数据存储操作
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
在爬虫运行的过程中会从网络上获取许多的数据,使用解析库可以将其中有价值的数据给提取出来,下一步就是将有价值的数据进行”持久化存储“,以便我们后期通过数据获取利益。所谓的”持久化“是指将数据从无法长久保存数据的存储介质(通常是内存)转移到可以长久保存数据的存储介质(通常是外存,也就是硬盘)。在商业项目、公司业务当中最常使用的数据持久化存储方式就是“数据库存储”,其主要优势在于以下几方面:
- 数据库加载快、存储量大。
- 数据库中的数据存放在硬盘当中,断电不丢失数据。
- 易于数据的增、删、改、查操作,能极大的减少了工作量。
- 数据库可以很简单的设置密码保护,提高了保护数据的安全性。
pymysql库
pymysql 是一个专门用于连接并操作 MySQL 数据库的第三方库,安装命令如下:
pip install pymysql警告
在执行下面操作时,请确保电脑中安装了 MySQL 数据库,并启动了 MySQL 服务。
连接执行
python
# 导入pymysql
import pymysql
# connect连接对象,负责开启\关闭连接MySQL数据库、提交执行操作。
connect = pymysql.connect(
host='127.0.0.1', # 数据库IP地址
user='root', # 连接用户名
password='123456', # 连接密码
database='db_name', # 数据库名称
port=3306, # 端口,int类型
charset='utf8', # 字符集,注意不是utf-8
# autocommit=True, # 自动提交,默认为False,表示不自动提交数据的增删改操作,需要手动提交。
# cursorclass=pymysql.cursors.DictCursor, # 字典结果,结果格式默认为((数据1), (数据2)...),设置后结果格式为[{字段1: 数据1}, {字段2: 数据2}...]。
)
# cursor游标对象,负责执行SQL语句。
cursor = connect.cursor()
try:
# 执行SQL查询语句
cursor.execute(f'SELECT 字段 FROM 表名 WHERE 条件语句')
# fetchall()返回所有的结果
print(cursor.fetchall()) # 输出:((数据1), (数据2)...)
# fetchmany(size=None)返回所有指定长度的结果
print(cursor.fetchmany(size=1)) # 输出:((数据1))
# fetchone()返回一条结果,如果没有结果返回None
print(cursor.fetchone()) # 输出:(数据1)
# 执行SQL建表语句
sql1 = "CREATE TABLE USER(\
Id INT PRIMARY KEY AUTO_INCREMENT, \
NAME VARCHAR(10), \
HOBBY VARCHAR(100))"
cursor.execute(sql1)
# 批量执行SQL插入语句
sql2 = "INSERT INTO USER(NAME, HOBBY) VALUES(%s, %s)"
cursor.executemany(sql2, [("chen", "computer"), ("zhuo", "study")])
# 若连接对象开启了自动提交,可以省略这里的手动提交。若没开启,除了查询操作外的其他操作都需要手动提交,否则操作无效。
connect.commit()
except:
# 操作失败就回滚再次执行SQL语句
connect.rollback()
# 关闭cursor游标对象、conn连接对象
cursor.close()
connect.close()建议
cursor游标对象、conn连接对象最后都会关闭,推荐使用上下文管理器来管理对象,在操作结束后,上下文管理器会自动销毁该对象。
提醒
常见错误,(1049, Unknown database 'lb'),没有名称为lb的数据库;(1045, Access denied for user 'rooot'@'localhost'(using password: YES));密码或用户名错误
[!ATTENTION]
使用
cursor去执行SQL语句,自始至终只有一个操作游标,如果使用connect.cursor()去执行SQL语句,则会生成多个操作游标,而且还可能会报错。
池化技术
数据库连接其实是一种稀缺的资源,这点在多用户页面上的体现尤为明显,每次与数据库建立连接都需要进行网络通信、身份认证等操作,而且面对大量的 Web 请求和插入与查询请求,单个的 MySQL 连接会不稳定,容易出现 Lost connection to MySQL server during query ([Errno 104] Connection reset by peer) 丢失 MySQL 服务连接的错误,**为此出现了专门负责分配、管理和释放数据库连接的”连接池“,其原理类似于进程池、线程池,其核心理念都是“池化复用”。在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非重新建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。这样可以避免每次需要连接数据库时都重新创建连接,从而减少了不必要的资源开销。**通过连接池来管理数据库连接,有以下几点优势:
- 共享使用:连接池中的连接可以被多个线程或进程共享使用,从而避免了频繁的连接和断开操作,提高数据库访问的响应速度和效率。
- 错误处理:连接池可以捕获和处理连接过程中的错误,例如连接超时、认证失败等。这样可以更好地处理异常情况,提高应用程序的健壮性和可靠性。
