哈希算法
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
回顾前面学习哈希表的工作原理和哈希冲突的处理方法。然而无论是开放寻址还是链式地址,它们只能保证哈希表可以在发生冲突时正常工作,而无法减少哈希冲突的发生。如果哈希冲突过于频繁,哈希表的性能则会急剧劣化。如下图所示,对于链式地址哈希表,理想情况下键值对均匀分布在各个桶中,达到最佳查询效率;最差情况下所有键值对都存储到同一个桶中,时间复杂度退化至 。可以看出来,影响哈希表冲突频率的关键因素就是键值对的分布,而键值对的分布是由哈希函数决定的。
算法介绍
哈希函数,又称散列函数,是一种将一个较大的输入空间映射到一个较小的输出空间的函数。其中,映射的过程是由哈希函数的核心“哈希算法”来完成。
哈希算法能把任意长度的输入转换为一个唯一的固定长度的输出,这个输出值就是哈希值(散列值),并且此过程不可逆,也就是说无法通过哈希值还原输入内容。简单讲,哈希算法本质上就是 关键字(key) 到 哈希值(Hash value) 的一种不可逆的映射关系。
回到哈希表上,当哈希表容量固定时,哈希算法 hash() 决定了输出值,进而决定了键值对在哈希表中的分布情况。这意味着,为了降低哈希冲突的发生概率,我们应当将注意力集中在哈希算法 hash() 的设计上。
算法设计
设计目标
为了实现“既快又稳”的哈希表数据结构,哈希算法的设计是一个需要考虑许多因素的复杂问题。总体来说,哈希算法应具备以下特点:
- 确定性:对于相同的输入,哈希算法应始终产生相同的输出。这样才能确保哈希表是可靠的。
- 效率高:计算哈希值的过程应该足够快。计算开销越小,哈希表的实用性越高。
- 均匀分布:哈希算法应使得键值对均匀分布在哈希表中。分布越均匀,哈希冲突的概率就越低。
对于密码学的相关应用,为了防止从哈希值推导出原始密码等逆向工程,哈希算法需要具备更高等级的安全特性。
- 单向性:无法通过哈希值反推出关于输入数据的任何信息。
- 抗碰撞性:应当极难找到两个不同的输入,使得它们的哈希值相同。
- 雪崩效应:输入的微小变化应当导致输出的显著且不可预测的变化。
请注意,“均匀分布”与“抗碰撞性”是两个独立的概念,满足均匀分布不一定满足抗碰撞性。例如,在随机输入 key 下,哈希函数 key % 100 可以产生均匀分布的输出。然而该哈希算法过于简单,所有后两位相等的 key 的输出都相同,因此我们可以很容易地从哈希值反推出可用的 key ,从而破解密码。
算法使用
标准算法
在实际中,我们通常会用一些标准哈希算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等,它们可以将任意长度的输入数据映射到恒定长度的哈希值。在介绍使用它们前,我们需要安装一个实现哈希算法的 hashlib 第三方库,它里面提供了常见的 MD5、SHA1、SHA2 算法等。
pip install hashlibMD5
MD5 信息摘要算法(MD5 Message-Digest Algorithm)是一种被广泛用于确保信息传输完整一致的密码散列函数,它可以产生出一个128位(16字节)的散列值,呈现形式为 32 个十六进制数(逆向常用)。在软件的下载网站一般会给出下载软件文件的 MD5 值,用于校验文件完整性。如果在下载过程中文件出现了损坏,或者骇客在里面添加了病毒程序,其文件的 MD5 值就会发生变化。
