列表、字典、集合、元组
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
在前面我们学习了 Python 语言中 4 种基本数据类型,包括整数类型(int)、浮点类型(float)、字符串类型(str)、布尔类型(bool),这里我们还要再介绍 4 种基本数据类型,分别是列表(list)、字典(dict)、集合(set)、元组(tuple)。
列表(list)
在 Python 中,列表是一个常用的有序数据容器类型,用 list 表示。
- 列表可以存储多个任意类型的数据,相互之间用英文逗号
,隔开,当中的数据被称为“元素”,而没有元素的空列表用[]表示。
python
# 列表(list):[数据1, 数据2, 数据3...]
[1234, 56.78, 'WASD', True] [] # 空列表
print(type([])) # 输出:list
print(isinstance([], list)) # 输出:True
print(type([1234, 56.78, 'WASD', True])) # 输出:list
print(isinstance([1234, 56.78, 'WASD', True], list)) # 输出:True- 列表的数据结构是基于数组建立的,因此可以通过下标索引访问元素。
- 列表里面元素的值是可变,因此在列表里面可以计算。
- 列表里面元素的个数是可变,里面增加或删除元素都会改变该元素后面其他元素的下标位置,并改变列表长度。
- 列表可以通过比较运算符来按下标依次比较大小关系。
python
print([1, 2, 3] > [1, 2]) # 输出:True
print([1, 2, 3] >= [1, 2]) # 输出:True
print([1, 2, 3] >= [1, 4]) # 输出:False。注释:按下标比较 2 < 4 所以结果False。
print([1, 2, 3] >= [1, 2, 3]) # 输出:True
print([1, 2, 3] == [1, 2, 3]) # 输出:True
print([1, 2, 3] <= [1, 2, 3]) # 输出:True
print([1, 2, 3] < [1, 2]) # 输出:False
print([1, 2, 3] <= [1, 2]) # 输出:False
print([1, 2, 3] <= [1, 4]) # 输出:True。列表创建
在 Python 中来创建一个列表有两种常用方式,具体如下:
- 自定创建:通过
[]来直接定义一个列表,在里面写入列表包含的元素。
python
print([]) # 输出:[]。注释:创建一个空列表。
print(['i', 'o']) # 输出:['i', 'o']。注释:创建一个包含字母i、o的列表。
print([1, 2, 3, 4]) # 输出:[1, 2, 3, 4]。注释:创建一个包含数字1、2、3、4的列表。- 迭代创建:通过内置的
list(可迭代对象)函数,遍历可迭代对象来创建一个列表。
python
print(list()) # 输出:[]。注释:可迭代对象为空,因此创建了一个空列表。
print(list('abc')) # 输出:['a', 'b', 'c']。注释:遍历'abc'字符串,创建了一个只包含字符元素的列表。
print(list(range(3))) # 输出:[0, 1, 2]。注释:遍历range(3)对象,创建了一个0~2范围的列表。列表操作
前后拼接:列表和字符串一样,通过 + 符号将两个列表拼接成一个列表。
python
print(['通天箓'] + ['风后奇门', '阿威十八式']) # 输出:['通天箓', '风后奇门', '阿威十八式']
print(['风后奇门', '阿威十八式'] + ['通天箓']) # 输出:['风后奇门', '阿威十八式', '通天箓']重复输出:列表和字符串一样,通过 * 符号,将数据指定倍数的重复输出。
python
print([1, 2] * 3) # 输出:[1, 2, 1, 2, 1, 2]下标选择:列表和字符串一样,每个元素都有一个对应的位置下标,这里不再赘述。
python
print(['路飞', '佐罗', '娜美', '鸣人', '佐助'][2]) # 输出:娜美
print(['路飞', '佐罗', '娜美', '鸣人', '佐助'][-3]) # 输出:娜美
print(['路飞', '佐罗', '娜美', '鸣人', '佐助'][5]) # 报错:下标索引超界。改变元素:通过 列表[下标] = 新元素 修改指定下标的元素,注意下标不能越界。
python
names = ['周', '张', '刘', '黄', '杨']
names[4] = '陈' # 注释:将names下标为4的元素重新赋值为'陈'
print(names) # 输出:['周', '张', '刘', '黄', '陈']切片操作:列表和字符串的切片操作一样,唯独不一样的是,字符串切片结果是新的字符串对象,而列表切片结果是一个新的列表对象。
列表[起始下标:结束下标]起始下标和结束下标是前闭后开,获取从起始下标到结束下标前的所有的元素,不能取到结束下标的元素。
python
print(['鸣人', '佐助', '小樱'][0:2]) # 输出:['鸣人', '佐助']
print(['鸣人', '佐助', '小樱'][1:3]) # 输出:['佐助', '小樱']列表[:]起始下标和结束下标都可以不写,默认为全列表。
python
print(['鸣人', '佐助', '小樱'][:]) # 输出:['鸣人', '佐助', '小樱']
print(['鸣人', '佐助', '小樱'][1:]) # 输出:['佐助', '小樱']
print(['鸣人', '佐助', '小樱'][:1]) # 输出:['鸣人']列表[起始下标:结束下标:步长]从起始下标开始,下标值加步长获取下一个元素,直到结束下标前为止。
python
print(['鸣人', '佐助', '小樱'][0:3:2]) # 输出:['鸣人', '小樱']
