验证码
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
验证码(Captcha)用于在网络环境中区分机器和人类。目前,验证码已经成为各种网站和应用程序的标准安全措施,通过让用户输入验证码,可以阻止机器程序的恶意行为。通过验证码可以,阻止爬虫抓取数据、用户批量注册,或者是刷单购票等行为。
在目前的互联网环境中,有多种完全不同的验证码形态。主要包括包括如下几种类型,分别是字符型验证码、文字型验证码、图片型验证码等等:

不同形态的验证码,需要使用不同的技术解决。验证码识别,可能涉及图片分类、目标检测、OCR光学字符识别,等等计算机视觉的相关算法:
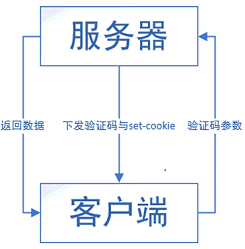
在爬取数据的过程中,难免会遇到各种各样的验证码来阻挡爬虫,绝大部分的验证码对于人来说还是很好识别并验证成功的。但爬虫只是一段死板的程序,没有灵活思维和高效的识别,所以如何破解验证码是爬虫的一个难点,因为它涉及到的不仅仅是爬取数据还有图片识别、轨迹计算等其他方面的分析。首先我们明确一点,所有的验证码原理都是一样的,服务器发送验证码图片,我们将验证码的参数返回给服务器,服务器验证参数是否正确,若正确则返回数据。
图形验证码
无背景验证码
无背景验证码:指的是内容背景是单色的,无其花纹的验证码。

有背景验证码
有背景验证码:指的是背景颜色多样,有花纹的验证码。对于有嘈杂的背景的验证码,我们可以对图片进行一定的处理,来提高识别率。

- 灰度化:以黑色为基准色,用不同的饱和度的黑色来显示图像,灰度图像的每个像素点色值在0-255,0代表纯黑,255代表纯白
- 二值化:将小于阈值(129)的像素点统一设置为黑色(0),反之统一设置为白色(255),得到黑白图像。

- 去噪点:检测像素点周围邻近的8个像素点,如果有4个即以上的白色像素点,则认为当前像素点是噪点,设置为白色,反之,则不是噪点,设置为黑色。

python
from PIL import Image
# 打开图片对象
image = Image.open('image.jpg')
# 图片灰度化
image1 = image.convert("L")
# 显示图片
image1.show()
# 图片二值化,有两种写法:
# 1.默认二值化数值
image2 = image.convert("1")
# 2.自定义129为二值化数值
image2 = image1.point(lambda x: 255 if x > 129 else 0)
image2.show()
# 去噪函数
def denoising(image):
pixdata = image.load()
# 获取图片宽高
w, h = image.size
# 遍历像素点
for j in range(1, h - 1):
for i in range(1, w - 1):
count = 0
l = pixdata[i, j]
if l == pixdata[i, j - 1]:
count = count + 1
if l == pixdata[i, j + 1]:
count = count + 1
if l == pixdata[i + 1, j - 1]:
count = count + 1
if l == pixdata[i + 1, j + 1]:
count = count + 1
if l == pixdata[i + 1, j]:
count = count + 1
if l == pixdata[i - 1, j + 1]:
count = count + 1
if l == pixdata[i - 1, j - 1]:
count = count + 1
if l == pixdata[i - 1, j]:
count = count + 1
if count < 4:
pixdata[i, j] = 255
return image
# 去噪点
image3 = denoising(image2)
image3.show()低像素验证码
低像素验证码:上面验证码都是图片质量比较好的验证码,即使将验证码图片放大以后,验证码字符依然很清晰。但是有的验证码图片质量就不是那么高了,例如下面的验证码,无论是放大或者缩小图片都比较模糊,对于人眼识别都是有一定偏差的,对机器识别来说就更是有难度了。