- 连接控制:连接池可以对连接的数量进行控制,限制同时打开的连接数量。这可以防止过多的连接导致数据库负载过高,保护数据库的稳定运行和性能。
- **最小连接数:限定连接池中最小数据库连接数量。**数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数制约。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。
- **最大连接数:限定连接池中最大数据库连接数量。**如果当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中,这会影响之后的数据库操作。
简单讲,连接池允许应用程序重复使用现有的数据库连接,而不是再重新建立数据库连接,应用这项技术能明显提高获取连接的速度和对数据库操作的性能,还能通过释放闲置的数据库连接来避免数据库连接遗漏。
池化案例
**DBUtils 是一套用于管理数据库连接池的 Python 包,为高频度、高并发的数据库访问提供更好的性能,可以自动管理连接对象的创建和释放。**安装命令如下:
pip install DBUtilsDBUtils 允许对非线程安全的数据库接口进行线程安全包装,提供两种能自动管理数据库连接的外部接口:
PersistentDB:为每个线程创建一个专用的、持久的数据库连接,即使在线程中关闭连接对象,连接也会保持打开状态,以便同一个线程的下一次连接请求直接使用,除线程执行结束该连接才会自动关闭。它通过回收数据库连接,在整体上增加多线程应用的数据库访问性能,以确保线程之间永远不会共享连接,因此执行速度最高,但是在某些特殊情况下,数据库的连接过程可能异常缓慢(适用于保持常量线程数且频繁使用数据库的应用)。PooledDB:为多个线程创建一组共享的数据库连接,当某个线程关闭不再共享的连接时,它会回收连接数据库到空闲连接池以便其他线程再次使用(适用于频繁开启、结束线程的应用)。
# DBUtils版本在1.2、1.3
from DBUtils.PooledDB import PooledDB
from DBUtils.PersistentDB import PersistentDB
# DBUtils版本在2、3(3.0.2、3.0.3)
from dbutils.pooled_db import PooledDB
from dbutils.persistent_db import PersistentDB建议
SQLite数据库只能使用 PersistentDB 作连接池。
python
# 导入pymysql
import pymysql
from dbutils.pooled_db import PooledDB
# 初始化pool连接池对象,只执行一次,可以作为模块级代码。
pool = PooledDB(
creator=pymysql, # 使用连接数据库的模块
host='127.0.0.1', # 数据库IP地址
user='root', # 用户名
passwd='123456', # 密码
db='db_name', # 数据库名称
port=3306, # 端口,int类型
charset='utf8', # 字符集,注意不是utf-8
maxconnections=200, # 连接池允许的最大连接数,默认为为0表示不限制连接数
mincached=2, # 初始化时,连接池中至少创建的连接,0表示不创建
maxcached=5, # 连接池中最多闲置的连接,0和None不限制
maxusage=1000, # 一个连接最多被重复使用的次数,默认为None表示无限制
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。默认为False,表示不等待并报错,为True,表示等待。
# ping=1, # 如果ping()方法可用,该值表示何时使用ping()方法检查连接(0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always, and all other bit combinations of these values)
# maxshared=1, # 连接池中最多共享的连接数量,0和None表示全部共享。由于pymysql、MySQLdb等threadsafety值为1,源码计算maxshared为0,所以该参数的对于pymysql和MySQLdb等模块来说是无效的。
# threadlocal=None, # 线程独享连接,供当前线程,当线程终止时,连接自动关闭。
# closeable=False, # 是否放回连接池,默认为False,即忽略close()中关闭连接的操作,把连接重新放到连接池中。如果为True时,close()则闭连接,不会放到连接池。
# setsession=[], # 用于传递到数据库的准备会话,如 ["set wait_timeout = 100", "set name UTF-8"]。
)
# 从连接池中获取一个连接成为connect连接对象
connect = pool.connection()
# cursor游标对象,负责执行SQL语句
cursor = conn.cursor()
# 执行sql语句
'''
这里和上面例子一样,都是使用cursor游标对象通过execute方法执行SQL语句。
'''
# 关闭cursor游标对象
cursor.close()
# 注意这里并没有将数据库连接关闭,而是将连接归还到连接池中。
connect.close()警告
在多线程环境中,这样写 pool.connection().cursor().execute(...) 会导致连接过早释放并被其他线程重用,如果连接非线程安全可能导致程序出现严重错误。
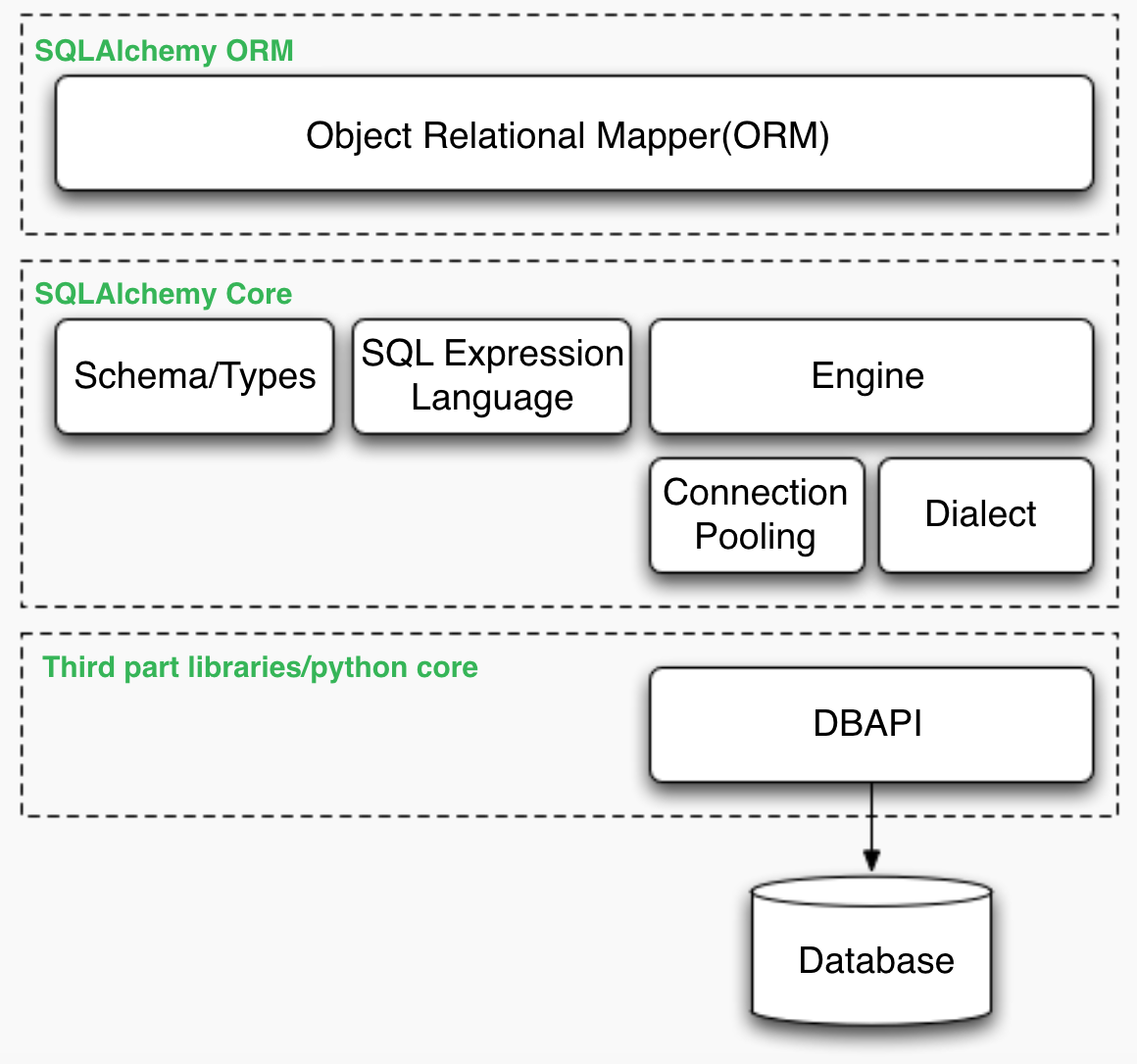