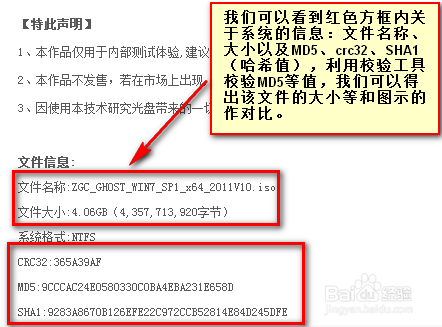
我们将下载好文件拖入MD5校验工具中,将工具生成 MD5 值同网站给出的 MD5 值比对,即可校验文件完整性。
.Bxe8jMsn.png)
同样,hashlib 库也能计算文件的 MD5 值:
python
import hashlib
# 生成md5散列对象
hasher = hashlib.md5()
# 打开文件
with open('文件路径/文件.后缀名', 'rb') as file:
while True:
# 每次循环读取512字节
data = file.read(512)
if data:
# 更新MD5对象的数据
hasher.update(data)
else:
break
# 最后返回十六进制形式的MD5哈希摘要
print(hasher.hexdigest())另外,hashlib 库也能计算字符串的 MD5 值:
python
import hashlib
# 被哈希的字符串
str1 = 'abc'
# 生成md5散列对象,将字符串转换为二进制字符串(bytes类型)添加进散列对象中,返回十六进制字符串
str2 = hashlib.md5(str1.encode('utf-8')).hexdigest()
# md5中间散列16位
print('16位MD5散列:' + str2[8:-8])
print('16位MD5散列:' + str2.upper()[8:-8])
# md5完整散列32位
print('32位MD5散列:' + str2)
print('32位MD5散列:' + str2.upper())
'''
输出:
16位MD5散列:3cd24fb0d6963f7d
16位MD5散列:3CD24FB0D6963F7D
32位MD5散列:900150983cd24fb0d6963f7d28e17f72
32位MD5散列:900150983CD24FB0D6963F7D28E17F72
'''SHA-1
SHA-1(英文全称:Secure Hash Algorithm 1,中文全称:安全散列算法 1)是由美国国家安全局设计的一种密码散列函数,它可以生成一个被称为消息摘要的 160 位(20 字节)散列值,呈现形式为 40 个十六进制数。与 MD5 一样,SHA-1 也可以被用于验证文件的完整性。
同样,hashlib 库也能计算字符串的 SHA-1 值:
python
import hashlib
# 被哈希的字符串
str1 = 'abc'
# 生成sha1散列对象,将字符串转换为二进制字符串(byte类型)添加进散列对象中,返回十六进制字符串
str2 = hashlib.sha1(str1.encode('utf-8')).hexdigest()
print('SHA-1散列前:' + str1)
print('SHA-1散列后:' + str2)
'''
输出:
SHA-1散列前:abc
SHA-1散列后:a9993e364706816aba3e25717850c26c9cd0d89d
'''SHA-2
