Session会话
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
前面我们学习 requests 库,现在我们已经能爬取最基本的网页了,但这并不是全部。比如登录一个页面,我们经常会“设置 30 天内记住我”或者“自动登录”选项。那么它们是怎么记住我的呢?假如需要爬取用户登录后的网页信息,该怎么办呢?现在的互联网是建立在各种网络协议基础之上的,其中的最重要的协议之一就是 HTTP 协议。标准的 HTTP 协议是无状态、无连接的,也就是说每一个访问都是独立的,服务器处理完一个访问就断开连接,然后处理下一个新的访问。然而这种访问机制的缺点显而易见,就是客户端在同一网站下浏览网页时,服务器会与客户端频繁的建立连接和断开连接,会带给服务器有很大的访问压力。为了弥补这一不足,两种用于保持 HTTP 连接状态的技术就应运而生了,一个是 Cookie,而另一个则是 Session。
建议
Cookie 和 Session 是两种不同的技术,用于在 Web 应用程序中保持用户的状态信息,它们可以独立使用,而且有时候会根据具体需求选择使用其中一种或两者结合使用。
Cookie
Cookie简介
Cookie 是由服务器在 HTTP 响应的头部中通过 Set-Cookie 字段将用于记录被访问网站相关信息的(例如用户的身份、偏好设置等)、有时效性的、以键值形式存储的一小段文本信息(主要包括:名字,值,路径和域)传递并存放在客户端。如下图所示:
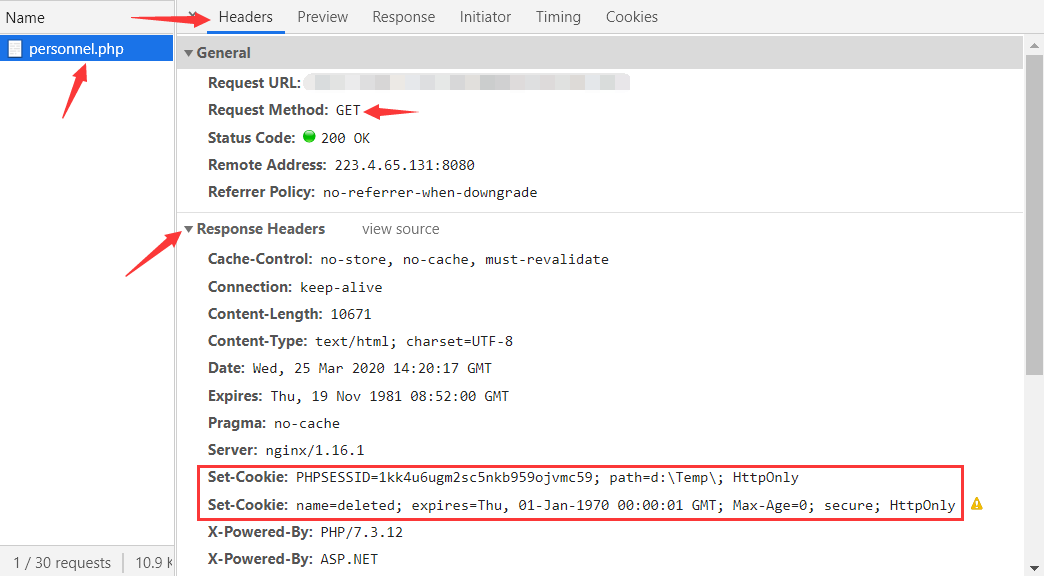
客户端获取 Cookie 后,Cookie 会随着客户端发出每一个请求的头部中通过 Cookie 字段发送至同一网站的服务器,以便访问时减少一些步骤,也是一个客户端保持状态的方案。如下图所示:
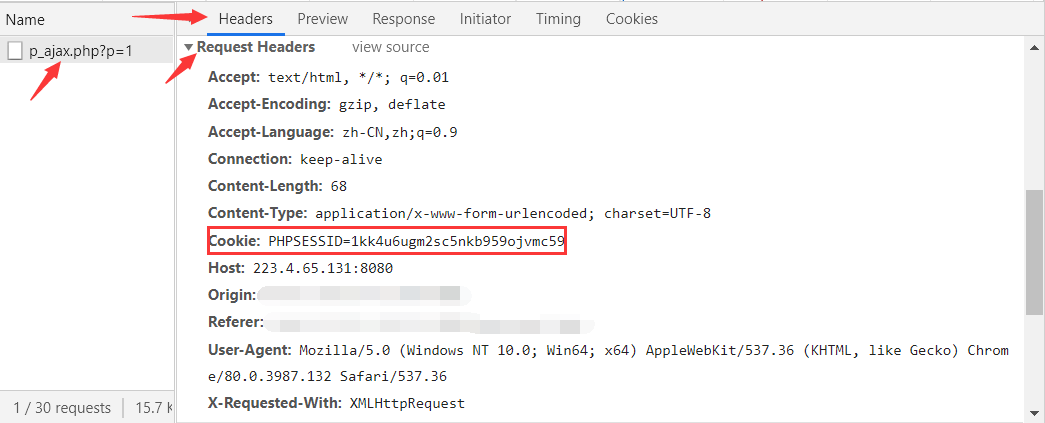
打开开发者工具——选择”Application“选项卡——点击”Cookies“选项——选择”当前网站的网址“,就能看到当前网站 Cookie 所有的信息。如下图所示:
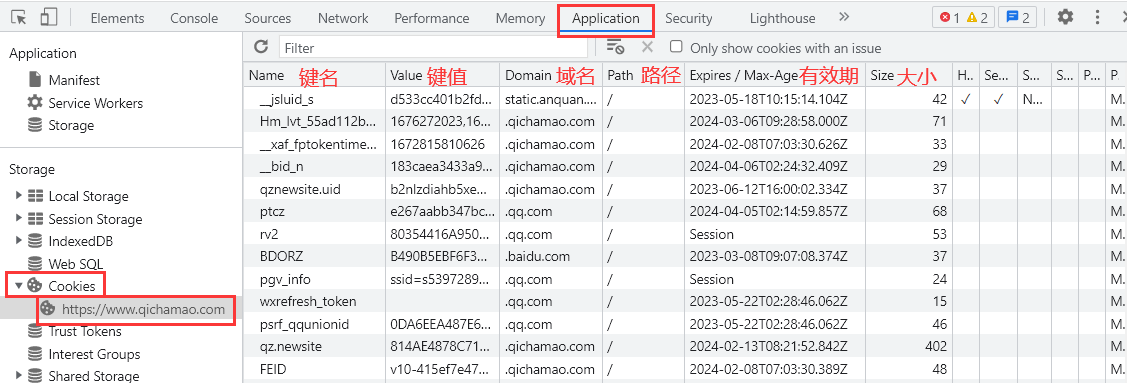
清空Cookie
前面提到 Cookie 一般是由服务器给予的,但有些反爬网站不会直接把可用的 Cookie 返回给你,而是让浏览器通过它提供的一些参数在本地计算出可用的 Cookie,再携带上进行访问。因此有时需要清空我们的 Cookie,好让服务器认为我们第一次访问的用户,重新给我们分配参数再逆向 Cookie 生成的逻辑。
清空单条Cookie
