网页干扰
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
目前,我们已经能够从一些网页上抓取数据了,还有一类网页就不是很好“对付”了,那就是含有人为干扰的网页。干扰网页的方式有很多,例如 woff 字体、CSS 样式、JS 加密数据等,可以说是五花八门。对于安全公司来说干扰网页有两大基本要素:1. 让浏览器正常访问,不影响用户体验;2. 让爬虫脚本难以获取明文数据,严重阻止爬虫工程师的工作。
woff字体干扰
加密介绍
woff 字体干扰:当你在网页上浏览时,浏览器会使用操作系统提供的字体来渲染文本。而 woff 字体加密就是网页设计者使用 Web Fonts 将一种特定的字体库来代替系统的字体库在浏览器显示的过程,一般字体加密的数量都不会太大。
woff 字体文件:Web 开放字体格式(web open font format,简称woff),字体格式文件的后缀名就是 .woff,该文件在 CSS 中需要使用 @font face 规则引用。
实战解析
难度:简单
访问题目测试网址,明确任务目的,确定返回数据的接口,发现返回的数据中 value 的值被编码,猜测被编码的数据就是页面中胜点数据,可以看到编码和胜点值是一一对应的关系,虽然我们可以总结出编码和数字对应的关系,但是这个编码并不是一成不变的,也就是说,当前图中的编码  对应的值是 3,当再次刷新这个页面的时候,编码就可能变成了 졤 对应的值是 3,而且刷新网页仔细观察还可以看到网页中的 3 这个数值的轮廓和像素点也会有微小的变化,即动态字体加密。另外,在返回的数据下方还有一个 woff 数据,猜测这是一个经过 Base64 编码的字体文件内容:
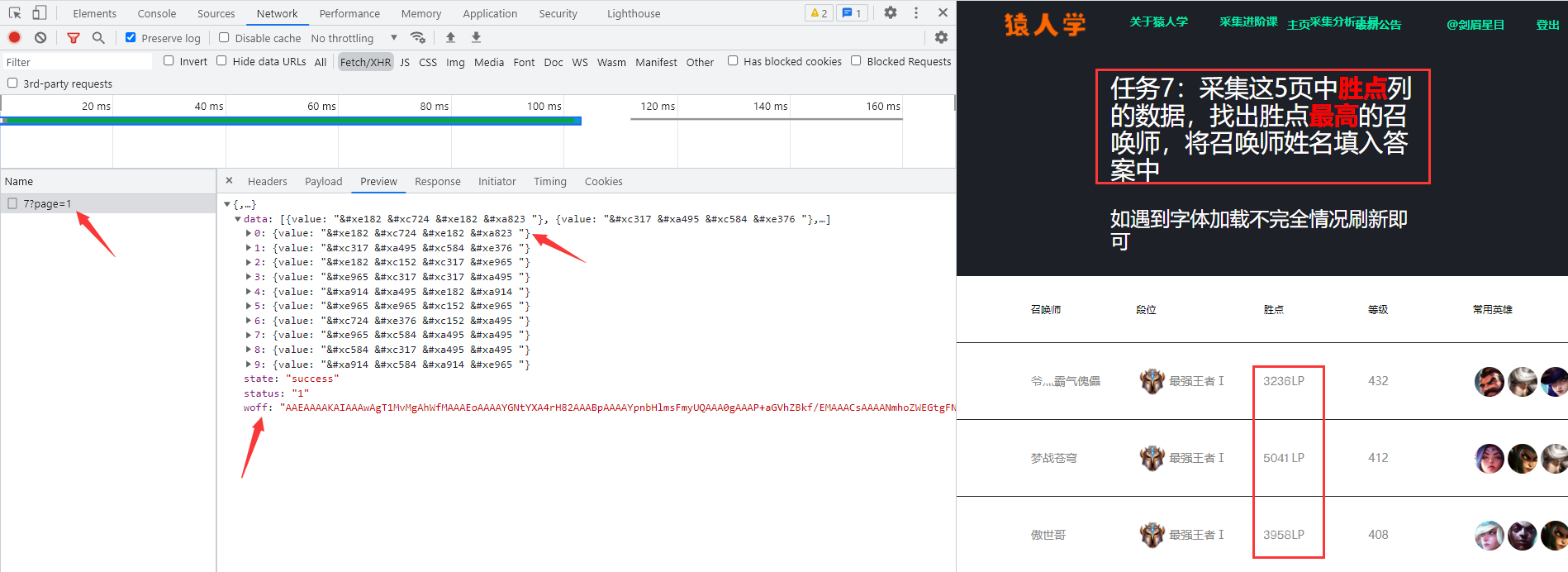
现在我们点击请求中 initiator 选项卡,再点击 request 后面的数字部分,跳转到发送 Ajax 请求的地方:
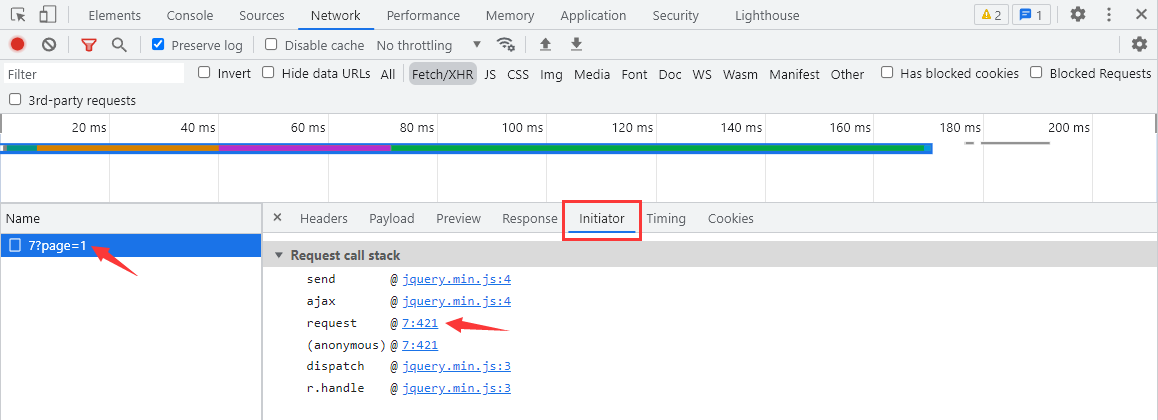
可以看到当 Ajax 请求成功后,网页通过 @font-face 使用了响应中的 woff 数据,这就更加确定该数据是一个经过 Base64 编码的字体文件内容。另外,初始化的玩家为 mad 中的 九不想乖,但玩家名称会被后面所替换,从代码来看玩家生成的顺序就是玩家列表 name 中第2个到第51个:
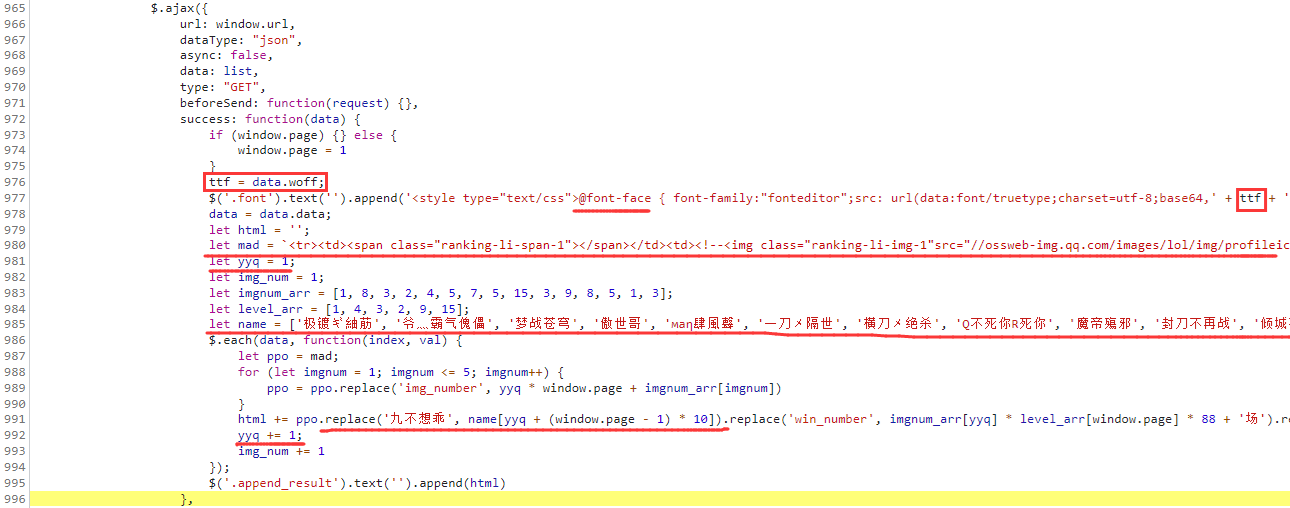
