CNN卷积神经网络
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
经过前面 Softmax 回归的学习,我们知道计算机识别图片实际上是把一幅图像转换为一大堆数字,通过训练就可以知道这一大堆的数字代表什么样的一个含义,其实这种训练的方式费时费力,而且一旦图片发生了一点放缩、旋转,或者是一些变化,计算机就认不出来了。但是我们眼睛的识别效率就特别的高,只要看过一次摩托车和汽车之后,我们就能立刻把它们给分辨出来,这是一辆汽车,而不是摩托车,并且下次在看到这辆汽车的时候,哪怕汽车的方向变了,位置变了,或者是它破损了,我们依然能认出来它是一辆汽车,而不是一辆摩托车。
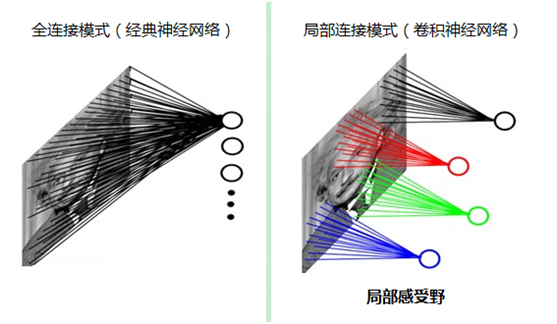
认知模型
在 1980 年,日本神经网络领域的科学家福岛邦彦首次提出了神经认知模型 "Neocognitron",该模型研究了人识别物体的大脑行为。简单讲,光从眼睛进入到大脑,而大脑里面有很多的皮层,会逐层对视觉信号进行处理,每一层对于信号的处理方式是不同的。
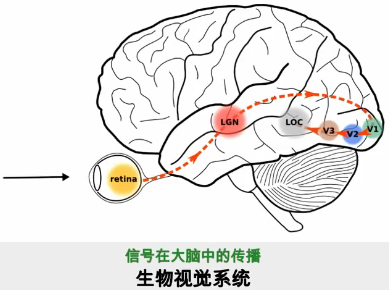
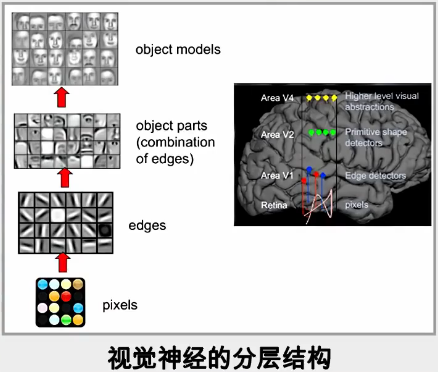
**详细讲,最开始光进入到眼睛的视网膜里面实际上是一大堆的像素点,然后进入到第一个皮层,在这个皮层中这些像素点会被抽象出一些特征,比如说方向、边缘,接着进入到第二个皮层,在这个皮层中会把这些特征组合起来形成轮廓、细节,接着进入到第三个皮层,在这个皮层中会把这些轮廓、细节组合成一个整体,最终才会做出一个判断。**这个就是人识别物体的流程,看起来是比较复杂的,因为它是由一层一层这样的递进关系去认识物体的,比如你看一个好友,你最开始的看到他的时候,其实是一大堆像素点,这些像素点进入你的大脑第一个皮层抽象出特征,比如两胳膊、两腿、直立行走等,接着第二个皮层抽象出眼睛形状、鼻子大小等轮廓,接着第三个皮层将特征组合在一起,和你大脑中的好友图像进行比较,发现匹配度极高,因此你判断确定是他。
建议
Neocognitron 是卷积神经网络(Convolutional Neural Network,CNN)的先驱,被设计用于图像识别。该模型受到了后来深度学习和计算机视觉领域的影响。
卷积神经网络
根据 Neocognitron 的识别原理,著名的科学家杨立坤发明出来了一种能够识别图像的方法,称之为卷积神经网络(Convolutional Neural Network,CNN)。
