Scrapy框架【初识】
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
Scrapy 是一个网络爬虫库,它允许用户以声明式的方式定义如何爬取网站数据,并提供了灵活高效的机制来处理爬取的数据。Scrapy 极大地提高了网络数据采集和效率和可靠性,它被广泛应用于各种领域,包括市场研究、竞争情报、数据聚合和搜索引擎索引等。

Scrapy 是一个纯 Python 实现的基于 Twisted 异步网络编程框架的爬虫框架,目前也是全世界开发爬虫最流行的框架,在招聘爬虫开发的岗位中,基本都会要求熟练使用 Scrapy 框架,因此我们需要好好钻研和掌握。回顾前面的学习,爬虫的工作流程可以总结为以下 5 个步骤:
- 设定抓取目标(种子页面 / 起始页面)并获取网页。
- 当下载页面出现错误时,按照指定的重试次数尝试重新下载页面。
- 通过正则表达式、XPath、CSS 等工具从下载页面中提取数据信息和链接信息。
- 将有用的数据信息进行持久化存储,以备后续的处理。
- 对链接信息进行进一步的处理,获取页面并重复上面的动作。
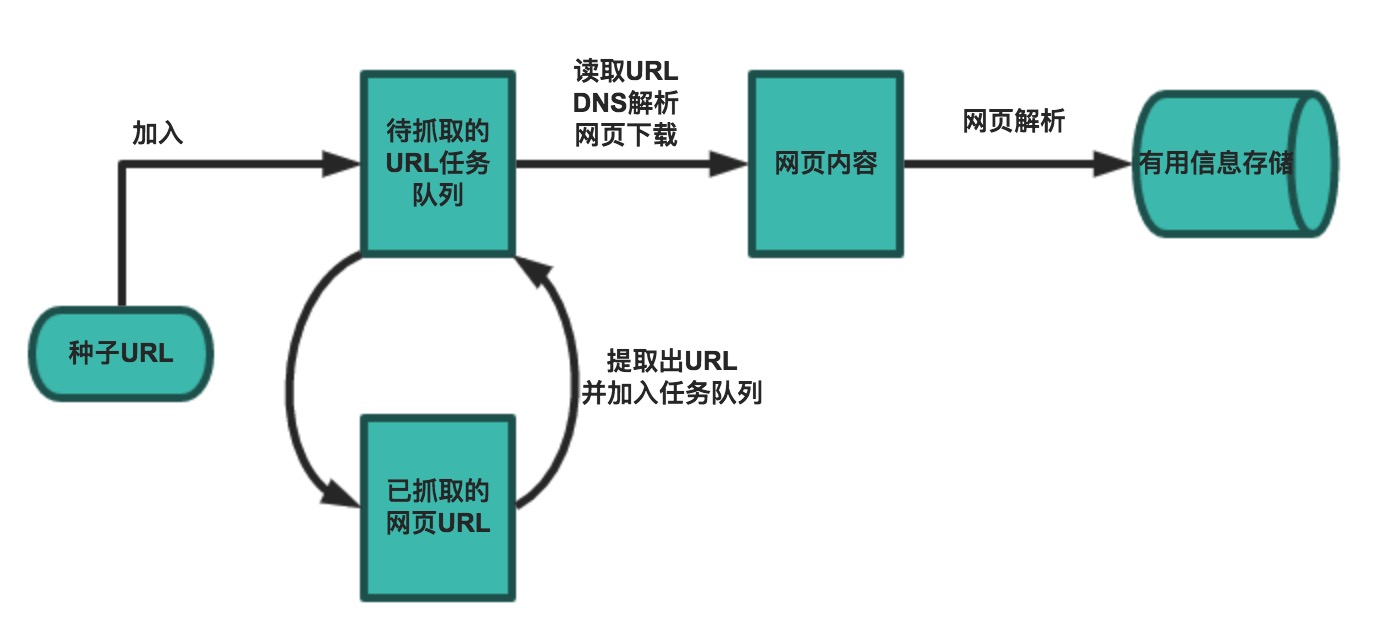
在 Scrapy 当中,我们可以理解为将上面的每一个步骤都单独写成了一个模块,每个模块只负责自己步骤的事情,这样模块之间的耦合程度低(相互影响小),可扩展性极强,可以灵活完成各种需求,我们只需要定制开发几个模块就可以轻松实现一个爬虫。
建议
所谓的“框架”,包含了两层含义:一种是“框”,含义就是限定范围,在使用框架时,我们所有的操作都必须符合框架的规则。另一种是“架”,含义就是基础功能,几乎所有的框架都是一个包含有基础功能的半成品,后续我们只需要在框架的基础功能继续新的开发就行了。
Scrapy 安装
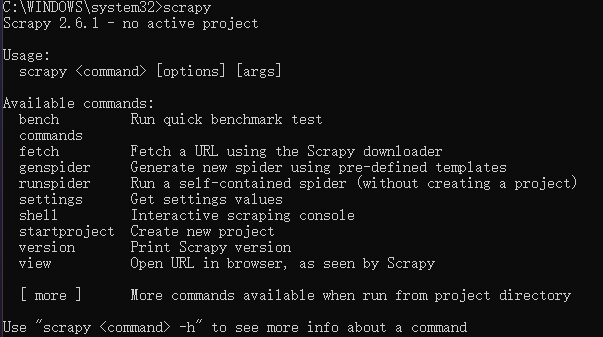
首先我们来安装 Scrapy 框架,在命令行中执行如下命令:
pip install scrapy成功安装了后,在命令行执行 scrapy 命令就会输出 Scrapy 版本和内置命令信息:
Scrapy 架构
Scrapy 架构由以下八大组件构成:
Engine引擎,负责整个系统的数据流处理、信号传递、事务触发,是整个框架的核心。Spiders爬虫,定义爬取的逻辑和网页解析规 ,主要负责解析响应并生成提取结果和新的请求。Spide Middlewares爬虫中间件,位于Engine和Spiders之间的钩子框架,主要处理Spiders输入的响应和输出的结果以及新的请求。Scheduler调度器,负责接受Engine发过来的请求,在Engine再次请求的时候将请求提供给Engine。Downloader下载器,负责发送网络请求并下载返回网页内容。Downloader Middlewares下载器中间件,位于Engine和Downloader之间的钩子框架,主要处理Engine与Downloader之间的请求及响应。Item项目,定义数据的结构字段。Item Pipelne项目管道,负责清洗、验证和存储由Spiders从网页中提取的Item项目。
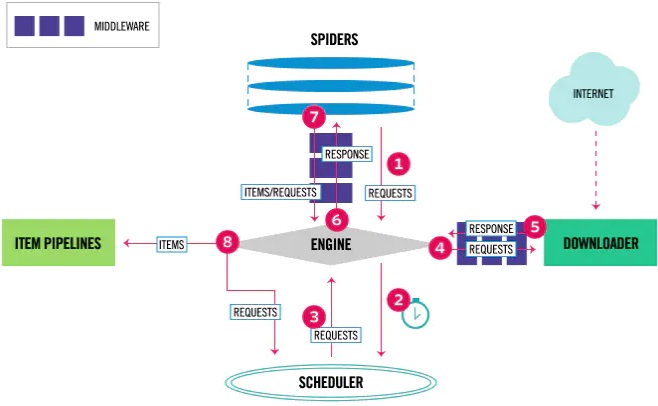
Scrapy 数据流
Scrapy 的数据流总共有九步:
- 启动爬虫项目时,
Engine根据爬取的站点找到处理该站点的Spider,这时Spider就会生成最初需要爬取的页面对应的一个或多个初始Requests请求。 Engine把从Spider获取的这些Requests都交给Scheduler进行调度。Engine向Scheduler索取下一个要处理的Request,Scheduler根据其调度逻辑选择合适的Request发送给Engine。Engine将Scheduler发来的Request转发给Downloader,转发的过程中Request会经由许多定义好的Downloader Middlewares进行加工处理(添加请求头、添加代理等)。Downloader将Request发送给目标服务器,得到对应的Response响应,然后将其返回给Engine,这个返回的过程中Response同样会经由许多定义好的Downloader Middlewares进行加工处理(判断状态码、判断完整性)。Engine从Downloader接收到的Response中包含了爬取的内容,Engine将此Response发送给对应的Spider进行处理,发送的过程中Response会经由许多定义好的Spider Middlewares进行加工处理。Spider对接收到Response进行解析,返回从内容中提取的一个或多个的Item数据以及一个或多个的Request后续请求,然后将Item、Request发送给Engine,发送的过程中Item、Request会经由许多定义好的Spider Middlewares进行加工处理。Engine将Spider发送过来的Item转发给定义好的Item Pipelne进行数据处理或存储,将Request转发给Scheduler等待下一次被调度。- 重复第二步到第八步直到
