Selenium自动化
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
Selenium 是一款用于自动化测试的工具,主要用于模拟用户在浏览器中的操作,以测试 Web 应用程序的功能和性能。简单来说,用户在浏览器上的输入、点击、滑动等所有的操作,Selenium 同样也能做。
准备工作
安装Selenium
Selenium 是一个第三方的开源工具和库,执行下面命令进行安装:
pip install selenium安装Driver
安装好了 Selenium 后,这里还需要安装一个 Driver 来驱动浏览器。为了方便理解,打个比方,浏览器好比汽车,Selenium 就是司机,驾驶汽车,Driver 就是车钥匙,来启动汽车。
Chromedriver
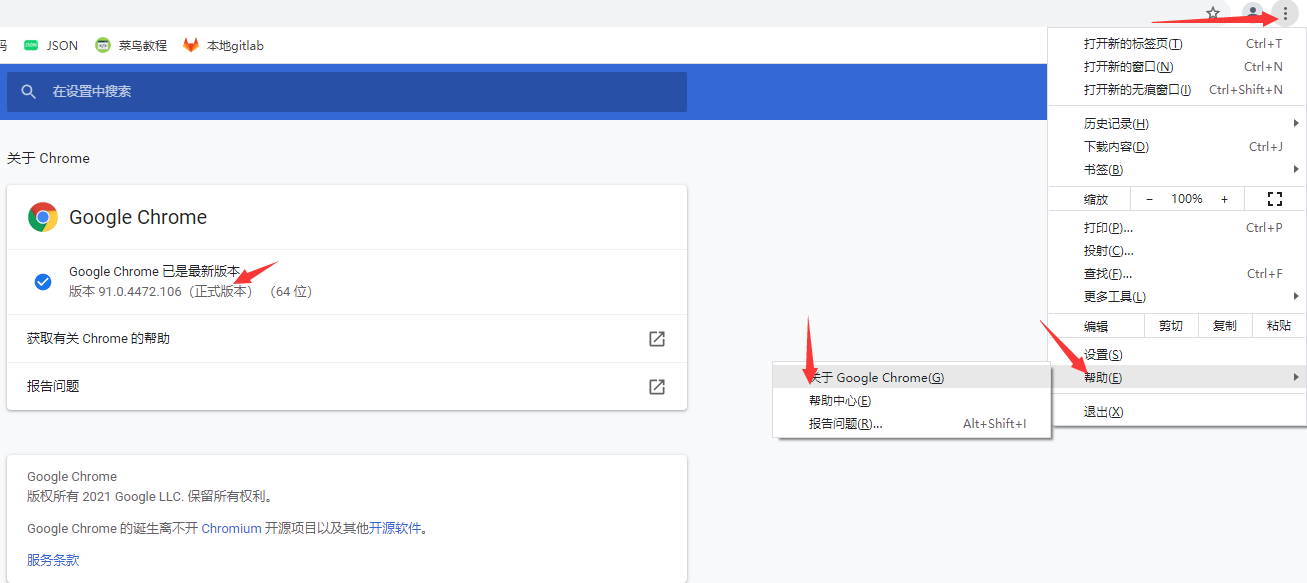
首先通过点击,菜单——帮助——关于 Google Chrome,获取 Chrome 浏览器版本:
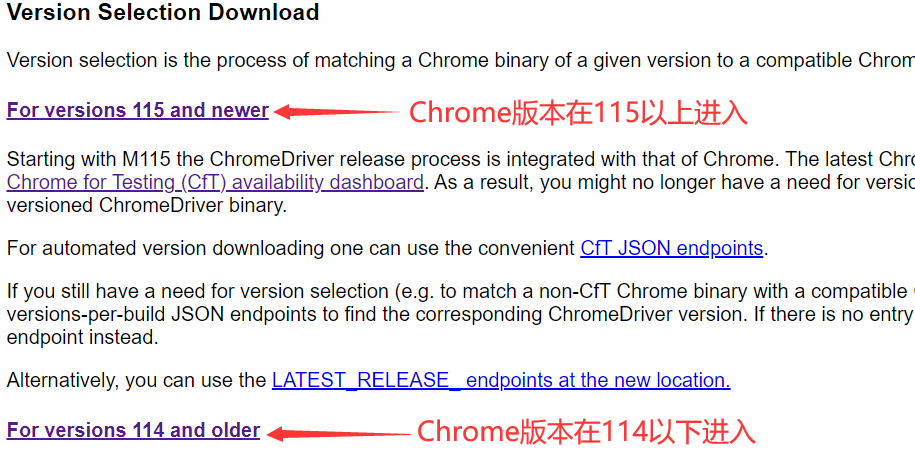
进入链接 https://chromedriver.com/,根据 Chrome 浏览器版本再进入相应链接:
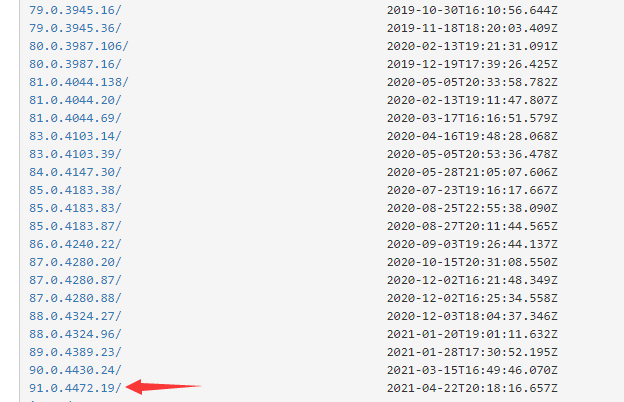
下载 Chrome(谷歌浏览器)的 Chromedriver 驱动程序,注意一定要选择和 Chrome 版本相同或最相近的链接,否则使用 Chromedriver 操作版本不匹配的 Chrome 可能会产生五花八门的错误:
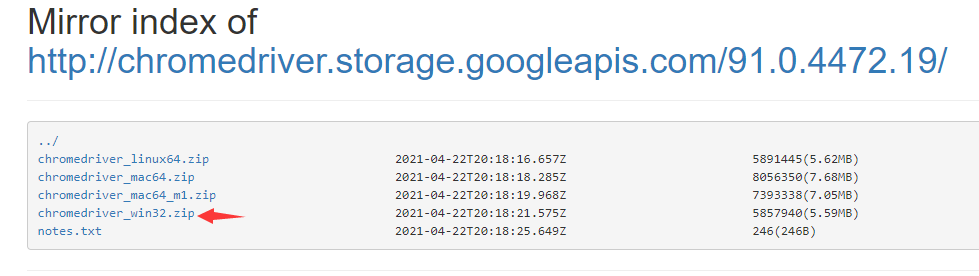
选择符合自己电脑操作系统的文件版本进行下载,将下载的文件解压到环境变量下的路径,或者将解压的路径添加到环境变量中,或者通过 executable_path 参数来指定 Chromedriver 文件的路径:
Geckodriver
**Geckodriver 是 Firefox(火狐浏览器)的驱动程序。**安装步骤和上面安装 Chromedriver 一样,访问链接:https://github.com/mozilla/geckodriver/releases ,选择符合自己电脑操作系统的版本的 Geckodriver 进行下载,将下载的文件解压到环境变量下的路径,或者将解压的路径添加到环境变量中,或者通过 executable_path 参数来指定 Geckodriver 文件的路径。
**需要注意的是,Firefox 占用的内存量会随时间不断增加,所以应该考虑定期重启 Firefox,让它维持在一个固定的内存占用量。**Firefox 设置快速缓存(默认情况下,Firefox 只会使用系统内存而不会使用快速缓存),操作步骤:
- 打开 Firefox 浏览器,并在地址栏中输入
about:config,在出现的警告页面上,点击“我了解此风险”按钮,以进入配置页面。 - 在配置页面的搜索栏中输入
browser.cache.memory.enable,双击browser.cache.memory.enable条目,将其值更改为true,以启用内存缓存。 - 在配置页面中右键单击空白区域,选择“新建” > “整数”,输入
browser.cache.memory.capacity,然后点击确定,为browser.cache.memory.capacity输入一个整数值,这个值取决于你计算机的物理内存大小。例如,如果你的内存大小为 256MB,你可以输入 4096;如果是 512MB,则输入 8192。如果你的内存较小,建议升级内存。如果要恢复默认设置,可以将browser.cache.memory.capacity的值改为 -1。
[!ATTENTION]