可以看到上面的图中,Cookie 是一段段文本信息,如果说我们要删除 Cookie 中某一条信息,可以进行如下操作:打开开发者工具——选择“Application”选项卡——点击“Cookies”选项——选择“当前网站的网址”——选中 Cookie 的一行信息——右键选项点击“Delete”或点击键盘 Delete 键进行删除。
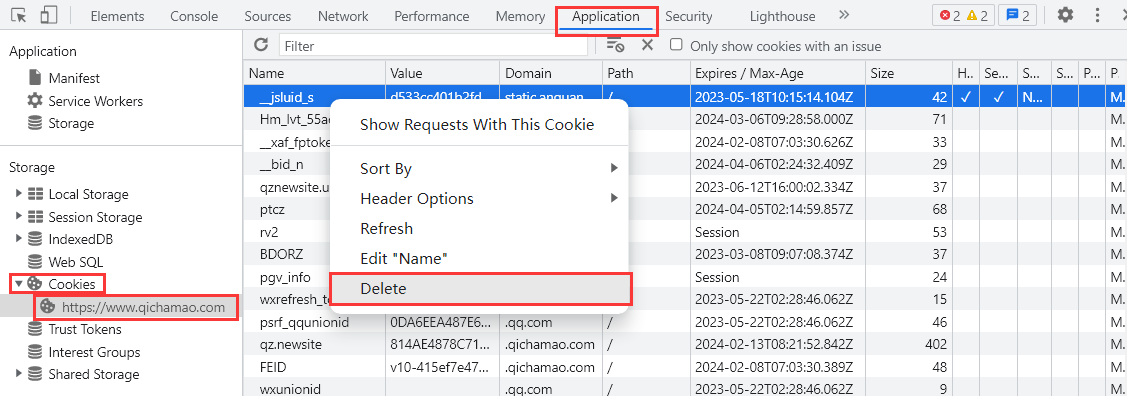
清空网站Cookie
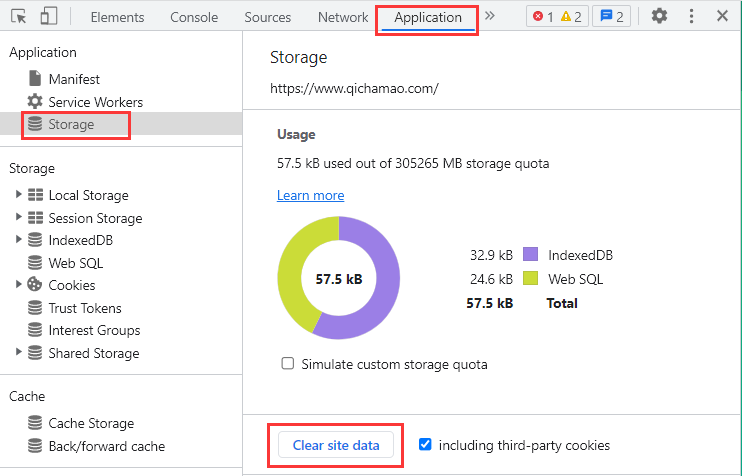
清空当前网站 Cookie 的方法:打开开发者工具——选择“Application”选项卡——选择“Storage”选项——点击“Clear site data”清空该站点数据。
清空所有Cookie
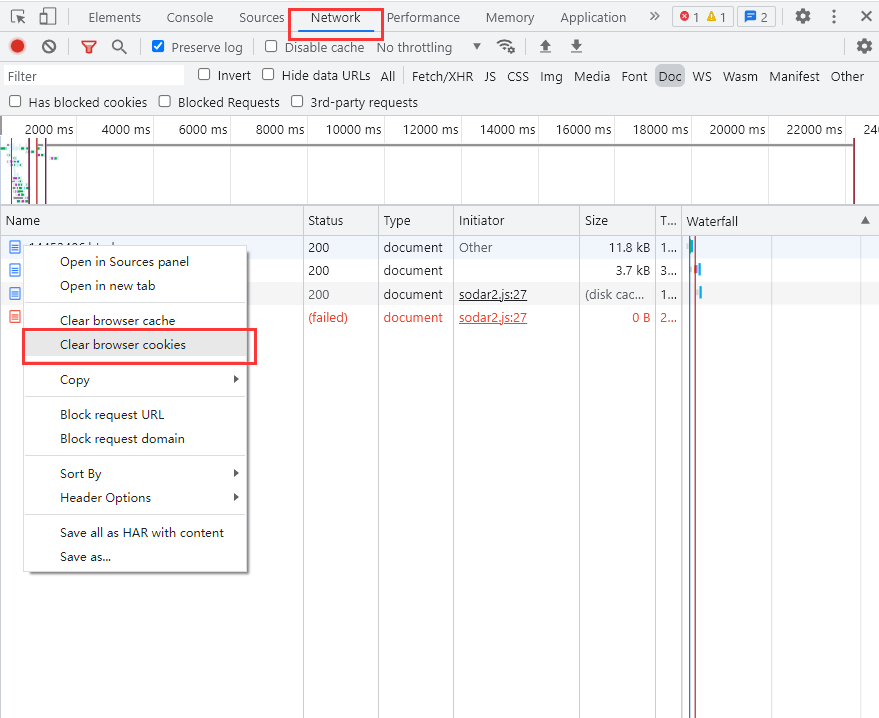
清空所有 Cookie 的方法也很简单:在“开发者工具”中的 Network 选中任一个请求,单击右键选择 Clear Browser cookies 清空浏览器 Cookies。
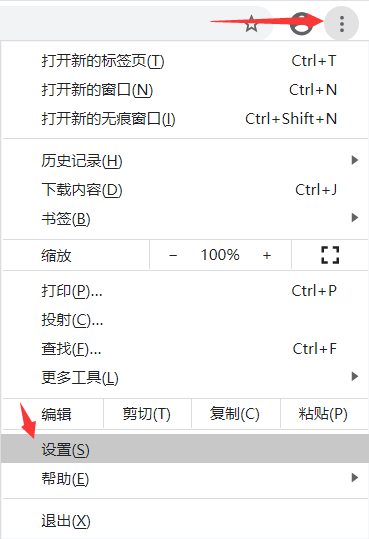
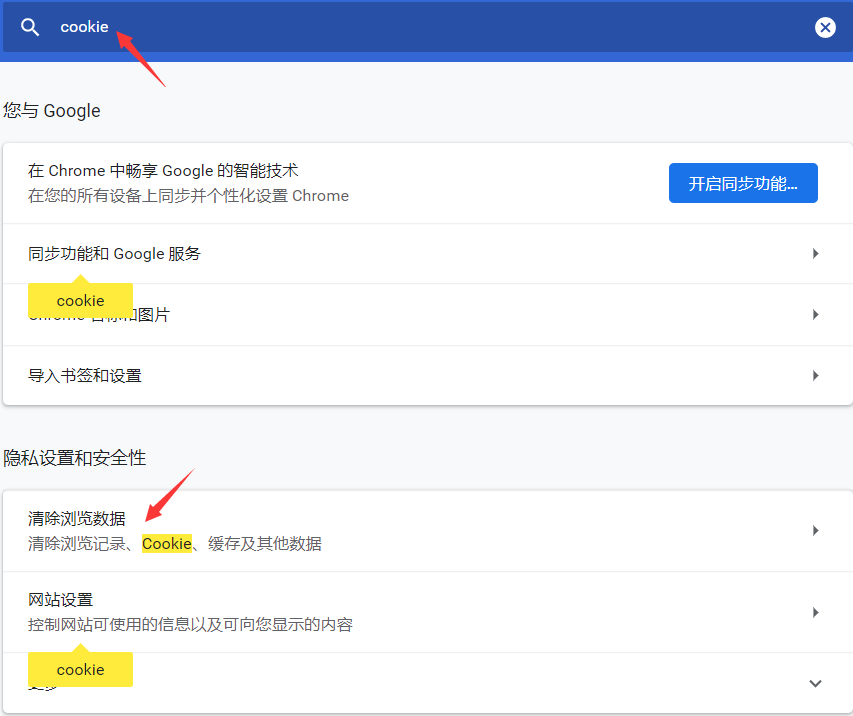
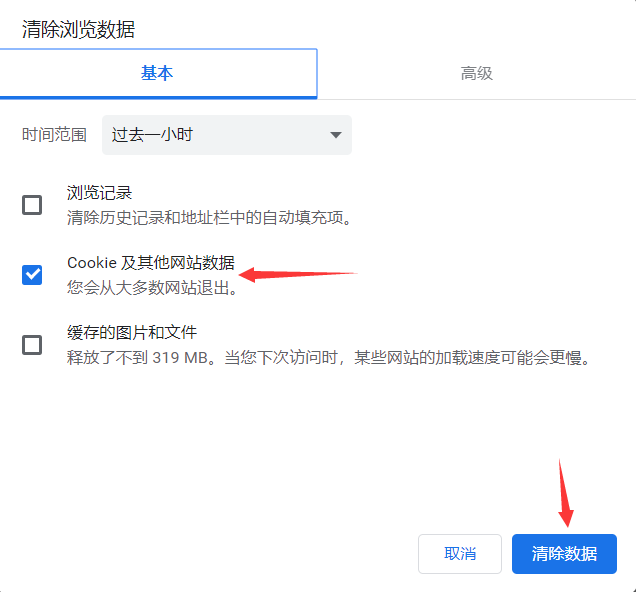
