Scrapy框架【中间件】
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
在前面介绍 Scrapy 架构时提到了中间件,简单来讲就是一个钩子框架,主要处理组件之间的请求以及响应,其中又分为下载中间件(Downloader Middleware)、爬虫中间件(Spider Middleware),下面进行深入介绍。
Downloader Middleware
下载中间件(Downloader Middleware):一个处于 Engine 和 Downloader 之间的处理模块,其功能十分强大,例如修改 User-Agent、处理重定向、设置代理、失败重试、设置 Cookie 等功能都需要借助它来实现。

在整个架构中,下载中间件起作用的位置是以下两个:
Engine从Scheduler获取 Request 请求对象发送给Downloader的过程中,下载中间件可以对 Request 请求对象进行处理。Downloader处理 Request 请求对象后生成 Response 响应对象发送给Engine的过程中,下载中间件可以对 Response 对象进行处理。
使用说明
在 Scrapy 中内置了许多不同功能的下载中间件,我们可以在了 Scrapy 默认配置文件 default_settings.py 中的 DOWNLOADER_MIDDLEWARES_BASE 变量中看到内置的下载中间件。比如 RetryMiddleware 负责失败重试、Redirectmiddleware 自动重定向等,这些功能默认都是开启的。
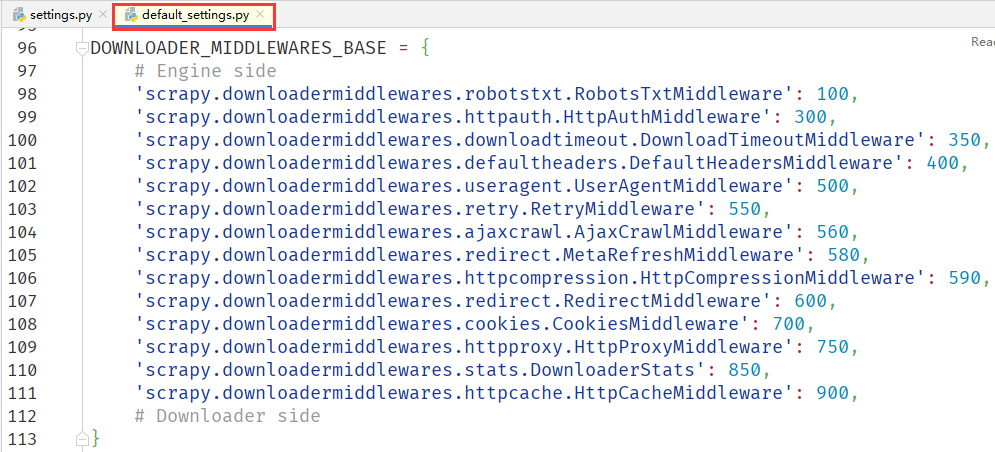
可以看到 Downloader Middleware 的整个配置是一个字典格式,详细说明如下:
- 键名,由路径的和类名组成,例如
scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware代表scrapy安装包,downloadermiddlewares文件夹,robotstxt文件,RobotsTxtMiddleware类名。
- 键值,一个整形数字,代表了下载中间件的执行优先级,我们可以将其看作为下载中间件到
Engine的距离,键值越小则越靠近Engine,也就越远离Downloader。因此当 Request 请求对象从Engine过来时,距离Engine近的下载中间件先处理,距离Engine远的下载中间件后处理,但当 Response 响应对象从Downloader返回时,情况就反过来了,距离Engine远的下载中间件先处理,距离Engine近的下载中间件后处理。
python
Downloader_Middleware = {
'Downloader_Middleware_1': 300,
'Downloader_Middleware_2': 400,
'Downloader_Middleware_3': 500,
}
核心方法
假如我们要自定义一个下载中间件该如何实现呢?很简单,只需要实现下载中间件中三个核心方法的其中一个就行。具体方法如下:
process_request(request, spider)处理请求,其中request即 Request 请求对象,spider即发送请求的 Spider 对象。当 Request 请求对象被Engine发送给Downloader的过程中,就会调用该方法对 Request 进行处理,并且返回值必须为下面四者之一:如果返回
None,Scrapy 会接着调用优先级更低的下载中间件中的process_request方法对该 Request 请求对象继续进行处理,直到送至Downloader才结束。如果返回 Request 请求对象,那么优先级更低的下载中间件中的
process_request方法将不会执行。这个 Request 会返回给Engine,Engine会重新放到调度队列里,相当于一个全新的 Request 请求对象,等待被调度。如果被Scheduler调度了,那么所有的下载中间件的process_request方法会被重新按照顺序执行。如果返回 Response 响应对象,所有下载中间件中的