现在我们将响应内容中的 woff 数据通过 Base64 解码后,保存为 woff 文件,由于 woff 文件看不出来字体和编码的对应规律,因此我们将 woff 文件转换为 xml 文件,因为 xml 是一种用于标记电子文件使其具有结构性的可扩展标记语言:
python
from fontTools.ttLib import TTFont
woffb64 = response.json().get('woff')
with open('tt.woff', 'wb') as f:
f.write(base64.b64decode(woffb64.encode()))
TTFont('tt.woff').saveXML('tt.xml')在 xml 文件里面主要包含有三部分信息:GlyphOrder 存储字形排序、cmap 存储 code 和 name 的映射关系、glyf 存储字体轮廓信息。在 img1 中我们可以看到 GlyphOrder 中 id="4" 对应 unif7e2 ,在 img2 中 cmap 的 unif7e2 与 0xf7e2 对应,在 img3 中可以看到 name="unif7e2" 下面的轮廓线条,里面 <contour> 代表轮廓,<pt> 中 x、y 代表坐标,on="0" 表示弧形,on="1" 表示矩形。
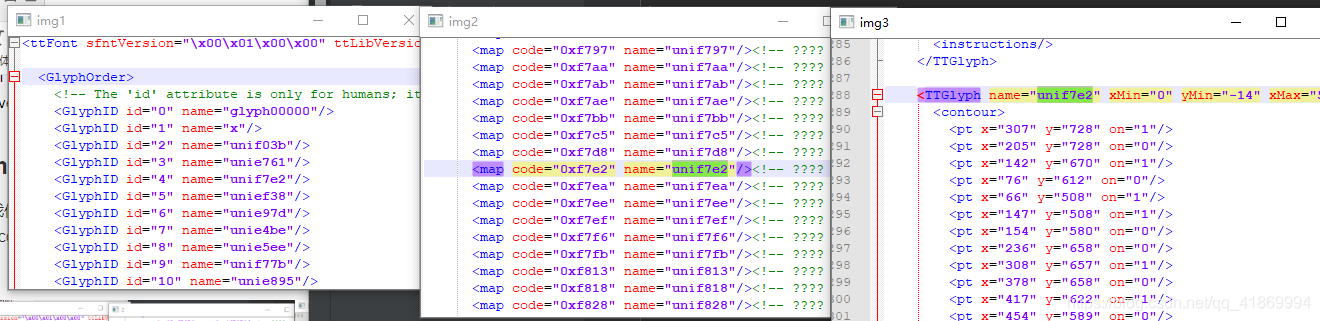
接下来我们选取一个 <contour> 轮廓,用 matplotlib 库描绘出来,从结果图中可以看到,这段代码所要表达的数字是 2:
python
import re
import matplotlib.pyplot as plt
glyf = """
<contour>
<pt x="310" y="728" on="1"/>
<pt x="202" y="728" on="0"/>
<pt x="69" y="585" on="0"/>
<pt x="68" y="465" on="1"/>
<pt x="150" y="465" on="1"/>
<pt x="152" y="560" on="0"/>
<pt x="194" y="608" on="1"/>
<pt x="233" y="659" on="0"/>
<pt x="307" y="658" on="1"/>
<pt x="377" y="658" on="0"/>
<pt x="455" y="587" on="0"/>
<pt x="455" y="521" on="1"/>
<pt x="455" y="452" on="0"/>
<pt x="400" y="393" on="1"/>
<pt x="372" y="364" on="0"/>
