哨兵模式、缓存设计方案
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
哨兵模式
前面我们讲解了主从复制,以及如何使用配置文件和命令搭建了一个一主二从的Redis伪集群,但是这样搭建方法在工程项目上不是会用到的,原因如下:
- 使用命令搭建的集群,当主节点挂掉后,整个集群的写服务就停掉了;
- 如果主节点一时半会不能恢复,但整个集群又需要提供写服务,那么就必须手动执行命令
salveof no one重新指定一个主节点,麻烦费时,还会造成一段时间内服务不可用。
所以为了能更好的向外部提供Redis集群的读写服务,必须要学习哨兵模式。前面我们搭建的Redis集群属于主从手动切换模式,而哨兵模式简单讲就是主从自动切换模式。
模式详解
哨兵模式:哨兵就是一个独立运行的进程,在Redis集群中,哨兵每隔一断时间向节点发送ping包,通过是否在指定时间范围内(cluster-node-timeout)响应来判断其是否故障,如果响应超出了指定时间,就认为该节点已断开和集群的连接;如果是主节点故障了,会进行选举投票,投票数最多的从节点转换为主节点。
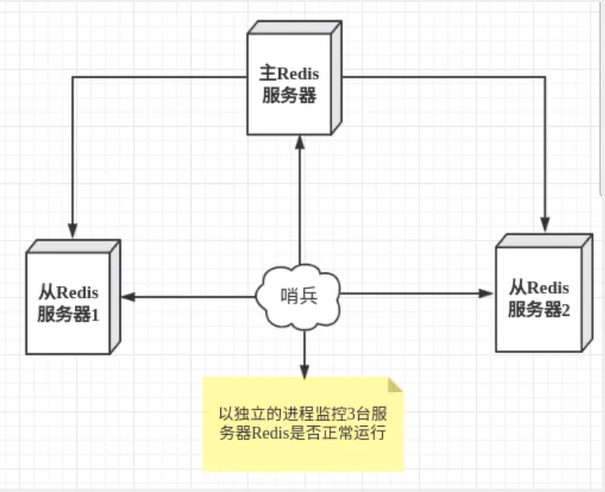
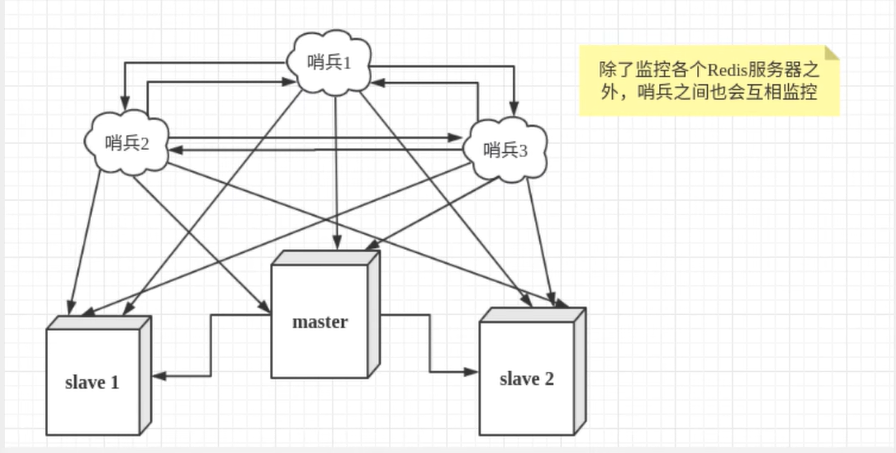