使用 Chromedriver 驱动 Chrome 浏览器去访问部分网站,其接口可能会状态码错误,并返回空白页,而使用 Geckodriver 驱动 Firefox 浏览器访问没有问题。虽然后面所有的 Selenium 例子都是基于 Chromedriver 驱动和 Chrome 浏览器写的,但不建议使用 Chromedriver 驱动和 Chrome 浏览器,推荐 Geckodriver 驱动和 Firefox 浏览器。
基本操作
声明对象
python
# 导入selenium的浏览器驱动接口webdriver
from selenium import webdriver
# 导入selenium的chrome浏览器的Service对象
from selenium.webdriver.chrome.service import Service
# 通过executable_path参数指定“驱动文件.exe”实例化一个service对象(如果“驱动文件.exe”在环境变量下,则不用写)
service = Service(executable_path=r'路径\驱动文件.exe')
# selenium支持非常多的浏览器,如Chrome、Firefox、Safari等(运行前提是环境变量中存在该浏览器的驱动)
browser = webdriver.Chrome(service=service)
browser = webdriver.Firfox(service=service)
browser = webdriver.Safari(service=service)
browser = webdriver.PhantomJS(service=service)配置选项
**使用 Chromedriver 驱动 Chrome 浏览器爬取网站信息时,默认情况下就是一个普通的纯净的 Chrome 浏览器,不过我们还需要对 Chrome 添加一些配置,以模拟用户使用浏览器的行为。而 Options 就是一个配置属性的类,通过添加启动参数(add_argument)、添加实验性质的设置参数(add_experimental_option)等,来配置 Chrome 启动时的属性。**常用的配置参数如下:
python
# 导入chrome中Options配置选项
from selenium.webdriver.chrome.options import Options
# 建立Option类对象
chrome_options = Options()
# 浏览器运行默认显示图形用户界面(GUI),--headless不显示图形用户界面(无头模式)
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 设置默认编码为utf-8
chrome_options.add_argument('lang=zh_CN.UTF-8')
# 设置头部user-agent
chrome_options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
# 设置代理(注意,=两边不能有空格)
chrome_options.add_argument("--proxy-server=http://202.20.16.82:10152")
# 禁止加载图片
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 禁止加载JS(注意,禁用JS加载可能导致页面无法正确加载或交互)
chrome_options.add_argument('--disable-javascript')
# 设置用户数据目录保存在指定的selenium目录中,这可以帮助在多次运行脚本时保留浏览器的状态,例如已登录的会话、浏览历史、缓存等。这对于某些应用场景,比如需要维持登录状态的测试或爬虫任务,是很有用的。(注意,使用用户数据目录的同时,可能需要额外处理一些安全性和隐私性的问题,尤其是在共享机器上运行脚本时)
chrome_options.add_argument("user-data-dir=selenium")