超扭曲验证码
超扭曲验证码:到目前为止出现的图片验证码中,字符的形状都是中规中矩的,没有出现扭曲、重叠的情况。但恰好就有这么一类字符的形状扭曲、重叠验证码,虽然我们不想遇见这类验证码,但并不代表它们不存在,并且它们还可能会主动找上我们,这类验证码同样对于人眼识别都是有一定偏差的,对机器识别来说就更是有难度了。
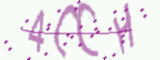
ddddocr识别库
**针对以上常见验证码,我们这里安装一个 Python 通用验证码识别模块,SDK 免费开源版的第三方库,叫 ddddocr,也称带带弟弟。该识别库无需其他的软件辅助,可直接完成图像识别,当然识别的准确率肯定不会是 100%,但相比于其它的 OCR 识别库,它的识别准确率算可以的。**首先执行下面命令来安装它:
pip install ddddocr针对以上常见的图片验证码均可使用下面的代码:
python
import ddddocr
# 读取验证码图片字节数据
with open('yzm.png', 'rb') as f:
img_bytes = f.read()
# 使用ddddocr去识别并输出结果,show_ad=False关闭广告
ocr = ddddocr.DdddOcr(show_ad=False)
# classification识别图片验证码中的内容方法
res = ocr.classification(img_bytes)
print(res)动态验证码
当前大多数验证码还是图形验证码,针对这类验证码我们可以使用 OCR(光学字符识别)扫描字符形状将其翻译成电子文本。
除了上面的静态图片验证码,还有很多种类,比方说动态验证码,这类验证码的处理方法和上面的图形验证码处理方法类似,只不过多了一些处理步骤,相对来说复杂点。
帧的概念
处理动态验证码之前,首先得说一个常识性的东西。我们之所以能看到视频中流畅的运动画面,因为将每一张静止的图像快速连续地显示,当展示的速率超过了人眼的能分辨的速率,就给大脑造成在观看运动画面的假象。
帧(Frame):视频或者动画中的每一张画面。
帧数(Frames):为帧生成数量的简称,可以解释为静止画面的数量。如果一个动画的帧率恒定为 60 帧每秒(fps),那么它在一秒钟内的帧数为 60 帧,两秒钟内的帧数为 120 帧。
帧率(Frame rate):帧数(Frames)/时间(Time),单位为帧每秒(f/s, frames per second, fps)。一般来说 FPS 用于描述视频、电子绘图或游戏每秒播放多少帧。
总的来说,每秒钟帧数愈多,所显示的动作就会愈流畅。通常,要避免动作不流畅的最低帧率是 30 。
处理流程
同样的,动态验证码也是由一帧一帧的静态验证码快速展示所形成的。
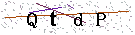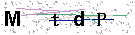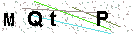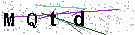
首先要做的是,获取动态验证码每一帧的静态验证码图像。观察下面的静态验证码,可以看出该验证码阴险的两点:
- 动态验证码中能看到有5个字符不停的出现,但在每一张静态验证码中就只显示4个字符,要想完整的识别字符就必须识别至少两张静态验证码。
- 多张静态验证码中就算是相同的字符,它的字体大小和粗细都不相同,这意味着多张静态验证码中即使是相同字符,识别出来的结果可能也会有所偏差。因此,我们需要从多张静态验证码中选出针对每个字符最好识别的大小和字体的图像。





按照观察的结论,接下来就是将每张静态验证码按照固定的字符宽度切割为单个图片。相对来说,字符的字体越大越粗,对于识别来说是越有利的,反应到图片上来说就是,**每列的单个图片的黑色像素点越多,就越符合我们识别的要求。**我们将每列图片上黑色像素点最多的图片筛选出来,再抹除掉背景花纹,就可以得到每个字符最容易识别的状态。