print(['鸣人', '佐助', '小樱'][::-1]) # 输出:['小樱', '佐助', '鸣人']- 起始下标和结束结束下标都超界,不会报错,会返回空列表。
python
print(['鸣人', '佐助', '小樱'][10:]) # 输出:[]删除列表:通过 del 列表 删除指定的整个列表,注意列表必须先存在才能删除。
删除元素:通过 ``del 列表[下标] 删除列表中指定下标位置的元素,注意下标不能越界。
python
films = ['肖', '阿', '摔', '逃', '赌', '英']
del films[1] # 注释:删除films列表中下标为1的元素
print(films) # 输出:['肖', '摔', '逃', '赌', '英']
del films # 注释:删除films列表
print(films) # 报错:films未定义列表方法
列表.append(元素) 方法:在原列表的末尾添加一个元素。
python
skills = []
skills.append('气') # 注释:在列表末尾插入元素'气'
print(skills) # 输出['气']
skills.append('拘') # 注释:在列表末尾插入元素'拘'
print(skills) # 输出:['气', '拘']列表.insert(下标, 元素) 方法:在原列表指定的下标位置前面插入一个元素,若下标越界,元素会插入到列表最后面。需要注意的是列表在底层采用的是“顺序存储”,在指定位置插入元素,也就需要把列表中指定位置后面的所有元素全部往后移动一个位置,再将元素添加进去,如果说列表比较大时,移动的元素越多,该方法的效率就会越低。
python
skills = ['气', '拘']
skills.insert(1, '通') # 注释:下标为1的元素'拘'前面插入元素'通'
print(skills) # 输出:['气', '通', '拘']
skills.insert(-1, '天') # 注释:下标为-1的元素'拘'前面插入元素'天'
print(skills) # 输出:['气', '通', '天', '拘']
skills.insert(10, '箓') # 注释:下标10超过列表长度,因此元素'箓'插入到列表最后面
print(skills) # 输出:['气', '通', '天', '拘', '箓']
skills.insert(0, '山') # 注释:下标为0的元素'气'前面插入元素'山'
print(skills) # 输出:['山', '气', '通', '天', '拘', '箓']列表.extend(可迭代对象) 方法:将可迭代对象中的每一个元素添加到原列表中。
python
names = ['周', '张']
names.extend('20') # 注释:'20'是可迭代对象
print(names) # 输出:['周', '张', '2', '0']
names.extend(['20']) # 注释:['20']是可迭代对象
print(names) # 输出:['周', '张', '2', '0', '20']列表.pop(下标) 方法:弹出并返回指定下标的元素,若没有下标取,则默认最后一个元素,注意下标不能越界。
python
films = ['摔跤吧爸爸', '逃学威龙', '英雄本色']
film = films.pop()
print(films) # 输出:['摔跤吧爸爸', '逃学威龙']
print(film) # 输出:英雄本色
film = films.pop(1) # 注释:由于上面已经取出一个元素,films发生变化。
print(films) # 输出:['摔跤吧爸爸']
print(film) # 输出:逃学威龙列表.remove(元素) 方法:从列表中移除指定元素,若存在多个相同指定元素,则只删除最前面的那一个;若删除的元素不在列表中,则会报错。
python
films = ['摔跤吧爸爸', '逃学威龙', '逃学威龙', '英雄本色']
films.remove('逃学威龙')
print(films) # 输出:['摔跤吧爸爸', '逃学威龙', '英雄本色']列表.index(元素, 开始, 结束) 方法:在列表的指定范围内获取指定元素的下标,范围是开始下标到结束下标,前闭后开。如果范围内不存在指定元素,则返回 ValueError 错误;如果范围中存在多个指定元素,则返回第一个指定元素的下标。
python
names = ['周', '张', '张', '刘', '张', '黄', '陈', '张']
print(names.index('李')) # 报错:'李'元素不在列表当中。
print(names.index('张')) # 输出:1。注释:虽然'张'元素在names列表中存在多个,但只返回第一个'张'元素的下标。
print(names.index('张', 1)) # 输出:1。注释:虽然'张'元素在[1:)列表范围中存在多个,但只返回第一个'张'元素的下标。
print(names.index('张', 2, -1)) # 输出:2。注释:虽然'张'元素在[2:-1)列表范围中存在多个,但只返回第一个'张'元素的下标。
print(names.index('张', 3, -1)) # 输出:4。注释:'张'元素在[3:-1)列表范围只存在一个,返回他的下标。
print(names.index('张', 5, -1)) # 报错:范围区间[5:-1)是前闭后开,'张'元素不在范围当中。列表.count(元素) 方法:获取指定元素在列表中出现的次数。
python
names = ['周', '张', '张', '刘', '张', '黄', '陈', '张']
print(names.count('张')) # 输出:4列表.reverse() 方法:在原列表的基础之上反向列表中的元素,注意此过程不会产生新的列表。
python
numbers = [1, 2, 3, 4]
numbers.reverse()