process_request方法和process_exception方法不会再被调用,转而依次调用优先级更高的下载中间件中的process_response方法。调用完毕后,直接将 Response 响应对象发送给 Spider 处理。比如,有 3 个下载中间件,优先级依次为 100、200、300,当优先级为 200 的中间件中process_request方法中返回了 Response 响应对象后,优先级为 300 的中间件将不再调用,转而执行优先级为 200、100 的下载中间件中的process_response方法来处理 Response 响应对象。如果抛出
IgnoreRequest异常,那么所有的下载中间件中的process_exception方法会依次执行。如果没有一个方法处理这个异常,则回调 Request 请求对象中的errorback参数指定的函数。如果该异常还没有被处理,那么它便会被忽略。
process_response(request, response, spider)处理响应,其中request即 Request 请求对象,response即 Response 响应对象,spider即获取响应的 Spider 对象。Downloader执行 Request 请求对象下载得到 Response 响应对象发送给Engine的过程当中,就会调用该方法对 Response 响应对象进行处理,返回值必须是下面三者之一:- 如果返回 Request 请求对象,优先级更低的下载中间件中的
process_response方法不会再调用。这个 Request 对象会重新放到调度队列里,成为一个全新的 Request 请求对象,等待被调度。如果被Scheduler调度了,那么所有的下载中间件中的process_request方法会被重新按照顺序执行。 - 如果返回 Response 响应对象,优先级更低的下载中间件中的
process_response方法会被依次调用,对该 Response 响应对象进行处理。
- 如果返回 Request 请求对象,优先级更低的下载中间件中的
如果抛出
IgnoreRequest异常,则回调 Request 请求对象的errorback参数指定的函数。如果该异常还没有被处理,那么它会被忽略。process_exception(request, exception, spider)处理异常,其中request即 Request 请求对象,exception即抛出的 Exception 异常对象,spider产生异常的 Spider 对象。当 Downloader 或process_request()方法抛出异常时,该方法就会被调用,返回值必须为下面三者之一:- 如果返回
None,优先级更低的下载中间件中的process_exception方法会被继续顺次调用,直到所有的方法都被调用完毕。 - 如果返回 Request 请求对象,优先级更低的下载中间件中的
process_request方法不再被继续调用。这个 Request 对象会重新放到调度队列里,其实它就是一个全新的 Request 请求对象,等待被调度。如果被Scheduler调度了,那么所有的下载中间件中的process_request方法会被重新按照顺序执行。 - 如果返回 Response 响应对象,优先级更低的下载中间件中的
process_exception方法不再被继续调用,转而依次调用每个下载中间件的process_response方法。调用完毕后,将 Response 对象发送给 Spider 进行处理。
- 如果返回
以上内容便是下载中间件核心方法的详细使用逻辑。在使用它们之前,请先对这三个核心方法返回值的处理情况有一个清晰认识。
设置 Headers
在未设置请求头的情况下,Scrapy 的 Request 请求对象使用的 User-Agent 是 Scrapy/2.2.1(+https://scrap.org),这是由 Scrapy 内置的下载中间件中的 UserAgentMiddleware 源码设置的:在 from_crawler 方法中,尝试获取 settings 全局配置里面的 USER_AGENT 参数,将其传递给 __init__ 方法初始化,其参数就是 user_agent。在 spider_opened 方法中,如果没有传递 USER_AGENT 参数,就使用默认的初始化 Scrapy 字符串。接下来,在 process_request 方法中判断 user_agent 变量是否有内容,再确定是否向 Request 请求对象的 headers 属性添加 User_Agent 配置。