<pt x="288" y="304" on="1"/>
<pt x="175" y="226" on="0"/>
<pt x="133" y="177" on="1"/>
<pt x="62" y="98" on="0"/>
<pt x="62" y="0" on="1"/>
<pt x="538" y="0" on="1"/>
<pt x="538" y="73" on="1"/>
<pt x="163" y="73" on="1"/>
<pt x="183" y="145" on="0"/>
<pt x="319" y="237" on="1"/>
<pt x="430" y="313" on="0"/>
<pt x="467" y="352" on="1"/>
<pt x="537" y="427" on="0"/>
<pt x="537" y="614" on="0"/>
<pt x="409" y="728" on="0"/>
</contour>
"""
x = [int(i) for i in re.findall(r'<pt x="(.*?)" y=', glyf)]
y = [int(i) for i in re.findall(r'y="(.*?)" on=', glyf)]
plt.plot(x, y)
plt.show()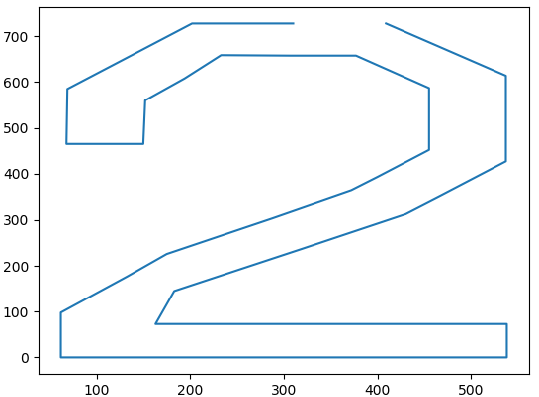
**既然我们可以通过轮廓代码来绘制出数字,得到数字和代码的对应关系,那么我们就可以先保存一组数字的轮廓,等下一组数字的轮廓过来后,通过轮廓的相似度来确定数字。这样的话,即使数字体轮廓有或多或少的变化,也不会影响对数字的判断,因为数字的大体轮廓是不会有很大变化的。**核心代码如下:
python
import io
import re
import os
import base64
import requests
from fontTools.ttLib import TTFont
# 数字轮廓
digital_contour = {
'0': [(298, 719), ...],
'1': [(283, 710), ...],
'2': [(310, 719), ...],
'3': [(305, 719), ...],
'4': [(381, 710), ...],
'5': [(107, 710), ...],
'6': [(310, 719), ...],
'7': [(66, 710), ...],
'8': [(298, 719), ...],
'9': [(280, 719), ...]