print(numbers) # 输出:[4, 3, 2, 1]列表.sort() 方法:在原列表的基础之上对列表进行排序,默认升序,添加参数 reverse=True 则为降序,注意此过程不会产生新的列表。
python
numbers = ['1', '42', '45', '6', '90']
numbers.sort() # 注释:默认升序
print(numbers) # 输出:['1', '42', '45', '6', '90']
numbers.sort(reverse=True) # 注释:排序为降序
print(numbers) # 输出:['90', '6', '45', '42', '1']
numbers.sort(key=int) # 注释:将字符型转为整型排序,结果仍是字符型
print(numbers) # 输出:['1', '6', '42', '45', '90']列表.copy() 方法:将原列表中的元素全部拷贝一份到新的列表。
python
names = ['张三', '李四']
# 注释:new_names1 = name[:] 效果也一样
new_names1 = names.copy()
print(new_names1) # 输出:['张三', '李四']列表.clear() 方法:清空列表中的所有元素。
python
numbers = [5, 'last']
# 注释:number = [] 效果也一样
numbers.clear()
print(numbers) # 输出[]列表迭代
列表也属于可迭代对象(Iterable),因此也是可以直接用于 for 循环的对象,前面讲到的可迭代对象函数也适用于列表。
python
from collections.abc import Iterable
print(isinstance([1234, 56.78, 'WASD', True], Iterable)) # 输出:True
# 通过循环来遍历列表中的元素
for item in [1234, 56.78, 'WASD', True]:
print(item, end=' ') # 输出:1234 56.78 WASD True
# in/not in:判断指定的元素是否在指定的列表中,结果是布尔值。
print('高' not in ['周', '张', '刘']) # 输出:True
# len(列表):获取列表长度。
print(len([12, '67', ['21', '51']])) # 输出:3。注释:对于列表里面的列表,无论包含多少元素,占用的长度都为1。
# max/min函数:获取列表中最大或最小的元素。
print(max(['a', 'hj', 'u', 'z'])) # 输出:z
print(min([1, 45, 89, 0, -1, 8])) # 输出:-1
# max/min函数添加'key=列表.count'参数:获得列表中出现频率最高或最低的元素。
a = [3, 3, 4, 2]
print(max(a, key=a.count)) # 输出:3。注释:3出现频率最高
print(min(a, key=a.count)) # 输出:4。注释:4、2出现频率都最低,但4的索引更靠前。
# sum(可迭代对象):返回可迭代对象中的数值之和,注意可迭代对象里面的元素必须全是整型或浮点型。
print(sum([1, 23, -7, -1])) # 输出:16列表推导式
列表可以和 for 循环、range 函数 、if 判断、三元表达式、逻辑运算符进行结合形成列表推导式。
python
# 在列表中通过for循环遍历字符串'12345'
list1 = [i for i in '12345']
print(list1) # 输出:['1', '2', '3', '4', '5']
# 在列表中通过for循环和range函数产生0~4的元素
list2 = [i for i in range(5)]
print(list2) # 输出:[0, 1, 2, 3, 4]
# 在列表中通过for循环和range函数产生0~4的元素,再将每个元素乘以2
list3 = [i * 2 for i in range(5)]
print(list3) # 输出:[0, 2, 4, 6, 8]
# 在列表中通过for循环和range函数产生0~4的元素,通过if判断将大于2的元素值乘以5
list4 = [i * 5 for i in range(5) if i > 2]
print(list4) # 输出:[15, 20]
# 在列表中通过for循环和range函数产生0~4的元素,通过if判断将大于2的元素值乘以5,小于2的元素值乘于3
list5 = [i * 5 if i > 2 else i * 3 for i in range(5)]
print(list5) # 输出:[0, 3, 6, 15, 20]
# 两个列表中的元素两两相加,两两组合,两两字符相加
one = [1, 2]
two = [3, 4]
print([o + t for o in one for t in two]) # 输出:[4, 5, 5, 6]
print([[o, t] for o in one for t in two]) # 输出:[[1, 3], [1, 4], [2, 3], [2, 4]]
print([f'{o}{t}' for o in one for t in two]) # 输出:['13', '14', '23', '24']
# words词汇,text文本
words = ['新冠', '公正', '高考']
text = '重点关注新冠密接检测结果'
# 在列表中通过for循环和三元表达式来筛选哪些词语出现在text文本当中
result = [word if word in text else '' for word in words]
print(result) # 输出:['新冠', '', '']
# 在列表中通过for循环和三元表达式来筛选词语结合逻辑运算符any判断是否有词语出现在text文本当中
result = any([word if word in text else '' for word in words])