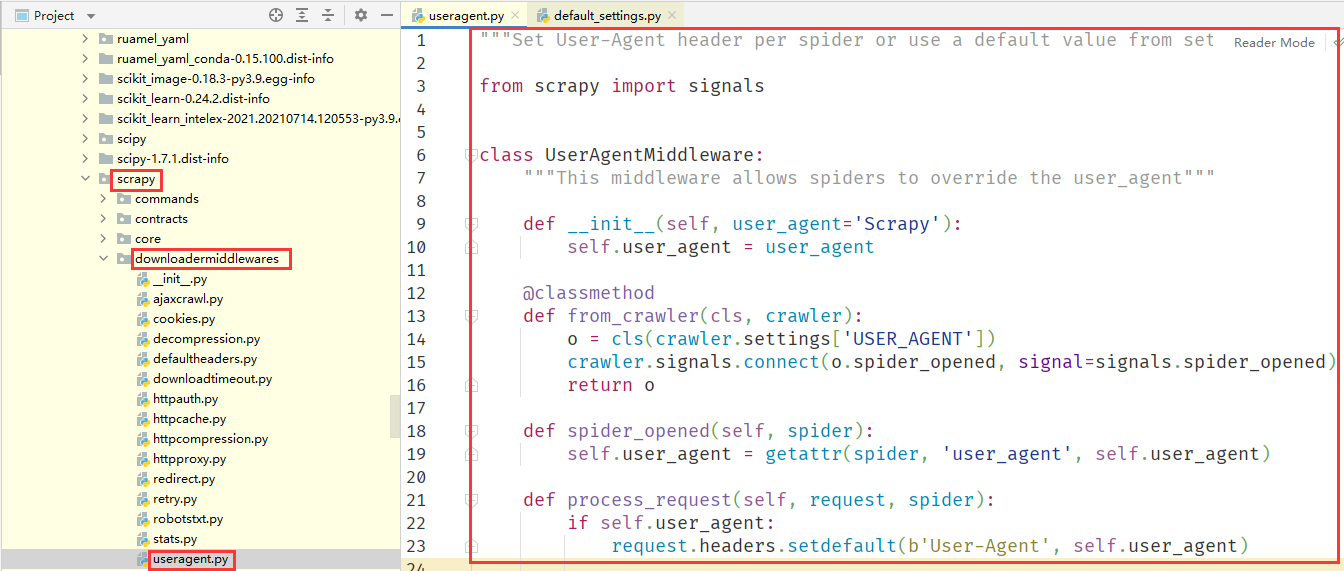
这样每次 Request 请求对象在被交给 Downloader 执行下载前,都会被 UserAgentMiddleware 的 process_request 方法加上默认的 User-Agent,但如果使用这个默认的 User-Agent 去请求目标网站,很容易被检测出来。所以现在我们来实现一个给 Request 请求对象添加随机请求头的下载中间件,我们在 middlewares.py 文件中添加一个 RandomUserAgentMiddleware 类:
python
import random
# 定义一个类
class RandomUserAgentMiddleware():
# __init_()方法中定义了三个不同的User-Agent
def __init__(self):
self.user_agents = [
'Mozilla/5.0 (Windows; U; Win 9x 4.90; ja-JP; rv:0.9.4) Gecko/20011128 Netscape6/6.2.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; ja-JP; rv:0.9.4.1) Gecko/20020508 Netscape6/6.2.3',
'Mozilla/5.0 (Macintosh; N; PPC; ja-JP; macja-pub12) Gecko/20001108 Netscape6/6.0',
]
# 实现上面讲的process_request方法,参数request就代表Request对象。
def process_request(self, request, spider):
# 设置Request对象headers的User-Agent属性选择随机的User-Agent。
request.headers['User-Agent'] = random.choice(self.user_agents)建议
我们自定义的下载中间件的 process_request 方法没有设置返回值,即返回值为 None,这样可以保证后续其他下载中间件的 process_request 方法继续调用。
警告
如果下载中间件的 process_request 方法最后是 return request ,即返回一个 Request 请求对象,那么后续其他下载中间件的 process_request 方法就不会被调用,因为这里会将 Request 直接发送给 Engine 并加回到 Scheduler,等待下次调度。当下次这个 Request 请求对象被调度到时,再次经过 process_request 方法处理,又一次被加回到 Scheduler,导致 Request 请求对象不断从 Scheduler 取出来又放回去,这时就会得到一个递归错误信息 RecursionError: maximum recursion depth exceeded while calling a Python object。
设置代理 IP
我们还可以自定义下载中间件来设置代理,在 middlewares.py 文件添加一个 ProxyMiddleware 类实现 process_request 方法来添加代理:
python
import random
# 添加代理IP中间件
class ProxyMiddleware(object):
# 实现上面讲的process_request方法,参数request就代表Request对象。
def process_request(self, request, spider):
# 设置Request对象meta的proxy属性选择随机的代理IP。
request.meta['proxy'] = 'http://111.160.169.54:41820'重要