Scheduler中没有更多地Request,这个时候Engine就会关闭Spider,整个爬取过程结束。
Scrapy 项目
创建初始项目
首先,在命令行中执行下面命令,在当前路径下创建一个名称为 test1 的 Scrapy 项目:
scrapy startproject test1(项目名称)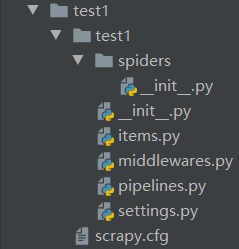
test1(存放整个项目的文件夹)
-test1(项目的根目录,即导包的基准目录)
-spiders(存放不同Spider文件的文件夹)
__init__.py
__init__.py
items.py(定义Item数据结构)
middlewares.py(定义Spider中间件、Downloader中间件)
pipelines.py(定义Item Pipeline管道)
settings.py(项目的全局配置)
scrapy.cfg(项目的配置文件路径、部署相关信息等内容)生成爬虫文件
执行下面命令进入到项目中,创建一个名称为 quotes 的爬虫:
# 进入test1项目
cd test1
# 创建一个名称为quotes的爬虫,采集的网络域名为quotes.toscrape.com
scrapy genspider quotes quotes.toscrape.com创建的爬虫文件会自动存放到 spiders 文件夹里,可以看到在 spiders 文件夹里面多出一个名称为 quotes.py 的爬虫文件。内容如下:
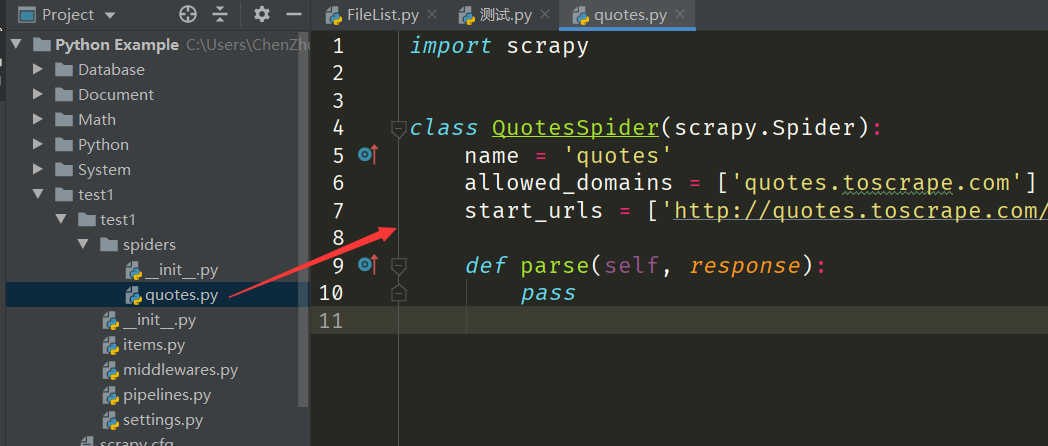
python
import scrapy
# QuotesSpider类通过命令建立,它继承自Scrapy提供的Spider类,即scrapy.Spider。
class QuotesSpider(scrapy.Spider):
# 爬虫名称,具有唯一性,用来区分不同的爬虫。
name = 'quotes'
# 域名过滤,用于过滤掉那些不在指定域名范围内的请求,若不需过滤可置为[]空列表(启动时自动生效)。
allowed_domains = ['quotes.toscrape.com']