还有一种清空所有Cookie的方法:右上角“自定义及控制”——设置——搜索框输入“cookie”——点击“清除浏览数据”——勾选“Cookie及其他网站数据”——点击“清除数据”就能清除所有 Cookie 了。
Session
Session简介
Session 是服务器为访问用户所创建并维护的一个会话对象,是存放在服务器的一种数据。
SessionID编号
在服务器创建对象的同时,会为该对象产生一个唯一的编号,这个编号称为 SessionID。服务器将 SessionID 通过 Cookie 存放在客户端中,当浏览器再次访问该服务器的时候,服务器可以通过该 SessionID 检索到以前的 Session 对象,再让其访问。
网站登录机制
登录网站时,账号密码通过验证后,服务器返回 Cookie 让浏览器带上,这个 Cookie 里面就保存了 SessionID 的信息。用户在站内的 Web 页间跳转所产生的新请求都会携带 Cookie 发送给服务器。服务器会根据发送过来的 Cookie 中的 SessionID 查找出服务器中对应的 Session 对象,进而找到会话。在整个过程中 Session 对象不会丢失,而是在整个用户会话中存在下去,但一般都会有个时间限制,可以自行设置(默认30分钟),超时后会进行销毁。Session 对象被毁掉后,当前的 Cookie 也就失效了,就会返回登录页面,要求重新登录以获取新的 Cookie。如果 Session 对象还未被销毁,则当前的 Cookie 还是有效的,那么服务器就判断用户当前已经登录了,返回请求的页面信息,这样我们就可以看到登录之后的页面。
建立会话
手动拷贝Cookie
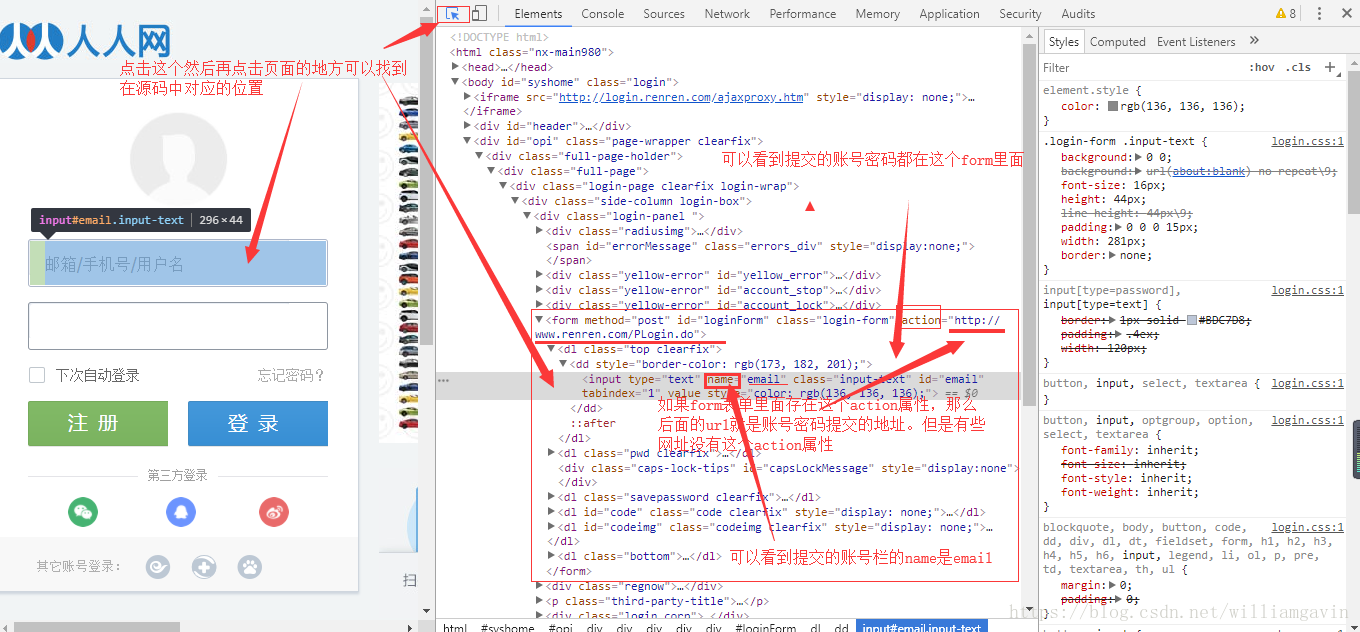
**既然服务器是通过 Cookie 来判断用户是否是登录状态,那么我们就在请求头中加入有效的 Cookie 来保持我们的会话。**这里以人人网为例,首先我们不携带Cookie去访问“我的主页”的URL,代码效果如下:
python
import requests
from fake_useragent import UserAgent
# 请求头不携带Cookie
headers = {'User-Agent':UserAgent().chrome}
# 我的主页
url ='http://www.renren.com/969371812/profile'
# 发起请求
response = requests.get(url=url, headers=headers)
# 输出响应
print(response.text)
'''
输出:
...