由于 Scrapy 对 Resquest 的 meta 中的 proxy 属性做了针对性处理,使得最终发送的 HTTP 请求使用了我们配置的代理 IP,具体处理逻辑可以查看 Downloader Middleware 和 Downloader 的源代码。
如果说我们是通过接口获取的代理,那么上面的中间件可以重写为如下代码:这里我们实现了一个 ProxyMiddleware,它的主要逻辑就是请求该代理池然后获取其返回内容,返回的内容便是一个代理地址。接着,我们直接将代理赋值给 request 的 meta 属性的 proxy 字段即可。值得注意的是,由于 Scrapy 2.0 及以上版本支持 asyncio,所以这里我们获取代理使用的是 aiohttp,可以更方便地实现异步操作,可以看到我们给 process_request 方法加上了 async 关键字,这样在方法内便可以使用 asyncio 的相关特性了。
python
import aiohttp
class ProxyMiddleware(object):
proxy_pool_url = 'http://127.0.0.1:5555/random'
async def process_request(self, request, spider):
async with aiohttp.ClientSession() as client:
response = await client.get(self.proxy_pool_url)
if not response.status == 200:
return
proxy = await response.text()
request.meta['proxy'] = f'http://{proxy}'设置 Cookie
我们还可以自定义下载中间件来设置代理,在 middlewares.py 添加一个 CookieMiddleware 类实现 process_request 方法来设置 Cookie:
python
# 添加Cookie
class CookieMiddleware(object):
# 实现上面讲的process_request方法,参数request就代表Request对象。
def process_request(self, request, spider):
# 设置Request对象cookie的uuid字段值。
request.cookies['uuid'] = '66a0f5e7546b4e068497'配置启用
上面三个自定义的下载中间件写好以后,还需要把它们添加到启动配置中才能发挥其功能,注意这里不能直接修改 default_settings.py 默认配置文件中的 DOWNLOADER_MIDDLEWARES_BASE 变量,而是通过修改 settings.py 配置文件中的 DOWNLOADER_MIDDLEWARES 变量添加自定义的下载中间件,以及禁用 DOWNLOADER_MIDDLEWARES_BASE 里面内置的下载中间件。在 settings.py 中,将 DOWNLOADER_MIDDLEWARES 取消注释,添加上面的类:
python
# project_name项目名称,middlewares即middlewares.py文件,...Middleware上面定义的Downloader Middleware
DOWNLOADER_MIDDLEWARES = {
# 禁用scrapy内置请求头下载中间件
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None
# 启用自定义的随机请求头下载中间件
'project_name.middlewares.RandomUserAgentMiddleware': 542,
# 启用自定义的代理下载中间件
'project_name.middlewares.ProxyMiddleware': 543,
# 启用自定义的Cookie下载中间件
'project_name.middlewares.CookieMiddleware': 544,
}建议