# 起始链接,Spider启动时所爬取的URL列表(启动时自动生效)。
start_urls = ['http://quotes.toscrape.com/']
# 默认情况下,负责解析start_urls中链接返回的response响应,提取数据或者进一步生成要处理的请求。
def parse(self, response):
pass补充说明一点,上面的 QuotesSpider 类是继承自 scrapy.Spider 父类,因此里的 parse 方法会重写父类里面的 parse 方法,但由于重写方法的参数不一致,PyCharm 觉得这样写有风险,因此在方法里面显示淡黄色。

为了保持一致,我们进入到 scrapy.Spider 父类中查看 parse 方法,发现它还有一个 **kwargs 参数:

我们将 **kwargs 参数添加到重写的 parse 方法就会发现黄色消失了:

建议
爬虫中 start_urls 起始链接是根据我们给定的域名参数自动生成的,如果和我们要抓取的起始页面链接不同,可以修改 start_urls 列表中 URL 的内容。
添加全局配置
在前面介绍过 settings.py 文件的作用,就是针对当前项目中的所有爬虫进行全局配置,即默认使用的配置。常见的配置参数如下:
python
# 爬虫并发数,默认16
CONCURRENT_REQUESTS = 8
# 爬虫请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
# 下载超时时间(单位秒)
DOWNLOAD_TIMEOUT = 15
# 下载延迟时间(请求之间的时间间隔,单位秒)
DOWNLOAD_DELAY = 3
# 随机下载延迟,默认为True(开启)
RANDOMIZE_DOWNLOAD_DELAY = True
# Robot协议检查,默认为True(开启)
ROBOTSTXT_OBEY = False
# 自动重定向,默认为True(开启)
REDIRECT_ENABLED = True
# 当响应的状态码为403、404时,不会过滤(默认不会过滤状态码为200的响应)
HTTPERROR_ALLOWED_CODES = [403, 404]
# 当响应的状态码为500、503时,重新请求
RETRY_HTTP_CODES = [500, 503]
