-8"> 的信息,表示该网页使用的 UTF-8 编码。

建议
总结一下 UTF-8 编码的优点:兼容 ASCII 码、表示英文字符非常高效、网页编码最为常见、软件通用性最佳。
逆向编码
发现问题
某公厕分别用中文,英文,日语和韩语写了下面一段提示:向前一小步,文明一大步。这种提示在男厕所基本上是见怪不怪了,但关键是下面还有一段用 0 和 1 组成的数字,作为一个程序员能敏锐的感觉到这应该就是上面中文的二进制表示方式。

大胆猜测
汉字在计算机中存储常见的字符集编码有 GBK,UTF-8 等,其中 UTF-8 是一种可变长字符编码,怎么确定一个字符占几个字节呢?这就和上面讲的 UTF-8 编码规则有关,如果是一个字节,那么最高位就是 0(就是上面讲 ASCII 所介绍的扩充比特),剩下的 7 个比特可以表示 128 种状态,这些字符对应 ASCII 的 128 个字符。如果是两个字节会以 110 开头,三个字节是 1110 开头,四个字节是 11110 开头……。上面的二进制很多地方出现了连续的 3 个 1,大胆猜测应该使用的是 UTF-8 编码。
进行验证
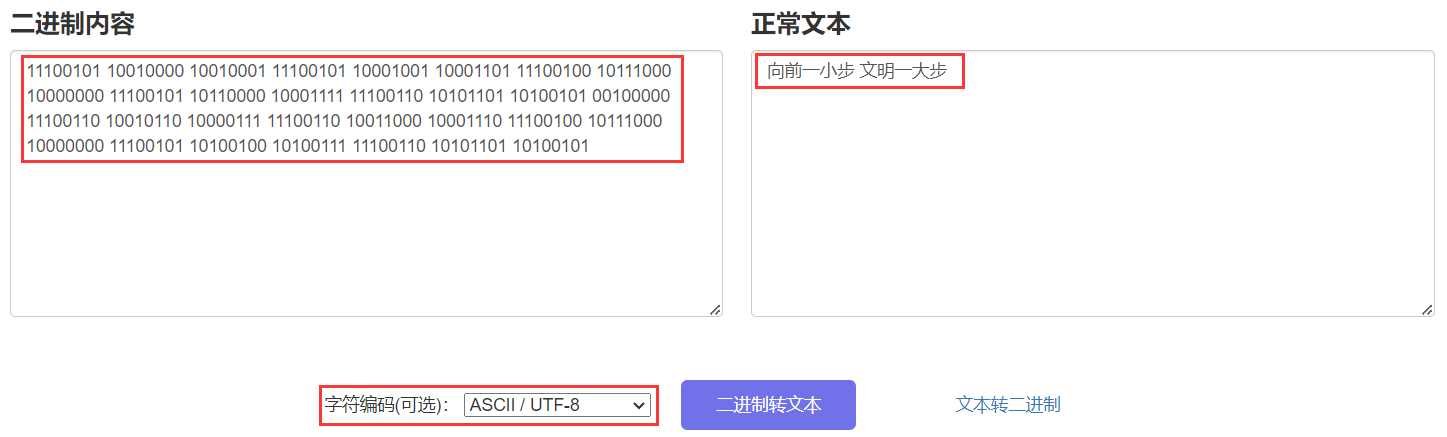
我们再来看下公厕的二进制编码,它是以 1110 开头的,所以第一个字符肯定是三个字节,也就是 24 个比特,我们截取前面 24 位来转换下,具体为 11100101 10010000 10010001,通过二进制文本在线转换工具转换得到的字符就是“向”。

