Requests库
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
2011 年 Requests 发布,Requests 是一个 Python 的 HTTP 库,提供简单直观的 API,使得发起 HTTP 请求变得非常容易,通常被用在网络爬虫和自动化测试等领域。

参考内容:requests中文文档
初识Requests
requests 是实现 HTTP 各类型请求的最简单、最易用的第三方库,也是写爬虫必须要掌握的库。使用前需安装 requests 库:
pip install requestsGET请求
使用 requests 中发送 GET 请求,需要根据不同的网站设置不同的参数:
url参数:确定请求的网络地址(必传)。params参数:以字典形式将参数添加到 URL 中,例如将{k1: y1, k2: y2}添加到httpbin.org/get就成了httpbin.org/get?k1=y1&k2=y2,当然也可以直接请求携带参数的 URL,这样就可以不使用该参数(可选)。
python
import requests
# URL地址
url = 'https://httpbin.org/get'
# URL参数
params = {'name': 'germey', 'age': 22}
# 发送GET请求
response = requests.get(url=url, params=params)
# 打印响应的内容信息
print(response.text)
'''
输出:
{
"args": {
"age": "22",
"name": "germey"
},
"headers": {
"Accept": "/",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"origin": "182.149.163.126",
"url": "https://httpbin.org/get?name=germey&age=22"
}
注释:"args"就是URL中携带的参数,相当于直接请求了下面"url"对应的地址。
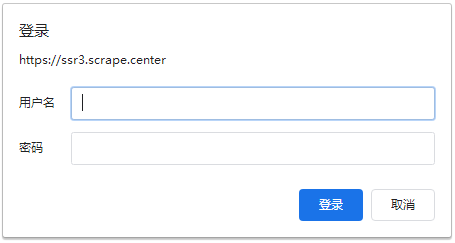
'''auth参数:有的网站启用了基本身份认证(例如:https://ssr3.scrape.center/)会给我们弹出一个登录窗口,因此我们访问时就必须带着用户名和密码一起访问,如果用户名和密码正确,那么请求时就会自动认证成功,返回 200 状态码;如果认证失败,则返回 401 状态码。
python
import requests
# URL地址
url = 'https://ssr3.scrape.center/'
# 用户名密码均为admin
auth=('admin', 'admin')
response = requests.get(url=url, auth=auth)
print(response) # 输出:<Response [200]>。注释:状态码200,说明用户名和密码正确。提醒
requests的 auth 参数会默认使用 requests.auth.HTTPBasicAuth 这个类来认证。
POST请求
在构造 POST 请求时,需要先确定请求体是以什么方式进行提交的,然后在请求头中使用对应的 Content-Type,否则可能会导致 POST 提交后无法得到正常的响应。这里列举出 Content-Type 和 POST 提交数据方式的关系:
| Content-Type | POST 提交数据的方式 |
|---|---|
application/x-www-form-urlencoded | 表单数据 |
application/form-data | 表单文件上传 |
application/json | 序列化 JSON 数据 |
text/xml | XML 数据 |
使用 requests 中发送 POST 请求,需要根据不同的网站设置不同的参数:
url参数:确定请求的网络地址(必传)。data参数:接收字典格式参数,默认请求头中的content-type为application/x-www-form-urlencoded,以表单数据的方式提交。
python
import requests
# url地址
url = 'https://httpbin.org/post'
# 字典格式参数
dict_data = {'name': 'germey', 'age': 22, 'company': '公司'}
response = requests.post(url=url, data=dict_data)
print(response.text)
'''
输出:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "22",
"company": "\u516c\u53f8",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-65716a9f-71eb04ed23def73846c13c4d"
},
"json": null,
"origin": "209.141.36.190",
"url": "https://httpbin.org/post"
}
注释:提交的数据出现在了"form",说明数据是以表单形式提交的,另外数据里的中文会被编码为Unicode。
'''json参数:接收字符串格式参数,默认请求头中的content-type为application/json,把字符串格式参数序列化 JSON 数据的方式提交数据。
python
import requests
# url地址
url = 'https://httpbin.org/post'
# 字符串格式参数
json_data = '{"name": "germey", "age": 22, "company": "公司"}'
response = requests.post(url=url, json=json_data)
print(response.text)
'''
输出:
{
"args": {},
"data": "\"{\\\"name\\\": \\\"germey\\\", \\\"age\\\": 22, \\\"company\\\": \\\"\\u516c\\u53f8\\\"}\"",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "68",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-65717736-79c36db76243a20862c30362"
},
"json": "{\"name\": \"germey\", \"age\": 22, \"company\": \"\u516c\u53f8\"}",
"origin": "209.141.36.190",
"url": "https://httpbin.org/post"
}
注释:提交的数据出现在了"json",而且被JSON序列化化了一次,说明数据是以序列化JSON数据形式提交的,另外数据里的中文会被编码为Unicode。
'''files参数:接收{'file': open(文件, 'rb')}格式参数,对于有需要上传文件的网站,通过此参数就可以实现将文件上传。

python
import requests
# url地址
url = 'https://httpbin.org/post'
# 以字节读取的方式打开文件,注意前面的
files = {'file': open('test.png', 'rb')}
response = requests.post(url=url, files=files)
print(response.text)
'''
输出:
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,iVBO..."