SQLAlchemy软件
SQLAlchemy 是 Python 编程语言下的一款开源软件,提供了 SQL 工具包及对象关系映射器(ORM),使用MIT许可证发行,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
- SQL 表达式语言,是一个完全独立于 ORM 包的工具包,它提供了一个构造由可组合对象表示的 SQL 表达式的系统,针对特定事务范围内的目标数据库“执行”这些 SQL 表达式,并返回结果集。
- 对象关系映射器(英语:Object Relational Mapping,简称ORM),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。简单的说:ORM相当于中继数据。
提醒
本章节使用的SQLAlchemy版本为1.4(安装要求最低python3.6),所有的例子也都适用于1.4以上的版本,有一点要注意的就是1.4版本与1.3版本有较大改动,以下案例或许不能通用。
安装连接
执行下面命令安装 SQLAlchemy:
pip install SQLAlchemy输出 SQLAlchemy 的安装版本:
python
import sqlalchemy
print(sqlalchemy.__version__) # 输出:1.4.29任何 SQLAlchemy 程序开始都是有一个只为特定数据库服务器创建一个的名为 engine 的全局引擎对象,此对象会通过一个 URL 字符串(该字符串将描述如何连接到数据库主机或后端)进行配置连接到特定数据库的中心源。
python
from sqlalchemy import create_engine
# 创建一个引擎对象
engine = create_engine("mysql+pymysql://用户名:密码@IP:端口/数据库名称",
echo=True, # 注释:输出SQL执行过程,调试的时候更方便(可选)
future=True, # 注释:启用2.0版API(用于1.4及以上版本,可选)
max_overflow=10, # 注释:最大连接数(默认为5,可选)
pool_size=10, # 注释:连接池大小(可选)
pool_timeout=60, # 注释:池中没有线程最多等待的时间,否则报错(可选)
pool_recycle=7200 # 注释:限制多久没连接自动断开,默认为-1或没有超时(可选)
)建议
因为 SQLAlchemy 自带对象关系映射器,即 ORM 框架,由于框架自身维护了连接池,因此就不需要使用 DBUtils。默认情况下,SQLAlchemy 使用 QueuePool 类作为连接池类,可以在创建引擎对象时通过 pool_size 和 max_overflow 参数设置连接池的大小和溢出数量。
执行SQL
python
from sqlalchemy import create_engine, text
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/db_name")
# 从引擎对象中调用connect()方法获取一个连接对象
connect = engine.connect()
# conn.execute()方法执行文本SQL语句,text()方法编写文本SQL语句。
result_1 = connect.execute(text("SELECT 3*8"))
print(result_1.all()) # 输出:[(24,)]
# 使用冒号格式“变量名:变量”接受变量传递的参数
result_2 = connect.execute(text("SELECT 3*8 WHERE 5>:y"), {"y": 4})
print(result_2.all()) # 输出:[(24,)]
result_3 = connect.execute(text("SELECT 3*8 WHERE 5>:y"), {"y": 5})
print(result_2.all()) # 输出:[]
# 调用连接对象的close()方法将连接归还到引擎对象中,由引擎对象负责管理连接池。
connect.close()
# 获取一个连接对象,并使用上下文管理器限制其范围在特定上下文中。
with engine.connect() as connect:
# 建表语句
connect.execute(text("CREATE TABLE some_table (x int, y int)"))
# 插入语句
connect.execute(text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),[{"x": 1, "y": 1}, {"x": 2, "y": 4}, {"x": 6, "y": 8}, {"x": 9, "y": 10}])Result 有很多用于获取和转换行的方法,**例如,上面 Result.all() 方法一次性接受所有结果,它返回所有 Row 物体。**下面演示访问行的各种方法:
python
with engine.connect() as connect:
result = connect.execute(text("select x, y from some_table"))
# 元组赋值,即在接收到变量时将变量按位置分配给每一行。
for x, y in result:
print(f'x: {x}, y: {y}')
# 整数索引,元组是Python序列,因此也可以进行常规整数访问。
for row in result:
print(f'x: {row[0]}, y: {row[1]}')
# 属性名称,由于是Python命名的元组,这些元组具有与每个列的名称相匹配的动态属性名。
for row in result:
print(f"x: {row.x}, y: {row.y}")
