HTTPX库
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
前面我们学习了 requests 库,这是写爬虫最简单、最易用的第三方库,虽然使用 requests 库可以爬取绝大部分网站,但它也不是万能的,它也有自己的局限,例如:不支持 HTTP2.0、只能同步请求(也就是第一个请求返回响应后才会去进行第二个请求)效率不高。**因此我们有必要多掌握一个写爬虫的库,毕竟没有万能的工具,那就只有成为会多种工具的人,让自己多一种技能。**接下来要介绍的第三库就是:HTTPX 库。
安装使用
HTTPX 库官方文档:https://www.python-httpx.org/
**HTTPX 是 Python3 的一个功能齐全的 HTTP 第三方库,它提供同步和异步 API,并支持 HTTP/1.1 和 HTTP/2。**安装 HTTPX 需要在 Python3.6+ 的环境里面,安装命令如下:
# 只安装包含基本功能的httpx库
pip install httpx
# 安装httpx库附带支持http2功能
pip install httpx[http2]
# 安装httpx库附带支持brotli解码器功能
pip install httpx[brotli]
# 安装httpx库附带可视化的命令行界面功能
pip install httpx[cli]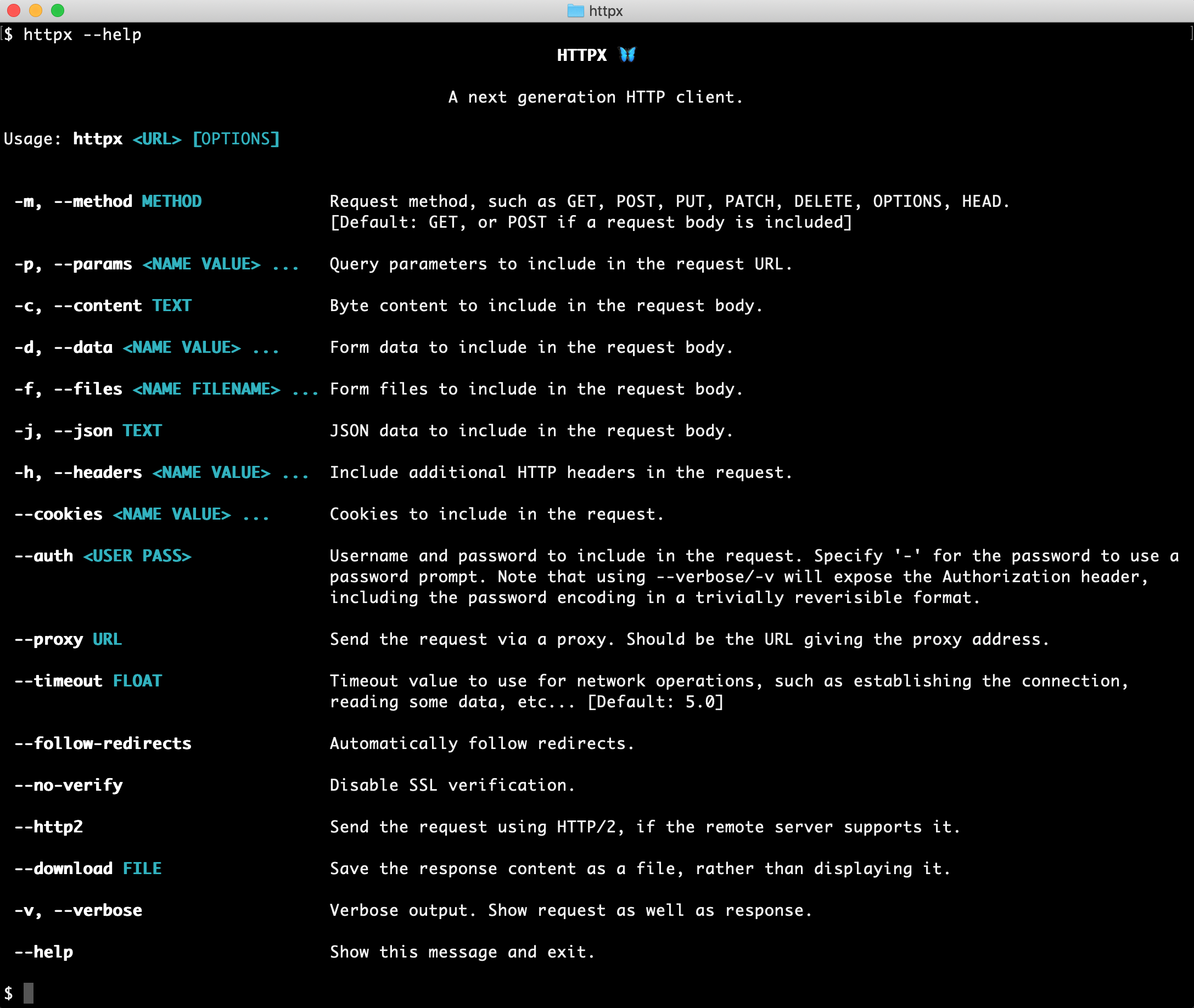
常规使用
HTTPX 库的使用方式和 requests 库的使用方式可以说几乎一样。
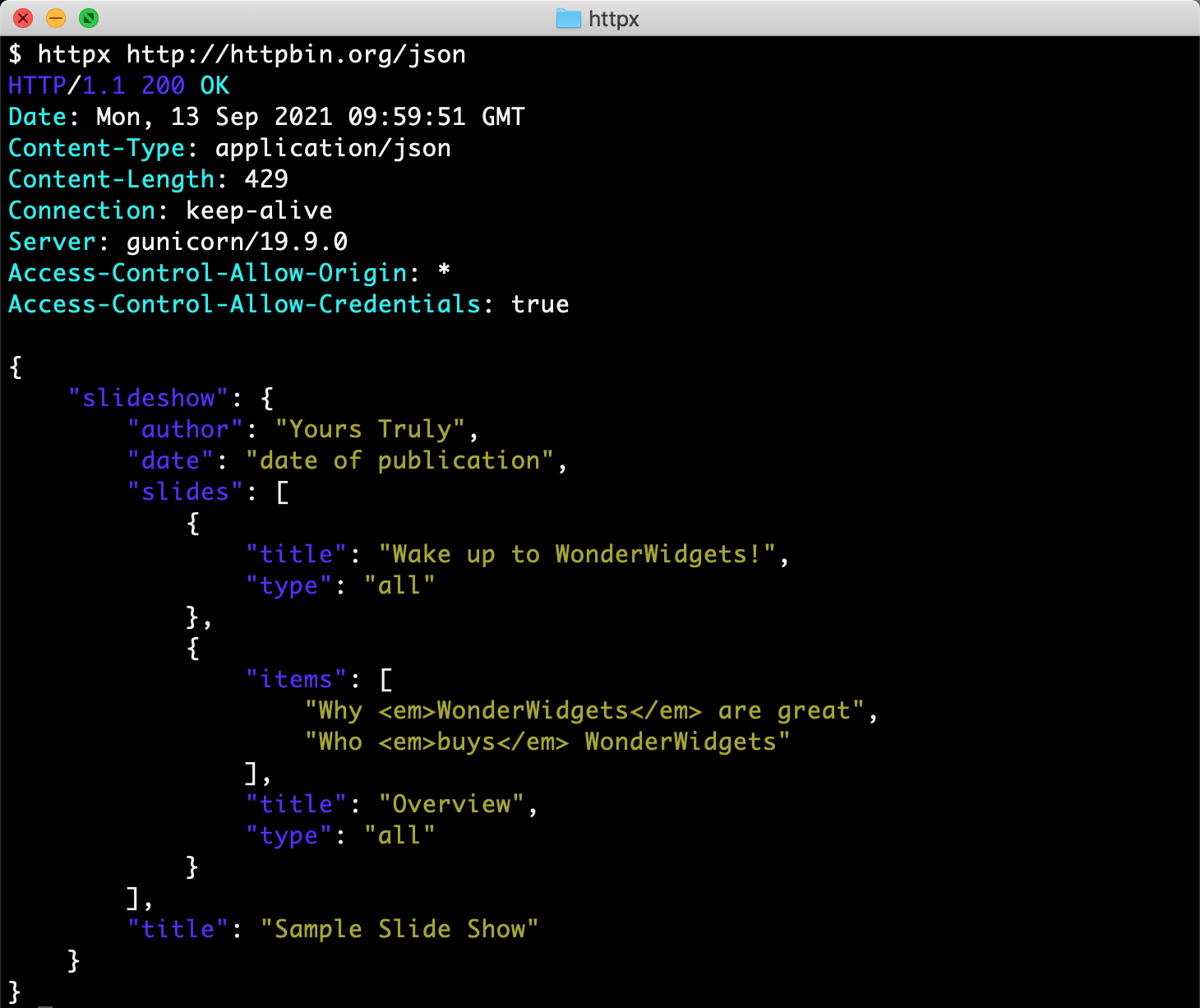
发送请求
使用 HTTPX 库实现 HTTP 多种请求类型的发送:
python
import httpx
# get请求
httpx.get('https://httpbin.org/get')
# post请求
httpx.post('https://httpbin.org/post', data={'key': 'value'})添加请求头
python
import httpx
# 请求头
headers = {'user-agent': 'my-app/0.0.1'}