}
# 遍历字体轮廓,返回轮廓最相似的数字
def confirm_num(shape):
store = {}
for num in digital_contour:
score = 0
num_shape = digital_contour[num]
for index in range(len(shape)):
x = shape[index][0]
y = shape[index][1]
if index > len(num_shape) - 1:
x_1 = 0
y_1 = 0
else:
x_1 = num_shape[index][0]
y_1 = num_shape[index][1]
score += ((x-x_1)**2 + (y-y_1)**2)
store.update({num: score})
# 返回分数最小的数字
return min(zip(store.values(), store.keys()))[1]
# 请求响应
url = 'https://match.yuanrenxue.cn/api/match/7?page=1'
# 提取woff数据
woffb64 = requests.get(url=url, headers=headers, verify=False).json().get('woff')
# 以font文件的格式加载base64解码后的woff数据
tt_data = TTFont(io.BytesIO(base64.b64decode(woffb64)))
# 获取cmap中的对应关系,{41603: 'unia283', 42311: 'unia547'...}(十进制编码对应字体轮廓编号)
ship_map = tt_data['cmap'].getBestCmap()
# 保存数值
all_data = []
# 循环解析字体
for data in response.json().get('data'):
n_value = ''
for d in data.get('value').split(' ')[:-1]:
# 网页中的编码为16进制,我们将其转换为十进制编码
key = eval(d.replace('&#', '0'))
# 通过十进制编码获取对应的字体轮廓
shape = list(tt_data['glyf'][ship_map[key]].coordinates)