print(result) # 输出:True提醒
列表推导式不仅写法简明,而且效率还高,因为 Python 里面有专门的指令来支持列表推导式,而使用 .append() 方法添加元素会涉及到函数调用,速度会更慢一些。
字典(dict)
在 Python 中,字典是一个常用的无序数据容器类型,用 dict 表示。
- 字典是以键值对(
{key:value},key为键,:分隔符,value为值)的形式存储多个任意类型的数据,相互之间用英文逗号,隔开,当中的数据被称为“元素”,而没有元素的空字典用{}表示。
python
# 字典(dict):{key1: value1, key2: value2, key3: value3...}
{'user': 'root', 'password': '123456'} {} # 空字典
print(type({'user': 'root', 'password': '123456'})) # 输出:dict
print(isinstance({'user': 'root', 'password': '123456'}, dict)) # 输出:True- 键值对中的键(
key)必须是可哈希的数据类型,一般使用字符串作为整个字典中的唯一的键,若键在字典中不唯一,则以最后一个相同键的值为准。 - 键值对中的值(
value)可以是任何类型的数据。 - 键值对中的键(
key)和值(value)是一对一存在的,删除了键,就相当于删除了整个键值对。 - 字典在被迭代的过程中不能改变长度,也就是说字典在被迭代的过程中不能进行“增删”操作,否则会报错。
- 字典中的数据在内存中并不是连续存储的,而是依赖于底层结构的哈希表,因此字典是不能使用下标来定位数据的,而是通过
key来定位数据。 - 字典中的键值对在 Python 3.6 之前是无序的,即每次输出键值对的顺序不固定。但从 Python 3.7 开始,字典在语言规范中开始保持键值对插入时的顺序,Python 3.8 之后这个行为已经被正式作为语言规范。
- 字典的内存分配规则是,先预分配一块内存区,当元素添加到一定阈值时进行扩容再分配一块比较大的内存区。由此可见使用字典时,内存会给字典预留比较大的空间,如果字典只存储极少量的数据,则会存在比较大的内存浪费。
字典创建
在 Python 中来创建一个字典有两种常用方式,具体如下:
- 自定创建:通过
{}来直接定义一个字典,在里面写入键和值。
python
print({}) # 输出:{}。注释:定义一个空字典。
print({1: 2, '3': 4}) # 输出:{1: 2, '3': 4}。注释:定义一个有2个键值对的字典。- 迭代创建:
dict.fromkeys(可迭代对象, value)创建一个新的字典,可迭代对象中的元素作为键,参数作为值。
python
new_dict1 = dict.fromkeys('abc', '100')
print(new_dict1) # 输出:{'a': '100', 'b': '100', 'c': '100'}
new_dict2 = dict.fromkeys(['abc', 'dcc', '123'], '100')
print(new_dict2) # 输出:{'abc': '100', 'dcc': '100', '123': '100'}
new_dict3 = dict.fromkeys(range(4), '100')
print(new_dict3) # 输出:{0: '100', 1: '100', 2: '100', 3: '100'}字典操作
获取键值:通过 字典[key] 来获取字典中指定键所对应的值,如果键不存在会报错。
python
student = {'name': '张三', 'score': {'english': 60, 'math': 100}}
print(student['name']) # 输出:张三
print(student['score']) # 输出:{'english': 60, 'math': 100}
print(student['score']['english']) # 输出:60
print(student['score']['math']) # 输出:100
print(student['score']['history']) # 报错:在'score'键中不存在'history'键。修改键值:通过 字典[key] = value 来获取字典中指定键所对应的值。若字典中不存在指定的键,则形成新的键值对添加到字典中;若字典中存在对应的键,则修改字典中的指定键所对应的值。
python
student = {'name': '张三'}
student['age'] = 18 # 注释:student字典中不存在'age'键,这里添加了{'age': 18}键值对。
print(student) # 输出:{'name': '张三', 'age': 18}
student['age'] = 20 # 注释:student字典中已存在'age'键,这里将'age'键的对应值从18修改为了20。
print(student) # 输出:{'name': '张三', 'age': 20}
# 统计列表中每个元素出现的次数
a = ['apple', 'banana', 'apple', 'tomato', 'apple', 'banana']
b = {}
for i in a:
b[i] = b.get(i, 0) + 1
print(b) # 输出:{'apple': 3, 'banana': 2, 'tomato': 1}删除键值:通过 del 字典[key] 来删除字典中指定的键值对,注意删除字典中不存在的键值对会报错。
删除字典:通过 del 字典 来删除指定的整个字典,注意字典必须先存在才能被删除。
python
person = {'name': '路飞', 'age': 17, 'face': 90}
del person['aaa'] # 报错:删除person字典不存在的键'aaa',报错KeyError。