如果两个中间件的优先级相同,那么它们的执行顺序将按照它们在配置中的顺序来决定,即先出现在配置中的中间件先执行,后出现的中间件后执行。
拓展延伸
通过上面的案例可以看到实现下载中间件,最重要的就是实现 process_request 方法,而且该方法返回了 None。假如该方法返回一个基于 HtmlResponse 类通过 url、status、encoding、body 参数构造了的 Response 响应对象,那么优先级更低的下载中间件中的 process_request 方法和 process_exception 方法就不会被继续调用,转而去调用每个下载中间件的 process_response 方法对 Response 响应对象进行处理,最后发送给 Spider 进行处理,而原先的 Request 请求对象也就不会再经由 Downloader 执行下载了。
python
from scrapy.http import HtmlResponse
class TestMiddleware(object):
def process_request(self, request, spider):
# 返回基于HtmlResponse类的Response响应对象
return HtmlResponse(
url=request.url,
status=200,
encoding='utf-8',
body='Test Downloader Middleware'
)我们再来看一下 process_response 的用法,比如这里修改一下 Response 的状态码,代码如下:将 Response 响应对象的 status 属性修改为 201,随后将 response 返回,这个被修改的 Response 就会被发送到 Spider,我们在 Spider 里面输出修改后的状态码就是 201 了。
python
from scrapy.http import HtmlResponse
class TestMiddleware(object):
def process_response(self, request, response, spider):
response.status = 201
return responseSpider Middleware
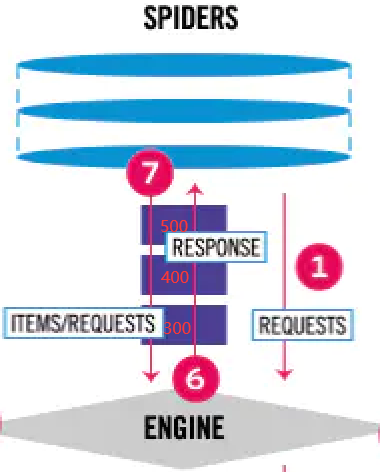
爬虫中间件(Spider Middleware):它是处于 Spider 和 Engine 之间的处理模块,主要用来处理 Spider 接收的 Response 响应对象和 Spider 输出的 ltem 数据对象以及 Request 请求对象。
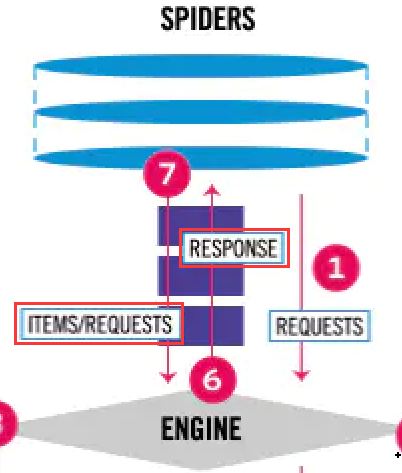
在整个架构中,爬虫中间件起作用的位置是以下两个:
- 当
Engine将Downloader返回的 Response 响应对象转发给Spider的过程中,Response 响应对象会经过爬虫中间件进行处理。 - 当
Spider处理 Response 响应对象生成 Item 数据对象和后续 Request 请求对象发送给Engine的过程中,Item 数据对象和后续 Request 请求对象还会经过爬虫中间件进行处理。
使用说明
与下载中间件类似,Scrapy 内置了许多不同功能的爬虫中间件,它们都可以在 Scrapy 默认配置文件 default_settings.py 中的 SPIDER_MIDDLEWARES_BASE 变量中看到,这些功能也都是默认开启的。
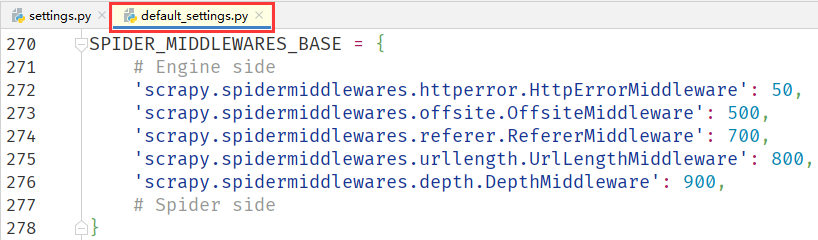
与下载中间件一样,整个爬虫中间件的配置也是一个字典格式,说明如下:
- 键名,由路径的和类名组成,例如
scrapy.spidermiddlewares.httperror.HttpErrorMiddleware代表scrapy安装包,spidermiddlewares文件夹,httperror文件,HttpErrorMiddleware类名。
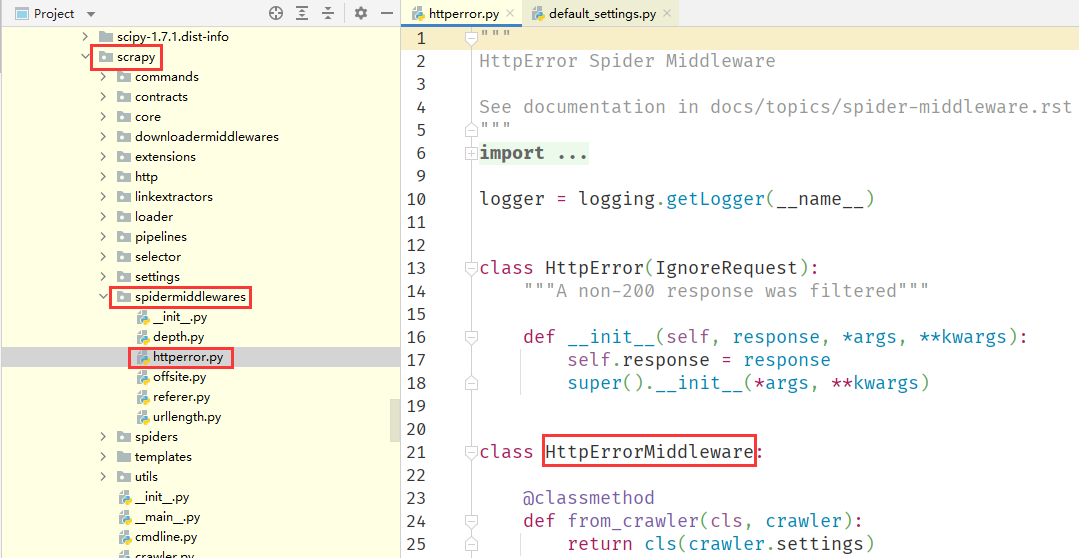
- 键值,一个整形数字,代表了爬虫中间件的执行优先级,我们同样可以理解为爬虫中间件到