卷积
首先我们先来了解一下卷积,比如说有一个手写的字母需要判断字母的内容是不是"X",虽然每个人写出来的字母"X"都略有不同,但我们知道字母"X"有一些共同的特征,比如说字母"X"只有两条线,一条线向左倾斜,一条线向右倾斜,并且这两条线在中间必定会有交叉,越符合这些特征,那么这个字母就越有可能是"X"。所以,卷积的作用就是用一种数学的方法提取出图像的特征。

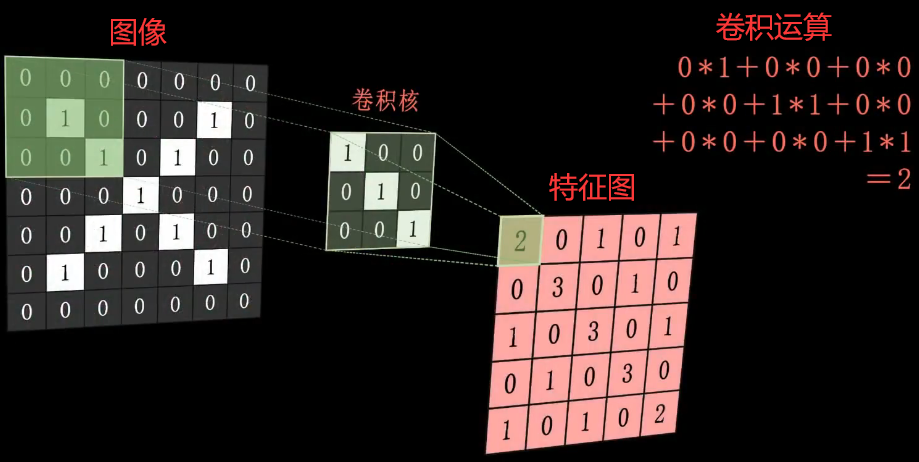
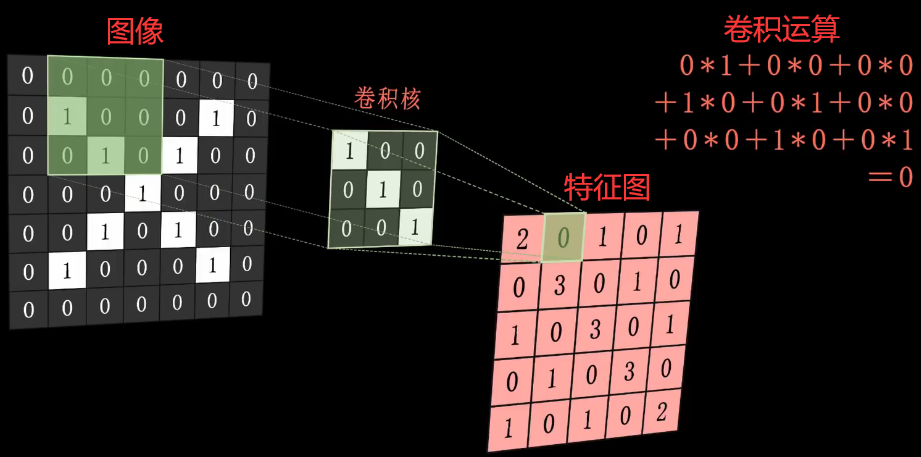
那么计算机如何进行卷积呢?我们给到计算机一张字母"X"的黑白图像,计算机首先会把图像中白色部分设置为 1,黑色部分设置为 0。

**接下来,计算机会用到一个叫“卷积核”的东西进行卷积运算来提取图像特征,所谓的“卷积核”就是一个 3X3 或 5X5 大小的矩阵,拿着这个“卷积核”在图像上平移和图像上每个相同大小的部分进行卷积运算,最后得到一张全新的特征图。**具体流程如下:我们仔细看就能发现,当前卷积核只有向左斜的三个元素是 1,其他都是 0,说明该卷积核提取的是向左斜的线条特征。如果图像中也存在向左斜的三个元素是 1 的话,它们做卷积的话这个数字就会特别的大,也就是说图像中存在向左斜的线条特征。在特征图中,3 是最大的,而且向左斜 3 个 3 是连贯的,也就说明这个 3 位置都特别满足向左斜的线条特征。而左上角和右下角的 2,则说明它们向左斜的线条特征稍弱一点。至于其他位置的 0 或 1,则说明在其他位置上没有展现出向左斜的线条特征。
建议
最开始的卷积核可能是人为设定的,但是后来在机器学习的过程中,它会根据自己的数据去反向调节这个卷积核,它最终会找到最合适的卷积核。
池化
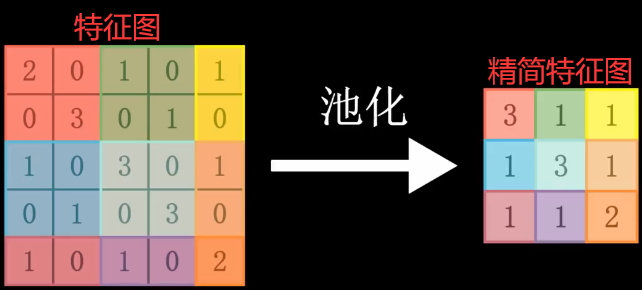
虽然我们得到了关于图像的特征图,但特征图当中的元素个数还是比较多的,于是乎我们要对特征图进行简化,减少训练参数的数量,也就是将特征图中有特征的部分放大,没有特征的部分就忽略,这一步就叫做“池化”,目的就是减少图像的空间大小。这里我们采用“最大值池化”的方法,将特征图切分成 2X2 大小的块,不足 2X2 大小的就使用 2X1 或 1X2 或 1X1 大小的块,每块只保留最大的特征值。这样我们就得到了一个更加精简的特征图,而且这个特征图仍然保留了原始特征图很重要的一些信息,这些信息就是向左斜的线条在值比较大的位置上:

激活
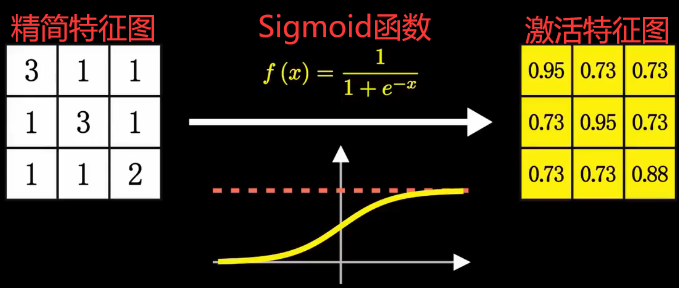