上面展示的是单哨兵模式,已经说过哨兵是一个单独的进程,但如果哨兵进程挂了,这样就无法对整个Redis集群进行监控了,为此出现了多哨兵模式,即哨兵除了监控Redis实例,哨兵之间也会互相监控。
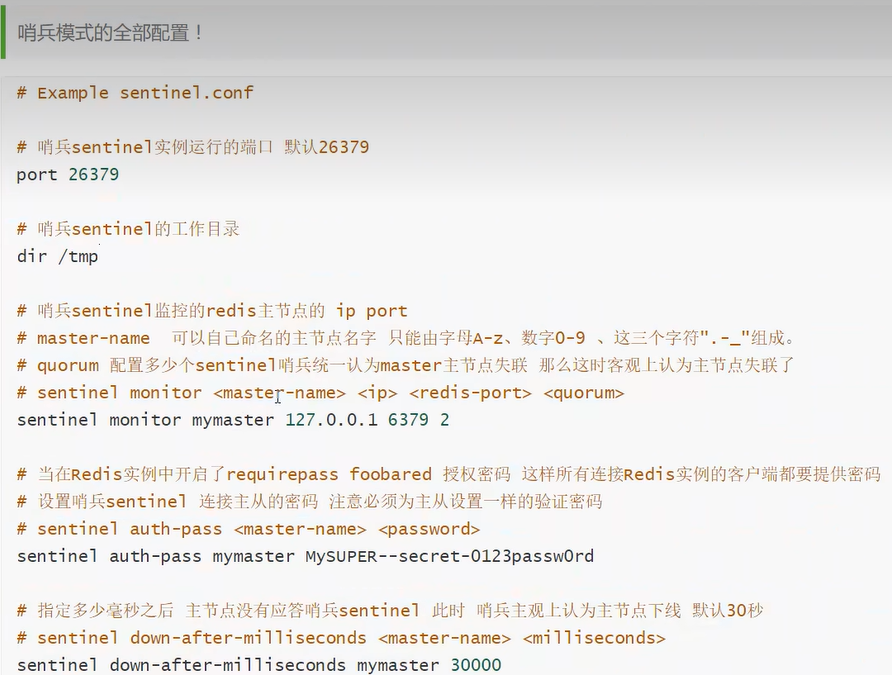
文件配置
我们在Redis的目录下面新建一个名称为 sentinel.conf 的文件内容如下:
sentinel monitor myredis 127.0.0.1 6379 1sentinel monitor固定写法;myredis哨兵名称;127.0.0.1 6379被监控的主机ip及端口;1代表主节点挂掉后,重新进行选举投票选出主节点。
注意 sentinel.conf 的文件名称是不可改变的,而配置内容也不止上面一行,详细的配置如下:
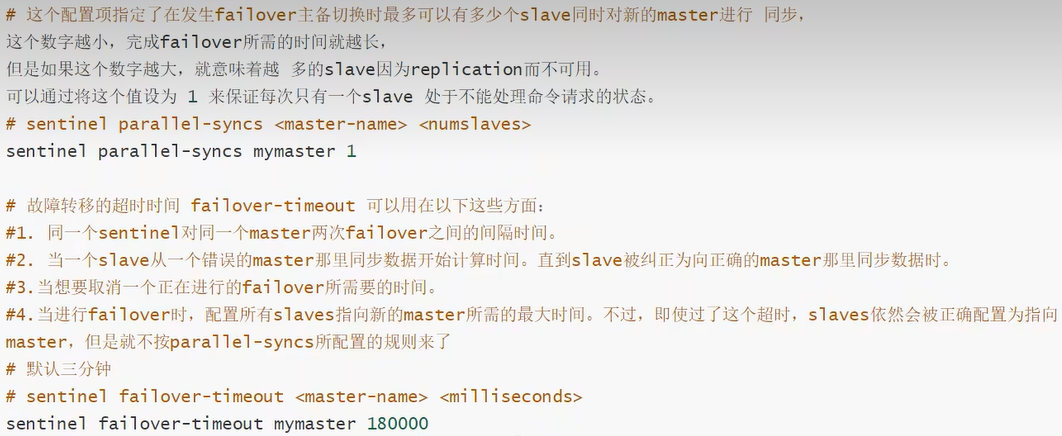

启动哨兵
现在,我们就要来启动我们的哨兵,命令如下:
redis-sentinel /redis目录/sentinel.conf- redis-sentinel就是Redis提供的哨兵模式可执行文件。
执行该命令后,可以看到Redis处于哨兵模式的运行状态:
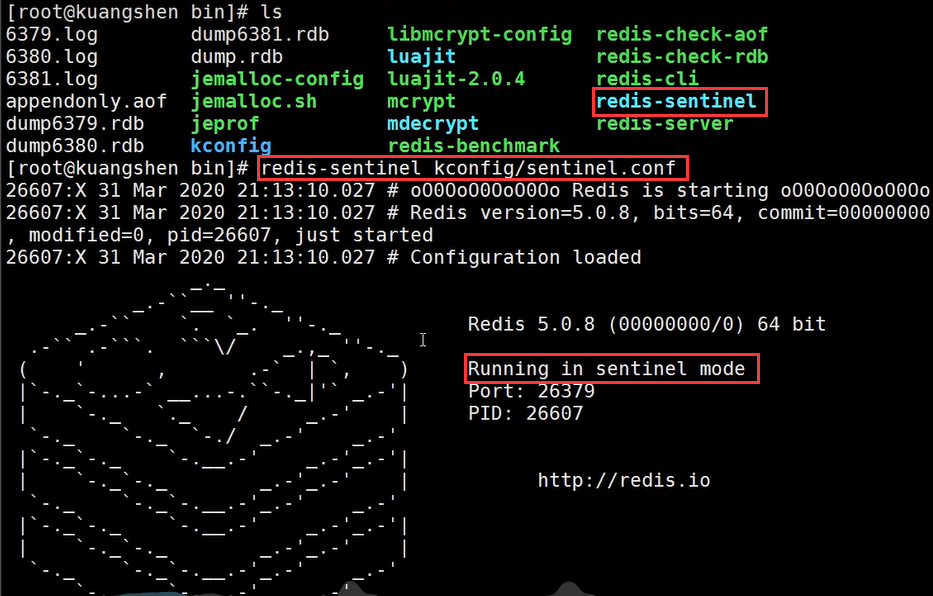
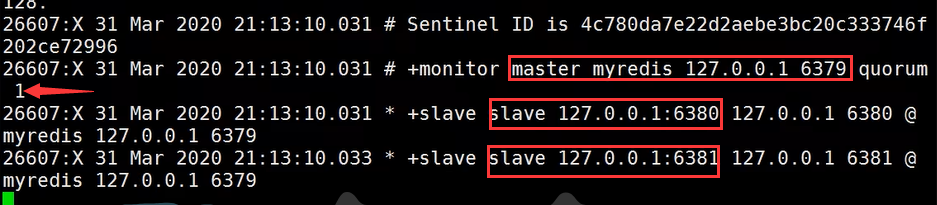