Engine的距离,键值越小则越靠近Engine,也就越远离Spider,当 Response 响应对象从Engine发送时,距离Engine近的爬虫中间件先处理,距离Engine远的爬虫中间件后处理,但当Item/Request从Spider返回时,情况就反过来了,距离Engine远的爬虫中间件先处理,距离Engine近的爬虫中间件后处理。
python
Spider_Middleware = {
'Spider_Middleware_1': 300,
'Spider_Middleware_2': 400,
'Spider_Middleware_3': 500,
}
核心方法
假如我们要自定义一个爬虫中间件该如何实现呢?很简单,只需要实现 Spider Middleware 四个核心方法的其中一个就可以了。四个核心方法具体如下:
process_start_requests(start_requests, spider)其中start_requests即包含 Request 的可迭代对象(即 Start Request),spider即 Start Requests 所属的 Spider 爬虫对象。该方法以 Spider 启动的 Request 请求对象为参数被调用,它没有相关联的 Response 响应对象,并且必须返回另一个包含 Request 请求对象的可迭代对象。process_spider_input(response, spider)其中response即被处理的 Response 响应对象,spider即此 Response 响应对象对应的 Spider 爬虫对象。返回值必须为None或者抛出一个异常。- 如果返回
None,Scrapy 会继续处理该 Response,调用所有其他的Spider Middleware直到 Spider 处理该 Response。 - 如果抛出异常,优先级更低的爬虫中间件的
process_spider_input方法不会被调用,并调用 Request 的errback方法。errback的输出将会以另一个方向被重新输入中间件,使用process_spider_output方法来处理,当其抛出异常时则调用process_spider_exception来处理。
- 如果返回
process_spider_output(response, result, spider)其中response即生成该输出的 Response 响应对象,result即 Spider 返回的包含 Request 请求对象或 Item 数据对象的可迭代对象,spider即结果对应的 Spider 爬虫对象。当 Spider 处理 Response 响应对象时,该方法会被调用,且必须返回包含 Request 请求对象或 Item 数据对象的可迭代对象。process_spider_exception(response, exception, spider)其中response即异常被抛出时被处理的 Response 响应对象,exception即被抛出的 Exception 异常对象,spider即抛出该异常的 Spider 爬虫对象。当爬虫中间件的process_spider_input()方法抛出异常时,该方法会被调用,并且必须返回None或者一个(包含 Response 请求对象或 Item 数据对象)可迭代对象。- 如果返回
None,Scrapy 会继续调用优先级更低的爬虫中间件中的process_spider_exception方法来处理该异常,直到所有下载中间件都被调用。 - 如果返回可迭代对象,则其它爬虫中间件的
process_spider_output方法会被调用,而其它爬虫中间件的process_spider_exception方法不会被调用。
- 如果返回
状态码过滤
HttpErrorMiddleware 是 Scrapy 内置的爬虫中间件,主要作用是过滤响应状态码不是以 2 开头的 Response 响应对象,比如状态码为 200 至 299 的响应直接通过,而 500 以上的不会处理。其核心代码如下:可以看到它实现了 process_spider_input 方法,里面判断了状态码为 200 至 299 就直接返回,否则会根据 handle_httpstatus_all 和 handle_httpstatus_list 来进行处理。例如状态码在 handle_httpstatus_list 定义的范围内,就会直接处理,否则抛出 HttpError 异常。