# AutomationControlled是一个启用自动化控制特性的Blink功能,设置通过禁用Blink引擎的自动化控制特性,可以减少自动化被检测的可能性(反反爬配置)
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
# 设置通过排除Chrome的enable-automation开关,试图防止被网站检测到使用自动化工具(反反爬配置)
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用Chrome的自动化扩展,自动化扩展通常是一些网站用来检测自动化工具的手段之一,禁用它可以降低被检测的概率(反反爬配置)
chrome_options.add_experimental_option('useAutomationExtension', False)
# 禁止加载JS和图片
prefs = {
'profile.default_content_setting_values': {
'javascript': 2,
'images': 2,
}
}
chrome_options.add_experimental_option('prefs', prefs)
# 创建浏览器对象
browser = webdriver.Chrome()
# 启用配置(上面所有的配置不启动,就无效)
browser = webdriver.Chrome(options=chrome_options)
# 设置代理
browser = webdriver.Chrome(seleniumwire_options={'proxy': {'http': f'http://{proxy}'}}, options=self.chrome_options)[!ATTENTION]
Selenium的反反爬配置对于绕过一些简单的爬虫检测机制可能是有效的,但并不是一劳永逸的解决方案。一些网站可能会有更先进的检测机制来检测自动化,因此没有绝对的方法来彻底防止所有屏蔽检测,最好的策略是不断监测目标网站的变化,并相应地调整你的自动化脚本。
爬取网页
首先我们写一个简单爬取网页的案例,运行代码后,会有 Chrome 浏览器弹出(有头模式),访问页面:
python
# 导入selenium驱动接口webdriver
from selenium import webdriver
# 传入service对象并初始化Chrome浏览器
browser = webdriver.Chrome()
# get方法访问url
browser.get('https://www.taobao.com')
# page_source方法输出网页的源代码
print(browser.page_source)
# 只会关闭浏览器的活动窗口,如果浏览器只有一个窗口,则退出WebDriver会话(释放浏览器的驱动程序及相关资源)
browser.close()
# 关闭浏览器的所有窗口,即退出WebDriver会话(释放浏览器的驱动程序及相关资源)
browser.quit()
'''
输出:
<title>淘宝网 - 淘!我喜欢</title>
<meta name="spm-id" content="a21bo" />
<meta name="description" content="淘宝网 - 亚洲较大的网上交易平台,提供各类服饰、美容、家居、数码、话费/点卡充值… 数亿优质商品,同时提供担保交易(先收货后付款)等安全交易保障服务,并由商家提供退货承诺、破损补寄等消费者保障服务,让你安心享受网上购物乐趣!" />...