# 映射访问,使用mappings()方法生成类似字典的RowMapping对象。
for row in result.mappings():
print(f"x: {row['x']}, y: {row['y']}")警告
SQLAlchemy的1.4.29版本已经没有 connect.commit() 方法来提交更改,都是 connect.execute() 边走边执行。
映射建表
Table类:创建基本结构 Table 表对象来对应操作的数据库表。
python
from sqlalchemy import Table
Table.__init__(self, name, metadata, *args, **kwargs)name数据库表名;metadata共享的元数据;*args用来定义列属性;**kwargs用来定义数据库表属性的可变参数,具体如下:schema表的结构名称,默认None;autoload自动从现有表中读入表结构,默认False;autoload_with从其他engine读取结构,默认None;include_columns如果autoload设置为True,则此项数组中的列明将被引用,没有写的列明将被忽略,None表示所有都列明都引用,默认None;mustexist如果为True,表示这个表必须在其他的python应用中定义,必须是metadata的一部分,默认False;useexisting如果为True,表示这个表必须被其他应用定义过,将忽略结构定义,默认False;owner表所有者,用于Orcal,默认None;quote设置为True,如果表明是SQL关键字,将强制转义,默认False;quote_schema设置为True,如果列明是SQL关键字,将强制转义,默认False;mysql_enginemysql专用,可以设置'InnoDB'或'MyISAM';
Column类:在上面的 Table 类中有一个 *args 参数是专门用来定义列的,及数据库表中的字段。
python
from sqlalchemy import Column
Column.__init__(self, name, type_, *args, **kwargs)name列名;type_列的类型;*args列的约束参数,具体如下:ForeignKey('列')列的外键;ColumnDefault默认;Sequenceobjects序列;key列的别名;
**kwargs列中的可变参数,具体如下:primary_key如果为True,则是主键;nullable是否可为Null,默认是True;default默认值,默认是None;index是否是索引,默认是True;unique是否唯一键,默认是False;onupdate指定一个更新时候的值,这个操作是定义在SQLAlchemy中,不是在数据库里的,当更新一条数据时设置,大部分用于updateTime这类字段;autoincrement设置为整型自动增长,只有没有默认值,并且是Integer类型,默认是True;quote如果列明是关键字,则强制转义,默认False;
**type类型:在 Column 类中 type_ 是专门定义列的类型的。**导入方式如下:
python
# 常用类型
from sqlalchemy import Integer, String
__all__ = ['TypeEngine', 'TypeDecorator', 'UserDefinedType', 'ExternalType', 'INT', 'CHAR', 'VARCHAR', 'NCHAR', 'NVARCHAR', 'TEXT', 'Text', 'FLOAT', 'NUMERIC', 'REAL', 'DECIMAL', 'TIMESTAMP', 'DATETIME', 'CLOB', 'BLOB', 'BINARY', 'VARBINARY', 'BOOLEAN', 'BIGINT', 'SMALLINT', 'INTEGER', 'DATE', 'TIME', 'TupleType', 'String', 'Integer', 'SmallInteger', 'BigInteger', 'Numeric', 'Float', 'DateTime', 'Date', 'Time', 'LargeBinary', 'Boolean', 'Unicode', 'Concatenable', 'UnicodeText', 'PickleType', 'Interval', 'Enum', 'Indexable', 'ARRAY', 'JSON']
# 不常用类型
from sqlalchemy.dialects.mysql import MEDIUMTEXT
__all__ = ('BIGINT', 'BINARY', 'BIT', 'BLOB', 'BOOLEAN', 'CHAR', 'DATE', 'DATETIME', 'DECIMAL', 'DOUBLE', 'ENUM', 'DECIMAL', 'FLOAT', 'INTEGER', 'INTEGER', 'JSON', 'LONGBLOB', 'LONGTEXT', 'MEDIUMBLOB', 'MEDIUMINT', 'MEDIUMTEXT', 'NCHAR', 'NVARCHAR', 'NUMERIC', 'SET', 'SMALLINT', 'REAL', 'TEXT', 'TIME', 'TIMESTAMP', 'TINYBLOB', 'TINYINT', 'TINYTEXT', 'VARBINARY', 'VARCHAR', 'YEAR', 'dialect', 'insert', 'Insert')前面提到首先需要创建基本结构 Table 表对象来对应操作的数据库表,即表的模型。 首先建立 user、address 表模型,模型可以在 ORM 持久性和查询操作中使用。内容如下:
python