del person['face'] # 注释:删除person字典存在的键'face'。
print(person) # 输出:{'name': '路飞', 'age': 17}
del person # 注释:删除person字典。
print(person) # 报错:person字典已被删除,现在person是未定义状态。字典方法
字典.get(key, 自定义值) 方法:获取字典中指定键所对应的值,如果键不存在返回自定义值,若无自定义值则返回 None 。
python
student = {'name': '张三', 'score': {'english': 60, 'math': 100}}
print(student.get('name')) # 输出:张三
print(student.get('score')) # 输出:{'english': 60, 'math': 100}
print(student.get('score').get('english')) # 输出:60
print(student.get('score').get('math')) # 输出:100
print(student.get('score').get('history')) # 输出:None。注释:在'score'键中不存在'history'键,返回默认值None。
print(student.get('score').get('history', 'Error')) # 输出:Error。注释:在'score'键中不存在'history'键,返回自定义Error。字典1.update(字典2) 方法:使用 字典2 中的键值对更新 字典1 中的键值对,若 字典2 中存在 字典1 中有的键,就更新该键值对;若 字典2 中存在 字典1 中没有的键,就添加该键值对(注意此过程不会产生新的字典)。
python
dict1 = {'1': 'a', '2': 'b'}
dict2 = {'1': 'aaa', '3': 'c'}
dict1.update(dict2) # 注释:dict2和dict1都有'1'键,因此对dict1中的'1'键进行更新,但'3'键只有dict2中才有,因此就对dict1进行添加。
print(dict1) # 输出:{'1': 'aaa', '2': 'b', '3': 'c'}字典.pop(key) 方法:通过指定键从字典中取出键值对,被取出的键值对就不会再出现在原字典当中了。如果指定键不在字典当中,取键值对就会报错,但可以通过设定默认返回值来避免报错,当指定键不在字典当中是,取键值对就会返回默认返回值。
python
person = {'name': '路飞', 'age': 18}
print(person.pop('age')) # 输出:18。注释:从person字典中取出'age'键值对,返回'age'键对应的值。
print(person) # 输出:{'name': '路飞'}。注释:'age'键值对被取出,因此不会出现在person字典中了。
print(person.pop('num')) # 报错:字典中不存在num的键值对。
print(person.pop('num', None)) # 输出:None。注释:字典中不存在num的键值对,返回默认返回值‘None’。字典.clear() 方法:清空字典。
python
person = {'name': '路飞', 'age': 18, 'face': 90}
# 注释:效果和person = {}相同
person.clear()
print(person) # 输出:{}。注释:空字典。字典视图
Python 提供了 字典.keys()、字典.values() 和 字典.items() 这三个将字典转换为视图对象的方法,其返回的结果都是可迭代的视图对象(view objects)。由于视图对象是只读的,因此我们不能对其进行任何的修改,而且也不支持索引操作。但视图对象是可迭代对象,我们可以使用内置的 list 函数将其转换为列表再进行操作。
python
student = {'name': '张三', 'score': {'english': 60, 'math': 100}}
# 获取字典中所有的key
print(list(student.keys())) # 输出:['name', 'score']
# 获取字典中所有的value
print(list(student.values())) # 输出:['张三', {'english': 60, 'math': 100}]
# 获取字典所有的key、value
print(list(student.items())) # 输出:[('name', '张三'), ('score', {'english': 60, 'math': 100})]字典迭代
字典也属于可迭代对象(Iterable),因此可以直接用于 for 循环的对象,前面讲到的可迭代对象函数也适用于字典。
python
from collections.abc import Iterable
print(isinstance({'name': '张三', 'score': {'math': 100, 'english': 60}}, Iterable)) # 输出:True
# 通过for循环遍历字典可以得到里面所有的键
student_dict = {'name': '张三', 'score': {'math': 100, 'english': 60}}
for key in student_dict:
print(key, student_dict[key])
'''
输出:
name 张三
score {'english': 60, 'math': 100}
'''
# in/not in:判断字典中是否存在指定的键。
print('user' in {'user': 'root', 'password': '123456'}) # 输出:True。注释:字典中存在'user'键。