注释:如果报错,请先检查本机是否下载了Chromedriver,再检查Chrome和Chromedriver版本是否兼容,最后检查文件是否在环境变量或者通过executable_path参数指定了驱动exe的路径。
'''警告
程序调用Chromedriver.exe文件时,会产生一个Chromedriver.exe进程来操控Chrome,如果程序代码执行过程中异常退出,也就是说在执行 browser.quit() 方法前报错退出了,那么浏览器的驱动程序及相关资源不会得到释放,内存中还会残留无用的Chromedriver.exe进程。因此最后可以添加 os.system('taskkill /im chromedriver.exe /F') 和 os.system('taskkill /im chrome.exe /F') 来确保结束所有的Chrome和Chromedriver进程。
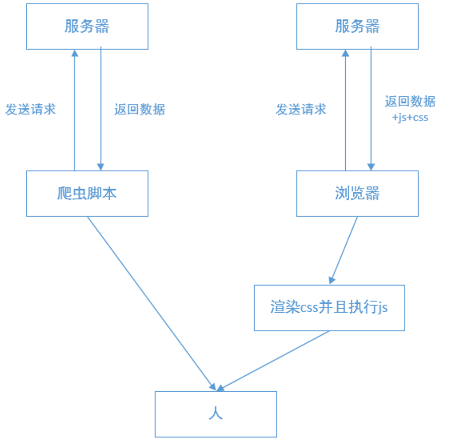
含JS网页
上面我们通过 Selenium 拿到了淘宝网的网页代码,有人会问这个和通过 requests 第三方库来获取网页代码有什么区别吗?我们来看下面一个案例:可以看到,通过 requests 抓取的网页代码和我们在浏览器中看到的网页代码不一样,这是因为网站使用了 JS 来处理网页,浏览器所展示的页面则是经过 JS 处理后的 HTML 文档,而 requests 无法运行 JS 代码,因此获取的是服务器发送过来的原始 HTML 文档。
python
import requests
from fake_useragent import UserAgent
# 网站url
url = 'https://www.hapag-lloyd.cn/zh/home.html#hal-map'
# 请求头
headers = {'user-agent': UserAgent().random}
# 发送请求
response = requests.get(url=url, headers=headers)
# 输出响应
print(response.text)
'''
输出:
<!DOCTYPE html>
<html><head>
# 下面就是未加载JS的数据,从中我们获取不到任何有用的信息
...window.kGv=!!window.kGv;try{(function(){(function LJ(){var L=!1;function z(L){for(var s=0;L--;)s+=_(document.documentElement,null);return s}function _(L,s){var z="vi";s=s||new I;return oJ(L,function(L){L.setAttribute("data-"+z,s.OS());return _(L,s)},null)}function I(){this.iz=1;this.SO=0;this.Ll=this.iz;this.SL=null;this.OS=function()
...</html>
'''现在我们用 Selenium 来获取网页代码:可以看到,Selenium 获取到了经过 JS 处理后的网页代码,这因为 Selenium 是驱动浏览器去请求网页,而浏览器会自行加载并执行 JS,因此我们可以拿到 JS 处理后的 HTML 文档。
python
import time
# 导入webdriver浏览器驱动
from selenium import webdriver
# get方法访问传入url
browser.get('https://www.hapag-lloyd.cn/zh/home.html#hal-map')
# 给加载JS留出时间
time.sleep(3)
# page_source方法输出网页的源代码
print(browser.page_source)
# 关闭浏览器
browser.close()
'''
输出:
<!DOCTYPE html>
<html><head>
...冷藏货物
<a href="/zh/products/cargo/dg/safety-first.html" class="hal-rtl--alt" btattached="true">
...</html>
'''总结一下,普通的爬虫只是负责拿着你给的 URL 传递一些参数来获取网页源码,它们不能运行 JS,也就无法对服务器需要验证的参数进行加密,从而导致服务器拒绝你的请求,给你返回一个不是你所期望的网页内容,这时 JS 也就起到了反爬的作用。
警告
目前许多网站的反爬的方向就是识别非浏览器客户端,而 Selenium 恰恰是让真正的浏览器去执行请求和操作,但对于服务端来说,仍然有很多检测点,来检测是否是Selenium自动化浏览器,所以Selenium并不是万能的。
[!ATTENTION]
Selenium虽然能获取经过JS处理后的网页,但是Selenium驱动的浏览器也会加载其他的网页资源,例如CSS样式、Font字体,因此相比其他的第三方库直接请求数据的效率要低很多了,另外浏览器本身也要占据一部分的系统资源,要是开几十个浏览器窗口去获取网页源码,作为爬虫确实比较慢了,而且资源消耗高、稳定性差。
定位元素
Selenium 可以完成模拟点击、输入框输入文字等各种操作,完成这些操作前需要定位元素,而 Selenium 提供了一系列查找元素的方法,利用这些方法我们可以获取想要的节点。
By是 Selenium 内置的一个模块,提供了多种方式来定位网页上的元素。.find_element(By..., '...')通过节点属性定位,返回单个节点。.find_elements(By..., '...')通过节点属性定位,返回多个节点组成的列表。
python
# 导入Selenium内置的By模块
from selenium.webdriver.common.by import By
# 选择name为q的单个节点
element = browser.find_element(By.NAME, 'q')
# 选择ID为q的单个节点
element = browser.find_element(By.ID, 'q')
# 利用css选择器选择id为q的单个节点
element = browser.find_element(By.CSS_SELECTOR, '#q')
# 利用xpath选择器选择id为q的单个节点
element = browser.find_element(By.XPATH, '//*[@id="q"]')
# 查找a标签文本内容为“下一页”的单个节点
element = browser.find_element(By.LINK_TEXT, '下一页')
# 利用css选择器选择所有class为bd节点下面的所有li节点
elements = browser.find_elements(By.CSS_SELECTOR, '.bd li')
# 利用xpath选择器所有class为bd节点下面的所有li节点
elements = browser.find_elements(By.XPATH, '//*[@class="bd"]/li')元素属性
获取节点的各种属性:
python
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
# 定位到id为zh-top-link-logo的节点
logo = browser.find_element_by_id('zh-top-link-logo')
# 输出logo节点
print(logo) # 输出:<selenium.webdriver...>
# 输出logo节点的class属性
print(logo.get_attribute('class')) # 输出:zu-top-link-logo
# text属性获取节点的文本内容
print(logo.text) # 输出:提问
# tag_name属性获取节点的标签名称
print(logo.tag_name) # 输出:button请求操作
操作Cookie
通过 Selenium 获取、添加、删除 Cookie:
python
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
# 获取所有的cookies
print(browser.get_cookies()) # 输出:[{'domain': ...]