# 导入工厂函数构造基类
from sqlalchemy.ext.declarative import declarative_base
# 导入数据类型和约束
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey, DateTime, text, Index, UniqueConstraint
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/db_name")
# declarative_base()是一个工厂函数,它为声明性类定义构造基类。
Base = declarative_base()
# Base作为我们声明的ORM映射类的基类。
class User(Base):
# user表
__tablename__ = 'user'
# id字段,整型,主键。
id = Column(Integer, primary_key=True)
# name字段,字符类型,长度不超过30。
name = Column(String(30))
# fullname字段,字符类型,长度不超过100,有唯一性。
fullname = Column(String(100), unique=True)
# company字段,字符类型,长度不超过128,默认值为'无'。注意,默认值必须是字符串,另外有些字段不支持默认值,例如,中文本MEDIUMTEXT、长文本LONGTEXT。
company = Column(String(128), server_default='无')
class Address(Base):
# address表
__tablename__ = 'address'
# id字段,整型,主键。
id = Column(Integer, primary_key=True)
# user_id字段,整型,关联外键user表id列,非空。
user_id = Column(Integer, ForeignKey('user.id'), nullable=False)
# email_address字段,字符型,长度不超过100,非空。
email_address = Column(String(100), nullable=False)
# update_time字段,日期时间类型,例如:2022-03-10 17:52:25,非空,在没有给出时间的情况下,设置默认值为当前时间。
update_time = Column(DateTime, nullable=False, server_default=text('CURRENT_TIMESTAMP'))
# 针对address表的设置的索引条件。注意,里面必须是字典、元组、空。
__table_args__ = (
# 创建一个名称为one的索引,字段包括"id"、"email_address"的索引,注意,有些字段不支持索引,例如:中文本MEDIUMTEXT、长文本LONGTEXT。
Index("one", "id", "email_address"),
# 创建一个名称为two的唯一索引,字段包括"user_id"、"email_address"的索引。
UniqueConstraint("user_id", "email_address", name="two")
)
# 使用映射类来安全创建上述所有表(操作会先判断表是否存在,存在不创建,否则创建)
Base.metadata.create_all(engine)
# 使用映射类来删除上述所有表
# Base.metadata.drop_all(engine)警告
在建立模型时,数据库表名称必须放在第一行。
操作对象
在最开始我们和数据库成功建立了连接,还进行了查询操作、建立了数据表,但这只是常规操作的一小部分,还有更新、插入等操作,但这些操作就比较特殊了,**因为查询、建表的操作要么成功要么失败,而更新、插入操作有可能成功一半后失败,因此我们需要一个原子性(Atomicity)的操作对象,这个对象执行一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。**具体代码如下:
python
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 引擎对象
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/new_origin_data")
# 通过sessionmake方法创建一个Session工厂
Session = sessionmaker(bind=engine)
# 调用工厂的方法来实例化一个原子性的session对象
session = Session()插入操作
python
'''
引入上面建表的User模型和原子性的session对象
'''
# 实例化对象
User1 = User(id=1001, name='ling', fullname="ling jing")
User2 = User(id=1002, name='molin', fullname="molin xi")
User3 = User(id=1003, name='karl', fullname="karl zhou")
# 添加单个对象添加到会话session
session.add(User1)
# 添加多个对象添加到会话session
session.add_all([User2, User3])
# 提交session对象操作
session.commit()
# 关闭session
session.close()查询操作