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "1663",
"Content-Type": "multipart/form-data; boundary=2600579e20620d4b5233d1e351855ea4",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-65717bb2-5e76e6c54a210ba1625a9db4"
},
"json": null,
"origin": "209.141.36.190",
"url": "https://httpbin.org/post"
}
注释:这里我用'test.png'来模拟文件上传,需要注意如果不再同一目录下需要加上路径,返回的响应中只有"files"字段有数据,而且是文件的Base64编码数据,说明文件上传部分会单独用一个files字段来标识。
'''请求头
一些网站服务器会通过检查请求头来判断发起访问的是人类,还是爬虫程序。因此,爬虫工程师会经常说:”没有请求头的爬虫是没有灵魂的爬虫“。我们使用 requests 库写爬虫,就算没有设置请求头,requests 库的源码会自动给爬虫设置一个默认请求头:
python
import requests
# 请求地址
response = requests.get('http://www.baidu.com')
# 输出请求头
print(response.request.headers)
'''
输出:{'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
注释:请求中虽然没有设置请求头headers,但在实际的访问过程当中,源码还是会添加默认的请求头参数,例如'User-Agent'、'Accept'等参数。
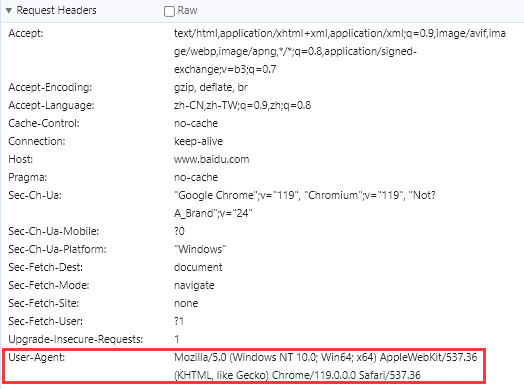
'''虽然 requests 库会自动添加请求头,但对于服务器识别爬虫来说太简单了,因为默认请求头中的 'User-Agent': 'python-requests/2.22.0' 就已经告诉了服务器这是用 requests 库的 2.22.0 版本发起的请求,这极大概率是爬虫。为了规避爬虫被封禁的风险,我们可以通过 GET、POST 请求方法中的 headers 参数来设置浏览器的请求头:
python
import requests
# url地址
url = 'http://www.baidu.com'
# 请求头参数
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.3', 'add':'abc'}
# 设置请求头,发送请求,获取响应
response2 = requests.get(url=url, headers=headers)
# 输出请求头
print(response2.request.headers)
'''
输出:{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.3', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'add': 'abc'}
注释:如果请求头headers有默认的请求参数,则会进行覆盖,反之则是增加该参数。这里和上面的例子相比就会发现,覆盖了User-Agent参数,新增了add参数,其他的默认请求头参数不变。
'''提醒
在爬取的某些网站时候,最好先获取一定数量的 User-Agent 来让爬虫随机更换,达到更好的伪装。
接受响应
当我们向服务器发送请求后,服务器会返回给客户端响应,在响应中包含许多内容,通过响应的各种属性可以轻松获取到我们想要的内容。
响应属性
python
import requests
# 请求头
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'}
# 地址
url = 'https://httpbin.org/get'
# 获取响应
response = requests.get(url=url, headers=headers)
# 打印响应对象
print(response) # 注释:<Response [200]>,表示成功获取到响应
# 打印响应的url内容
print(response.url)
# 打印网页响应的状态码
print(response.status_code) # 注释:返回200表示成功访问
# 以字符型文本形式打印响应内容(Unicode类型数据编码后得到的内容)
print(response.text) # 注释:主要用于打印网页的代码和文本内容
# 以二进制的形式打印响应内容数据(原始的bytes类型数据)
print(response.content) # 注释:主要用于打印网页中图片、音频、视频(二进制文件)内容
# 以Python数据类型打印json格式的响应的内容
print(reponse.json()) # 注释:等价于print(json.loads(reponse.text))
# 打印响应头
print(response.headers) # 注释:查看服务器返回响应头
# 打印请求头
print(response.requests.headers) # 注释:查看访问时的请求头
# 打印响应的cookie
print(response.cookies) # 注释:打印响应内容中Cookie
# 打印响应的cookies.items
print(response.cookies.items()) # 注释:以视图对象的形式打印响应内容中Cookie
# 关闭响应
reponse.close()响应语言
有时候我们在网页上看到的日期是标准格式:

但我们爬取下来却发现日期变成了标准的英文格式:
python
# 请求头
headers = {
"accept-language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
# 安全许可证url
url = '...'
response = requests.get(headers=headers, url=url)
print(response.text)
'''
输出:
<tr>
<td>有效期</td>
<td colspan="3">Sep 22, 2022 - Sep 22, 2025</td>
</tr>
<tr>
<td>发证机关</td>
<td>山西省住房和城乡建设厅</td>
<td>发证时间</td>
<td>Sep 22, 2022</td>
</tr>
'''其问题就在于请求头中的 "accept-language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7" 告诉了服务端优先返回英文格式的内容。现在我们将内容改为 "accept-language": "zh-CN,zh;q=0.9" 就能接受网页上显示的日期格式内容了:
python
# 请求头
headers = {
"accept-language": "zh-CN,zh;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
# 安全许可证url
url = '...'