# 添加一个cookies
browser.add_cookie({'name':'name','value':'germey'})
print(browser.get_cookies()) # 输出:[{'domain': ... {'name': 'name', 'value': 'germey'}]
# 删除所有的cookies
browser.delete_all_cookies()
print(browser.get_cookies()) # 输出:[]模拟运行JS
Selenium 还可以通过 execute_script 方法来模拟运行 JS:
python
# 将进度条下拉到最底部
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 弹出alert提示框,内容是(To Bottom)
browser.execute_script('alert("To Bottom")')
# 点击id属性为su的按钮
element = browser.find_element_by_id("su")
driver.execute_script("arguments[0].click();", element)
# 获取id为nice元素的title属性的值
js='document.getElementById("nice").getAttribute("title")'
browser.execute_script(js)
# 修改id为nice元素的title属性的值
js='document.getElementById("nice").title="测试"'
browser.execute_script(js)
# 反反爬js代码
browser.execute_cdp_cmd(
# CDP命令,表示要添加一个新脚本,并在每个新加载的页面中执行。
'Page.addScriptToEvaluateOnNewDocument',
# 通过webdriver控制浏览器时,浏览器的里面navigator对象的webdriver属性的值为True,因此许多网站就通过该属性进行反爬,所以这里将webdriver属性改为undefined,来尝试规避一些检测WebDriver的手段。
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'}
)更换代理IP
Selenium 结合 Firefox(火狐浏览器)执行下面 JS 代码可以在,浏览器运行的过程中更换代理IP:
python
# 代理IP
proxy = '182.105.201.71:9000'
# Firefox设置页面
browser.get("about:config")
# js代码
setupScript = '''
var prefs = Components.classes["@mozilla.org/preferences-service;1"].getService(Components.interfaces.nsIPrefBranch);
prefs.setIntPref("network.proxy.type", 1);
prefs.setCharPref("network.proxy.http", "%s");
prefs.setIntPref("network.proxy.http_port", "%s");
prefs.setCharPref("network.proxy.ssl", "%s");
prefs.setIntPref("network.proxy.ssl_port", "%s");
prefs.setCharPref("network.proxy.ftp", "$%s");
prefs.setIntPref("network.proxy.ftp_port", "%s");
''' % (proxy.split(':')[0], proxy.split(':')[1], proxy.split(':')[0],proxy.split(':')[1], proxy.split(':')[0], proxy.split(':')[1])
# 执行js
browser.execute_script(setupScript)Iframe上下文
有时候驱动了浏览器去爬取网页,元素明明在那,浏览器中也可以看到,但就是抓取不到,page_source 输出的源码中也没有该元素,这个时候就需要检查下页面是否含有 iframe 了。所谓的 iframe 是 HTML 中的一个标签,全称是 "Inline Frame"(内联框架),它可以将一个 HTML 文档嵌入在另一个 HTML 中显示,但 Selenium 默认只在当前页面的上下文中查找元素,而无法直接访问 iframe 中的元素。如果你需要定位的元素是否在 iframe 之中,就需要先定位到相应的 iframe,切换到 iframe 上下文之后,再对元素进行定位。
python
# 定位到iframe元素
iframe = browser.find_element_by_xpath('//iframe[@id="your_iframe_id"]')
# 切换到iframe上下文
browser.switch_to.frame(iframe)
# 在iframe中查找元素
element_in_iframe = browser.find_element_by_xpath('//div[@class="your_element_class"]')
# 从当前的子iframe上下文切换到其父级iframe上下文
browser.switch_to.parent_frame()
# 从当前的子iframe上下文切换到主页面iframe上下文
browser.switch_to.default_content()建议
一个页面中可以存在多个 iframe 上下文,也可以在 iframe 页面中嵌套多级 iframe 上下文。如果我们在多级嵌套的 iframe 页面中的最里层,使用 .switch_to.default_content() 方法可以让我们切换到最外层的主页面,如果当前上下文是在主页面中,调用该方法不会产生任何效果。
等待操作
前面我们使用 Selenium 获取页面代码的例子中,使用 time.sleep 方法给 JS 加载留出了一定的时间,这是因为 浏览器对象.get() 方法会在网页框架加载结束后完成执行,而此时通过 page_source 获取的网页代码,可能并不是资源完全加载完成后的页面,如有额外的 Ajax 请求、JS 加载,在网页源代码中也不一定能成功获取到。所以需要延时等待,确保节点已经加载出来。
强制等待
强制等待:使用 time.sleep 方法让脚本在执行过程进行固定时间的休眠等待。
python
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.hapag-lloyd.cn/zh/home.html#hal-map')
# 获取网页代码
print(browser.page_source)
print('=================================')
# 暂停10秒
time.sleep(10)
# 获取网页代码
print(browser.page_source)
'''
输出:
...<script>
(function(){
window["bobcmn"] = "111110101010102000000022000000052000000002d35d0af5200000096300000000300000000300000006/TSPD/300000008TSPD_101300000005https3000000b0081ecde6...