python
def __init__(self, settings):
self.handle_httpstatus_all = settings.getbool('HTTPERROR_ALLOW_ALL')
self.handle_httpstatus_list = settings.getlist('HTTPERROR_ALLOWED_CODES')
def process_spider_input(self, response, spider):
if 200 <= response.status < 300: # common case
return
meta = response.meta
if meta.get('handle_httpstatus_all', False):
return
if 'handle_httpstatus_list' in meta:
allowed_statuses = meta['handle_httpstatus_list']
elif self.handle_httpstatus_all:
return
else:
allowed_statuses = getattr(spider, 'handle_httpstatus_list', self.handle_httpstatus_list)
if response.status in allowed_statuses:
return
raise HttpError(response, 'Ignoring non-200 response')URL 过滤
OffsiteMiddleware 是 Scrapy 内置的爬虫中间件,的主要作用是过滤不符合 allowed_domains 的 Request 请求对象,Spider 里面定义的 allowed_domains 其实就是在这个爬虫中间件里生效的。其核心代码实现如下:这里首先遍历了 result,然后判断了 Request 类型的元素并赋值为 x。然后根据 x 的 dont_filter、url 和 Spider 的 allowed_domains 进行了过滤,如果不符合 allowed_domains,就直接输出日志并不再返回 Request 请求对象,只有符合要求的 Request 请求对象才会被返回并继续调用。
python
def process_spider_output(self, response, result, spider):
for x in result:
if isinstance(x, Request):
if x.dont_filter or self.should_follow(x, spider):
# 返回了Request
yield x
else:
domain = urlparse_cached(x).hostname
if domain and domain not in self.domains_seen:
self.domains_seen.add(domain)
logger.debug(
"Filtered offsite request to %(domain)r: %(request)s",
{'domain': domain, 'request': x}, extra={'spider': spider})
self.stats.inc_value('offsite/domains', spider=spider)
self.stats.inc_value('offsite/filtered', spider=spider)
else:
# 返回了Item
yield xURL 加参
现在我们来实现一个给 URL 添加参数的爬虫中间件,在 middlewares.py 添加一个 CustomizeMiddleware 类:这里实现了 process_start_requests 方法,它可以对 start_requests 初始 URL 表示的每个 Request 请求对象进行处理。我们首先获取了每个 Request 请求对象的 URL,然后在 URL 的后面又拼接上了一个 &name=germey 参数,然后我们利用 request.replace 方法将 url 属性替换,这样就成功为初始的 Request 请求对象赋值了新的 URL。