得到精简特征图后,还需要对该图进行激活,这里我们使用到 Sigmoid 激活函数,对图中的特征值进行处理,最后我们得到一张经过激活后的精简特征图,在这个图中数值接近于 1,就越满足卷积核的特性,就是有一个向左斜的线条:
训练流程
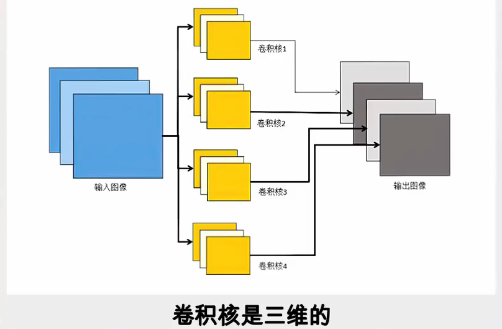
多核卷积
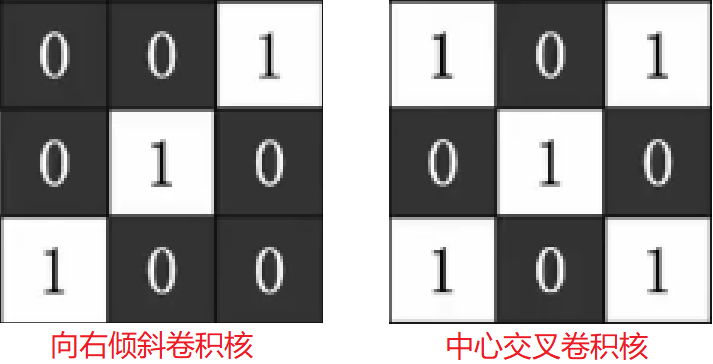
上面我们通过一个卷积核提取到了图像中向左斜的线条特征图,但是我们知道字母"x"是由一条线向左倾斜和一条线向右倾斜组合而成,也就是说,我们还需要另外一个卷积核来提取图像中向右斜的线条特征,除此之外字母"x"两条斜线的交叉点在中间,也就是说我们还需要另外一个卷积核来提取图像在中间位置交叉的线条特征,具体如下:经过这两个卷积核的运算,我们又能提取两张新的关于图像向右斜和图像中心交叉的特征图。
建议
通过不同的卷积核,我们就能够对图像进行不同的处理,得到不同的特征图,显示出来这种特征分布在图像的什么位置。
三维池化
现在我们通过三个卷积核得到了三张关于图像的特征图,而且这三张特征图是叠在一起的,每张特征图的 X、Y 和原来的 X、Y 是一致的,叠在一起之后多出了一个 Z 方向,这个 Z 方向表示每一个卷积核会对应出一张特征图,因此这三张特征图叠在一起就是一个三维的图像,这就是一次卷积的结果。下一步就是池化,实际上就是减少参数数量的过程,于是乎我们就会得到比较小的三维精简特征图:
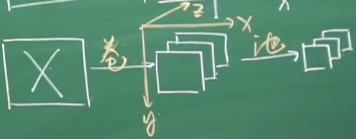
二次卷积
**一次卷积和池化可能有些问题处理不了,所以可能会进行二次卷积,在进行二次卷积的每一个卷积核就必须是三维的,因为我们前面得到精简特征图是三维的。**比如说,第二次卷积有 4 个三维卷积核,每一个三维卷积核和三维精简特征图进行内积,内积完后就是一个二次特征图,但有 4 个三维卷积核,因此最后会得到 4 张二次特征图。
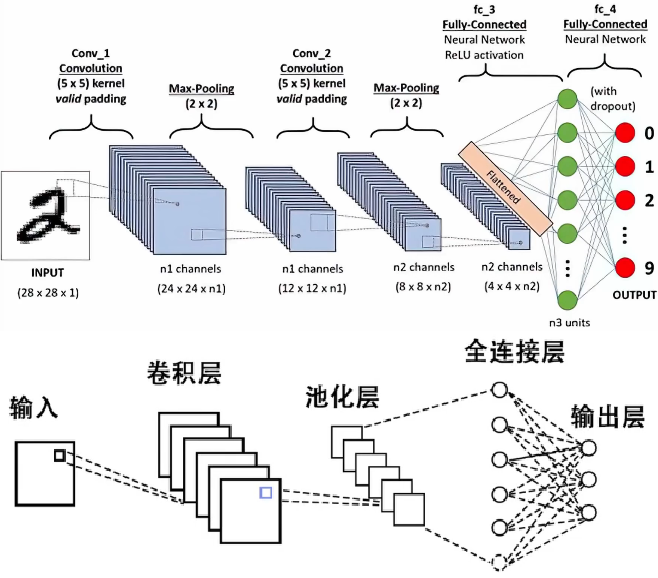
接入网络
经过多次卷积和多次池化,计算机就可以找到很多特征,比如图像的水平线条、竖直线条、倾斜线条、轮廓、颜色特征等,我们把这些足够多的信息接入到全连接网络进行训练,最后就可以判断图像中到底是什么了。
建议
我们把一大堆数据给到卷积神经网络,卷积神经网络通过一定的方法去调节自己的卷积核和参数,最终就可以分辨出来每一种不同的物体到底什么了。
验证码识别
