Scrapy进阶
Scrapy-redis
scrapy-redis框架与scrapy相差无几,本质的区别就是将scrapy的内置的去重的队列和待抓取 的request队列换成了redis的集合,这就使得了scrapy-redis支持了分布式抓取。 在redis的服务器中,会至少存在三个队列:
- 用于请求对象去重的集合,队列的名称为spider:dupefilter。
- 待抓取的request对象的有序集合,队列的名称为spider:requests
- 保存提取到item的列表,队列的名称为spider:items
最后,建议大家参考一下这篇文章:Python爬虫的N种姿势
Scrapy技巧
启动多个爬虫
我们知道,如果要在命令行下面运行一个 Scrapy 爬虫,一般这样输入命令:
scrapy crawl xxx(爬虫名称)此时,这个命令行窗口在爬虫结束之前,会一直有数据流动,无法再输入新的命令。如果要运行另一个爬虫,必须另外开一个命令行窗口。假设有一个 Scrapy 项目叫做 test_multple_crawler,它下面有两个爬虫 exercise 和 ua。如果我把运行两个爬虫的代码同时写到 main.py 里面会怎么样呢?输出如下图所示:
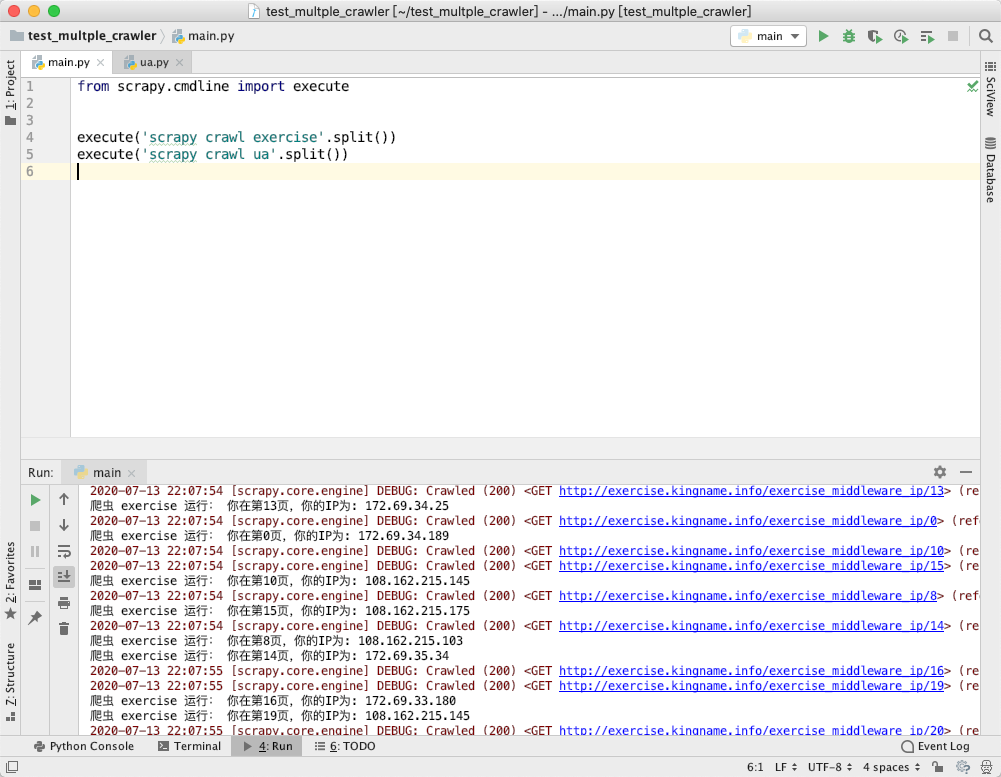
可以看到,这两个爬虫是串行运行的。首先第一个爬虫运行。直到它里面所有代码全部运行完成了,它结束了以后,第二个爬虫才会开始运行。这显然不是我们需要的。**我们要在一个命令窗口里面同时运行同一个项目下面的两个爬虫,我们可以使用 Scrapy 的 CrawlerProcess 来让多个爬虫实现真正的同时运行。**它的用法如下:
python
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
crawler = CrawlerProcess(settings)
crawler.crawl('爬虫名1')
crawler.crawl('爬虫名2')
crawler.crawl('爬虫名3')
crawler.start()回到我们的例子中,修改 main.py 代码为:
python
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
crawler = CrawlerProcess(settings)
crawler.crawl('exercise')
crawler.crawl('ua')
crawler.start()
crawler.start()可以看到,两个爬虫真正实现了同时运行。运行效果如下图所示:
.png)
中间件
在中间件请求
python
import json
import re
from urllib.parse import quote
import scrapy
from scrapy.core.downloader.handlers.http import HTTPDownloadHandler
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy.http.cookies import CookieJar
from twisted.internet import defer
from scrapy_spider.core.spiders import BaseRedisSpider
from scrapy_spider.items import ComposedDefaultItem, CertQualification
from scrapy_spider.spiders_queue.item_original_base import item_original_base
class MyRetryMiddleware(RetryMiddleware):
def __init__(self, crawler):
super().__init__(crawler.settings)
self.downloader = HTTPDownloadHandler(crawler.settings, crawler)
self.home_url = 'http://hngcjs.hnjs.henan.gov.cn/company/enterpriseListMaster'
self.headers = {
"Host": "hngcjs.hnjs.henan.gov.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
}
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
if not request.meta.get('cookiejar'):
return
d = defer.maybeDeferred(self.async_event_handler, request, spider)
d.addErrback(lambda failure: self._retry(request, failure.value, spider))
return d
@defer.inlineCallbacks
def async_event_handler(self, request, spider):
meta = {'proxy': request.meta.get('proxy')}