在 SQLAlchemy 中,数据库的查询操作是通过 Query 对象来实现的。Session 提供了创建 Query 对象的接口。Query 对象返回的结果是一组同一映射(Identity Map)对象组成的集合。所谓同一映射,是指每个对象有一个唯一的 ID,如果两个对象(的引用)ID 相同,则认为它们对应的是相同的对象。事实上,集合中的一个对象,对应于数据库表中的一行(即一条记录)。
查询操作格式:
session.query(映射类名).过滤条件(连接条件(判断条件1,判断条件2...)).返回形式映射类名:模型映射表的类名;
连接条件:
from sqlalchemy.sql.elements import and_, or_, not_过滤条件:
| 过滤条件 | 含义 |
|---|---|
filter(类.id==1001) | 筛选id为1001的数据 |
filter(类.id==None) | 筛选id为空的数据 |
filter(类.id!=1001) | 筛选id不为1001的数据 |
filter(类.name.like("%m%")) | 模糊查询name中有m字符的数据(区分大小写) |
filter(类.name.ilike("%m%")) | 模糊查询name中有m或M字符的数据(不区分大小写) |
filter(类.name.contains("m")) | 模糊查询name中有m字符的数据 |
filter(and_(类.id>=1001, 类.name.like("%m%"))) | 筛选id大于等于1001且name中有m字符的数据 |
filter(or_(类.id>=1001, 类.name.like("%m%"))) | 筛选id大于等于1001或name中有m字符的数据 |
filter(类.id.in_([1001, 1002])) | 筛选id等于1001或等于1002的数据 |
filter(类.id.notin_([1001, 1002])) | 筛选id不等于1001且不等于1002的数据 |
order_by(类.id) | 以id字段排序将数据升序输出 |
order_by(类.id.desc()) | 以id字段排序将数据降序输出 |
limit(3) | 返回最前面3条数据 |
- 返回形式:
| 返回形式 | 含义 |
|---|---|
one() | 当结果只有一个返回该结果,当结果不足一个或者多个时会报错。 |
first() | 当结果不足一个返回None,当结果只有一个返回该结果,当结果多个返回第一个结果。 |
all() | 以列表形式返回所有结果,当结果不足一个返回空列表。 |
count() | 返回查询结果的数量。 |
简单查询操作例子:
python
# filter方法可以像sql那样写where条件使用>、<等符号,但引用列名时,需要通过`类名.属性名`的方式,等号用==
user_1 = session.query(User).filter(User.id==1001).first()
print(user_1) # <__main__.User object at 0x000001F71E244508>
print(user_1.name) # ling
print(user_1.fullname) # ling jing
# filter_by方法的where条件不能使用>、<等符号,指定列名时,`参数名`即对应名类中的`属性名`,等号用=
user_2 = session.query(User).filter_by(id=1002).first()
print(user_2) # <__main__.User object at 0x000001F71E244D48>
print(user_2.name) # molin
print(user_2.fullname) # molin xi
'''
注释:可以看到查询出来的数据sqlalchemy直接给映射成一个对象了,这个对象和我们创建表时候的class是一致的,我们就也可以直接通过对象的属性就可以直接调用就可以了。
'''更新操作
更新操作就比较简单了,直接查询出来重新赋值就可以了。
python
user_1 = session.query(User).filter(User.id==1001).first()
print(user_1) # 输出:<__main__.User object...>
print(user_1.name) # 输出:ling
print(user_1.fullname) # 输出:ling jing
# 重新赋值
user_1.name = 'xiao'
user_1.fullname = 'xiao hong'
# 提交session操作
session.commit()
# 再次查询,信息已经被更新
user_1 = session.query(User).filter(User.id==1001).first()
print(user_1) # 输出:<__main__.User object...>
print(user_1.name) # 输出:xiao
print(user_1.fullname) # 输出:xiao hong
# 关闭session
session.close()删除操作
删除其实也是跟查询相关的,将查询操作的返回形式改为 delete() 方法就可以直接删除掉。
python
# 删除id为1001的数据
session.query(User).filter(User.id==1001).delete()
# 提交session操作
session.commit()
# 关闭session
session.close()reids-py库
redis-py 是一个用于 Python 的 Redis 客户端库,它提供了 Python 与 Redis 数据库进行通信的功能,并且允许你执行各种 Redis 操作,包括字符串、哈希、列表、集合等数据结构的操作,以及支持事务、发布/订阅等高级功能。
安装连接