response = requests.get(headers=headers, url=url)
print(response.text)
'''
输出:
<tr>
<td>有效期</td>
<td colspan="3">2022-9-22 - 2025-9-22</td>
</tr>
<tr>
<td>发证机关</td>
<td>山西省住房和城乡建设厅</td>
<td>发证时间</td>
<td>2022-9-22</td>
</tr>
'''响应乱码
中文乱码
**有些时候我们通过浏览器打开某个网页,能正常显示网页内容,但通过爬虫下载来就会发现响应中的 HTML 标签、英文内容能正常显示,但中文内容却是一堆乱码,其原因就是编码的问题。**例如下图:

requests 接收到响应时,会根据服务器返回的响应头中的 Content-Type 字段中的 charset 值去设置字符集编码,这时 requests 能正确解码响应。
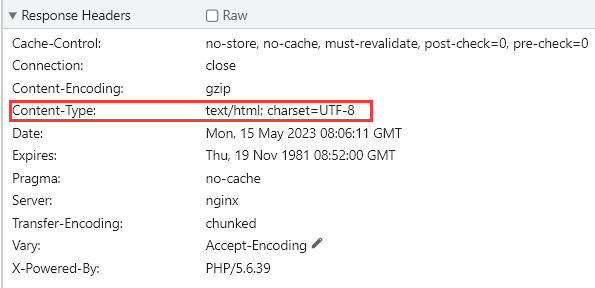
但如果响应头中的 Content-Type 字段中没有 charset 值,这时 requests 就会遵循《HTTP权威指南》第 16 章中的规定:如果 HTTP 响应中 Content-Type 字段没有指定 charset 字符集编码,则默认页面是 ISO-8859-1 编码。
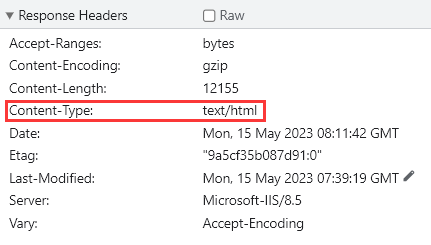
使用 ISO-8859-1 来编码英文页面当然没有问题,然而使用 ISO-8859-1 来编码中文会产生”编码黑洞“,要么报错,要么乱码,因此响应内容也是不可读的,一般那些不规范的页面往往有这样的问题。
python
import requests
r = requests.get('http://www.haozhanhui.com/exh/exh_index_ccdmlk.html')
print(r.text)
'''
输出:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>ã2023ä¸å½å½é
天ç¶æåç©åå¥åº·é£åé
æå±è§ä¼ãæ¶é´_å°ç¹_æä¹æ ·-好å±ä¼ç½</title>
<meta name="keywords" content="è¯åä¿å¥,é£åé
æ,å¥åº·,æåç©" />
'''遇到这种乱码的情况,如何获取正确的编码呢?在 requests 内部的 utils 模块中提供了一个从响应内容获取页面编码的 get_encodings_from_content 函数。源码如下:
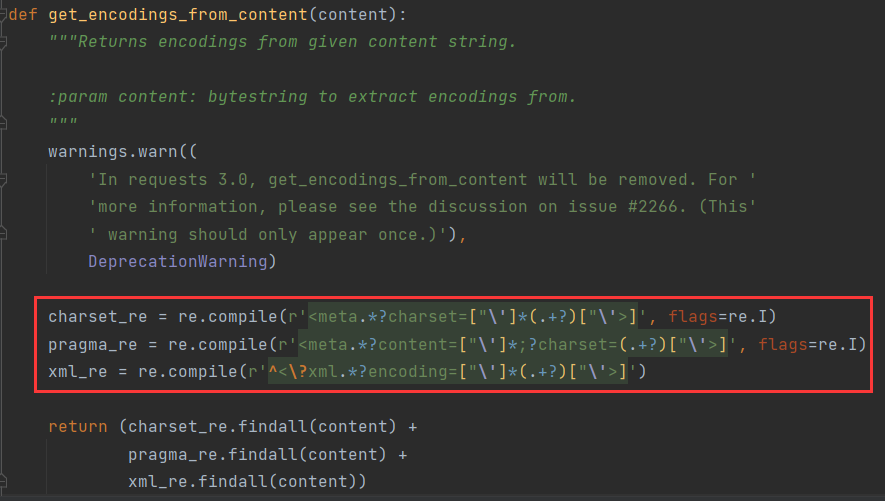
该函数通过正则匹配了响应内容中的字符集标签,因为很多网页的源码上会有 <meta charset="UTF-8"> 、<meta charset="gbk"> 这样的标签信息,表示该网页采用的是 UTF-8 编码或 GBK 编码,最后将网页中能匹配到的字符编码合成一个列表返回。


需要注意的是 get_encodings_from_content 函数接收的是字符类型响应,返回的结果是一个可能存在多个匹配的字符编码的列表,需要选择其中之一的编码。
python
import requests
r = requests.get('http://www.haozhanhui.com/exh/exh_index_ccdmlk.html')
print(requests.utils.get_encodings_from_content(r.text)) # 输出:['utf-8']在响应对象里还有一个 apparent_encoding 函数,它源码通过调用第三方库 chardet 中的 chardet.detect() 方法分析响应内容得到网页编码,虽然分析得到的编码不一定完全都是对的,但有一定的可信度。比如 jd.com 页面,编码是 GBK,但是检测出来却是 GB2312,虽然这两种编码是兼容的,但是用 GB2312 解码 GBK 编码的网页还是会报错,而且在分析的过程中还会消耗一定的 CPU 计算资源。
python
import requests