# 日志输出等级,低于当前等级的日志不输出(DEBUG、INFO、警告、ERROR、CRITICAL)
LOG_LEVEL = 'INFO'建议
**当我们开启 RANDOMIZE_DOWNLOAD_DELAY 随机下载延迟后,Scrapy 将在 DOWNLOAD_DELAY 下载延迟的 0.5 到 1.5 倍的范围内随机选择一个值作为实际的下载延迟。**如果你设置了 DOWNLOAD_DELAY 为 2 秒,而且 RANDOMIZE_DOWNLOAD_DELAY 为 True,那么实际的下载延迟将在 1 到 3 秒之间随机选择一个值。这种机制的目的是为了在平均下载延迟的基础上,引入一些随机性,以模拟更自然的网络请求行为,避免对服务器造成过于规律的负载。
重要
需要注意的是,settings.py 文件只会在爬虫启动的时候,进行一次全局配置,后续不在调用。所以针对爬虫通用的配置我们可以写入到该文件中,例如数据库的连接配置、Item 数据处理配置等。但一些相对灵活的参数,例如爬虫并发数、爬虫请求头、下载响应时间等,通过中间件或者爬虫局部配置来设置会更加符合采集情况。
定义数据字段
前面讲过 items.py 文件的作用是定义 Item 数据结构字段,创建 Item 需要继承 scrapy.Item 类,并定义类型为 scrapy.Field 的字段,也就是需要爬取的字段名称。代码如下:
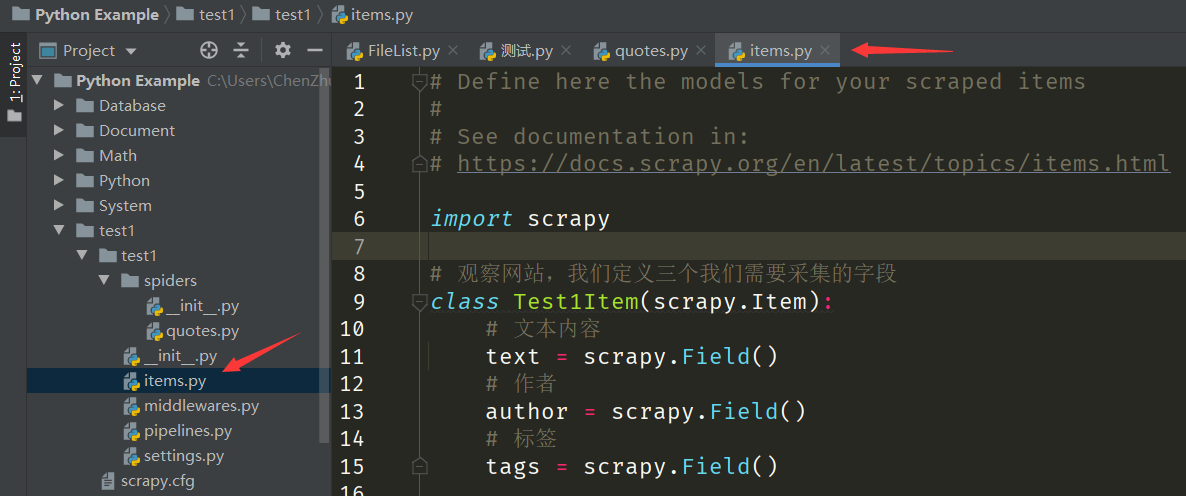
python
import scrapy
# 定义三个需要采集的字段
class Test1Item(scrapy.Item):
# 文本内容,一个字符串
text = scrapy.Field()
# 作者,一个字符串
author = scrapy.Field()
# 标签,字符串组成的列表
tags = scrapy.Field()重要
我们可以将 Test1Item 类中定义的 Item 数据字段看作一个内容为 {'text': None, 'author': None, 'tags': None} 的字典。如果要在字典中新增键,就需要在 Test1Item 类中新定义 Item 数据字段。另外就是,要保存的数据内容必须对应一个 Test1Item 类中定义的 Item 数据字段,这样做的目的就是要规范数据字段的定义以及数据的采集。
解析响应内容