print('root' in {'user': 'root', 'password': '123456'}) # 输出:False。注释:字典中不存在'root'键。
# len(可迭代对象)函数:返回可迭代对象的长度。
print(len({'x': 3, 'y': 2.0, 'z': ['1', '0']})) # 输出:3。注释:返回字典中键值对的个数。
print(len({'name': '张三', 'score': {'math': 100, 'english': 60}})) # 输出:2。注释:返回字典中第一层键值对的个数,忽略嵌套键值对。
# max(可迭代对象)/min(可迭代对象):获取可迭代对象中最大/最小的元素。
prices = {
'apple': 191,
'goog': 1186,
'ibm': 149,
'orcl': 48,
'acn': 166,
'fb': 208,
'symc': 21
}
print(min(prices.keys())) # 输出:acn。注释:获取字典中最小的键。
print(min(prices.values())) # 输出:21。注释:获取字典中最小的值。
print(min(prices, key=prices.get)) # 输出:symc。注释:获取字典中最小的值所对应的键。参数key代表对比规则,prices.get即每组键值对的值。
print(min(prices, key=len)) # 输出:fb。注释:获取字典中长度最小的键。参数key代表对比规则,len即每组键值对中键的长度。
print(max(prices.keys())) # 输出:symc。注释:获取字典中最大的键。
print(max(prices.values())) # 输出:1186。注释:获取字典中最大的值。
print(max(prices, key=prices.get)) # 输出:goog。注释:获取字典中最大的值所对应的键。参数key代表对比规则,prices.get即每组键值对的值。需要注意的是,当字典对象本身在迭代过程中时,不能被改变长度。也就是说涉及改变字典长度的方法在迭代过程中都不能使用。
python
temp_dict = {'1': 1, '2': 2, '3': 3}
# 字典对象本身在循环过程中
for ip_port in temp_dict:
del temp_dict[ip_port] # 报错:dictionary changed size during iteration在迭代过程中字典的长度发生改变。
print(temp_dict, end=', ')要解决这个问题也很简单,可以通过 .cpoy() 方法拷贝出一个新的有相同元素的字典,或者通过 list() 方法返回一个新的列表对象。
python
temp_dict = {'1': 1, '2': 2, '3': 3}
# 拷贝出一个新的有相同元素的字典
for ip_port in temp_dict.copy():
del temp_dict[ip_port]
print(temp_dict, end=', ') # 输出:{'2': 2, '3': 3}, {'3': 3}, {}
temp_dict = {'1': 1, '2': 2, '3': 3}
# 返回一个新的列表对象
for ip_port in list(temp_dict):
del temp_dict[ip_port]
print(temp_dict, end=', ') # 输出:{'2': 2, '3': 3}, {'3': 3}, {}字典推导式
套用上面列表推导式的原理,我们还可以写出字典推导式:
python
dict1 = {i:i for i in '12345' if i != '1'}
print(dict1, type(dict1)) # 输出:{'2': '2', '3': '3', '4': '4', '5': '5'} <class 'dict'>集合(set)
在 Python 中,集合是一个常用的数据容器类型,用 set 表示。
- 集合可以存储多个可哈希类型的数据,相互之间用英文逗号
,隔开,当中的数据被称为“元素”,没有元素的空集合用set()表示,注意{}只能用来表示空字典的。
python
# 集合(set):{数据1, 数据2, 数据3...}
{1234, 56.78, 'WASD', True} set() # 空集合
print(type({'user', 'root'})) # 输出:set
print(isinstance({'user', 'root'}, set)) # 输出:True- 集合自带去重功能,每个元素都具有唯一性。
python
set1 = {1, 2, 3, 2, 3}
print(set1) # 输出:{1, 2, 3}。注释:集合自带去重功能。- 集合中元素的位置是无序的,因此不能使用下标定位元素。
- 集合中的元素无法通过索引来访问,因此也无法使用索引修改元素。
- 集合可以通过比较运算符来确定包含关系。
python
print({1, 2, 3} > {1, 2}) # 输出:True
print({1, 2, 3} >= {1, 2}) # 输出:True
print({1, 2, 3} >= {1, 4}) # 输出:False
print({1, 2, 3} >= {1, 2, 3}) # 输出:True
print({1, 2, 3} == {1, 2, 3}) # 输出:True
print({1, 2, 3} <= {1, 2, 3}) # 输出:True
print({1, 2, 3} < {1, 2}) # 输出:False
print({1, 2, 3} <= {1, 2}) # 输出:False
print({1, 2, 3} <= {1, 4}) # 输出:False集合创建
在 Python 中来创建一个集合有两种常用方式,具体如下:
- 自定创建:通过
{}在里面写入元素来直接定义一个集合。
python
print({1, 2, '3', 4}) # 输出:{1, 2, 4, '3'}。注释:定义一个有4个元素的集合。- 迭代创建:通过内置的