所以我们猜测它使用的 UTF-8 编码是正确的,后面我们全部转化看一下,结果和中文提示一模一样:
文本文件
提到文本文件,最先想到的就是 Windows 自带的记事本,用它保存的就是 txt 格式的文本文件,内部运行原理如下:打开文本文件的时候,计算机会读取文件中的内容统一编码为 Unicode 存放到内存当中;当保存修改或传输的时候,Unicode 就被编码为占用空间更小、传输更快的 UTF-8 编码。
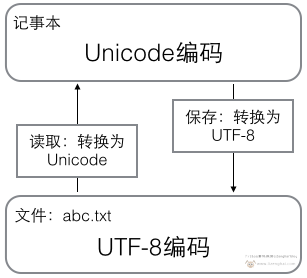
ANSI
在 Win7、Win8 以及 Win10 较早期的中文版中,它们自带的记事本用的是所谓的 ANSI,这个其实只是一个代码页指针,它在不同语言系统中所代指的实际编码不同,在简体中文系统中,它就是 GBK 编码,在繁体中文系统中,它就是 Big5 编码,在日文系统中,它就是 JIS 编码,但现如今新版的 Windows 系统已经把记事本的默认编码改成了 UTF-8。

BOM
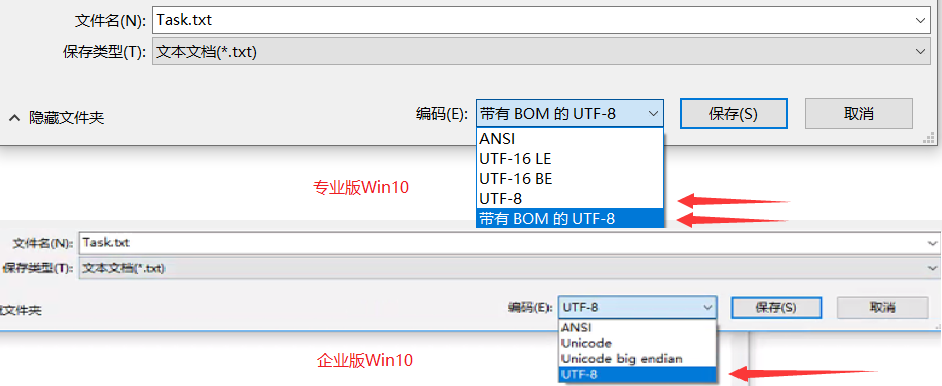
当我们在记事本中进行内容保存时,在专业版 Win10 系统中,会有两个 UTF-8 选项,分别是 [UTF-8、带 BOM 的 UTF-8],而企业版 Win10 系统中,就只有一个 UTF-8 选项,就是 [带 BOM 的 UTF-8]。