r = requests.get('http://www.haozhanhui.com/exh/exh_index_ccdmlk.html')
print(r.apparent_encoding) # 输出:utf-8现在我们已经获取了正确的响应编码了,那么解决乱码的办法就是手动指定编码方式。具体有两种:
python
from requests.utils import get_encodings as ed
# 方式一:设置指定编码方式,用于在调用response.text方法时对响应进行解码。
response.encoding = 'UTF-8' # 注释:主要针对于网页中文乱码的情况
response.encoding = 'GBK' # 注释:主要针对于网页编码为gbk、gb2312类型的内容
response.encoding = 'unicode_escape' # 注释:主要针对于网页编码为unicode类型的的内容
response.encoding = ed(response.text)[0] # 注释:根据网页源码标签确定网页编码的方式。
response.encoding = response.apparent_encoding # 注释:根据响应的内容分析网页编码的方式。
# 方式二:使用response.content获取响应的二进制流数据再进行解码。
response.content.decode() # 注释:默认解码为UTF-8。
response.content.decode('GBK') # 注释:解码为GBK。
response.content.decode('unicode_escape') # 注释:解码为unicode。
response.content.decode(ed(response.text)[0]) # 注释:根据网页源码标签确定网页编码的方式。
response.content.decode(response.apparent_encoding) # 注释:根据响应的内容分析网页编码的方式。我们随机选择一种进行设置就能获得正确的响应,代码如下:
python
import requests
from requests.utils import get_encodings_from_content as ed
r = requests.get('http://www.haozhanhui.com/exh/exh_index_ccdmlk.html')
print(r.content.decode(ed(r.text)[0]))
'''
输出:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>【2023中国国际天然提取物和健康食品配料展览会】时间_地点_怎么样-好展会网</title>
<meta name="keywords" content="药品保健,食品配料,健康,提取物" />
'''压缩乱码
除了字符编码导致的响应乱码外,还有一种就是压缩编码导致的响应乱码,也就是网页内容是正常显示的,但通过爬虫下载来就会发现响应中,不论是 HTML 标签,还是英文内容、中文内容,都是一堆乱码。通过 Fiddler 抓包界面如下:
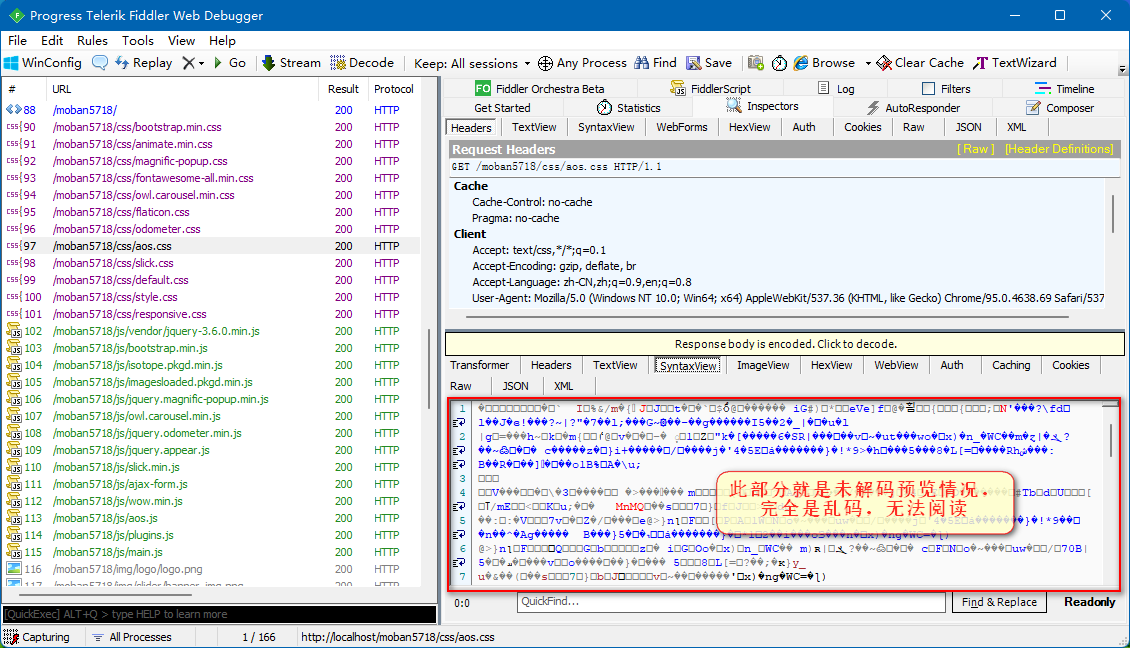
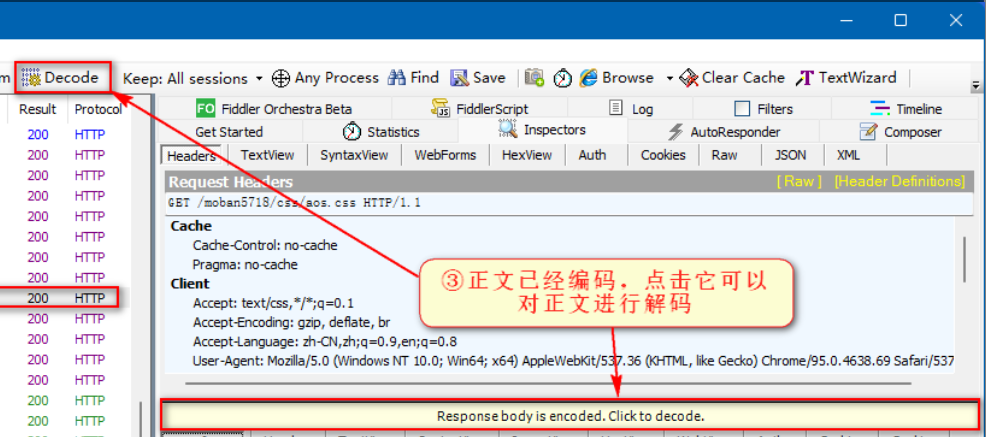
当我们点击了“Response body is encoded. Click to decode” 或者工具“Decode”按钮,那么 Fiddler 将对响应进行解压缩操作,解压缩后就可以直接阅读了。
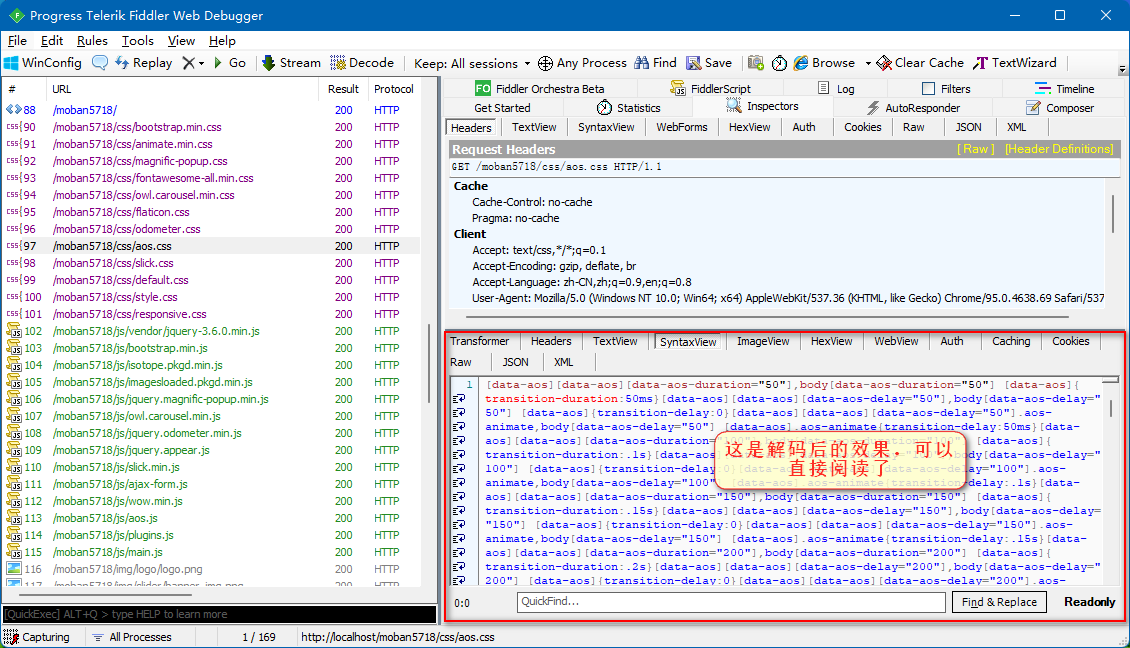
原来许多 Web 服务器都具有发送压缩数据的能力,若只传输压缩数据可以将传输的数据流量削减 60% 以上。下面图中,选择了一个“aos.css”文件,从 Inspectors 选项卡中的 Response 部分中可以看出,服务器返回的 CSS 文件采用了 GZIP 压缩:
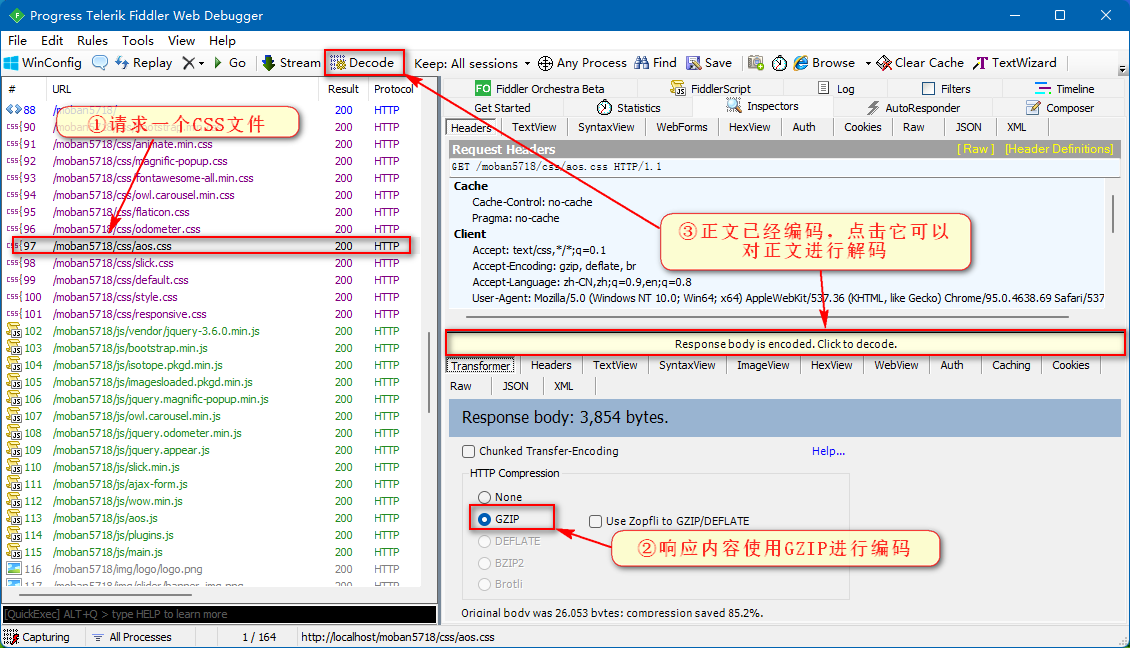