</script>...
=================================
...</script>
<div id="hal-cookieconsent" class="hal-cookienotice" style="display: block;">
<div class="hal-cookienotice-info">
<p class="hal-cookienotice-info-text">...
注释:上面两次打印的结果不一样,是因为Selenium加载网页后马上获取的网页代码是未加载Js的,而Js能改变网页内容,在等待10秒的过程中,Js加载完毕,此时再执行获取网页代码的方法,获取的就是Js加载后的网页代码。
'''警告
强制等待有一个缺点就是,即使我们所需要的元素被很快的加载出来了,也还是要等待固定的休眠时间。
显式等待
显式等待:通过 WebDriverWait() 配合该类的 until() 或 until_not() 方法,针对于某个特定的元素设置的等待时间,默认每隔 0.5s 检测一次,如果条件成立,则执行下一步,否则继续等待,直到超过设置时间,然后抛出 TimeoutException 错误。
python
# 导入WebDriverWait,设置延时等待
from selenium.webdriver.support.ui import WebDriverWait
# 设置浏览器对象和10秒的等待时间
wait = WebDriverWait(浏览器对象, 10)既然是针对元素的等待,那么如何判断一个元素是否存在?在 Selenium 的 expected_conditions 模块收集了一系列的场景判断方法。引入路径和方法如下:
python
# expected_conditions一般也简称为EC
from selenium.webdriver.support import expected_conditions as EC
# 判断当前页面的title是否包含预期字符串,返回布尔值
EC.title_contains(u"字符串")
# 判断某个元素是否被加到dom树下(因为参数必须是可迭代的,所以用By类的元组)
EC.presence_of_element_located((By..., '...'))
# 判断某个元素中是否可见并且是enable的
EC.element_to_be_clickable((By..., '...'))
# 判断某个元素是否被选中了,一般用在下拉列表
EC.element_to_be_selected((By..., '...'))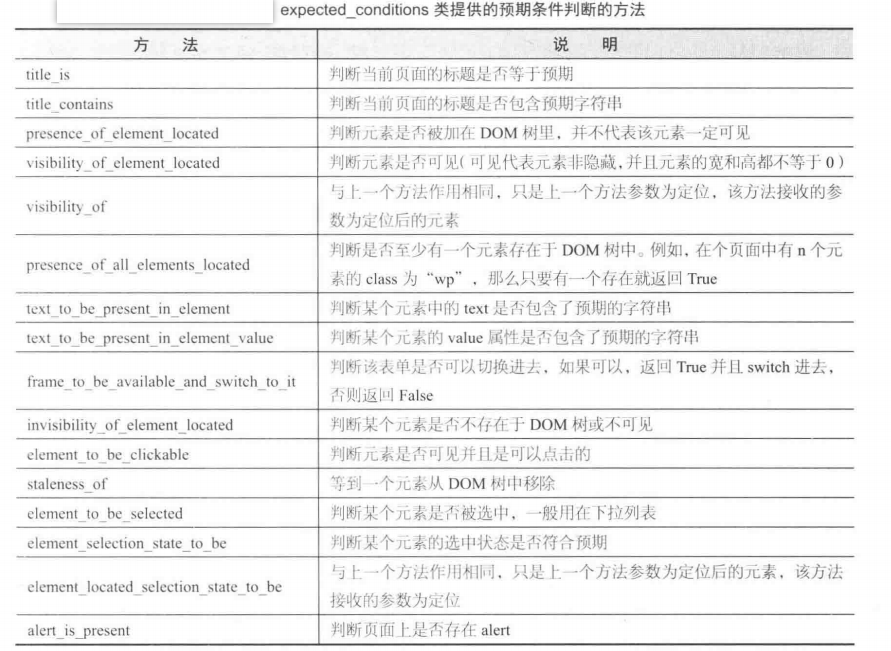
爬取淘宝网时的显式等待:
python
from selenium import webdriver
# 导入Selenium的定位的By类
from selenium.webdriver.common.by import By
# 导入WebDriverWait,设置延时等待
from selenium.webdriver.support.ui import WebDriverWait
# 将导入的expected_conditions重命名为EC
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
# 每个元素的等待时间统一设置为10秒
wait = WebDriverWait(browser, 10)
# 在10秒内如果ID为q的节点成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
search = wait.until(EC.presence_of_element_located((By.ID, 'q')))
print(search) # 输出:<selenium...(session="932...f34", element="0.243...237-1")>
# 在10秒内如果btn-search节点是可点击的,就返回该节点;如果超过10秒不可点击,就抛出异常。
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(button) # 输出:<selenium...(session="932...f34", element="0.243...237-2")>隐式等待
隐式等待:通过 implicitly_wait() 设置的全局等待时间,即对页面中的所有元素设置加载时间,如果超出了设置时间的则抛出 NoSuchElementException 异常。这可以理解成在规定的时间范围内,selenium 在不停的刷新查找页面中的元素,直到找到相关元素或者时间结束。
python
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com')
# 隐式等待10秒,元素在10s内定位到了,则继续执行;否则,就抛出异常。
browser.implicitly_wait(10)隐式等待和显示等待的区别:
- 隐式等待是全局性的,适用于整个 WebDriver 实例,即应用与脚本中的所有元素,而显式等待是基于某个具体条件的元素,更具体、灵活。