最后对每个字符进行单独识别,再将字符进行拼接,就可以得到该动态验证码的正确识别结果了。
识别代码
python
# -*- coding: UTF-8 -*-
import os
import re
import ddddocr
from PIL import Image
# 分析图片
def analyseImage(path):
im = Image.open(path)
results = {
'size': im.size,
'mode': 'full',
}
try:
while True:
if im.tile:
tile = im.tile[0]
update_region = tile[1]
update_region_dimensions = update_region[2:]
if update_region_dimensions != im.size:
results['mode'] = 'partial'
break
# im.tell():返回当前帧所处位置,从0开始计算。
# im.seek(frame):在文件序列中查找指定的帧(默认为0帧)。如果查找超越了序列的末尾,则产生一个EOFError异常。
im.seek(im.tell()+1)
except EOFError:
pass
return results
# 处理图片并保存每一帧图片
def processImage(path):
mode = analyseImage(path)['mode']
im = Image.open(path)
i = 0
# 以列表形式返回图像调色板
p = im.getpalette()
# 图像转换为RGBA格式
last_frame = im.convert('RGBA')
try:
while True:
if not im.getpalette():
im.putpalette(p)
new_frame = Image.new('RGBA', im.size)
if mode == 'partial':
new_frame.paste(last_frame)
new_frame.paste(im, (0, 0), im.convert('RGBA'))
new_frame.save('./image/%s-%d.png' % ('yzm', i))
i += 1
last_frame = new_frame
im.seek(im.tell() + 1)
except EOFError:
pass
# 切割静态验证码
def division():
for index in range(5):
for i in range(5):
im = Image.open(f'./image/yzm-{index}.png')
# 经过测算,每个字符长度大概为22
im = im.crop((i*22, 0, (i+1)*22, 35))
im.save(f'./image/{index}-{i}.png')
# 筛选最容易识别的字符图片
def distinguish():
file_list = [file for file in os.listdir('./image') if 'yzm' not in file and '-' in file]
count_list = [10000, 10000, 10000, 10000, 10000]
for file in file_list:
index = int(re.search(r'-(\d+)', file).group(1))
count = 0
image1 = Image.open(f'./image/{file}')
for y in range(0, image1.size[1]):
for x in range(0, image1.size[0]):
all = image1.load()[x, y][0] + image1.load()[x, y][1] + image1.load()[x, y][2]
if all // 3 > 30:
image1.load()[x, y] = (255, 255, 255)
count += 1
if count_list[index] > count:
count_list[index] = count
image1.save(f'./image/{index}.png')
# 识别筛选处理后的图片字符并输出拼接结果
def know():
file_list = [file for file in os.listdir('./image') if '-' not in file]
letter = ''
for file in file_list:
# 读取验证码图片字节数据
with open(f'./image/{file}', 'rb') as f:
img_bytes = f.read()
# 使用ddddocr去识别并输出结果
ocr = ddddocr.DdddOcr(show_ad=False)
res = ocr.classification(img_bytes)
letter += res
print(letter)
if __name__ == "__main__":
# 需要再当前目录下新建image文件夹,yzm-all.gif为动态验证码
processImage('./image/yzm-all.gif')
division()
distinguish()
know()
'''
识别结果:MQtdp
'''滑块验证码
滑块验证码:存在拼图缺口的图片验证码,通过下方的滑块将拼图拖动至缺口的处即可验证成功。

方块滑块
例如,当前网站的验证码,其验证方式就是核验滑块的移动距离,若移动距离等于滑块到缺口的距离,则验证成功,否则就验证失败。

当验证成功以后,访问网站的URL就会带上滑块的位移距离。
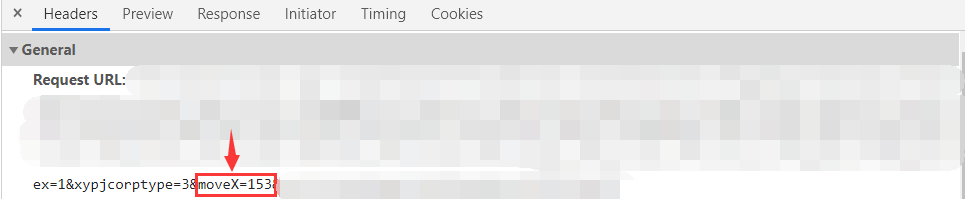
既然这样,我们就直接识别大背景图中白色缺口所在位置即可。因为是最终需要的是位移距离,因此问我们只需要知道白色缺口的横坐标,即下图红线的长度。