set(可迭代对象)函数,遍历可迭代对象来创建一个集合。
python
print(set()) # 输出:set()。注释:使用set()创建一个空的集合。
print(set('abc')) # 输出:{'a', 'c', 'b'}。注释:遍历'abc'字符串,创建了一个只包含字符元素的集合。
print(set(range(3))) # 输出:{0, 1, 2}。注释:遍历range(3)对象,创建了一个0~2范围的集合。重要
需要记住的是,创建一个空集合必须用 set() 而不是 {},因为 {} 是用来创建一个空字典。
集合操作
集合可以进行数学集合相关的操作:交集、对称差、并集、差集。
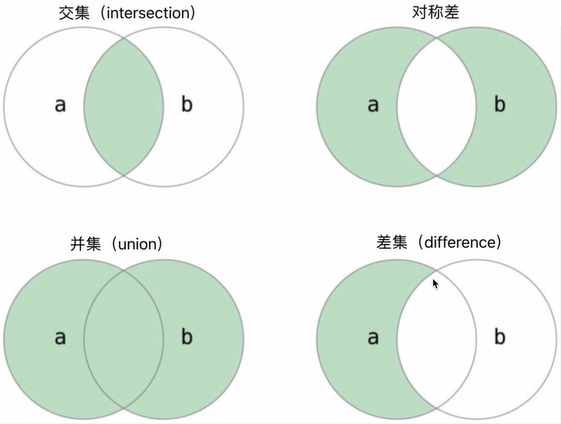
python
# 交集 &
print({1, 2, 3} & {2, 3, 4, 5}) # 输出:{2, 3}
# 对称差 ^
print({1, 2, 3} ^ {2, 3, 4, 5}) # 输出:{1, 4, 5}
# 并集 |
print({1, 2, 3} | {2, 3, 4, 5}) # 输出:{1, 2, 3, 4, 5}
# 差集 -
print({1, 2, 3} - {2, 3, 4, 5}) # 输出:{1}
print({2, 3, 4, 5} - {1, 2, 3}) # 输出:{4, 5}
# 判断子集
print({1, 2, 3} <= {2, 3, 4, 5}) # 输出:False集合方法
集合.add(元素) 方法:在集合中添加指定的元素(添加元素的位置不能确定,因为元素是无序的)。
python
set1.add(100)
print(set1) # 输出:{1, 2, 3, 100}。注释:可能输出的顺序不一样,这是由于集合的无序性导致的。集合.pop() 方法:从集合中随机取出元素,被取出的元素不会出现在集合当中了(取出元素的位置不能确定,因为元素是无序的)。
python
a = set1.pop()
print(a) # 输出:1
print(set1) # 输出:{2, 3, 100}集合.remove(元素) 方法:从集合中移除指定元素,若元素不存在于集合中,则报键错误。
python
set1.remove(100)
print(set1) # 输出:{2, 3}集合1.update(集合2) 方法:将 集合2 中 集合1 不存在的元素添加到 集合1 中。
python
set1.update({'abc', 'ss'})
print(set1) # 输出:{2, 3, 'ss', 'abc'}集合.clear() 方法:清空集合。
python
# 注释:效果和set1 = set()相同
set1.clear()
print(set1) # 输出:set()集合迭代
集合也属于可迭代对象(Iterable),因此可以直接用于 for 循环的对象,前面讲到的可迭代对象函数也适用于集合。
python
from collections.abc import Iterable
print(isinstance({'a', 'b', 'c', 1, 2, 3}, Iterable)) # 输出:True
# 通过for循环遍历集合可以输出里面所有的元素
set1 = {'a', 'b', 'c', 1, 2, 3}
for item in set1:
print(item, end=' ') # 输出:1 2 b 3 a c
# in/not in:判断集合中是否存在指定的元素。
print(0 in {0, 1, 2, 3}) # 输出:True
print(1 not in {1, 2, 3}) # 输出:False
# len(可迭代对象)函数:返回可迭代对象的长度。
print(len({1, 2.0, '3'})) # 输出:3
# max/min函数:获取集合中最大或最小的元素。
print(max({'a', 'hj', 'u', 'z'})) # 输出:z
print(min({1, 45, 89, 0, -1, 8})) # 输出:-1
# sum(可迭代对象):返回可迭代对象中的数值之和,注意可迭代对象里面的元素必须全是整型或浮点型。
print(sum({1, 23, -7, -1})) # 输出:16需要注意的是,当集合对象本身在迭代过程中时,不能被改变长度。也就是说在迭代中涉及到改变集合对象本身长度的方法都不能使用。
python
temp_set = {1, 2, 3}
# 集合对象本身在迭代过程中
for ip_port in temp_set:
temp_set.remove(ip_port) # 报错:Set changed size during iteration在迭代过程中集合的长度发生改变。
print(temp_set, end=', ')要解决这个问题也很简单,要么通过 .cpoy() 方法拷贝出一个新的有相同元素的集合,要么通过 list() 方法返回一个新的列表对象。
python
temp_set = {1, 2, 3}
# 拷贝出一个新的有相同元素的集合
for ip_port in temp_set.copy():
temp_set.remove(ip_port)
print(temp_set, end=', ') # 输出:{2, 3}, {3}, set()
temp_set = {1, 2, 3}
# 返回一个新的列表对象
for ip_port in list(temp_set):
temp_set.remove(ip_port)
print(temp_set, end=', ') # 输出:{2, 3}, {3}, set()集合推导式
套用上面列表推导式的原理,我们还可以写出集合推导式:
python
set1 = {i for i in '12345'}
print(set1, type(set1)) # 输出:{'5', '1', '3', '4', '2'} <class 'set'>。注释:集合是无序的,因此输出也是无序的。元组(tuple)