但是一般服务器不会给我们发送压缩数据,除非我们告诉服务器可以处理压缩数据。那我们在哪里告诉了服务器我们可以处理压缩数据的呢?答案就是请求头中的 Accept-Encoding: gzip, deflate, br 这段,前面我们学习爬虫请求头的时候讲过 Accept-Encoding 字段表示客户端支持的解码类型。一般情况下,在写爬虫时不定义该属性,而现在我们写上了,恰好我们请求的服务器也具有发送压缩数据的能力,于是乎给我们返回了压缩数据。解决服务器返回压缩数据有两种很简单的方法:
- 要想服务器不给我们发送压缩数据,直接将请求头中的
Accept-Encoding字段删除即可。 - 我们也可以自行解压服务器发来的压缩数据,代码如下:
python
import zlib
import brotli
import zstandard
from scrapy.utils.gz import gunzip
# 二进制压缩数据
body = b'\x1f\x8b\x08\x00...'
# 服务器返回的响应头的Content-Encoding压缩格式
encoding = b'gzip'
# 根据压缩格式解压数据
if encoding == b'gzip' or encoding == b'x-gzip':
body = gunzip(body)
if encoding == b'deflate':
try:
body = zlib.decompress(body)
except zlib.error:
body = zlib.decompress(body, -15)
if encoding == b'br' and b'br' in ACCEPTED_ENCODINGS:
body = brotli.decompress(body)
if encoding == b'zstd' and b'zstd' in ACCEPTED_ENCODINGS:
reader = zstandard.ZstdDecompressor().stream_reader(io.BytesIO(body))
body = reader.read()
# 输出解压内容
print(body) # 输出:b'<html><script>...'异常处理
重定向循环
重定向:指请求从当前 URL 地址转向到另一个 URL 地址上。比如,网站调整(如网页目录结构变化)、网页协议改变、网页地址改变、网页扩展名(.php、.html、.asp)的改变、一个网站注册了多个域名等,这些情况都需要进行重定向,否则就容易出现 404 错误。
重定向状态码:301(永久性重定向)、302(暂时性重定向)
重定向的域名:重定向后的域名就存放在第一次重定向的 headers 头部信息中的 Location 键值对中。
python
import requests
r = requests.get('http://home.cnblogs.com/u/xswt/')
# history属性是一个地址序列,里面存储着当前请求的历史记录,可以来追踪页面重定向。
print(f'获取当前请求的历史记录:{r.history}')
print(f'获取重定向后的头部信息:{r.history[0].headers}')
print(f'获取重定向后的域名地址:{r.history[0].headers["location"]}')
print(f'获取重定向后的页面内容:{r.text}')
'''
获取当前请求的历史记录:[<Response [302]>]
获取重定向后的头部信息:{'Date': 'Sun, 30 Aug 2020 07:44:04 GMT', 'Content-Type': 'text/html', 'Content-Length': '154', 'Connection': 'keep-alive', 'Location': 'https://home.cnblogs.com/u/xswt/', 'Via': 'HTTP/1.1 SLB.69'}
获取重定向后的域名地址:https://home.cnblogs.com/u/xswt/
获取重定向后的页面内容:<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
...