**首先确保本地电脑安装了 Redis 以及 Python 3.6 及以上版本的环境,并且已经在本机的 6379 端口(默认)启动了 Redis 服务。**执行下面命令安装 redis-py 库:
pip install redis-py执行下面代码连接 Redis 数据库:
python
# 导入redis
from redis import StrictRedis
# StrictRedis对象,默认传入地址localhost、端口6379、选择0号数据库(不写默认0号)、密码为None。
client = StrictRedis(host='localhost', port=6379, db='0', password='None')提醒
redis-py 提供两个类 Redis 和 StrictRedis 来实现 Redis 的命令操作。StrictRedis 实现了绝大部分官方的命令,参数一一对应(官方推荐);而 Redis 是 StrictRedis 的子类,它的主要功能是用于向后兼容旧版本库里的几个方法。
常用类型
python
# 字符串string
client.set("hello","world") # 输出:True。注释:设置一个键值对{"hello":"world"}
print(client.get("hello")) # 输出:world。注释:获取"hello"键对应的值。
# 哈希hash
client.hset("myhash","f1","v1") # 注释:在myhash中设置一个键值对{"f1":"v1"}。
client.hset("myhash","f2","v2") # 注释:在myhash中设置一个键值对{"f2":"v2"}。
print(client.hgetall("myhash")) # 输出:{'f1':'v1', 'f2':'v2'}。注释:获取myhash中所有的键值对。
# 列表list
client.rpush("mylist","1") # 注释:从mylist列表右侧推入字符1。
client.rpush("mylist","2") # 注释:从mylist列表右侧推入字符2。
client.rpush("mylist","3") # 注释:从mylist列表右侧推入字符3。
print(client.lrange("mylist", 0, -1)) # 输出:['1', '2', '3']。注释:获取mylist列表中所有的元素。
# 集合set
client.sadd("myset","a") # 注释:在myset集合中添加字符a。
client.sadd("myset","b") # 注释:在myset集合中添加字符b。
client.sadd("myset","a") # 注释:在myset集合中添加字符a。
print(client.smembers("myset")) # 输出:set(['a', 'b'])。注释:输出myset集合中所有的元素成员。
# 有序集合zset
client.zadd("myzset","99","tom") # 注释:在myzset集合中添加成员('tom', 99.0)。
client.zadd("myzset","66","peter") # 注释:在myzset集合中添加成员('peter', 66.0)。
client.zadd("myzset","33","james") # 注释:在myzset集合中添加成员('james', 33.0)。
print(client.zrange("myzset", 0, -1, withscores=True)) # 输出:[('james', 33.0), ('peter', 66.0), ('tom', 99.0)]。注释:输出myzset集合中所有的元素成员。命令管道
Redis 客户端执行一条命令分为如下四个过程: 其中过程 1 和过程 4 称为 Round Trip Time(RTT,往返时间)。

要执行 n 条命令,需要消耗 n 次 RTT:
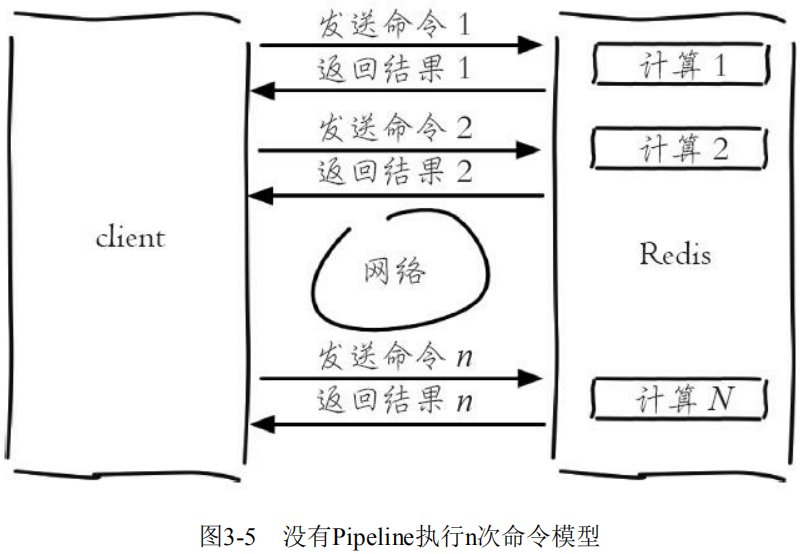
即使 Redis 处理能力很强,如果受到网络传输影响,吞吐量仍然会上不去。**Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis 命令进行组装,通过一次 RTT 传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端,多个请求可以变成只需要 2 次交互。**这样网络传输上能够更加高效,加上 Redis 本身强劲的处理能力,给数据处理带来极大的性能提升。
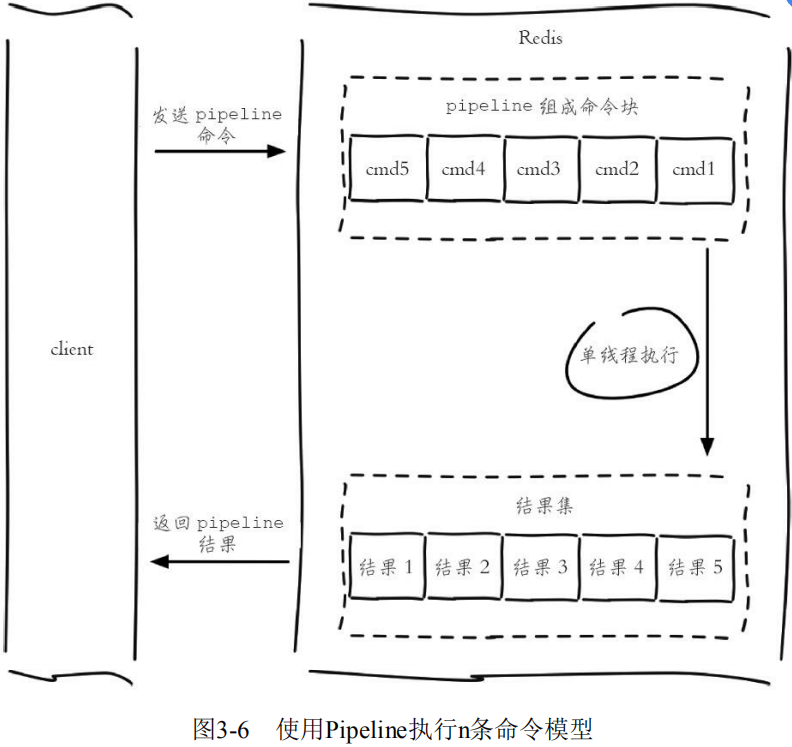
在不同网络环境下非 Pipeline 和 Pipeline 执行10000次 set 操作的效果,可以得到如下两个结论:
- Pipeline执行速度一般比逐条执行要快。
- 客户端和服务端的网络延时越大,Pipeline的效果越明显。

**redis-py 支持 Redis 的 Pipeline 功能,可以用来批量执行多个 Redis 命令,从而减少与 Redis 服务器的通信次数,提高性能。**目前 Redis 提供了 mset 批量添加键、mget 批量获取值的方法,但没有提供 mdel 批量删除键的方法,如果想实现,可以借助 Pipeline 实现:
python
import redis
# 生成连接
client = redis.StrictRedis(host='localhost', port=6379)
# 使用with可以确保Pipeline管道在使用完后会被正确地清理资源,transaction=True代表使用事务
with client.pipeline(transaction=True) as pipeline:
for key in keys:
# 将删除命令封装到Pipeline中,此时命令并没有真正执行
pipeline.delete(key)
'''
注释:这里使用了事务,在退出with语句块时,需要批量执行的多个命令会作为一个事务一起提交到Redis服务器。而且事务中的命令在执行过程中是原子性的,要么全部成功执行,要么全部失败,不会存在部分执行成功、部分执行失败的情况。
'''警告
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline命令量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。
pymongo库
pymongo 是一个专门用于连接 MongoDB 数据库的第三方库。
安装连接
**首先确保电脑中安装了 MongoDB,并且已经在本机的 27017 端口(默认)启动了 MongoDB 服务。**执行下面命令安装 pymongo 库:
pip install pymongo连接数据库:
python
# 导入pymongo
from pymongo import MongoClient
# 连接本地的MongoDB数据库
client = MongoClient()
# 连接其他机器的MongoDB数据库
client = MongoClient('mongodb://主机IP:27017')
client = MongoClient(host='主机IP', port=27017)
# 连接对象,假设要连接的数据库名为:primer
db = client.primer
db = client['primer']
# 操作游标,连接到对应的数据表
coll = db.dataset
coll = db['dataset']插入数据
python
# 插入数据
coll.insert(document)
# 插⼊一条数据
coll.insert_one(document)
# 插入多条数据
coll.insert_many(documents, ordered=True)
# 插入一条字典类型数据:students集合,新建一条学生数据,这条数据以字典形式表示:
student = { 'id':'20170101',
'name':'Jordan',
'age', 20,
'gender':'male'}
# 执行插入数据方法
result = coll.insert(student)
# 在MongoDB中,每条数据都有一个_id 属性来唯一标识。如果没有显式指明该属性,MongoDB会自动产生一个ObjectId类型的_id属性。insert()方法会在执行后返回_id值。
print(result) # 输出:932a68615c2606814c91f3d查询数据
python
# find:查询出来的是一个列表集合
# 查询所有数据
cursor = coll.find()
# 查询字段是最上层的
cursor = coll.find({"borough": "Manhattan"})
# 查询字段在内层嵌套中
cursor = coll.find({"address.zipcode": "10075"})
# 查询得分大于30的数据
cursor = coll.find({"grades.score": {"$gt": 30}})
# 查询得分小于10的数据
cursor = coll.find({"grades.score": {"$lt": 10}})
# and条件查询,find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
cursor = coll.find({"cuisine": "Italian", "address.zipcode": "10075"})
# or条件查询
cursor = coll.find({"$or": [{"cuisine": "Italian"}, {"address.zipcode": "10075"}]})
# find_one:查找一条数据,返回的是一个JSON式文档,所以可以直接使用!
# sort排序使用的列表,当排序的标准只有一个,且是递增时,可以直接写在函数参数中:
# 升序
pymongo.ASCENDING = 1
# 升序排列
cursor = coll.find().sort(“borough”)
# 降序
pymongo.DESCENDING = -1
# 降序排列
cursor = coll.find().sort([(“borough”, pymongo.ASCENDING),(“address.zipcode”, pymongo.DESCENDING)])修改数据
python
# 更新⽂档的函数有三个(不能更新_id字段)
# 更新匹配的第一条数据
update_one(filter, update, upsert=False)
# 更新匹配的每一条数据
update_many(filter, update, upsert=False)
# 替换匹配的第一条数据
replace_one(filter, replacement, upsert=False)
# 查找并更新匹配的第一条数据
find_one_and_update(filter, update, projection=None, sort=None,
return_document=ReturnDocument.BEFORE, **kwargs)删除数据
python
# 删除⼀个
result = coll.delete_one({'x': 1})
# 删除多个
result = coll.delete_many({"borough": "Manhattan"})
# 删除全部
result = coll.delete_many({})
# 删除整个集合,是drop_collection()的别名
coll.drop()