<li>删除过账号</li>
<li>长时间没有登录网站</li>
<li>安全原因</li>
<input type="password" id="password" name="password" error="请输入密码" class="input-text" tabindex="2"/>
<label class="pwdtip" id="pwdTip" for="password">请输入密码</label>
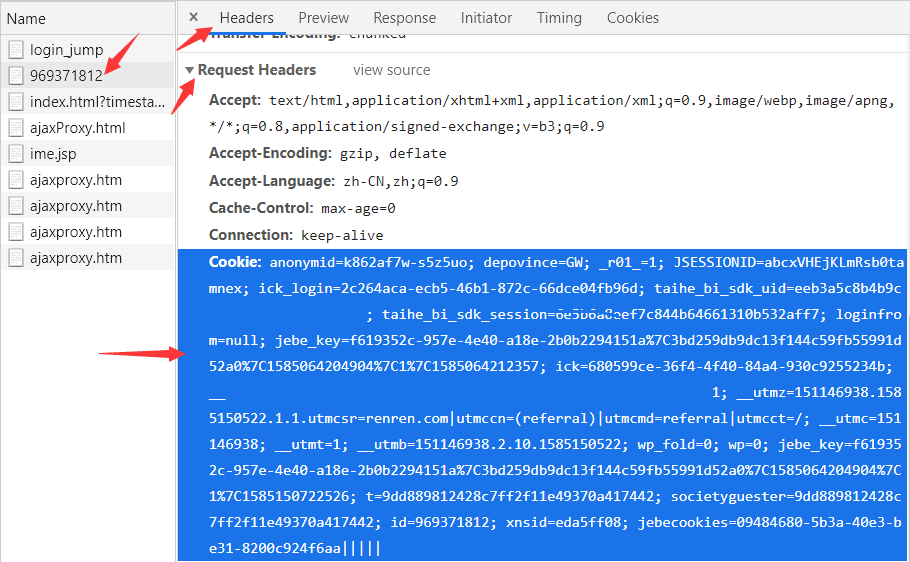
'''**可以看到上面输出,由于没有携带有效 Cookie 去访问,服务器不认识你,就把你拦截下来了,要求你输入账号、密码,那么我们就用登录后的有效 Cookies 来实现免登录。**最简单的方法就是:在登录后,访问“我的主页”页面,在开发者工具中的 Network 中找到访问“我的主页”请求,复制请求头中的 Cookie 将其粘贴到爬虫的 headers 中进行访问,就能获取到登录后的“我的主页”页面了。
python
import requests
from fake_useragent import UserAgent
headers = {
'User-Agent':UserAgent().chrome,
'Cookie':'粘贴登录后的Cookie'
}
url ='http://www.renren.com/969371812/profile'
response = requests.get(url=url, headers=headers)
print(response.text)
'''
输出:
<!Doctype html>
<html class="nx-main860">
...