- 隐式等待是针对每一个元素的等待,因此不需要在元素上指定 ExpectedConditions,而显示等待需要在定位的元素上指定 ExpectedConditions。
- 隐式等待可能导致整个测试用例的执行时间增加,因为它会等待每一个查找元素的操作都达到设定的等待时间。显式等待则可以更精准地控制等待的时机。
其他操作
基本功能
浏览器基本功能,Selenium 也可以完成:
python
# 刷新当前窗口
browser.refresh()
# 前进到下一个访问的页面
browser.forward()
# 后退到上一个访问的页面
browser.back()
# 如果打开了多个窗口,则关闭当前窗口;如果只打开一个窗口,则退出浏览器
browser.close()
# 关闭所有窗口,退出浏览器,
browser.quit()键盘操作
键盘基本操作,Selenium 也可以完成:
python
import time
from selenium import webdriver
# 调用键盘按键操作引入keys包
from selenium.webdriver.common.keys import Keys
# 声明浏览器对象
browser = webdriver.Chrome()
# 访问“百度”
browser.get('https://www.baidu.com')
# id="kw"是百度搜索输入框,输入框中输入字符串"程序猿"
browser.find_element_by_id('kw').send_keys('程序猿')
time.sleep(2)
# ctrl+a 全选输入框内容
browser.find_element_by_id("kw").send_keys(Keys.CONTROL, 'a')
time.sleep(2)
# ctrl+x 剪切输入框内容
browser.find_element_by_id("kw").send_keys(Keys.CONTROL, 'x')
time.sleep(2)
# 输入框中输入字符串"程序员"
browser.find_element_by_id('kw').send_keys('程序员')
time.sleep(2)
# 方法一:id="su"是百度搜索按钮,使用回车
browser.find_element_by_id("su").send_keys(Keys.ENTER)
time.sleep(2)
# 方法二:id="su"是百度搜索按钮,click()点击
browser.find_element_by_id("su").click()
time.sleep(2)
# 方法三:id="su"是百度搜索按钮,通过js点击搜索
element = browser.find_element_by_id("su")
driver.execute_script("arguments[0].click();", element)行为事件
actionchains 是 Selenium 里面专门处理鼠标相关的操作如,鼠标移动,鼠标按钮操作,按键和上下文菜单(鼠标右键)交互。
python
from selenium import webdriver
# 导入ActionChains行为事件
from selenium.webdriver import ActionChains
# 浏览器对象
browser = webdriver.Chrome()
# 滑块对象
slider = find_element_by_id('...')
# 滑动链表
track = [0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2]
# click_and_hold保持按住并滑动
ActionChains(browser).click_and_hold(slider).perform()
# 滑动距离就是滑动链表中的值
for x in track:
# xoffse水平位移, yoffset垂直位移
ActionChains(browser).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(browser).release().perform()
# 对于下拉列表,使用move_to_element移动到该元素,一层一层的指向
# 移动到button1
button1 = wait.until(EC.presence_of_element_located((By..., '...')))
ActionChains(browser).move_to_element(button1).perform()
# 移动到button1下的button2
button2 = wait.until(EC.element_to_be_clickable((By..., '...')))
ActionChains(browser).move_to_element(button2).perform()
# 移动到button1下的button2下的button3
button3 = wait.until(EC.element_to_be_clickable((By..., '...')))