SHA-2(英语:Secure Hash Algorithm 2,中文名:安全散列算法2)是由美国国家安全局研发的一种密码散列函数,属于 SHA-1 的后继者。SHA-2 又可再分为六个不同的算法标准,包括了:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256。这些变体除了生成摘要的长度 、循环运行的次数等一些微小差异外,算法的基本结构是一致的。实际中,最常用的 SHA-2 算法标准是SHA-256,它可以生成一个被称为消息摘要的 256 位(32 字节)散列值,呈现形式为 64 个十六进制数(逆向常用)。现在的网站 CA 证书上,就使用了 SHA-256 来生成指纹:
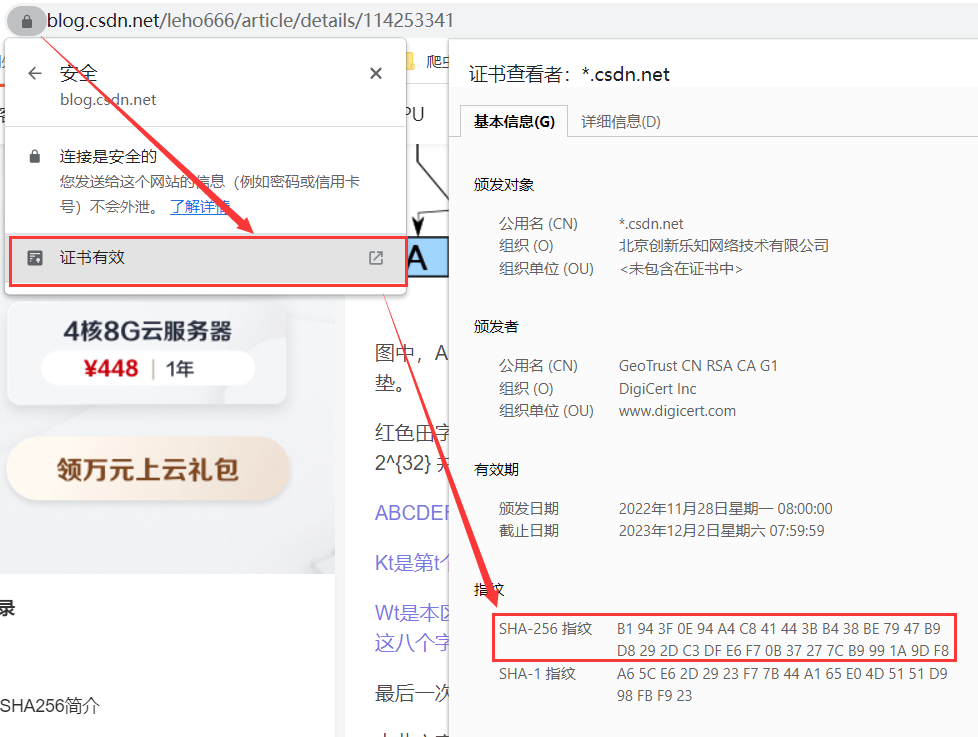
同样,hashlib 库也能对数据进行 SHA-256 哈希:
python
import hashlib
# 被哈希的字符串
str1 = 'abc'
# 生成sha256散列对象,将字符串转换为二进制字符串(byte类型)添加进散列对象中,返回十六进制字符串
str2 = hashlib.sha256(str1.encode('utf-8')).hexdigest()
print('SHA-256散列前:' + str1)
print('SHA-256散列后:' + str2)
'''
输出:
SHA-256散列前:abc
SHA-256散列后:ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad
'''差异比较
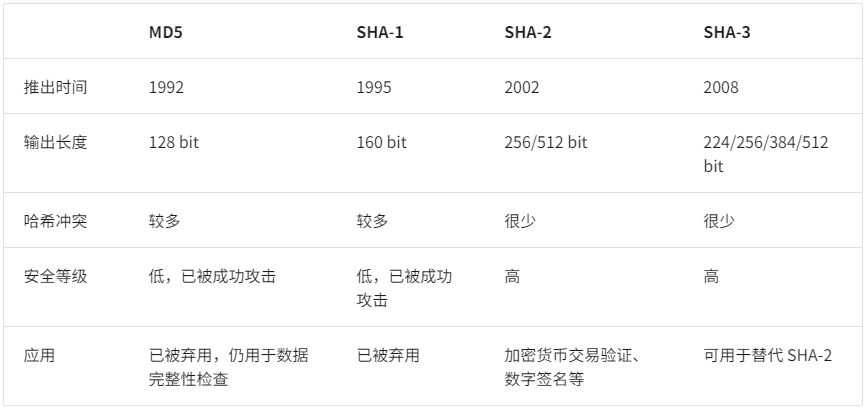
MD5、SHA-1、SHA-2 都属于哈希算法,它们的共同点都是将一个任意长度的输入转换为一个唯一的固定长度的输出,而且都具有不可逆的特点。它们之间的区别如下:
- MD5 和 SHA-1 已多次被成功攻击,因此它们被各类安全应用弃用。
- SHA-2 系列中的 SHA-256 是最安全的哈希算法之一,仍未出现成功的攻击案例,因此常用在各类安全应用与协议中。
- SHA-3 相较 SHA-2 的实现开销更低、计算效率更高,但目前使用覆盖度不如 SHA-2 系列。
提醒
在 Crypto 2004 会议上中国数学家王小云等提出一种能成功攻破 MD5 的算法,但只停留在算法的层面,网上那些所谓的 MD5 在线破解,其实就是采用跑字典方法,暴力求逆,目前没有软件能有效地求逆 MD5。与 MD5 一样,SHA-1 算法的破解也是由王小云提出的,但也只停留在算法的层面,目前没有软件能有效地求逆 SHA-1。
国密
以下是使用 gmssl 库中的 SM3 加密算法的 Python 实现。gmssl 是一个支持国密算法的第三方库,支持 SM3、SM2、SM4 等加密算法。
安装 gmssl 库
如果你还没有安装 gmssl 库,可以通过以下命令安装:
bash
pip install gmssl使用 SM3 加密的 Python 实现
python
from gmssl import sm3, func
def sm3_hash(data):
# 将输入数据转换为字节
data_bytes = data.encode('utf-8')
# 使用 gmssl 库的 sm3 哈希函数
hash_value = sm3.sm3_hash(func.bytes_to_list(data_bytes))
return hash_value
# 示例
data = 'hello, SM3!'