在本次实战目的是深入学习卷积神经网络算法和 PyTorch 深度学习框架,整体来说,我们会开发一个基于深度学习的验证码识别系统,其中重点是设计并训练卷积神经网络模型,来专门识别某一种特定形态的验证码。
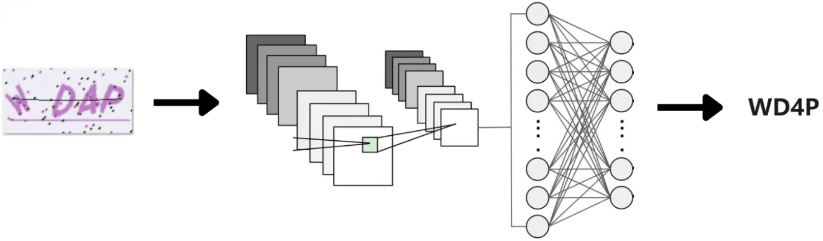
对于字符型验证码识别,主要会使用到图片分类技术。最简单的是字符型验证码,一般在一个图片中,会包括 4 ~ 6 位的数字与字母的组合。为了增加识别难度,网站会对字符进行扭曲和旋转,并在字符的周围设置线条或点等干扰因素。

验证码数据集的关键在于,针对带破解网站进行分析,收集足够多的且符合带破解验证码形式的数据后,再使用这些数据训练模型。只要训练使用的数据集,可以覆盖待破解网站中的全部验证码形态,那么在应用时,就会得到比较好的效果。换句话说,如果训练时,使用的是某一种形式的验证码,而在应用时,待识别的验证码是另一种形式,那么前面训练的模型很可能无法有效识别后面的应用数据,这就是前面说的“泛化”。
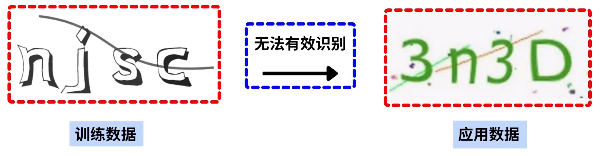
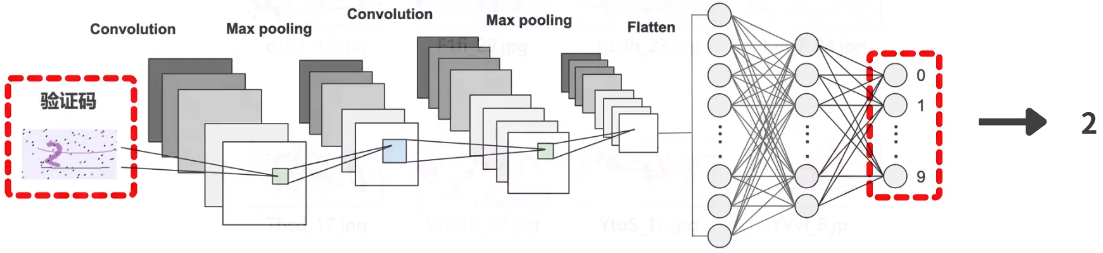
**无论哪种形式的验证码,其模型训练的过程是相同的,就是将验证码识别问题抽象为一个图片分类问题,其中使用卷积神经网络训练图片分类模型。**例如,如果验证码只有一位,对于这一位可能是 0 到 9 中的某个字符,那么我们就要把输入的验证码图片,识别为 0 到 9 中的某个类别:
生成验证码
我们使用代码生成一种特定形式的验证码数据,未来会使用生成的验证码数据训练识别验证码的卷积神经网络模型。安装命令如下:
python
import os
import random
# 导入验证码模块ImageCaptcha
from captcha.image import ImageCaptcha
# 定义函数generate_data,用于生成验证码图片
def generate_data(num, count, chars, path, width, height):
# 使用变量i,循环生成num个验证码图片
for i in range(num):
# 打印当前的验证码编号
print("generate %d"%(i))
# 使用ImageCaptcha,创建验证码生成器generator
generator = ImageCaptcha(width=width, height=height)
random_str = "" # 保存验证码图片上的字符