</body>
</html>
注释:访问该域名会进行一次重定向,相较于原域名,重定向后的域名协议从'http'变成了'https'。
'''在 requests 库的源码中 allow_redirects=True 即默认状态下访问会自动重定向,当然我们也可以通过 all_redirects=False 禁止重定向。代码如下:
python
import requests
# all_redirects=False禁止重定向
r = requests.get('http://home.cnblogs.com/u/xswt/', allow_redirects=False)
print(f'响应状态码:{r.status_code}')
print(f'响应的内容:{r.text}')
'''
响应状态码:302
响应的内容:<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
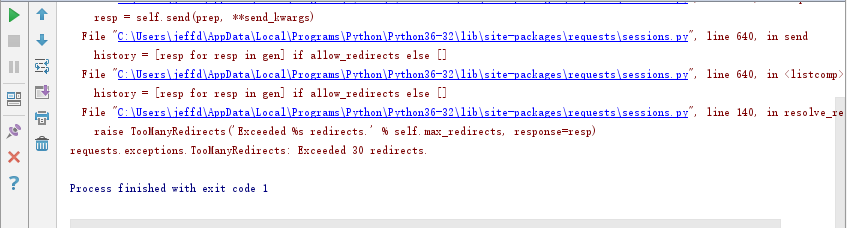
'''虽然在 requests 中默认是自动重定向,但重定向的次数是有限制的,最大为 30 次,如果超过 30 次,就会抛出 Exceeded 30 redirects 重定向超过 30 次的错误。比如下图:简单来说就是没有与服务器建立会话,页面重定向成了环形的死循环。因此解决该问题的根本在于保持会话,防止重定向进入死循环,可以通过添加正确响应的请求头来保持会话的持久性(检查请求头中参数和 Cookie 的有效性)。
超时错误
requests 默认的超时是 None,也就是说默认是阻塞的,除非显式指定了 timeout 值,否则不会做超时处理,这意味着它将等待(挂起)直到连接关闭。因此使用 requests 最好传入一个元组来设定 timeout 值,元组分别指定连接和读取的超时时间,服务器在指定时间没有应答,就会抛出错误。
timeout = (连接超时时间, 读取超时时间)- 连接超时时间:客户端连接服务器并发送http请求服务器。
- 读取超时时间:客户端等待服务器发送第一个字节之前的时间。
python
import requests
# 设置连接的超时时间为100秒,读取的超时时间为0.001秒
requests.get('http://github.com', timeout=(100, 0.001))
'''
在指定时间内服务器没有响应,抛出requests.exceptions.ReadTimeout读取超时错误:requests.exceptions.ReadTimeout: HTTPConnectionPool(host='github.com', port=80): Read timed out. (read timeout=0.001)
'''若只给 timeout 传入一个值,则将会用作连接超时和读取超时二者的共同时间。
python
import requests
# 设置连接的超时时间和读取的超时时间都为0.001秒
requests.get('http://github.com', timeout=0.001)
'''
在指定时间内没有连接到服务器,抛出requests.exceptions.ConnectTimeout连接超时错误:requests.exceptions.ConnectTimeout: HTTPConnectionPool(host='github.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x000002B3A3B55788>, 'Connection to github.com timed out. (connect timeout=0.001)'))
'''超过最大连接
requests 底层使用了 urllib3 库,每次请求和服务器建立的 TCP 连接默认状态是 Keep-alive 的,当服务器保持的连接数超过最大限制时,就不能再新建连接了,于是乎就抛出 requests.exceptions.ConnectionError: HTTPSConnectionPool Max retries exceeded 错误。解决方法有如下几种:
方案一:使用代理,绕过单个 IP 建立的 HTTP 连接数的限制;
方案二:设置固定的睡眠时间,降低访问频率;
python
time.sleep(3)- 方案三:在请求头中关闭 TCP 持久连接,这样每次请求一结束,TCP 连接就会完全断开;
python
headers = {'Connection': 'close'}方案四:创建一个会话对象 Session,通过 Session 来发起请求,这样每次请求都会复用前面已经建立好的 TCP 连接。
建议
这个错误经常出现在使用代理的爬虫中,后面代理部分会细讲。
未知服务器
访问不存在的网址,抛出 requests.exceptions.ConnectionError 错误。
python
import requests
# 访问不存在的网址
requests.get('http://github.comasf')
'''
抛出requests.exceptions.ConnectionError错误:requests.exceptions.ConnectionError: HTTPConnectionPool(host='github.comasf', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001DA07F41848>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
'''网络异常
在断网的情况下,抛出 requests.exceptions.ConnectionError 错误。
python
import requests
# 已断开网络连接的情况下
requests.get('http://github.com')
'''
抛出requests.exceptions.ConnectionError错误:requests.exceptions.ConnectionError: HTTPConnectionPool(host='github.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000002BB2BFC46C8>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