if 'Cookie' in self.headers:
request.headers.update(self.headers)
response = yield self.downloader.download_request(request, spider)
if '{"code":"3303"}' not in response.text:
return response
else:
del self.headers['Cookie']
# 访问主页
home_request = scrapy.Request(url=self.home_url, meta=meta, headers=self.headers)
home_response = yield self.downloader.download_request(home_request, spider)
if b'Set-Cookie' in home_response.headers:
cookie_jar = CookieJar()
cookie_jar.extract_cookies(home_response, home_request)
cookie = ''
for cookies_item in cookie_jar:
cookie += f'{cookies_item.name}={cookies_item.value};'
self.headers.update({'Cookie': cookie})
# 请求验证码
img_url = 'http://hngcjs.hnjs.henan.gov.cn/captcha/captchaImage1'
img_request = scrapy.Request(url=img_url, meta=meta, headers=self.headers)
img_response = yield self.downloader.download_request(img_request, spider)
img_code = spider.ocr.classification(img_response.body)
# 验证结果
check_url = f'http://hngcjs.hnjs.henan.gov.cn/setToken?validateCode={img_code}'
check_request = scrapy.Request(url=check_url, meta=meta, headers=self.headers)
check_response = yield self.downloader.download_request(check_request, spider)
assert '操作成功' in check_response.text, 'Verify code error!'
# 发送查询请求
# 替换请求url
# request._set_url(url='https://httpbin.org/get')
response = yield self.downloader.download_request(request, spider)
if request.url != self.home_url:
assert '{"code":"3303"}' not in response.text, 'Verify code not passed!'
# 返回响应对象(不能返回请求对象,否则会加入调度器,一直循环)
return response
def process_response(self, request, response, spider):
if '运行时异常' in response.text or '访问过于频繁' in response.text:
return self._retry(request, 'response error!', spider) or response
if 'safetyProduction' not in request.url and request.url != 'https://www.baidu.com/' and request.url != self.home_url:
try:
json.loads(response.text)
except Exception as e:
return self._retry(request, e, spider) or response
return response
class JianZhuZiZhiHeNan(BaseRedisSpider):
name = 'intellectual_property_spiders.jian_zhu_zi_zhi_he_nan'
redis_key = 'intellectual_property_spiders.jian_zhu_zi_zhi_he_nan:start_urls'
custom_settings = {
"RETRY_TIMES": 10,
"DOWNLOADER_MIDDLEWARES": {
"scrapy_spider.core.middlewares.ProxyMiddleware": 501,
"scrapy_spider.intellectual_property_spiders.jian_zhu_zi_zhi_he_nan.MyRetryMiddleware": 551,
}
}