# 向random_str中,循环添加count个字符
for j in range(count):
# 每个字符,使用random.choice,随机的从chars中选择
choose = random.choice(chars)
random_str += choose
# 调用generate_image,生成验证码图片img
img = generator.generate_image(random_str)
# 生成的验证码本身就有自带一些干扰点,在此基础上再随机增加4~40个黑色干扰点
generator.create_noise_dots(img, '#000000', 4, 40)
# 生成的验证码本身就有自带一条干扰线,在此基础上再增加一条黑色干扰线
generator.create_noise_curve(img, '#000000')
# 设置文件名,命名规则为,验证码字符串random_str,加下划线,加数据编号
file_name = path + random_str + '_' + str(i) + '.jpg'
img.save(file_name) # 保存文件
if __name__ == '__main__':
# 字符列表
NUMBER = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
LOW_CASE = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
UP_CASE = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z']
CAPTCHA_CHAR = NUMBER + LOW_CASE + UP_CASE # 验证码包含的字符
CAPTCHA_NUM = 100 # 待生成的验证码图片数量
CHAR_COUNT = 4 # 验证码图片中的字符数
SAVE_PATH = "./data/" # 保存路径
CAPTCHA_WIDTH = 200 # 验证码图片宽度
CAPTCHA_HEIGHT = 100 # 验证码图片高度
# 生成data文件夹保存验证码图片
os.makedirs(SAVE_PATH, exist_ok=True)
# 调用generate_data,生成验证码数据
generate_data(CAPTCHA_NUM, CHAR_COUNT, CAPTCHA_CHAR, SAVE_PATH, CAPTCHA_WIDTH, CAPTCHA_HEIGHT)