ActionChains(browser).move_to_element(button3).perform()
# 点击button3
button3.click()窗口截屏
只针对窗口显示的部分网页进行截屏,有头模式和无头模式都能进行截屏:
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 创建设置类
chrome_options = Options()
# 设置无头模式
chrome_options.add_argument('--headless')
# 启用配置
browser = webdriver.Chrome(options=chrome_options)
# 访问百度页面
browser.get('https://www.baidu.com')
# 生成当前页面快照并保存
browser.save_screenshot("baidu.png")窗口句柄
**我们在操作网页时,可能会打开很多个窗口,但总会有一个窗口位于最上层,不被其他窗口遮挡,就是“活动窗口”,即当前的工作窗口。当我们要在某个页面上操作,就得将活动窗口切换到该页面上。**比如,百度首页登录框点击注册,会打开一个新的注册页面,要在新页面注册,就得先切进新页面。我们可以通过浏览器的显示来判定哪一个是活动窗口。
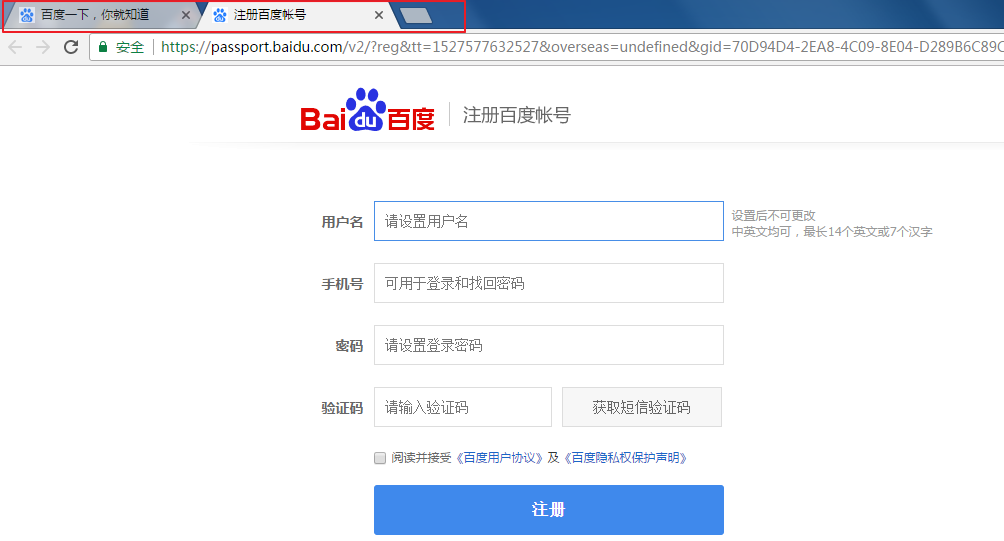
我们来看看下面的例子:这里我们可以发现一个问题,两次输出的活动页面代码相同。也就是说,Selenium 打开一个网页,通过 page_source 输出了网页代码,接着 Selenium 再打开一个新的网页,虽然我们看到浏览器的活动窗口在新的网页上,但 page_source 输出的仍然是第一个网页的代码。也就是说,我们看到的活动窗口,不一定就是程序的活动窗口。
python
from selenium import webdriver
# 生成webdriver对象
browser = webdriver.Chrome()
# 访问百度页面
browser.get('https://www.baidu.com')
time.sleep(5)
# 保存活动窗口页面代码
old_page = browser.page_source
# 点击当前网页的一个链接,产生新的窗口
browser.find_element(By.XPATH, '//a[contains(@class, "title-content")]').click()
time.sleep(5)
# 保存活动窗口页面代码
new_page = browser.page_source
# 比较两次页面代码是否相同
print(old_page == new_page) # 输出:True。注释:两次输出的活动页面代码相同。**对于程序来说,它是通过切换句柄(浏览器赋予每个窗口的唯一编号)来切换活动窗口的,造成上述问题的原因,就是因为程序没有切换到新网页上的句柄,认为活动窗口还在第一个网页上所造成的。这里说一下窗口句柄的分配是根据打开的顺序,也就是说,新打开的窗口的句柄通常是已有窗口句柄中最大的加一。**举个例子:
- 打开第一个网页,窗口句柄是0。
- 打开第二个网页,窗口句柄是1(因为0是已有窗口的最大句柄,加一得到1)。
- 打开第三个网页,窗口句柄是2(因为1是已有窗口的最大句柄,加一得到2)。
- 关闭第二个网页。
- 重新打开一个新的网页,其句柄可能是3(因为0、1、2是已有窗口的句柄,加一得到3)。
python
from selenium import webdriver
# 生成webdriver对象
browser = webdriver.Chrome()
# 访问百度页面
browser.get('https://www.baidu.com')
time.sleep(5)
# 保存活动窗口页面代码
old_page = browser.page_source
# 点击当前网页的一个链接,产生新的窗口
browser.find_element(By.XPATH, '//a[contains(@class, "title-content")]').click()
time.sleep(5)
# 获取所有窗口句柄
n = browser.window_handles
# 切换到新网页的句柄
browser.switch_to.window(n[1])
# 保存活动窗口页面代码
new_page = browser.page_source
# 比较两次页面代码是否相同
print(old_page == new_page) # 输出:False。注释:两次输出的活动页面代码不同。