<title>人人网 - 剑眉星目</title>
<meta charset="utf-8"/>
'''自动获取Cookie
可以看到上面的代码成功获取到了登录后的”我的主页“页面,这是因为我们拷贝的是刚登录生成的 Cookie,还在有效期内,一旦 Cookie 过期,程序就不能访问了,又得手动登录、手动拷贝Cookie,太过麻烦,因此我们需要更便捷的方法。首先我们分析登录的页面,使用爬虫模拟发送登录的请求,获取服务器返回的可用的 Cookie,在将 Cookie 携带在爬虫上访问”我的主页“页面:
python
import requests
from requests.utils import dict_from_cookiejar, cookiejar_from_dict
from fake_useragent import UserAgent
# 生成随机的Chrome浏览器请求头
headers = {'User-Agent': UserAgent().chrome}
# 填入账号、密码
data = {'email': '账号', 'password': '密码'}
# 登录地址
url = 'http://www.renren.com/PLogin.do'
# POST发送form表单验证身份
res = requests.post(headers=headers, url=url, data=data)
# 输出Cookie
print(res.cookies) # 输出:<RequestsCookieJar[...]>。注释:返回一个RequestsCookieJar类型的Cookie对象。
cookie_dict = dict_from_cookiejar(res.cookies) # 注释:将RequestsCookieJar类型的Cookie转换为字典类型的Cookie。
print(cookie_dict) # 输出:{'anonymid': ...}。
cookie_jar = cookiejar_from_dict(cookie_dict) # 注释:将字典类型的Cookie转换为RequestsCookieJar类型的Cookie,和上面res.cookies一样。
print(cookie_jar) # 输出:<RequestsCookieJar[...]>
# 个人主页地址
home_url = 'http://www.renren.com/974088904/profile'
# 参数cookies接收的Cookie可以是RequestsCookieJar类型,也可以是字典类型
home_res = requests.get(headers=headers, url=home_url, cookies=cookie_jar)
# 输出网页代码
print(home_res.text)
'''
输出:
<!Doctype html>
<html class="nx-main860">
...
<title>人人网 - 剑眉星目</title>
<meta charset="utf-8"/>
'''获取cookie代码
cookie = ';'.join([i.decode().split(";")[0] for i in response.headers.getlist('Set-Cookie')])会话对象
上面的代码通过一些方法来获取、设置 Cookie,也成功的获取到登录后的“我的主页页”面了。还不够,requests 库的还有高级用法,可以让我们更加便捷的获取到登录后的页面,那就是**“会话对象”**。
保持会话
会话对象具有主要的 Requests API 的所有方法,能帮我们自动保存、处理Cookie,而且能够跨请求保持某些参数,前提是通过对象级别的属性进行赋值,而方法级别的参数不会被跨请求保存。案例代码如下:
python
import requests
# 创建一个会话对象session
session = requests.Session()
# 通过cookies参数设置Cookie(可以接收RequestsCookieJar类型或字典类型)
q1 = session.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
print(q1.text) # 输出:{"cookies": {"from-my": "browser"}}
q2 = session.get('http://httpbin.org/cookies')
print(q2.text) # 输出:{"cookies": {}}。注释:方法级别的参数不会被跨请求保存。
# 通过会话对象session的cookies属性设置Cookie(只能接收RequestsCookieJar类型)
session.cookies = requests.utils.cookiejar_from_dict({'sessioncookie': '1234567890'})
q3 = session.get('http://httpbin.org/cookies')
print(q3.text) # 输出:{"cookies": {"sessioncookie": "1234567890"}}
q4 = session.get('http://httpbin.org/cookies')
print(q4.text) # 输出:{"cookies": {"sessioncookie": "1234567890"}}
# 通过会话对象session的headers属性设置Cookie
session.headers = {
"Cookie": "SessionID=123"
}
q5 = session.get('http://httpbin.org/cookies')
print(q5.text) # 输出:{"cookies": {"SessionID": "123"}}
q6 = session.get('http://httpbin.org/cookies')
print(q6.text) # 输出:{"cookies": {"SessionID": "123"}}明白了会话对象的使用方法,我们还是拿上面的人人网例子,使用会话对象进行重写:
python
import requests
from fake_useragent import UserAgent
# 创建会话对象session
session = requests.session()
# 生成随机的Chrome浏览器请求头固定到会话对象的请求头
session.headers = {'User-Agent': UserAgent().chrome}
# 填入账号、密码
data = {'email': '972305453', 'password': '5335915'}
# 登录地址
url = 'http://www.renren.com/PLogin.do'
# 通过会话对象session发起POST请求发送form表单验证身份
res = session.post(url=url, data=data)
# 个人主页地址
home_url = 'http://www.renren.com/974088904/profile'
# 由于使用了会话对象session,访问个人主页时会自动将上面res响应头中的Cookie添加到请求头中
home_res = session.get(url=home_url)
# 输出网页代码
print(home_res.text)
'''
输出:
<!Doctype html>
<html class="nx-main860">
...