在 Python 中,元组是一个常用的数据容器类型,用 tuple 表示。
- 元组可以存储多个任意类型的数据,相互之间用英文逗号
,隔开,当中的数据被称为“元素”,没有元素的空元组用()表示,注意当元组中只有一个元素的时候,后面必须加上英文逗号,才能表示为元组。
python
# 元组(tuple):(数据1, 数据2, 数据3...)
(1234, 56.78, 'WASD', True) () # 空元组
print(type((1234, 56.78, 'WASD', True))) # 输出:tuple
print(isinstance((1234, 56.78, 'WASD', True), tuple)) # 输出:True
print(type((1234))) # 输出:int。注释:数据本身的类型。
print(type((1234,))) # 输出:tuple。注释:元组中只有一个元素的时候,后面必须加上英文逗号,才能表示为元组。- 元组的长度不能被改变,因此元组不支持“增删”操作;元组中元素的内存地址不能被改变,因此元组不支持“改”操作;元组的数据结构是有序的(按顺序排列),因此可以使用下标获取元组中的元素,所以元组支持“查”操作。
- 一个变量接收用英文逗号分开的多个值时,且外部没有其他符号时,变量的类型就是元组。
python
names = 'name1', 'name2', 'name3'
print(names, type(names)) # 输出:('name1', 'name2', 'name3') <class 'tuple'>提醒
在不改变容器中元素的情况下,使用元组比使用列表更好,因为创建一个元组比创建一个列表,不管是内存开销还是 CPU 时间的开销都更少。
元组创建
在 Python 中来创建一个元组有两种常用方式,具体如下:
- 自定创建:通过
()在里面写入元素来直接定义一个元组。
python
print((1, 2, '3', 4)) # 输出:(1, 2, '3', 4)。注释:定义一个有4个元素的集合。- 迭代创建:通过内置的
tuple(可迭代对象)函数,遍历可迭代对象来创建一个列表。
python
print(tuple()) # 输出:()。注释:使用tuple()创建一个空的集合。
print(tuple('abc')) # 输出:('a', 'b', 'c')。注释:遍历'abc'字符串,创建了一个只包含字符元素的元组。
print(tuple(range(3))) # 输出:(0, 1, 2)。注释:遍历range(3)对象,创建了一个0~2范围的元组。元组操作
元组拼接:通过 + 符号,将两个元组合并成一个新元组。
python
print((1, 2) + (3, 4)) # 输出:(1, 2, 3, 4)重复输出:通过 * 符号,将元组里面的数据重复输出生成一个新元组。
python
print((1, 2) * 2) # 输出:(1, 2, 1, 2)下标选择:通过下标获取元组中的元素。
python
print(('red', 'green', 'yellow', 'purple')[1]) # 输出:green切片操作:通过两个下标或两个下标加步长来切割元组。
python
print(('red', 'green', 'yellow', 'purple')[0:3]) # 输出:('red', 'green', 'yellow')
print(('red', 'green', 'yellow', 'purple')[0::2]) # 输出:('red', 'yellow')元组方法
元组.index(元素, 开始下标【可选】, 结束下标【可选】) 方法:返回元组内指定元素的下标,可以通过开始下标和结束下标指定查询范围,前闭后开。如果范围内不存在指定元素,则返回 ValueError 错误;如果范围中存在多个指定元素,则返回第一个指定元素的下标。
python
names = ('周', '张', '张', '刘', '张', '黄', '陈', '张')
print(names.index('李')) # 报错:元素'李'不在元组当中。
print(names.index('张')) # 输出:1。注释:虽然'张'元素在names元组中存在多个,但只返回第一个'张'元素的下标。
print(names.index('张', 1)) # 输出:1。注释:虽然'张'元素在[1:)元组范围中存在多个,但只返回第一个'张'元素的下标。
print(names.index('张', 2, -1)) # 输出:2。注释:虽然'张'元素在[2:-1)元组范围中存在多个,但只返回第一个'张'元素的下标。
print(names.index('张', 3, -1)) # 输出:4。注释:'张'元素在[3:-1)元组范围只存在一个,返回他的下标。
print(names.index('张', 5, -1)) # 报错:范围区间[5:-1)是前闭后开,'张'元素不在范围当中。元组.count(元素) 方法:获取指定元素在元组中出现的次数。
python
names = ('周', '张', '张', '刘', '张', '黄', '陈', '张')
print(names.count('张')) # 输出:4元组迭代
元组也属于可迭代对象(Iterable),因此可以直接用于 for 循环的对象,前面讲到的可迭代对象函数也适用于元组。
python
from collections.abc import Iterable
print(isinstance(('red', 'green', 'yellow', 'purple'), Iterable)) # 输出:True
# 通过for循环遍历获取元组中的元素。
colors = ('red', 'green', 'yellow', 'purple')
for item in colors:
print(item, end=', ') # 输出:red, green, yellow, purple,
# in/not in判断指定元素是否包含在元组中。
print('red' in ('red', 'green', 'yellow', 'purple')) # 输出:True
print('pink' in ('red', 'green', 'yellow', 'purple')) # 输出:False
# len(可迭代对象)函数:返回可迭代对象的长度。
print(len(('red', 'green', 'yellow', 'purple')) # 输出:4
# max/min函数:获取元组中最大或最小的元素。
print(max(('a', 'hj', 'u', 'z'))) # 输出:z
print(min((1, 45, 89, 0, -1, 8))) # 输出:-1
# sum(可迭代对象):返回可迭代对象中的数值之和,注意可迭代对象里面的元素必须全是整型或浮点型。
print(sum((1, 23, -7, -1))) # 输出:16元组推导式
在 Python 中,没有元组推导式这样的直接语法结构。不过在后面学习的中,我们会通过生成器表达式结合 tuple() 函数来创建元组,达到与上面推导式类似的效果。