# 返回字体轮廓最相近的数字
n_value += confirm_num(shape)
all_data.append(int(n_value))
print(all_data) # 输出:[3236, 5041, 3958, 8550, 7037, 8898, 2190, 8400, 4500, 7478]。注释:和网页一样。CSS样式干扰
加密介绍
CSS 样式干扰:CSS 在前端当中主要影响的是样式,它能够对网页中元素位置的排版进行像素级精确控制,支持几乎所有的字体字号样式,拥有对网页对象和模型样式编辑的能力,因此通过 CSS 主要是对前端展示的样式进行了加密或干扰。
实战解析
难度:简单
打开 Chrome 浏览器及开发者工具,访问题目测试网址,明确任务目的,确定返回数据的接口,发现返回的是 Base64 编码的图片:
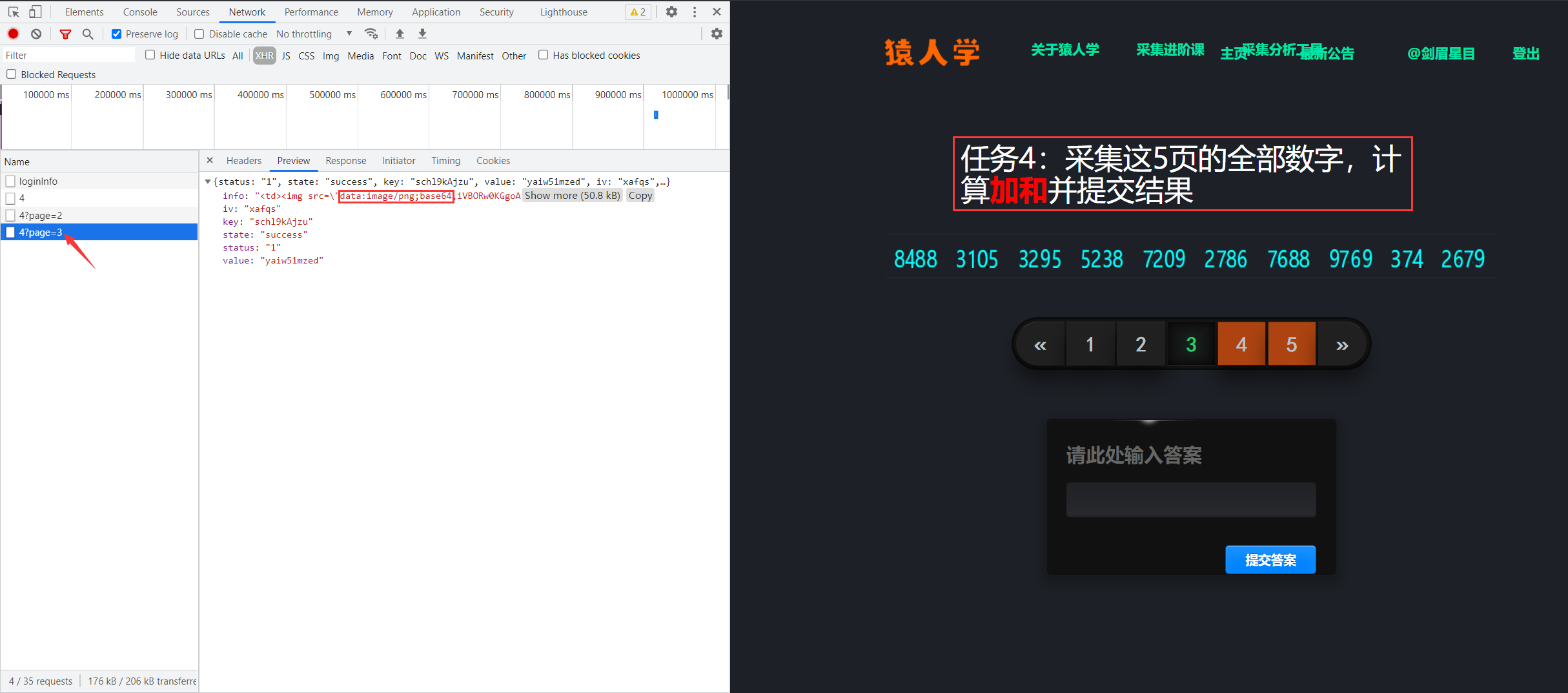
我们将鼠标移至数字旁点击右键,发现有“图片另存为”选项,说明返回的是包含数字的图片:
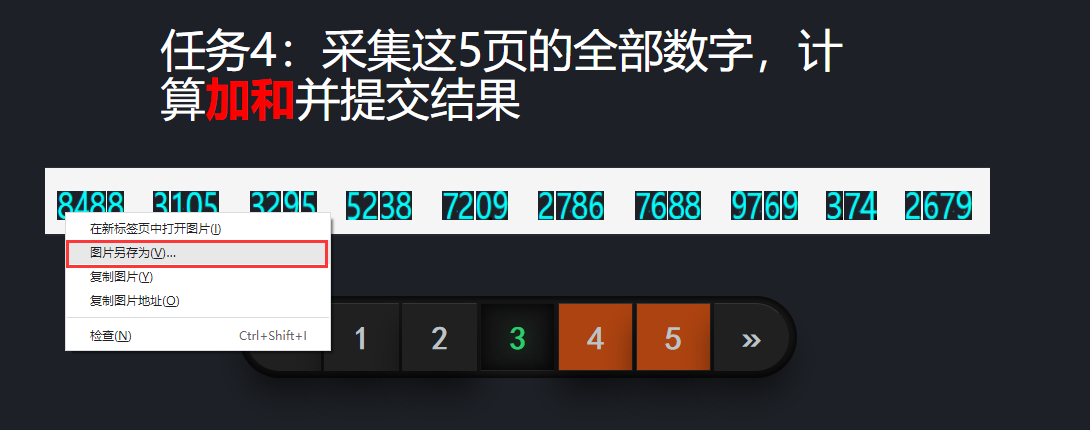