<title>人人网 - 剑眉星目</title>
<meta charset="utf-8"/>
'''性能提升
**可以看到使用了会话对象,不仅保持了会话,还简化了代码,可谓是一举两得,但其实还有一得,就是性能提升。**这里我们进行一项测试,比较 requests 和 session 向同一主机发送 100 个请求的效率,代码如下:可以看到 requests 的耗时是 session 耗时的4倍多,想知道其原因,还得回到网络协议上来。首先我们都知道,HTTP 请求是建立在 TCP 连接上面的,也就是说发送 HTTP 请求前会进行一个“三次握手”的操作来建立 TCP 连接,如果使用 requests 发送 HTTP 请求,那么每次发送 HTTP 请求前都会进行一个“三次握手”的操作来建立 TCP 连接,这会严重降低访问的效率;如果首先就初始化一个 Session 会话,每次 HTTP 请求都通过 Session 来发起,那么 Session 只会在第一次发起 HTTP 请求前,进行一个”三次握手“的操作建立 TCP 连接,后续的 HTTP 请求都将会复用前面建立的TCP连接,从而带来显著的性能提升,大大提高请求速度。
python
import time
import requests
time_1 = time.time()
# 使用requests进行100次请求
for _ in range(100):
requests.get('https://www.baidu.com')
time_2 = time.time()
# 使用session进行100次请求
session = requests.session()
for _ in range(100):
session.get('https://www.baidu.com')
time_3 = time.time()
print(f'requests耗时{time_2-time_1:.2f}秒!') # 输出:requests耗时21.79秒!
print(f'session耗时{time_3-time_2:.2f}秒!') # 输出:session耗时5.34秒!警告
复用底层 TCP 连接有两个前提:其一是从始至终所有的请求都通过同一个 Session 会话发起访问,且访问的对象都是同一个域名的网站;其二是请求头中 Connection 的状态不能为 close,否则每次请求还是会重新去建立 TCP 连接。
结束会话
Session 会话虽然能复用 TCP 连接,但在程序运行完后,TCP 连接不会马上断开,要等一会才释放,如果想要提前释放可以使用 session.close() 方法来结束会话,或者在请求头中设置 Connection 的状态为 close,也能在会话结束后马上断开 TCP 连接。
重写会话
使用 Session 会话对象可以像 requests 那样设置 timeout 超时时间,例如下面的代码:
python
import requests
session = requests.session()
res1 = session.get('https://www.baidu.com', timeout=2) # 注释:正常响应的网址,设置timeout超时时间2秒。
print(res1) # 输出:<Response [200]>
res2 = session.get('https://www.httpbin.org/delay/5') # 注释:延迟5秒响应的网址。
print(res2) # 输出:<Response [200]>**可以看到会话对象发起的 HTTP 请求中,只有设置了 timeout 参数的请求才会起作用,而没有设置该参数的请求如果出现网络问题就很容易导致阻塞,降低采集效率,但如果每个请求都设置 timeout 参数又太麻烦,这时我们就可以重写会话对象,为所有经过该对象发起的 HTTP 请求设置统一的 timeout 参数。**代码如下:
python
import requests
# 定义一个sessions类继承requests.Session类
class sessions(requests.Session):
# 重写request方法
def request(self, *args, **kwargs):
# 设置连接超时时间、读取超时时间都为2秒
kwargs.setdefault('timeout', (2, 2))
# 返回设置后的对象
return super(sessions, self).request(*args, **kwargs)
# 创建一个session对象
session = sessions()
res1 = session.get('https://www.baidu.com') # 注释:正常响应的网址
print(res1) # 输出:<Response [200]>
res2 = session.get('https://www.httpbin.org/delay/5') # 注释:延迟5秒响应的网址
print(res2) # 报错:requests.exceptions.ReadTimeout(读取超时)