r = httpx.get('https://httpbin.org/headers', headers=headers)构建URL参数
python
import httpx
# 使用params关键字,通过字典构建URL参数
params1 = {'key1': 'value1', 'key2': 'value2'}
# 还可以使用列表list构建URL参数
params2 = {'key1': 'value1', 'key2': ['value2', 'value3']}
# 发送请求
r1 = httpx.get('https://httpbin.org/get', params=params1)
r2 = httpx.get('https://httpbin.org/get', params=params2)
# 输出构建后的URL
print(r1.url) # 输出:'https://httpbin.org/get?key1=value1&key2=value2'
print(r2.url) # 输出:'https://httpbin.org/get?key1=value1&key2=value2&key2=value3'传递POST参数
python
import httpx
data1 = {'key1': 'value1', 'key2': 'value2'}
data2 = {'key1': ['value1', 'value2']}
data3 = {'integer': 123, 'boolean': True, 'list': ['a', 'b', 'c']}
data4 = b'Hello, world'
r1 = httpx.post("https://httpbin.org/post", data=data1)
r2 = httpx.post("https://httpbin.org/post", data=data2)
r3 = httpx.post("https://httpbin.org/post", json=data3)
r4 = httpx.post("https://httpbin.org/post", content=data4)
print(r1.text)
print(r2.text)
print(r3.text)
print(r4.text)