'''代理异常
代理服务器拒绝建立连接,端口拒绝连接或未开放,抛出 requests.exceptions.ProxyError 错误。
代理服务器没有响应,抛出 requests.exceptions.ConnectTimeout 错误。
python
import requests
# 代理192.168.10.1:800
requests.get('http://github.com', proxies={"http": "192.168.10.1:800"})
'''
抛出requests.exceptions.ProxyError错误:requests.exceptions.ProxyError: HTTPConnectionPool(host='192.168.10.1', port=800): Max retries exceeded with url: http://github.com/ (Caused by ProxyError('Cannot connect to proxy.', NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fce3438c6d8>: Failed to establish a new connection: [Errno 111] Connection refused',)))
'''SSL证书错误
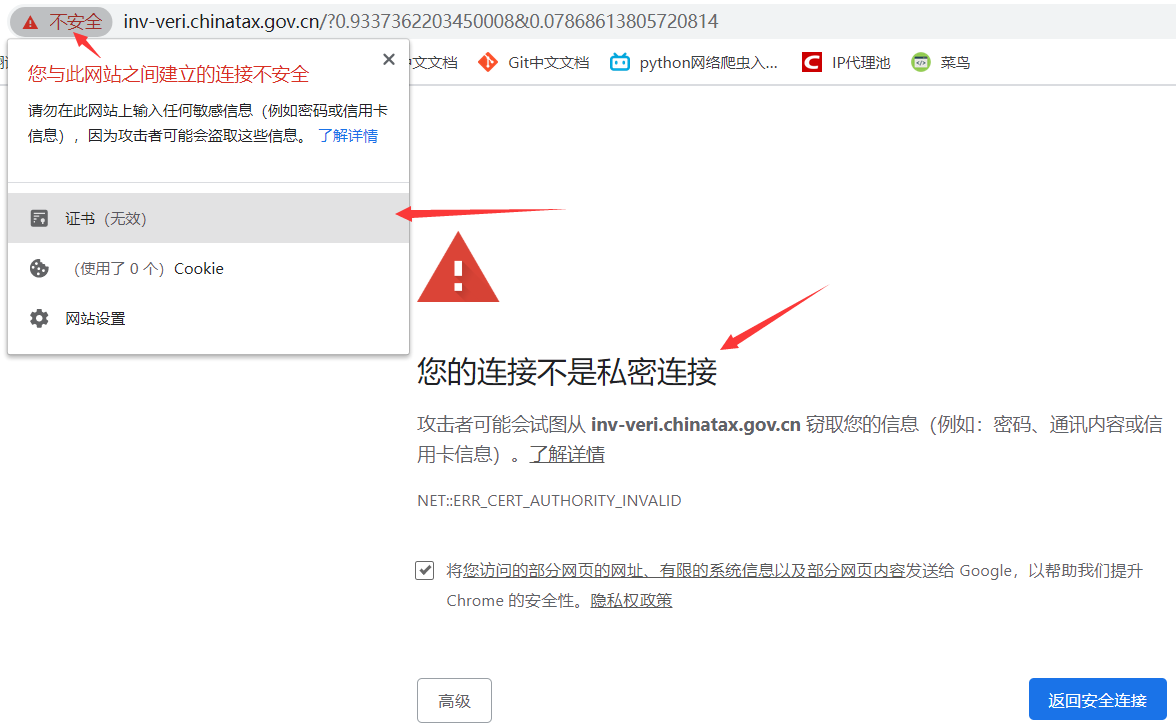
使用 requests 库访问有些网站比如:国家税务总局全国增值税发票查验平台,就会报如下错误:
python
import requests
response = requests.get('https://inv-veri.chinatax.gov.cn/')
print(response.status_code)
'''
报错:requests.exceptions.SSLError: ("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')],)",)
'''原因在于:使用 requests 库在爬取这些网站时,会进行一个 SSL 证书验证的过程,如果证书验证不通过就会报错 SSLError。
通过设置 verify=False,可以让 requests 库忽略对 SSL 证书的验证,代码如下:
python
import requests
# 忽略掉SSL证书警告
requests.packages.urllib3.disable_warnings()
# verify=False忽略对SSL证书的验证
response = requests.get('https://inv-veri.chinatax.gov.cn/', verify=False)
print(f'状态码:{response.status_code}')
'''
警告:InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
状态码:200
'''反DH检测爬虫
有时候,即使我们已经忽略警告并关闭了 SSL 验证,在某些服务器上验证时,还是会返回一个 SSL 错误,导致无法通过:
python
import requests
data = {
'mainZZ': '0',
'aptText': '',
'areaCode': '0',
'entName': '',
'pageSize': '10',
'pageIndex': 1,
}
url = 'https://cxpt.fssjz.cn/cxpt/web/enterprise/getEnterpriseList.do'
requests.packages.urllib3.disable_warnings()
response = requests.post(url=url, data=data, verify=False)
print(response.text)
'''
报错:requests.exceptions.SSLError: HTTPSConnectionPool(host='cxpt.fssjz.cn', port=443): Max retries exceeded with url: /cxpt/web/enterprise/getEnterpriseList.do (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_ske_dhe', 'dh key too small')])")))
翻译:由SSL错误导致了错误的握手(“SSL例程”中的“tls进程”中的“dh密钥太小”)
'''报错原因:服务器检测到DH密钥太短小,很可能在中间人攻击中被破解,导致禁用警告或证书验证无济于事。要解决此问题,就要不受弱 DH 密钥的影响,即要选择一个不使用 Diffie Hellman 密钥交换的密码,并且此密码必须由服务器支持。如果不知道服务器支持什么,可以尝试使用密码 AES128-SHA 或密码设置 HIGH:!DH:!aNULL。
python
import requests
data = {
'mainZZ': '0',
'aptText': '',
'areaCode': '0',
'entName': '',
'pageSize': '10',
'pageIndex': 1,
}
url = 'https://cxpt.fssjz.cn/cxpt/web/enterprise/getEnterpriseList.do'
# 忽略掉SSL证书警告
requests.packages.urllib3.disable_warnings()
# 添加默认密码HIGH:!DH:!aNULL
requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS += ':HIGH:!DH:!aNULL'
response = requests.post(url=url, data=data, verify=False)
print(response.text)
'''
输出:{"total":8608,"data":[{"id":"54fbff74402344f28026b2cbf38bfd1d"...