在下方还可以看到,哨兵打印出了6379主节点和1个投票数、以及6380、6381两个从节点:
主从切换
现在我们关闭掉6379主节点:

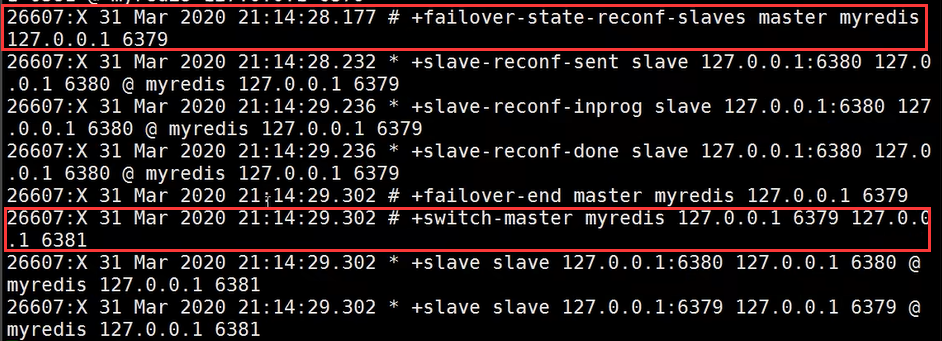
过一会,哨兵发现6379主节点连不上了,开始进行选举,选出6381成为新的主节点:
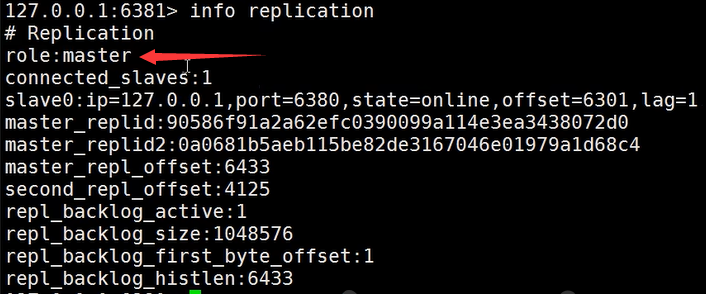
这时再回到6381节点查看信息,可以到该节点就是新的主节点了:
若此时我们再去开启6379节点,哨兵发现后新的节点进来后,就会输出 转换为从节点 的内容:

现在我们去查看6379节点信息时,它已经是从节点了:
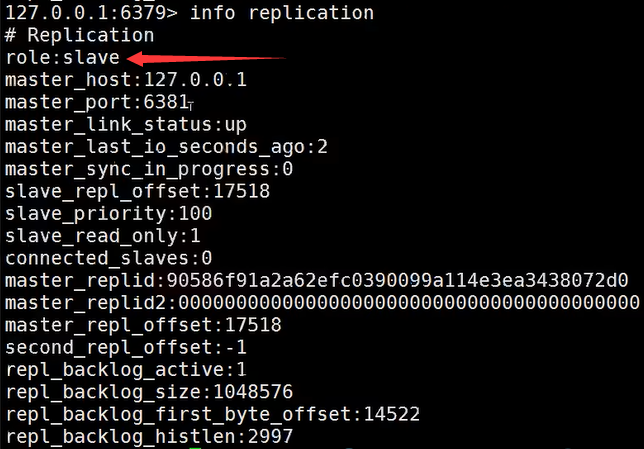
?> 提示:哨兵模式如果发现旧的主节点回来了,只能归并到新的主节点下,当中从节点。
哨兵特点
优点:哨兵模式是主从模式的升级,继承了主从配置全部优点,主从可以自动切换,故障可以自动转移,且系统可用性更好。
缺点:集群容量一旦达到上线,Redis的在线扩容就会变得十分麻烦;哨兵模式的配置有很多,配置起来很麻烦的。
缓存设计方案
**目前大多数公司的存储都是MySQL + Redis:其中MySQL作为主存储,Redis作为辅助存储被用作缓存,加快访问读取的速度,提高性能。