python
class Customizemiddleware(object):
def process_start_requests(self, start_requests, spider):
for request in start_requests:
url = request.url
url += '&name=germey'
request = request.replace(url=url)
yield requestSpider 进出
我们还可以对 Spider 输入的 Response 响应对象和 Spider 输出的 Item 数据对象进行改写。首先在 items.py 文件中,定义 DemoItem 字段类的代码如下:
python
import scrapy
class DemoItem(scrapy.Item):
origin = scrapy.Field()
headers = scrapy.Field()
args = scrapy.Field()接着我们在 middlewares.py 文件中,定义一个 Handlemiddleware 爬虫中间件,并在里面实现 process_spider_input 方法,参数 response 自然就是输入给 Spider 的 Response 响应对象,我们直接在这里修改了状态码。再实现一个 process_spider_output 方法,输出的自然就是 Request 请求对象或 Item 数据对象了,但这里二者是混合在一起的,作为参数 result 传递过来。result 是一个可迭代对象,我们遍历了 result,然后使用 isinstance 方法判断了每个元素的类型,如果 i 是上面的 DemoItem 字段类型,就把它的 origin 属性置为空。
python
class Handlemiddleware(object):
def process_spider_input(self, response, spider):
response.status = 201
def process_spider_output(self, response, result, spider):
for i in result:
if isinstance(i, DemoItem):
i['origin'] = None
yield i配置启用
写好了上面两个自定义的爬虫中间件,还需要把它们添加到项目中才能发挥其功能,和启用下载中间件类似,这里就不能直接修改 default_settings.py 默认配置文件中的 SPIDER_MIDDLEWARES_BASE 变量,而是通过修改 settings.py 配置文件中的 SPIDER_MIDDLEWARES 变量添加自定义的爬虫中间件,以及禁用 SPIDER_MIDDLEWARES_BASE 变量里面定义的爬虫中间件。在 settings.py 中,将 SPIDER_MIDDLEWARES 取消注释,添加上面的类:
python
# project_name项目名称,middlewares即middlewares.py文件,...Middleware上面定义的Spider Middleware
SPIDER_MIDDLEWARES = {
# 禁用scrapy内置的状态码过滤爬虫中间件
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': None
# 启用自定义的URL加参爬虫中间件
'project_name.middlewares.Customizemiddleware': 542,
# 启用自定义的Spider进出爬虫中间件
'project_name.middlewares.Handlemiddleware': 543,
}建议
如果两个中间件的优先级相同,那么它们的执行顺序将按照它们在配置中的顺序来决定,即先出现在配置中的中间件先执行,后出现的中间件后执行。