'''Fiddler监控错误
还有一种情况,当我们开启 Fiddler 监控,使用 requests 库发送请求,遇到 SSL 的错误:
ssl.SSLError: [SSL:WRONG_VERSION_NUMBER] wrong version number (_ssl.c:1091)出现这种情况的原因可能有两种情况:
- Fiddler 没有安装信任证书,即 requests 请求时,需要通过 Fiddler 代理时,需要证书验证。
- Fiddler 安装信任证书了,那 requests 的版本必须是2.22.0,太高的版本可能不适用。
# 卸载当前版本的requests
pip uninstall requests
# 安装2.22.0版本requests
pip install requests==2.22.0直接访问IP
了解网络通信的朋友都知道,访问网站的时候,会有一个域名解析的过程,客户端会先到域名服务器将访问的网站域名解析为 IP 地址,然后通过 IP 地址来进行后续的 HTTP 通信。
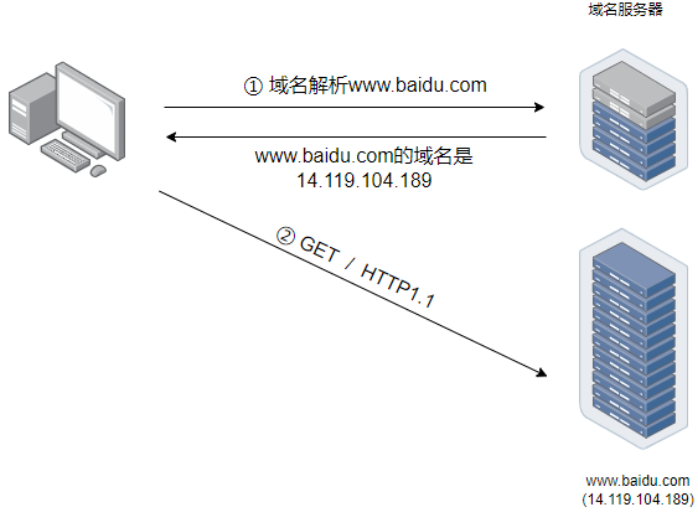
那既然如此,如果已经知道了网站的 IP 地址,是不是可以跳过域名解析的过程,直接拿着 IP 地址去请求呢?以百度为例,我们 ping 一下百度的域名,拿到它的 IP 地址,直接访问 https://14.119.104.189,结果被拒绝了!
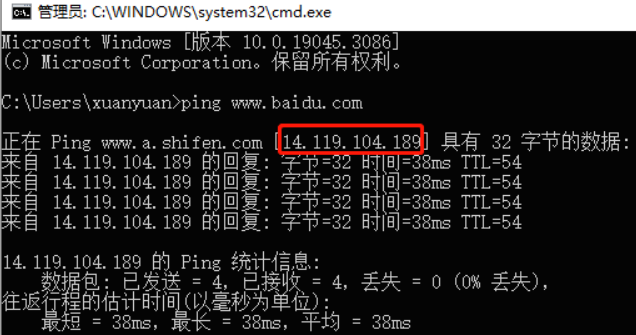
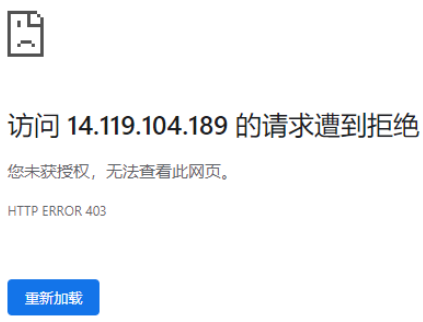
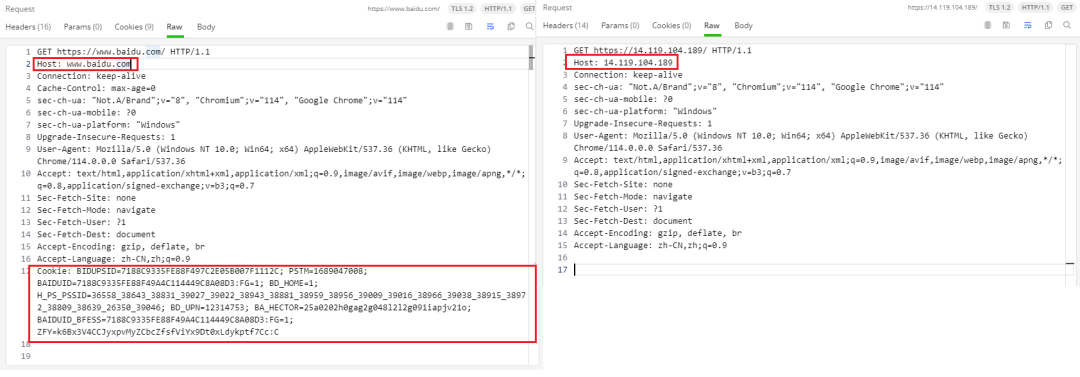
为啥我跳过了第一步,直接用 IP 访问就不行呢?我们使用抓包软件分别抓包通过域名来访问和通过 IP 地址来访问的数据包进行比对,发现只有两个地方不一样,分别是 Host 字段和 Cookie 字段:
访问百度是不需要登录的,因此也是不会进行 Cookie 字段验证的,这样看来,问题多半出在这个 Host 字段。为了进一步验证,我们使用 Postman 来直接访问 https://14.119.104.189,可以看到服务器返回了 403 错误!

然后,我们通过 Postman 修改一下 Host 字段,将其设置为域名 www.baidu.com,再试一次,可以看到成功访问了:

至此,我们可以进行总结了,当客户端在发起 HTTP 请求的时候,会将其要访问的服务器地址填在 Host 字段。当使用域名访问的时候,这个字段的值就是域名,而通过IP地址访问的时候,这个字段的内容就是对应的IP地址。而服务器正是通过请求中的 Host 字段,识别出了客户端是直接通过 IP 访问的还是通过域名访问的,从而给出了不同的响应。当我用 HTTPS 直接访问 https://14.119.104.189 的时候,浏览器给了我这样一个提示:

这不是百度自己的 SSL 证书吗,为什么会有这个提示出现?这其实是因为百度的 SSL 证书设置的是 www.baidu.com 地址,而不是它的 IP 地址。如果直接使用 IP 地址访问会导致访问的 IP 与证书上的 www.baidu.com 地址不一致而出现“不是私密连接”的提示。