python
from PIL import Image
# 打开图片对象
image1 = Image.open('image.png')
# 图像转换为RGB图像(如果图片像素引用调色板中的256个值之一,就需要这步处理)
image1 = image1.convert('RGB')
# 白色像素点个数
count = 0
# 像素点遍历方式:从上往下,从左往右
# 遍历图片的X轴
for x in range(0, image1.size[0]):
# 遍历图片的Y轴
for y in range(0, image1.size[1]):
# 获取当前坐标色素点的RGB值
color = image1.load()[x, y]
# 白色的RGB值(255,255,255),但颜色识别会有误差,因此认为RGB值不小于(245,245,245)即为白色
if color[0] >= 245 and color[1] >= 245 and color[2] >= 245:
count +=1
# 当连续出现25个白色像素点时,则认为找到白色方块缺口
else:
if count > 0:
count -=1
if count > 25:
break
if count > 25:
break
# 输出X轴的横坐标
print(f'白色缺口横坐标:{x}') # 白色缺口横坐标:153OpenCV视觉库
前面的滑块验证码只要你识别到了多个连续的白色像素点,就基本上找到了缺口的位置,相对来说比较好处理,因为这是网站开发者自主设计的滑块,难度不高,容易破解。如果说使用了网络安全服务商提供的验证码,例如极验、网易易盾等,涉及到的图像处理会更复杂,验证流程更加严格:
- 验证失效:当频繁滑动极验验证码时,会偶尔出现“怪物吃掉拼图”、“请重新验证”等验证失效的情况。
- 时间限制:极验验证码生成时,若没有及时验证,即使后面验证通过,也会要求重新再验证一次。
- 轨迹验证:在拖动滑块时,会记录并上传滑块的移动轨迹,服务器会分析判定是否为人类行为还是机器行为。
因此我们需要一个视觉库来协助识别图像,其中 OpenCV 是一个用 C++ 语言编写基于 BSD 许可(开源)发行的跨平台计算机视觉库,拥有丰富的常用图像处理函数,能够快速的实现一些图像处理和识别的任务,可运行在 Linux、Windows、Android 和 Mac OS 操作系统上,使得图像处理和图像分析变得更加易于上手。
建议
这部分我们只讲图像识别这块,至于轨迹验证等其他验证在逆向章节中讲到。
安装使用
whl文件安装法:先去官网下载相应 Python 版本的 OpenCV 的 whl 文件,然后在 whl 文件所在目录下使用命令进行安装即可。
pip install opencv_python‑3.4.1‑cp36‑cp36m‑win_amd64.whl包命令安装法:直接通过包命令进行安装。
pip install opencv_python导入方法:注意安装库的名称为 opencv-python,导入模块的名称为 cv2.
import cv2图像操作
图像格式有许多种,例如:BGR 格式、RGB 格式、GRAY 格式、HSV 格式等。

python
# cv2.imread()以BGR格式读取图像,数据格式在0~255。
cv2.imread(filepath, flags)
# filepath:图片路径(注意路径中不能出现中文)
# flags:图像的通道和色彩信息(非必须)
# flag = -1, 8位深度,原通道
# flag = 0, 8位深度,1通道(灰度图(单通道))
# flag = 1, 8位深度,3通道(默认为1,即读取为彩色图像)
# flag = 2, 原深度, 1通道
# flag = 3, 原深度, 3通道
# flag = 4, 8位深度,3通道
cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道
cv2.IMREAD_GRAYSCALE:读入灰度图片
cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道
# 不同格式之间可以相互转换
img = cv2.imread()
# 格式转换:将BGR格式转换成RGB格式
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 热力化:将RGB格式转换成GRAY格式,彩色图像转为热力图像
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 彩色化:将GRAY格式转换成RGB格式,灰度图像转为彩色图像
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
# 模型化:将RGB格式转换为HSV颜色模型
img = cv2.cvtColor(img, cv2.COLOR_RGB2HSV)
# 图像缩放
cv2.resize(image, image2, dsize)
# image,输入原始图像
# image2,输出新图像
# dsize,图像的大小
#图像翻转
cv2.flip(img, flipcode)
# img,要反转的图像
# flipcode,控制翻转效果,大于0沿y轴翻转,等于0沿x轴翻转,小于0沿x,y轴同时翻转
# 显示图像,需要cv2.waitKey保持图像窗口的显示,否则图像会一闪而过
cv2.imshow(wname, img)
# wname:显示图像的窗口的名字
# img:显示imread读入的图像
# 保持图像窗口的显示
cv2.waitKey(delay)
# delay表示保持窗口显示多少毫秒,不填默认为0,即一直保持窗口。
# 保存图片
cv2.imwrite(file, img, num)
# file:要保存的文件名
# img:要保存的图像。可选的第三个参数,它针对特定的格式:对于JPEG,其表示的是图像质量,用0-100的整数表示,默认95。
# num:压缩级别,默认为3。模板匹配
模板就是一副已知的小图像,而模板匹配就是在一副大图像中搜寻目标,已知该图中有要找的目标,且该目标同模板有相同的尺寸、方向和图像元素,通过一定的算法可以在图中找到目标。
python
# 下面方法中带NORMED表示归一
# 系数匹配法: 1表示完美的匹配,-1表示最差的匹配。
cv2.TM_CCOEFF
cv2.TM_CCOEFF_NORMED
# 相关匹配法: 该方法采用乘法操作,数值越大表明匹配程度越好。
cv2.TM_CCORR
cv2.TM_CCORR_NORMED
# 平方差匹配法: 采用平方差来进行匹配;最好的匹配值为0;匹配越差值越大。
cv2.TM_SQDIFF
cv2.TM_SQDIFF_NORMED易盾滑块
网易易盾是一家安全服务提供商,旗下有许多验证码产品,其中一项便是嵌入式滑块验证码,仅需轻轻滑动完成拼图,即可完成安全验证。