定义好了数据字段,回到 quotes.py 爬虫文件中。前面我们讲过在 QuotesSpider 类中的 start_urls 起始链接就是爬虫启动后最先爬取的链接,然后 Scrapy 会将爬取到的结果包装为一个 Response 响应对象,里面不仅包含了 URL(响应链接)、Status(响应状态码)、Text(响应内容)等内容,甚至还可以直接调用 XPath、CSS 选择器进行数据提取。接着,Scrapy 会将 Response 响应对象赋值给 parse 方法中的 response 参数,这时 parse 方法就可以看作解析 start_urls 起始链接响应结果的方法。在 parse 方法中,我们可以直接对 response 参数包含的内容进行解析,提取出我们需要的 Item 数据,或者找出下一个请求的链接来生成请求。不过这里我们先解析 Response 响应的内容,给定义好的 Item 数据字段进行赋值并返回:
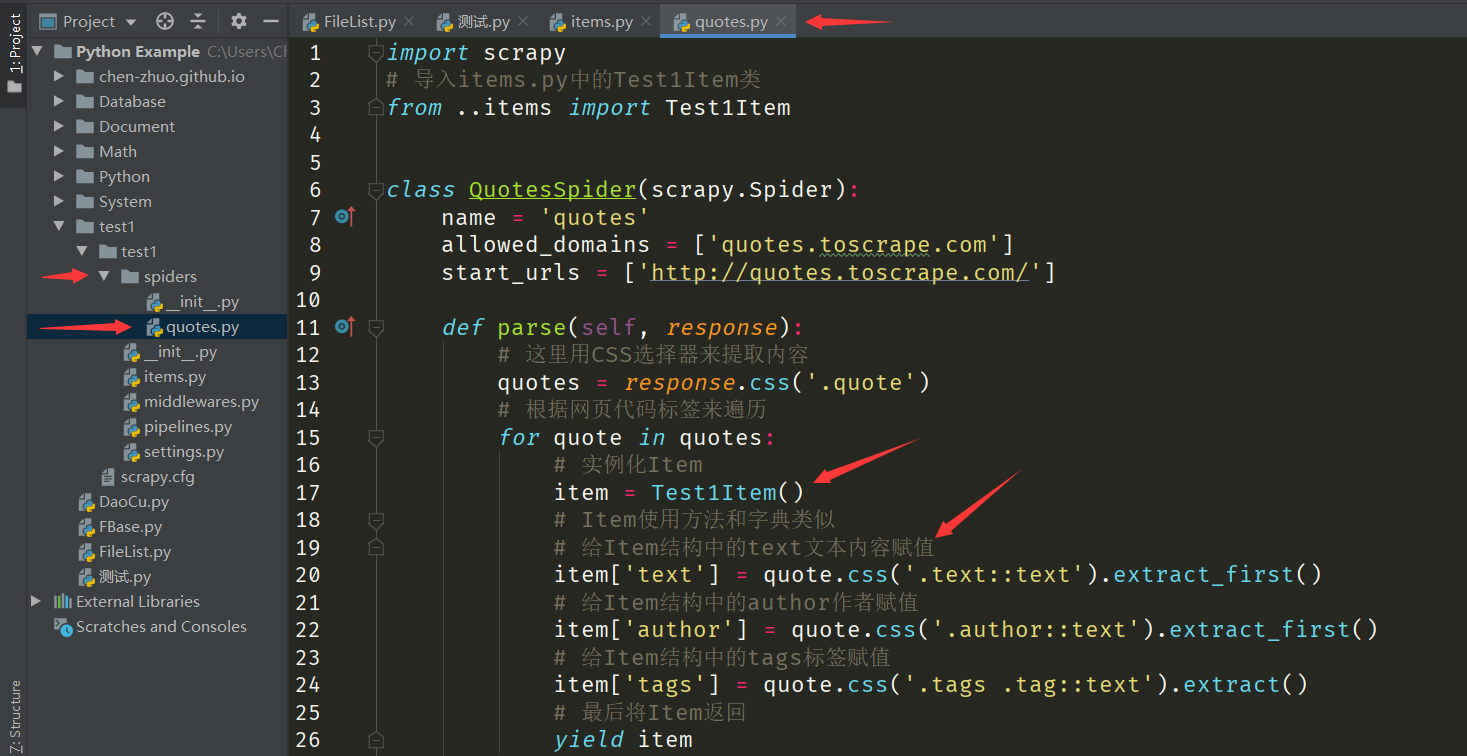
python
def parse(self, response):
# 这里用CSS选择器来提取内容
quotes = response.css('.quote')
# 根据网页代码标签来遍历
for quote in quotes:
# 实例化Item使用方法和字典类似
item = Test1Item()
# 给Item数据字段中的text文本内容赋值
item['text'] = quote.css('.text::text').extract_first()
# 给Item数据字段中的author作者赋值
item['author'] = quote.css('.author::text').extract_first()
# 给Item数据字段中的tags标签赋值
item['tags'] = quote.css('.tags .tag::text').extract()
# 最后将Item返回
yield item注意
注意这里实例化的 Item 对象,它只能以 Test1Item 数据结构里面已经定义的 Item 数据字段为键进行赋值,假如想对 item['date'] 进行赋值,由于在 Test1Item 数据结构里面并没有定义 date 字段,是会报 KeyError: 'Test1Item does not support field: date' 错误的。
构造后续请求