hash_result = sm3_hash(data)
print(f"SM3 hash: {hash_result}")说明:
sm3.sm3_hash是gmssl提供的 SM3 哈希函数。func.bytes_to_list将字节数据转换为列表,这是 SM3 算法所需的输入格式。- 最终的输出是 256 位(32 字节)的十六进制格式哈希值。
示例输出:
SM3 hash: 7c626ee12bbf64b3d437b0b70ffbce68c6c055f9f2197a934dfecc43db59d886这个方法非常简单,利用 gmssl 库即可轻松实现 SM3 哈希。
内置算法
数据类型
前面讲过,字典的底层结构就是哈希表,而字典的 key 可以是整数、小数或字符串等数据类型。编程语言通常会为这些数据类型提供内置的哈希算法,用于计算哈希表中的桶索引。以 Python 为例,我们可以调用 hash() 内置函数来计算各种数据类型的哈希值。
- 整数和布尔量的哈希值就是其本身。
- 浮点数和字符串的哈希值计算较为复杂,有兴趣的读者请自行学习。
- 元组的哈希值是对其中每一个元素进行哈希,然后将这些哈希值组合起来,得到单一的哈希值。
python
num = 3
hash_num = hash(num)
# 整数 3 的哈希值为 3
bol = True
hash_bol = hash(bol)
# 布尔量 True 的哈希值为 1
dec = 3.14159
hash_dec = hash(dec)
# 小数 3.14159 的哈希值为 326484311674566659
str = "Hello 算法"
hash_str = hash(str)
# 字符串“Hello 算法”的哈希值为 4617003410720528961
tup = (12836, "小哈")
hash_tup = hash(tup)
# 元组 (12836, '小哈') 的哈希值为 1029005403108185979可哈希性
在 Python 中并不是所有的对象都可哈希。一个对象是否可哈希必须满足以下两个条件:
- 哈希值在对象的整个生命周期内不可改变。
- 可比较,两个对象相等的情况下,它们的哈希值一定相同。
假如我们将列表(动态数组)作为 key ,当列表的内容发生变化时,它的哈希值也随之改变,我们就无法在哈希表中查询到原先的 value 了。正是由于可变对象(mutable)的内容可以被改变,导致哈希值的变化,也就无法查询其在哈希表中对应的值,因此是不可哈希的(unhashable)。而不可变对象(immutable)的内容不能被改变,所以哈希值也是固定的,也就能查询其在哈希表中对应的值,因此是可哈希的(hashable)。具体的可哈希性如下:
- 不可哈希(
unhashable)的数据类型:列表(list)、字典(dict)、集合(set)。
python
print(hash([1, 2, 3])) # 报错:列表不可哈希。
print(hash({'12': 3})) # 报错:字典不可哈希。
print(hash({1, 2, 3})) # 报错:集合不可哈希。- 可哈希(
hashable)的数据类型:整型(int)、浮点型(float)、字符型(str)、布尔型(bool)、只包含不可变对象的元组(tuple)。
python
print(hash('123')) # 输出:-2971724094100733724
print(hash((1, 2, 3))) # 输出:2528502973977326415
print(hash((1, 2, [3]))) # 报错:元组(tuple)可哈希是有前提的,就是里面的所有元素也必须是可哈希的,这里列表元素[3]是不可哈希的,所以这里元组是不可哈希的。另外,自定义对象(比如链表节点)的成员变量是可变的,但它是可哈希的。这是因为对象的哈希值通常是基于内存地址生成的,即使对象的内容发生了变化,但它的内存地址不变,哈希值仍然是不变的。