所谓的 “BOM”,全称是"ZERO WIDTH NO-BREAK SPACE",即字节序标记字符,是国际标准化组织为各种语言字符制定的编码标准。通过 BOM 可以表明这个字节流是 Big-Endian(大头),还是 Little- Endian(小头)。UTF-16 为双字节,UTF-32 为四字节,他们均有大头与小头的区别,而 UTF-8 不存在字节序,因此也就不需要 BOM 来表明字节序,但可以用 BOM 来表明编码方式。这里我们做一个测试,将“编码”两字存入不同的编码文本,再查看十六进制编码分析得出下表:
| 文档编码 | 十六进制编码 | BOM | 解释 |
|---|---|---|---|
| UTF-32BE | FF FE 00 00 7F 16 78 01 | FF FE 00 00 | Big-Endian(BE,大头),高位字节在前,低位字节在后。 |
| UTF-32LE | 00 00 FF FE 16 7F 01 78 | 00 00 FE FF | Little-Endian(LE,小头),低位字节在前,高位字节在后。 |
| UTF-16 BE | FE FF 7F 16 78 01 | FE FF | Big-Endian(BE,大头),高位字节在前,低位字节在后。 |
| UTF-16 LE | FF FE 16 7F 01 78 | FF FE | Little-Endian(LE,小头),低位字节在前,高位字节在后。 |
| 带有 BOM 的UTF-8 | EF BB BF E7 BC 96 E7 A0 81 | EF BB BF | UTF-8 编码的 BOM 只用来表明编码方式。 |
| UTF-8 | E7 BC 96 E7 A0 81 | 无 | UTF-8 不需要 BOM 来表明字节顺序。 |
CR、LF、CRLF
这里顺带解释一下 CR、LF、CRLF 三个词的含义:
CR:即 Carriage Return,对应 ASCII 中转义字符\r,表示回车,即光标回到当前行最左边的位置,即水平位置改变,垂直位置不变。LF:即 Linefeed,对应 ASCII 中转义字符\n,表示换行,即光标在当前位置下移一行,即水平位置不变,垂直位置改变。CRLF:即 Carriage Return & Linefeed,对应 ASCII 中转义字符\r\n,表示回车并换行,即光标移动至下一行最左边的位置,即水平位置改变,垂直位置改变。
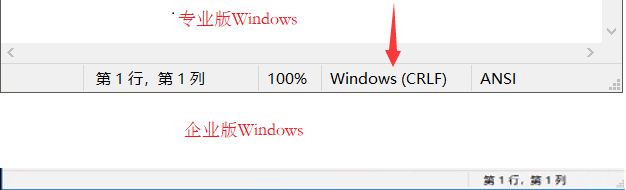
在专业版 Windows 系统中打开一个文本文档,在右下角会显示一个 Windows(CRLF) 表明 Windows 系统中采用的是回车并换行,而企业版的 Windows 中是不显示的。如下图:
乱码现象
产生原因
无论是保存文本文件,还是打开文本文件,编码方式的选择很重要,因为即使是同一串二进制数字,在不同的字符集和编码方式下,也会对应不同的字符。所以如果用错误的编码打开文本,乱码就来了。
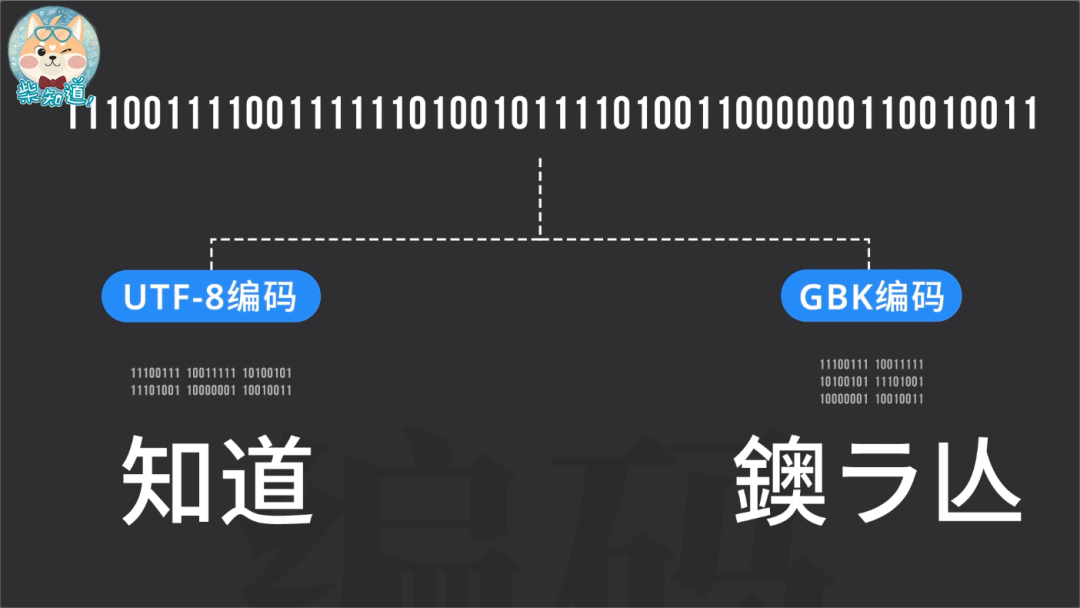
当你写出这段文字,点击保存,此时它们就被按照 GBK 编码存储成了这串二进制数字。
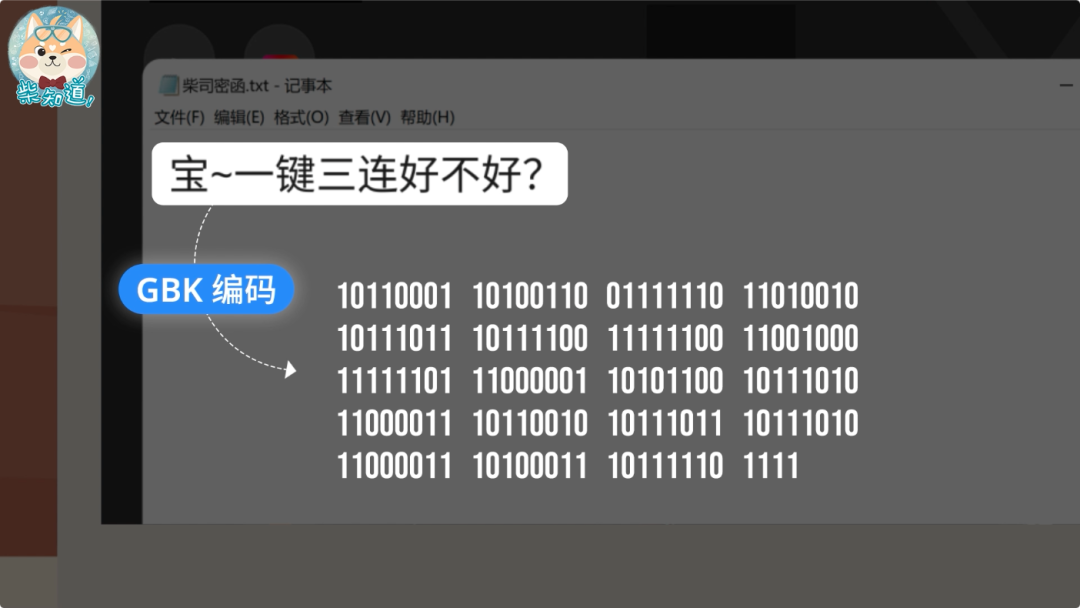
然后你把这份文档发给其他人,她用最常见的 UTF-8 编码打开。此时软件就懵逼了,因为它会发现这些东西根本无法正常显示。此时,Unicode 就会用这个替换符号 �,来展示所有无法正确显示的字符。
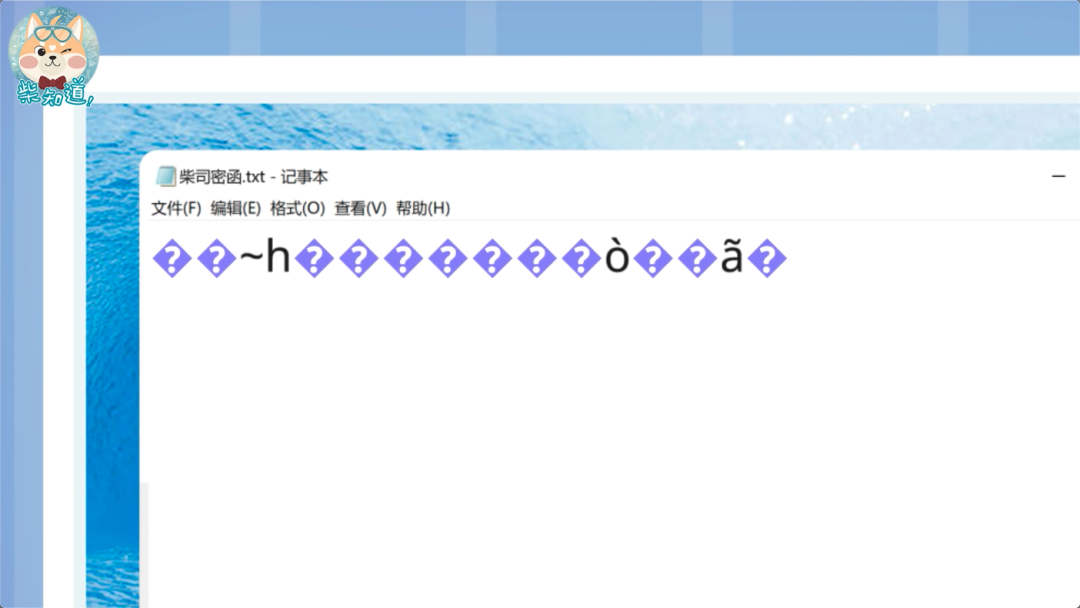
这时她也懵逼了,保存一下发给室友让她帮忙打开吧。在她点击保存的那一瞬间,文档中所有的 � 字符,就被根据 UTF-8 编码,编码为了 0xEF BF BD。而收到这份文件的大冤种室友,再次使用 GBK 编码打开了这份文档。此时根据 GBK 编码规则,如果有连续两个问号,那么 EFBF、BDEF、BFBD 这三个码位对应的,正是“锟斤拷”三个字。也就是说,连续两个问号,就对应了一个“锟斤拷”,一串问号,就对应了满屏的“锟斤拷”。经过这套操作,坍缩成了无穷无尽的“锟斤拷”。