'''
输出:
"form": {"key1": "value1", "key2": "value2"}
"form": {"key1": ["value1", "value2"]}
"json": {"boolean": true, "integer": 123, "list": ["a", "b", "c"]}
"data": "Hello, world"
'''添加Cookie
python
import httpx
# URL中设置Cookie
r = httpx.get('https://httpbin.org/cookies/set?chocolate=chip')
# 输出Cookie
print(r.cookies['chocolate']) # chip
# 手动添加Cookies
cookies = {"peanut": "butter"}
r = httpx.get('https://httpbin.org/headers', headers=headers, cookies=cookies)
# Cookie在Cookie实例中返回,该实例是一个类似dict的数据结构,带有额外的API,用于按域或路径访问Cookie。
cookies = httpx.Cookies()
cookies.set('cookie_on_domain', 'hello, there!', domain='httpbin.org')
cookies.set('cookie_off_domain', 'nope.', domain='example.org')
r1 = httpx.get('http://httpbin.org/cookies', cookies=cookies)
r2 = httpx.get('http://example.org/cookies', cookies=cookies)
print(r1.json()) # 输出:{'cookies': {'cookie_on_domain': 'hello, there!'}}
print(r2.json()) # 输出:{'cookies': {'cookie_off_domain': 'nope.'}}响应属性
python
import httpx
r = httpx.get('...')