**因为Redis对内存要求比较高,而且存储容量肯定要比磁盘少很多,要存储大量数据,只能花更多的钱去购买内存,在一些不需要高性能的地方造成浪费,因此不能把所有数据都放在Redis,MySQL偏向于存数据,Redis偏向于快速取数据,最好把热门数据放Redis,基本数据放MySQL。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
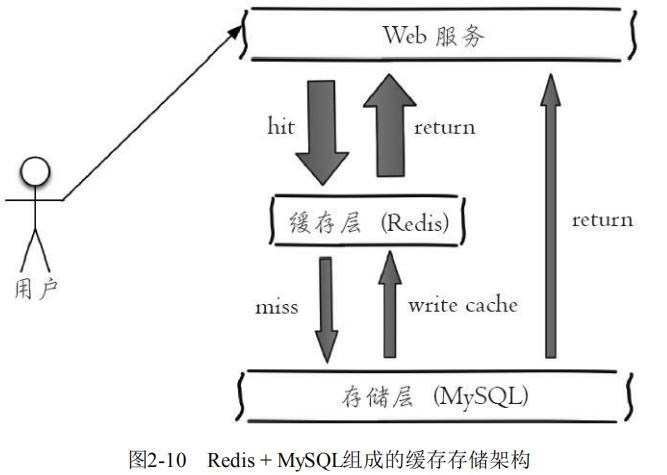
缓存穿透
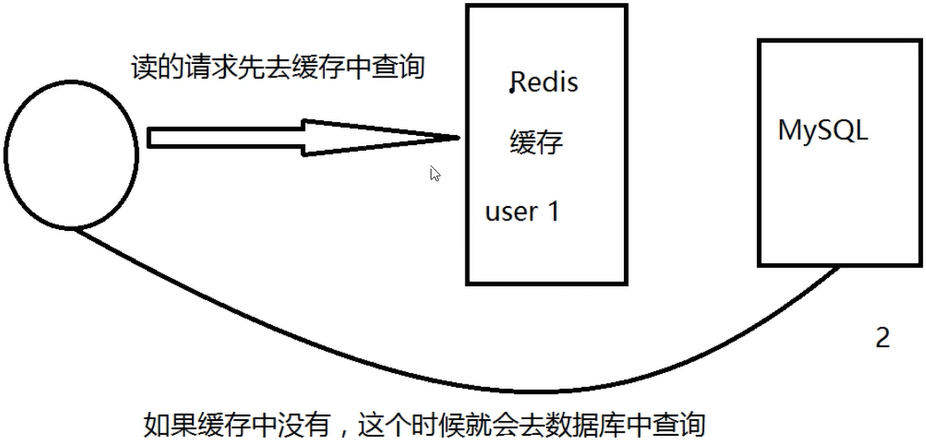
缓存穿透场景:用户在网站上查询数据,首先会去到缓存层当中查询,如果缓存层当中没有查询到该数据,就会去到存储层查询。一旦这样的情况出现很频繁时,就会给存储层造成很大的压力,就相当于出现了缓存穿透。(商品秒杀)
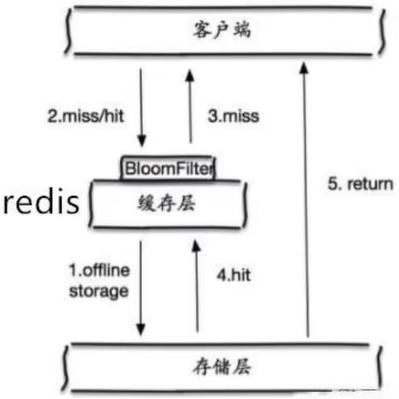
解决方案:布隆过滤器,一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。
缓存击穿
缓存击穿场景:当一个key成为了爆热点,在不停的大并发集中对这一个点进行访问,当这个key失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。(明星出现社会性事件)
解决方案:
- 延长热点数据过期时间;
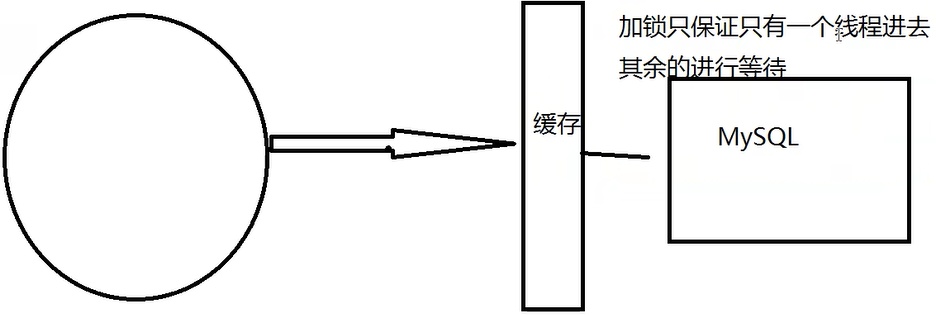
- 使用分布式锁(互斥锁),保证对于每个key同时只有一个线程去查询后端的服务,其他没有获得分布式锁的线程只能等待,这样就将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
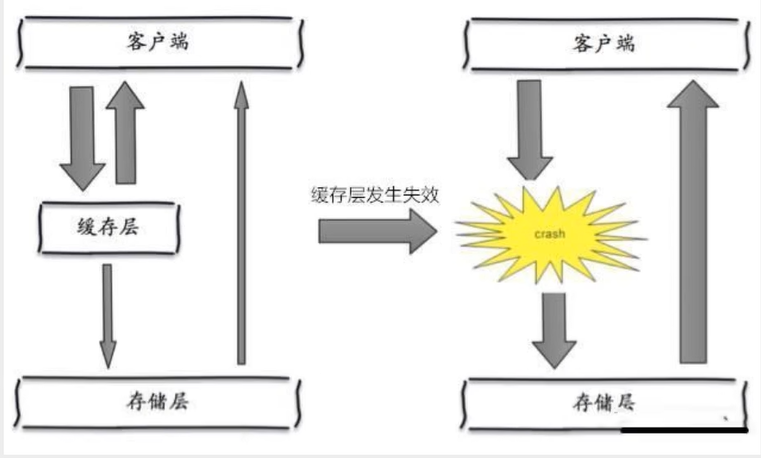
缓存雪崩场景:在某一个时间缓存集体失效,所有的请求全部打在了存储层上,就很可能造成数据库的崩溃。(缓存服务器宕机)
解决方案:
- 增加Redis节点,一个节点挂掉后,其他的还可以继续工作,就是Redis集群;
- 使用分布式锁(互斥锁),保证对于每个key同时只有一个线程去查询后端的服务,其他没有获得分布式锁的线程只能等待,这样就将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
- 服务降级,例如双十一的时候,一些服务是被禁用的,例如退款、查看评论信息等,目的就是为了腾出更多的资源将更多的商品数据放到缓存当中,保证用户的基本购物流程。
三者区别
缓存穿透:很多请求缓存层查不到,去到存储层查询。
缓存击穿:某个点的缓存过期后,来了巨大的请求去到存储层查询。
缓存雪崩:缓存层失效或者出现问题,所有的请求去到了存储层。