这时我们点击开发者工具的左上角,在点击图片元素,看看在前端代码中是怎样展示的,经过多组比对我们得到如下规律:
- 每组的数字是 4 个,对应每组 4 个
img标签,若有 5 个img标签的,则必有一个标签的style属性中包含display: none,也就意味着该标签不会在网页中展示。 - 相同数字的
img标签的src属性是一样的。 - 数字的
img标签中style属性中的left内容控制数字展示的相对位置,主要就是三个值:负数、零、正数,且值都是 11.5 的倍数。
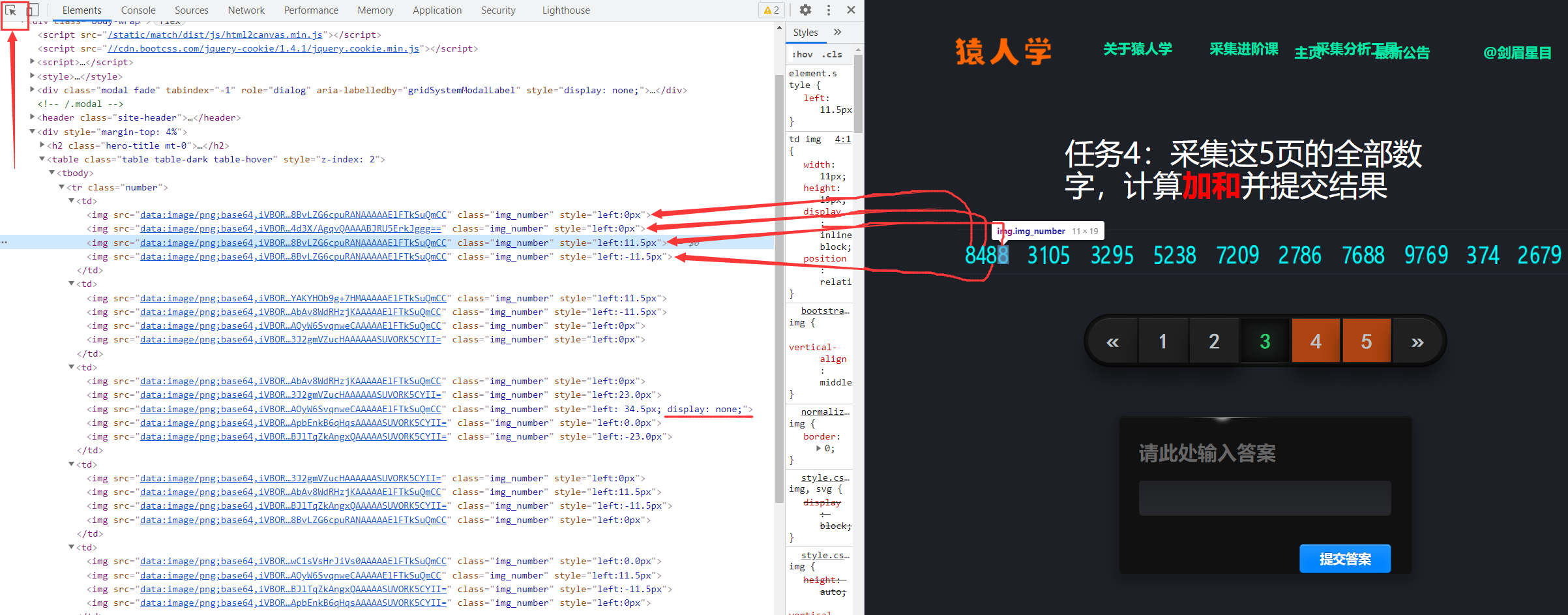
然后我们将响应的内容拷贝出来发现,img_number 后面有一串被加密的参数:
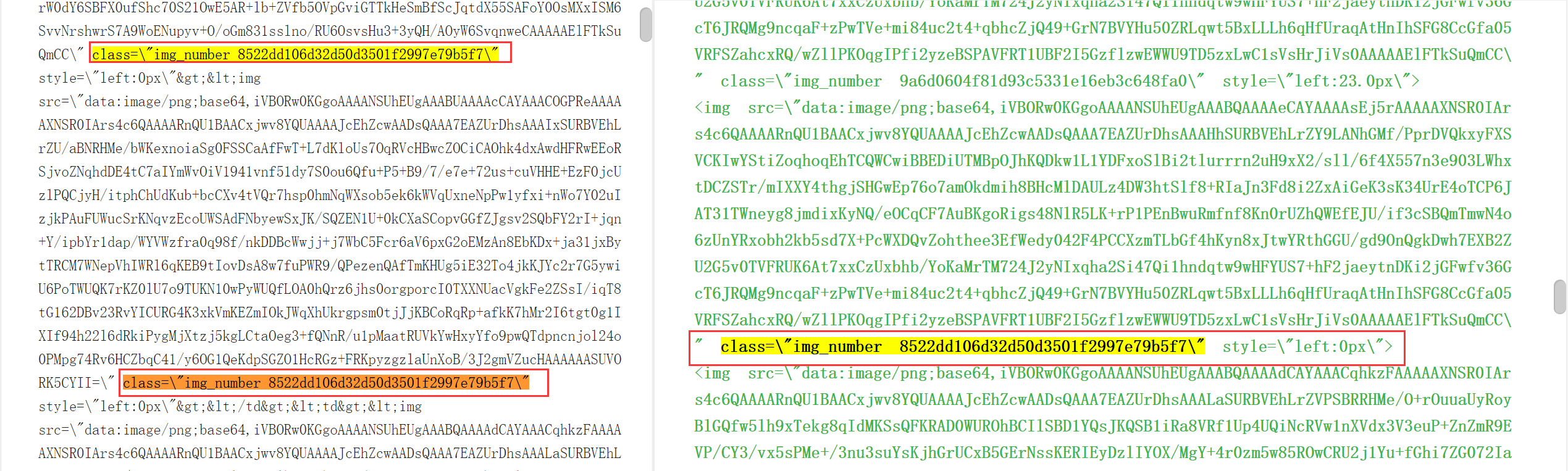
于是定位请求发送位置,发现了 MD5 哈希,也就是说数据是否展示,是通过响应内容 key 和 value 的和的 MD5 值共同决定的,理解到这一层,就基本破解了 CSS 干扰了:
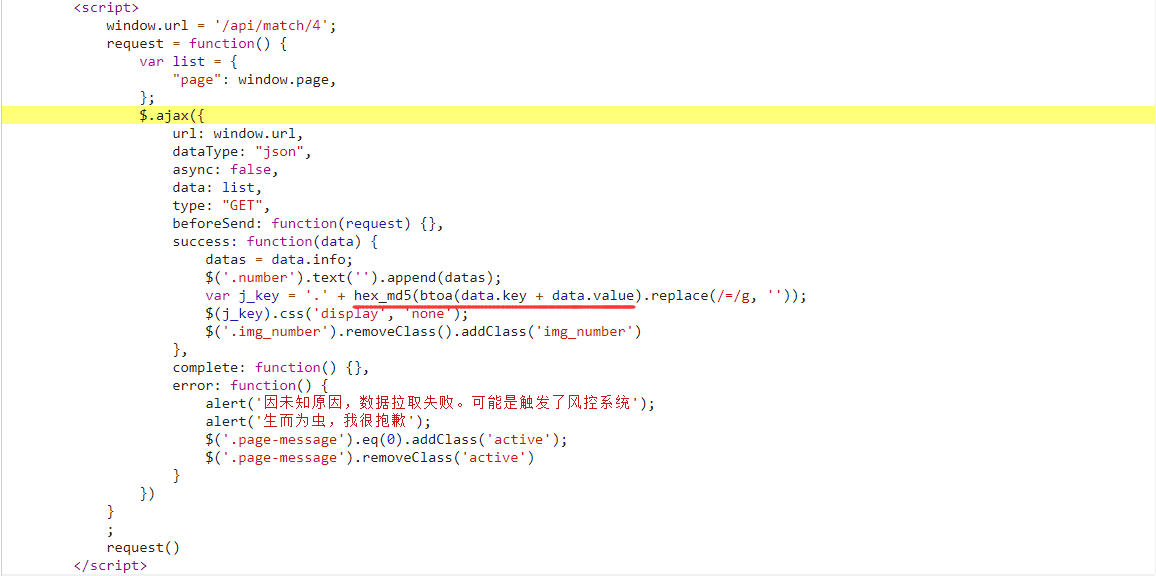
JS加密干扰