而 Mac 上的“文本编辑”,以及一大堆其他软件,默认用的是UTF-8编码。所以你一不小心,就能搞出一份乱码文件。而“锟斤拷”还不是最离谱的。我们可以给你展示一个更灵异的现象:你拿一台安装了 Win7 的电脑,当你敲下“联通”两个字时,它就被记事本按照默认的 GBK 编码,编成了这串二进制数字,而当你再次打开它时,记事本会觉得,这串二进制数字的开头跟 UTF-8 编码的文件很像,于是就用 UTF-8 编码打开了它,显示出乱码。


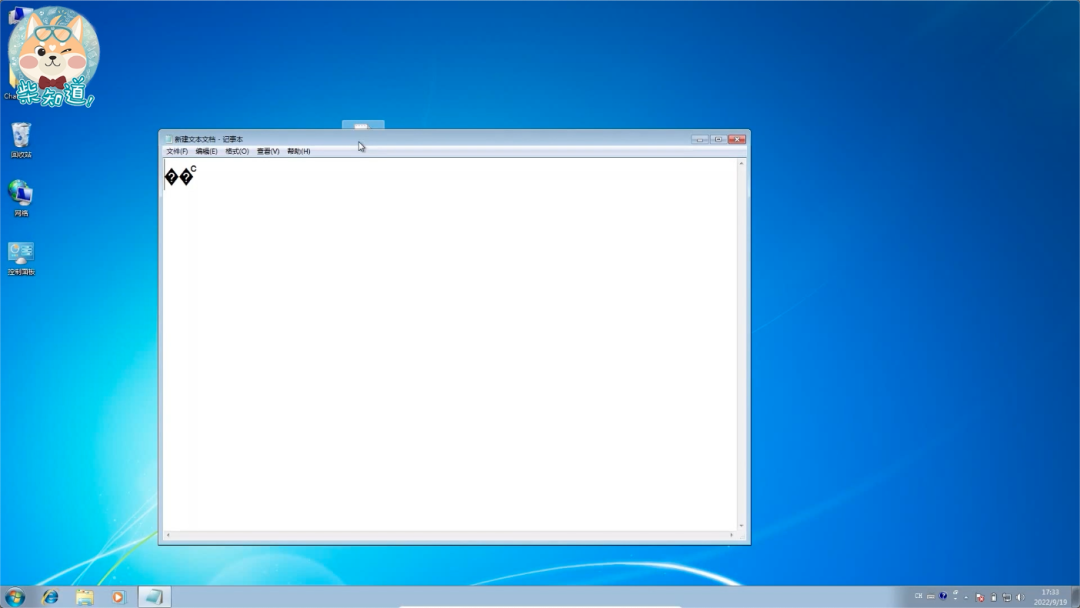
对照表格
其实现在,乱码的情况已经比之前少了很多。随着 Unicode 这座现代的巴别塔越盖越高,采用它的软件也越来越多,**如今新版的 Windows 系统已经把记事本的默认编码改成了 UTF-8 。**但在地球各地,很多老设备、老软件,你不知道里面装着什么样的字符集,用着哪些编码,所以这里提供了一个乱码对应表:简单讲,当字符的编码和解码使用的字符集不一样,就有可能会出现乱码或报错。
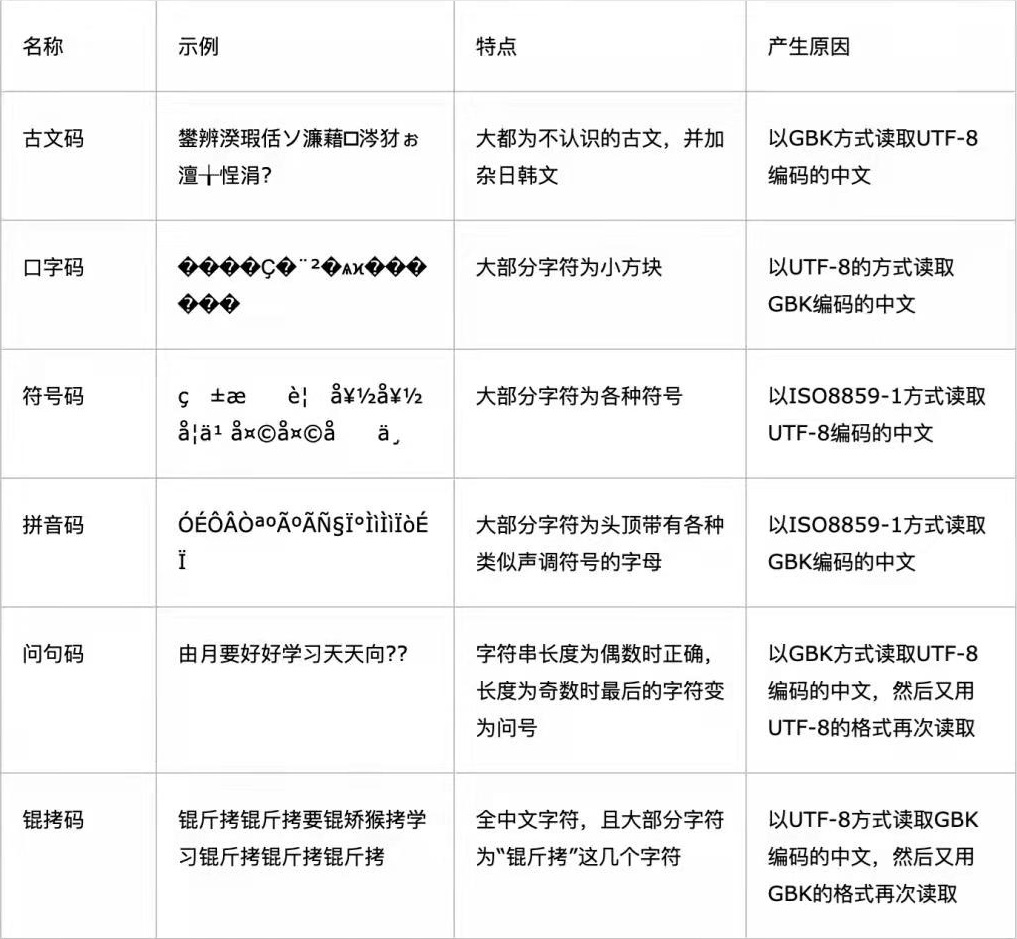
警告
乱码对应表中有一个 ISO-8859-1 编码,它又被叫做 latin-1 或”西欧语言“,可以处理英文字符,但不能处理中文字符,所有的中文字符全部乱码,想解码还原都不行,这个编码对于中文来说可以“编码黑洞”。