上面的代码中只解析了第一页的 Response 响应对象,如果要采集后面页码的内容,就需要构造后续的 Resquest 请求对象。构造 Resquest 请求对象需要用到 scrapy.Request 方法,里面有两个必须传递的参数:
url后续的请求链接。callback回调函数,当爬取url请求链接获取到 Response 响应对象之后,Engine会将 Response 响应对象作为实参传递给回调函数中的response形参,进行后续的解析或生成下一轮请求。
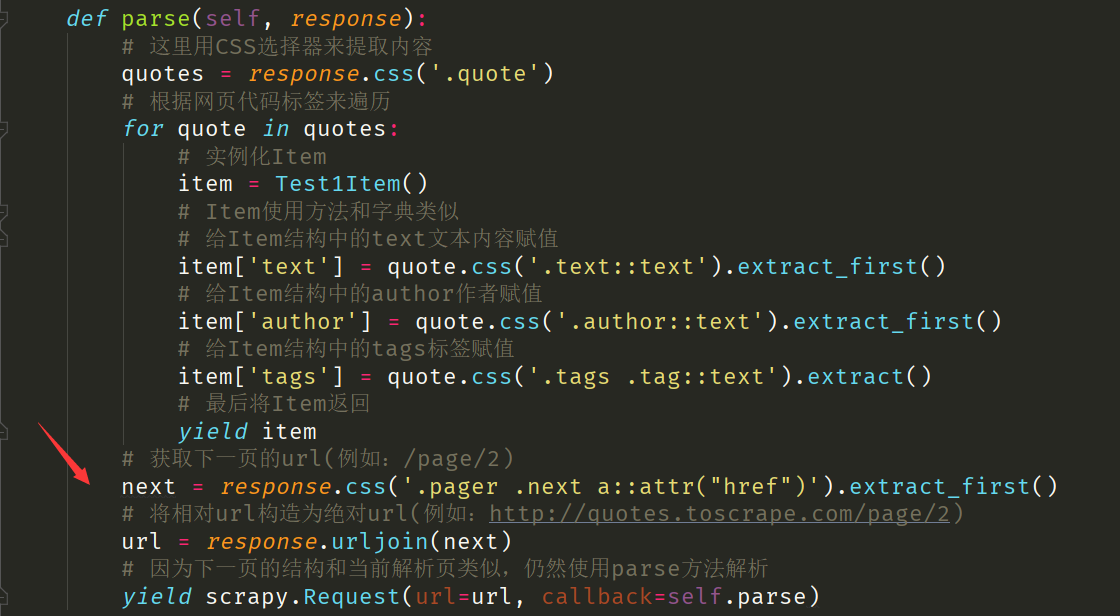
python
# 获取下一页的href属性(例如:/page/2)
next = response.css('.pager .next a::attr("href")').extract_first()
# 将href属性构造为url链接(例如:http://quotes.toscrape.com/page/2)
url = response.urljoin(next)
# 通过url和callback变量构造一个新的Request,由于下一页的结构和当前解析页类似,因此仍然使用parse方法来解析后续的Response响应对象。
yield scrapy.Request(url=url, callback=self.parse)重要
需要特别注意的是,在爬虫文件中,不管是返回 Item 数据对象,还是返回 Requset 请求对象,都是通过 yiled 关键字进行返回的。假如使用 return 关键字进行返回,就会造成返回一个对象就结束函数了。
运行爬虫项目
接下来,在爬虫项目所在的路径下,输入下面命令,即可运行爬虫:
python
# quotes就是爬虫的名字,即爬虫文件里面name变量
scrapy crawl quotes
保存结果文件
如果想将上面的结果保存成 JSON 文件,可以执行下面命令:
scrapy crawl quotes -o quotes.json # 所有item在一行
scrapy crawl quotes -o quotes.jsonlines # 一个item占一行输出格式还支持很多种,例如 csv、xml、pickle、marsha 等,还支持 ftp、s3 等远程输出:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pwd@ftp.example.com/path/to/quotes.csv