在所有干扰网页的方式中,JS 加密可以说是最常见的干扰方式了。
POST加密
POST 加密:通过 JS 加密 POST 提交的表单参数,经过加密后表单参数通常不可读。
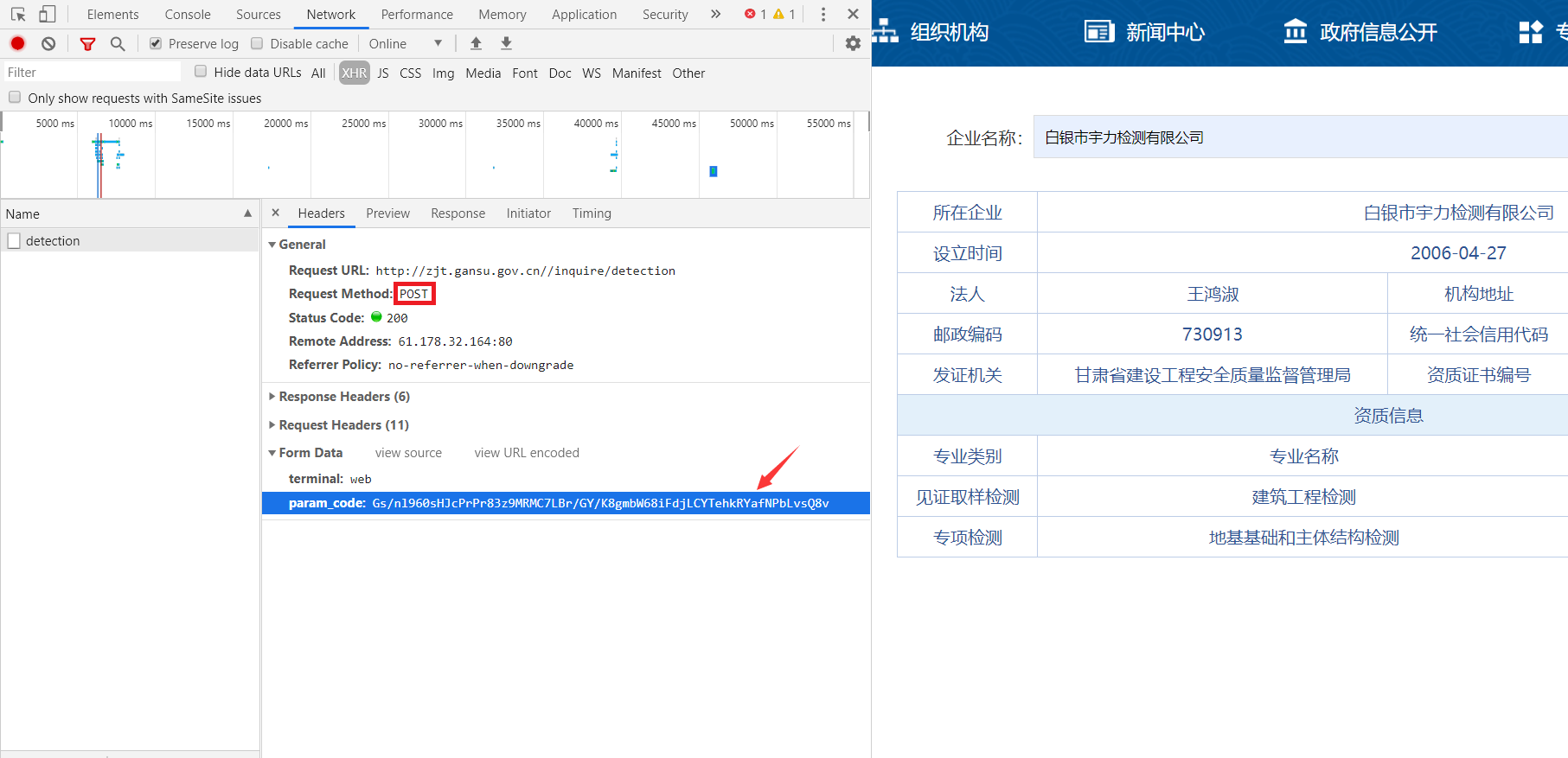
Cookie加密
Cookie 加密:通过 JS 加密 Cookie 参数,凭借加密后的 Cookie,服务器才会返回正确的响应内容。
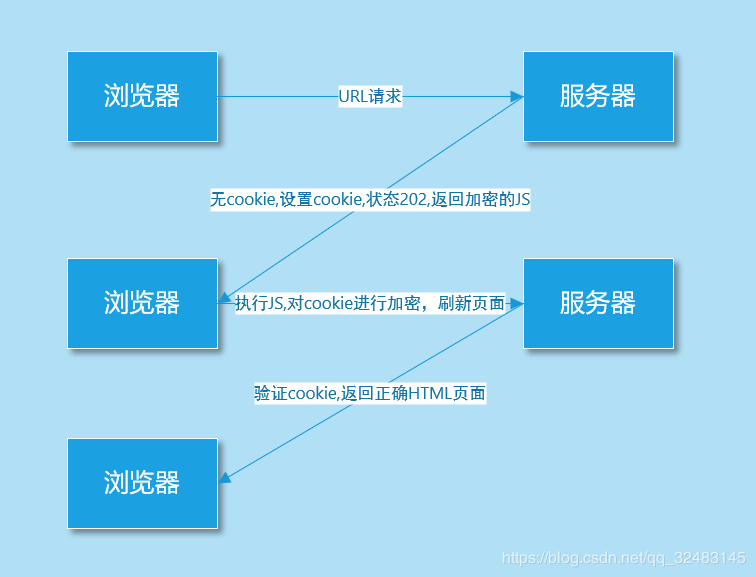
破解加密思路
破解 JS 加密主要有三种方案:
方案一:把 JS 代码翻译成 Python 代码,这个是有难度的,因为爬虫偏向于后端的处理,JS 属于前端,需要精通前端才行,还有一点就是经过加密、混淆、压缩后的 JS 代码阅读性很差。(技术要求偏高,不建议)
方案二: 抠 JS 代码,使用 Python 的一些第三方库比如 execjs 库去执行 JS 代码。(需要学习JS逆向,建议)
方案三:使用 Selenium 或者 Appiun 等自动化框架,驱动浏览器抓取数据,因为浏览器可以直接执行 JS 文件,因此可以基本无视 JS 加密。(效率低,稳定性差,不建议)