python
import cv2
import numpy as np
from PIL import Image, ImageDraw
# 分析出具体位置
def tell_location(path1, path2, path3):
# 以彩色图像BGR格式读取背景图
img_rgb = cv2.imread(path2)
# 将背景图转为热力图
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
# 以灰度图像BGR格式读取缺口图
template = cv2.imread(path1, 0)
# 使用归一化系数匹配法,在背景图中匹配缺口图
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
# 使用二分法查找阈值的精确值
L = 0
R = 1
start = 0
run = 1
while run < 20:
run += 1
threshold = (R + L) / 2
if threshold < 0:
print('Error')
return None
# 输出满足条件的坐标
loc = np.where(res >= threshold)
if len(loc[1]) > 1:
L += (R - L) / 2
# 筛选出匹配度最高的
elif len(loc[1]) == 1:
start = loc[1][0]
print('目标区域起点x坐标为:%d' % start)
break
elif len(loc[1]) < 1:
R -= (R - L) / 2
distance = int(start)
draw_line(distance, path2, path3)
# 通过跟踪发现,最终的轨迹落点x轴位置会大10px
return distance + 10
# 绘制一条竖线标记位置,方便查看效果
def draw_line(x, path2, path3):
img = Image.open(path2)
img_draw = ImageDraw.Draw(img)
img_draw.line((x, 0, x, img.size[1]), 'red')
img.save(path3)
if __name__ == '__main__':
tell_location('small.jpg', 'big.jpg', 'final.jpg')
'''
目标区域起点x坐标为:215
'''极验滑块
极验是一家专门做反爬验证的公司,主要的产品之一就是缺口滑块验证码。上面使用了模板匹配的方法成功识别到了网易易盾滑块的缺口位置,这里我们使用新的方法来破解极验滑块。
读取图片:通过 cv2.imread() 以BGR格式读取图像。
python
import cv2
# 读取图片
img = cv2.imread(r'图像路径')
高斯滤波:把背景图片模糊化,去除图片中的一些噪声,减少干扰,为下一步的边缘检测做好铺垫。
python
img = cv2.GaussianBlur(src=img, ksize=(5, 5), sigmaX=0, sigmaY=None)
# src:需要处理的图片
# ksize:高斯内核大小,需要传入一个(x, y)元组,这里可以取(5, 5)
# sigmaX:高斯内核函数在X方向上的标准偏差
# sigmaY:高斯内核函数在Y方向上的标准偏差
边缘检测:验证码图片中的缺口通常具有比较明显的边缘,所以借助一些边缘检测算法,再加上调整阈值是可以找出缺口位置的。
python
img = cv2.Canny(image=img, threshold1=200, threshold2=400, apertureSize=None, L2gradient=None)
# image:需要处理的图片
# threshold1、threshold2:两个阈值,分别是最小判定临界点和最大判定临界点(根据图片自行调整)
# apertureSize:用于查找图片渐变的索贝尔内核的大小
# L2gradient:用于查找梯度幅度的等式
轮廓提取:可以看到图片中会保留比较明显的边缘信息,利用 findContours 方法提取出这些边缘的轮廓信息。
python
# findContours提取出这些边缘的轮廓信息,image需要处理的图片,mode定义轮廓的检索模式为cv2.RETR_CCOMP,method定义轮廓的近似方法为cv2.CHAIN_APPROX_SIMPLE
# 结果包含两个参数的元组,第一个是包含一系列轮廓坐标的元组(有用),第二个则是一个数组(无用)
contours, _ = cv2.findContours(image=img, mode=cv2.RETR_CCOMP, method = cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
# boundingRect提取边缘的轮廓的起点(x, y)和宽高(w, h)
x, y, w, h = cv2.boundingRect(contour)
# rectangle将边缘的轮廓绘制在图像上,参数分别是图像img、轮廓的起点(x, y)、轮廓的终点(x + w, y + h)、白色线框(255【灰度】, 0, 0)、线条粗细1
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 1)
# 保存图片
cv2.imwrite('image.png', img)
轮廓筛选:我们已经成功获取了各个轮廓的矩形边缘,接下来我们可以根据面积、周长和偏移量等筛选缺口所在位置。
- 首先经过测算目标缺口的外接矩形高度大约是整个验证码高度的0.25倍,宽度大约是0.15倍,允许误差在20%情况。
python
# 验证码高度、宽度
height, width, _ = img.shape
# 面积范围
max_area = (height * 0.25) * (width * 0.15) * 1.2
min_area = (height * 0.25) * (width * 0.15) * 0.8
# 周长范围
max_length = ((height * 0.25) + (width * 0.15)) * 2 * 1.2
min_length = ((height * 0.25) + (width * 0.15)) * 2 * 0.8- 其次图中滑块的外接矩形和缺口的外接矩形是相识的,但我们可以通过外接矩形起点的X坐标,也就是偏移量来区分哪一个是缺口的外接矩形,这里设最小偏移量是验证码宽度的0.2倍,最大偏移量是验证码宽度的0.85倍。
python
# 偏移量范围
max_offset = height * 0.85
min_offset = height * 0.2- 最后通过筛选符合要求的外接矩形,其X坐标就是滑块需要滑动的距离。
python
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
if max_area >= (w * h) >= min_area and max_length >= (w + h) * 2 >= min_length and max_offset >= x >= min_offset:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 1)
print(f'滑块滑动距离:{x}') # 滑块滑动距离:206
cv2.imwrite('image.png', img)
其他滑块
最后我们再来看一个网站自主设计的滑块,如下:


我们使用前面易盾滑块中的模板匹配方法,发现识别结果就出现了偏差,红线并没有到缺口位置:

既然是识别结果出现了偏差,那我们将图片中影响识别的点给抹除掉,将需要识别的点给凸显出来。验证码中缺口图和背景图的缺口都存在着明显的白色轮廓,根据这些白色像素点结合上面的二值化处理方法,我们就可以将整个轮廓凸显出来,再使用上面的方法就可以达到很好的识别效果。



python
import cv2
import numpy as np
from PIL import Image, ImageDraw
# 二值化方法
def binary(path1, path2):
image1 = Image.open(path1)
img_draw = ImageDraw.Draw(image1)
for y in range(0, image1.size[1]):
for x in range(0, image1.size[0]):
all = image1.load()[x, y][0] + image1.load()[x, y][1] + image1.load()[x, y][2]
# 设定阈值为220,大于220画为白色点,小于220画为黑色点
if all // 3 > 220:
img_draw.point((x, y), (255, 255, 255))
else:
img_draw.point((x, y), (0, 0, 0))
image1.save(path2)
# 分析出具体位置
def tell_location(path1, path2, path3):
# 以彩色图像BGR格式读取背景图
img_rgb = cv2.imread(path2)
# 将背景图转为热力图
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
# 以灰度图像BGR格式读取缺口图
template = cv2.imread(path1, 0)
# 使用归一化系数匹配法,在背景图中匹配缺口图
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
# 使用二分法查找阈值的精确值
L = 0
R = 1
start = 0
run = 1
while run < 20:
run += 1
threshold = (R + L) / 2
if threshold < 0:
print('Error')
return None
# 输出满足条件的坐标
loc = np.where(res >= threshold)
if len(loc[1]) > 1:
L += (R - L) / 2
# 筛选出匹配度最高的
elif len(loc[1]) == 1:
start = loc[1][0]
print('目标区域起点x坐标为:%d' % start)
break
elif len(loc[1]) < 1:
R -= (R - L) / 2
distance = int(start)
draw_line(distance, path2, path3)
# 通过跟踪发现,最终的轨迹落点x轴位置会大10px
return distance + 10
# 绘制一条竖线标记位置,方便查看效果
def draw_line(x, path2, path3):
img = Image.open(path2)
img_draw = ImageDraw.Draw(img)
img_draw.line((x, 0, x, img.size[1]), 'red')
img.save(path3)
if __name__ == '__main__':
# 二值化处理原图
binary('old_small.jpg', 'new_small.png')
binary('old_big.jpg', 'new_big.png')
# 调用方法识别处理后的图
tell_location('new_small.png', 'new_big.png', 'final.png')
'''
输出:
目标区域起点x坐标为:83
'''上图中的干扰点少,我们可以进行二值化处理,但如果图片中的干扰点太多了,就不是那么容易处理了,如下图:


这时自己也可以写一种通过轮廓定位方法来识别滑块需要滑动的距离,效果如下:

python
from PIL import Image, ImageDraw
# 得出识别距离
def dis(path1, path2):
'''
:param path1: 缺口图
:param path2: 背景图
:return: 识别距离
'''
# 缺口图
# 缺口图白色像素点列表
white = []
image1 = Image.open(path1)
for y in range(0, image1.size[1]):
# 缺口图的最大宽度为60
x_min = 60
x_max = 0
for x in range(0, image1.size[0]):
all = image1.load()[x, y][0] + image1.load()[x, y][1] + image1.load()[x, y][2]
if all // 3 > 235:
if x < x_min:
x_min = x
if x > x_max:
x_max = x
# 将每行最左边和最右边的白色点存储到列表
if x_min != 60 and x_max != 0:
white.append([x_min, y])
white.append([x_max, y])
# 筛选所有白点横坐标
white_x = [item[0] for item in white]
# 从左至右,从上至下,第一个白点x坐标减最小x坐标的距离
white_fir = white_x[0] - min(white_x)
# 背景图
# 背景图的白色点列表
white_bg = []
image2 = Image.open(path2)
for y in range(0, image2.size[1]):
for x in range(0, image2.size[0]):
all = image2.load()[x, y][0] + image2.load()[x, y][1] + image2.load()[x, y][2]
if all // 3 > 235:
# 将所有识别的白点存储到列表
white_bg.append([x, y])
# 遍历背景图白点列表
for bg in white_bg:
# 设置容错点数为7(点数越高,准确率越低,反之则越高,若为0,可能匹配不到,这和识别的白点有关)
points = 7
# 从第二个点遍历缺口图白点列表
for i in range(1, len(white)):
# 缺口图第一白点和后面所有白点的x轴差值,y轴差值
fir_dif = [white[i][0] - white[0][0], white[i][1] - white[0][1]]
# 结合背景图出现的白点,结合差值计算理论上可能出现的白点
theory = [bg[0] + fir_dif[0], bg[1] + fir_dif[1]]
# 理论白点不出现在背景图的实际白点中,容错点减一
if theory not in white_bg:
points -= 1
# 当容错点为0或负数,则该点不是识别轮廓上的点
if not points:
break
# 能运行到遍历结束,说明该点对应轮廓上的第一个白点
if i == len(white) - 1:
# 第一个白点横坐标减去轮廓第一个白点x坐标减最小x坐标的距离就是位移距离
distance = bg[0] - white_fir
print(f'识别位移距离:{distance}')
return distance
# 绘制一条竖线标记位置,方便查看效果
def draw_line(x, path2, path3):
img = Image.open(path2)
img_draw = ImageDraw.Draw(img)
img_draw.line((x, 0, x, img.size[1]), 'red')
img.save(path3)
if __name__ == '__main__':
# 原小缺口图
original1 = './image1.jpg'
# 原大背景图
original2 = './image2.jpg'
# 处理后图
original3 = './image3.jpg'
# 得出距离
x = dis(original1, original2)
if x:
draw_line(x, original2, original3)
else:
print('未能有效识别...')
'''
输出:
识别位移距离:185
'''**同样的,这里也可以使用 ddddocr 库来识别。**代码如下:
python
import ddddocr
with open('image1_1.jpg', 'rb') as f:
slide_bytes = f.read()
with open('image2_1.jpg', 'rb') as f:
background_bytes = f.read()
# show_ad=False关闭广告
det = ddddocr.DdddOcr(show_ad=False, det=False, ocr=False)
res = det.slide_match(slide_bytes, background_bytes, simple_target=True)
print(res)
'''
输出:{'target_y': 0, 'target': [181, 1, 241, 61]}
注释:其中target第一个值正好和上面代码的出来的结果差不多。
'''**但如果验证码的和拼图相似的缺口不止一处,使用上面的代码就有可能出错,因为可能会识别到形状一样但错误的缺口,导致输出错误的移动距离,这个时候我们就需要把缺口形状以及背景像素同时考虑来进行处理了。**例如,下面的拼图验证码:


python
# -*- coding: utf-8 -*-
import asyncio
import cv2
import numpy as np
class GapLocater:
def __init__(self, gap, bg):
"""
init code
:param gap: 缺口图片
:param bg: 背景图片
"""
self.gap = gap
self.bg = bg
async def clear_white(self, img):
"""
清除图片的空白区域,这里主要清除滑块的空白
"""
img = cv2.imdecode(np.frombuffer(img, np.uint8), cv2.IMREAD_COLOR)
rows, cols, channel = img.shape
min_x = 255
min_y = 255
max_x = 0
max_y = 0
for x in range(1, rows):
for y in range(1, cols):
t = set(img[x, y])
if len(t) >= 2:
if x <= min_x:
min_x = x
elif x >= max_x:
max_x = x
if y <= min_y:
min_y = y
elif y >= max_y:
max_y = y
img1 = img[min_x: max_x, min_y: max_y]
return img1
async def template_match(self, tpl, target):
"""
背景匹配
"""
th, tw = tpl.shape[:2]
result = cv2.matchTemplate(target, tpl, cv2.TM_CCOEFF_NORMED)
# 寻找矩阵(一维数组当作向量,用Mat定义) 中最小值和最大值的位置
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
tl = max_loc
br = (tl[0] + tw, tl[1] + th)
# 绘制矩形边框,将匹配区域标注出来
# target:目标图像
# tl:矩形定点
# br:矩形的宽高
# (0, 0, 255):矩形边框颜色
# 1:矩形边框大小
cv2.rectangle(target, tl, br, (0, 0, 255), 2)
return tl
async def image_edge_detection(self, img):
"""
图像边缘检测
"""
edges = cv2.Canny(img, 100, 200)
return edges
async def run(self, is_clear_white=False):
if is_clear_white:
img1 = await self.clear_white(self.gap)
else:
img1 = cv2.imdecode(np.frombuffer(self.gap, np.uint8), cv2.IMREAD_COLOR)
img1 = cv2.cvtColor(img1, cv2.COLOR_RGB2GRAY)
slide = await self.image_edge_detection(img1)
back = cv2.imdecode(np.frombuffer(self.bg, np.uint8), cv2.IMREAD_COLOR)
back = await self.image_edge_detection(back)
slide_pic = cv2.cvtColor(slide, cv2.COLOR_GRAY2RGB)
back_pic = cv2.cvtColor(back, cv2.COLOR_GRAY2RGB)
x = await self.template_match(slide_pic, back_pic)
# 输出横坐标, 即 滑块在图片上的位置
return x[0]
if __name__ == '__main__':
# 滑块图片
with open('./block.png', 'rb') as fs:
block = fs.read()
# 背景图片
with open('./bg.png', 'rb') as fs:
bg_img = fs.read()
img_index = GapLocater(block, bg_img)
x = asyncio.run(img_index.run())
print(f'位移距离{x}')点选验证码
除了滑块验证码,有些网站还会添加点选验证码进行验证。
易盾点选
前面我们讲到了一种易盾滑块验证码,然而网易易盾开发的验证码不止这一种,还有一类属于点选类的验证码。例如下图就是网易登录使用的验证码:

**对于点选类验证码,服务器验证它的方式就是图片上的字体坐标以及点击字体的顺序。**这里同样可以使用 cv2 结合 ddddocr 来识别处理:
python
import cv2
import ddddocr
# 读取验证码字节数据
with open('eb.jpg', 'rb') as f:
image = f.read()
# 识别验证码,det=True启用文本检测
det = ddddocr.DdddOcr(det=True)
poses = det.detection(image)
# 标上矩形框
im = cv2.imread('eb.jpg')
for box in poses:
x1, y1, x2, y2 = box
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
# 保存至新的图片
cv2.imwrite('result.jpg', im)最终的识别结果如下:可以看到每个字体都被打上标记,说明已经被定位到,接下来就是字符的顺序问题了。