python
obj = ListNode(0)
hash_obj = hash(obj)
# 节点对象 <ListNode object at 0x1058fd810> 的哈希值为 274267521加盐保护
细心的人可能会发现运行上面的 hash() 内置哈希算法,得到的哈希值与注释的哈希值不一样。这是因为 Python 解释器在每次启动时,哈希函数会在原始数据里加入一段无用的数据来进行哈希,这一段无用的数据称之为“盐值(Salt)”,加入无用的数据过程称之为“加盐(Add salt)”。为什么要这样做呢?举个例子,我们都知道哈希算法是根据一定规则来对原始数据进行哈希,所以理论上是可以从结果倒推出原始数据是什么。比如,有一位骇客收集了有关成语的 MD5 哈希值,组成了如下字典:
| key(MD5 哈希值) | value(四字成语) |
|---|---|
| 5318BBF914C29C244391FFF764504E34 | 蒸蒸日上 |
| D2CB550B1F6D6405CF05990C28280368 | 江河日下 |
| ... | ... |
有一天他截获到 5318BBF914C29C244391FFF764504E34 这样一段 MD5 哈希值,通过上面的字典很快就能对应出哈希前的内容为 蒸蒸日上,所以后面有关成语的 MD5 哈希值基本都能通过跑字典进行暴力求逆。但假如我们在内容里面加入一个随机盐值,比如 蒸蒸日上_9527 得到 MD5 哈希值就变为了 6D652EFFA12EE1942F5F3CEB46B06F2F,这下骇客的字典库里面没有该 MD5 哈希值,也就无法通过跑字典进行暴力求逆了。所以,加盐会让其他人无法通过倒推的方式来解密,还能有效防止 HashDoS 攻击,提升哈希算法的安全性。
算法特点
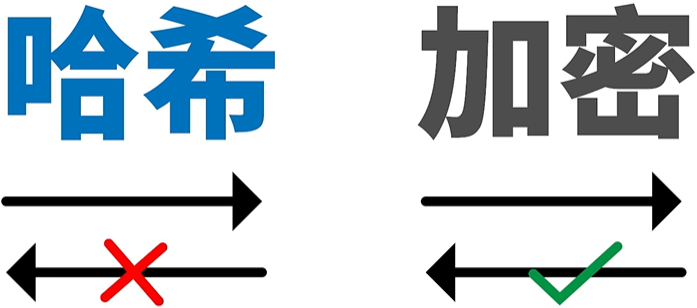
哈希算法具有加密特性,因此经常有同学会把哈希等同于加密,实则不然。严格来说哈希不是加密,因为哈希有如下三个重要的特点:
- 没有密钥:无论是加密,还是解密,都会使用到密钥,而哈希没有密钥;
- 不可逆向:加密都是可逆的,只要获得“密钥”,就可以将密文解密为明文,而哈希过后的数值是不可逆的。
- 长度固定:密文长度通常会随着被加密对象的变化而变化,而哈希的数值长度是固定的,不受被哈希对象的变化。
算法应用
哈希算法除了可以用于实现哈希表,还广泛应用于其他领域中:
网页反爬:哈希算法也常用在一些反爬网页的请求参数中,因为哈希不可逆,我们只能一步步去调试跟踪,找到被哈希前的对象。
数据校验:数据发送方可以计算数据的哈希值并将其一同发送,接收方可以重新计算接收到的数据的哈希值,并与接收到的哈希值进行比较。如果两者匹配,那么数据就被视为完整。
密码存储,为了保护用户密码的安全,一些网站在存储用户密码的时候,不会明文存储,而是会对密码进行一个哈希操作,保存密码的哈希值,当用户输入密码时,系统会对输入的密码计算哈希值,然后与存储的哈希值进行比较。如果两者匹配,那么密码就被视为正确。这样即使网站的用户数据被泄露了,也不用担心用户的账户被盗,这是因为密码的哈希值是无法逆向还原为密码的。
文件秒传,在一些具有上传功能的云盘软件中,有一种上传方式叫“极速秒传”,其实这种上传文件的方式根本没有上传文件,它是先对文件进行了一个哈希操作得到一个哈希值,服务器将这个哈希值拿去对比硬盘中已存文件的哈希值,如果有相同的哈希值文件,说明服务器中已经有了相同的文件,那么只用修改一条用户数据,把用户标记为拥有了这个文件即可,这不仅节省了带宽,还节省了服务器的硬盘资源,也说明服务器中的文件都是独一无二,不可能同一个的文件保存个几百上千份,否则服务器的存储预算就要爆炸了。