# 输出请求的URL
print(r.url)
# 指定解码响应的编码
r.encoding = 'ISO-8859-1'
# 输出解码响应的编码(默认UTF-8)
print(r.encoding)
# 输出状态码
print(r.status_code)
# 输出响应头
print(r.headers)
print(r.headers['Content-Type'])
print(r.headers.get('content-type'))
# 输出服务器使用的HTTP协议版本
print(response.http_version) # 输出:"HTTP/1.0" or "HTTP/1.1" or "HTTP/2"
# 输出响应的字符串文本
print(r.text)
# 输出响应的bytes内容
print(r.content)
# 输出响应的json格式
print(r.json())
# 输出访问历史
print(r.history)设置超时
HTTPX 超时时间默认为 5 秒,这点与 requests 不一样,requests 是发送请求后只要没有接受到响应都会一直挂起。
python
# 设置超时时间为0.001秒
httpx.get('https://github.com/', timeout=0.001)
# 设置超时为空None,即没有超时时间
httpx.get('https://github.com/', timeout=None)设置代理
HTTPX 也支持通过 proxies 参数设置 HTTP 代理,例如将 HTTP 和 HTTPS 请求路由到两个不同的代理:
python
proxies = {
"http://": "http://localhost:8030",
"https://": "http://localhost:8031",
}
# 添加代理
httpx.get('https://github.com/', proxies=proxies)[!ATTENTION]
HTTPX 不支持 SOCKS 代理。
追踪重定向
HTTPX 默认情况下是不会自动重定向的,这点与 requests 不一样,requests 是自动重定向,你可以在 HTTPX 中设置 follow_redirects 为 True 让其能自动重定向
python
# 举个例子,GitHub会将所有的HTTP请求重定向为HTTPS
r = httpx.get('http://github.com/')
print(r.status_code) # 输出:301
print(r.history) # 输出:[]
print(r.next_request) # 输出:<Request('GET', 'https://github.com/')>。注释:重定向后的请求。
# 设置为允许重定向
r = httpx.get('http://github.com/', follow_redirects=True)
print(r.url) # 输出:https://github.com/
print(r.status_code) # 输出:200
print(r.history) # 输出:[<Response [301 Moved Permanently]>]身份认证
HTTPX 支持基本和摘要 HTTP 身份验证。需要提供基本身份验证凭据,将两元组的纯文本 str 或字节对象作为 auth 参数传递给请求函数:
python
httpx.get("https://example.com", auth=("my_user", "password123"))要为摘要身份验证提供凭据,您需要使用明文用户名和密码作为参数实例化一个 DigestAuth 对象。然后可以将此对象作为 auth 参数传递给请求方法,如下所示:
python
auth = httpx.DigestAuth("my_user", "password123")
httpx.get("https://example.com", auth=auth)SSL证书认证
使用 HTTPX 库在爬取这些网站时,也会进行一个 SSL 证书验证的过程,和 requests 库一样,HTTPX 库也有一个 verify 参数来控制证书验证。
python
import httpx
# verify=False关闭SSL证书验证
response = httpx.get('https://inv-veri.chinatax.gov.cn/', verify=False, follow_redirects=True)
print(response.status_code)会话对象Client
requests 库有高级用法 Session 会话对象,同样的 HTTPX 库也有高级用法 Client 会话对象,两者用途类似。
使用方式
**我们知道 HTTP 请求走完后,底层的 TCP 连接不会马上断开,如果我们使用 HTTPX 库的 Client 会话对象,还会复用底层的 TCP 连接,提升采集效率。**但如果我们要提前释放 TCP 连接可以通过 Client.close() 方法来释放,或者使用 Python 上下文管理器来管理 Client 会话对象:
python
import httpx
# 方法一:手动管理client会话对象
client = httpx.Client()
client.get('...')
client.close()
# 方法二:使用上下文管理器来管理client会话对象
with httpx.Client() as client:
pass添加参数
HTTPX 库的 Client 会话对象添加请求头参数:
python
with httpx.Client() as client:
headers = {'X-Custom': 'value'}
r = client.get('https://example.com', headers=headers)
print(r) # 输出:<Response [200 OK]>
print(r.request.headers['X-Custom']) # 输出:value**客户端允许您通过向客户端构造函数传递参数,将配置应用于所有传出请求。**例如,要在每个请求上应用一组自定义头,请执行以下操作:
python
headers = {'user-agent': 'my-app/0.0.1'}
with httpx.Client(headers=headers) as client:
r = client.get('http://httpbin.org/headers')
print(r.json()['headers']['User-Agent']) # 输出:'my-app/0.0.1'甚至请求的参数还可以自动合并:
python
headers = {'X-Auth': 'from-client'}
params = {'client_id': 'client1'}
with httpx.Client(headers=headers, params=params) as client:
headers = {'X-Custom': 'from-request'}
params = {'request_id': 'request1'}
r = client.get('https://example.com', headers=headers, params=params)
print(r.request.url) # 输出:https://example.com?client_id=client1&request_id=request1
print(r.request.headers['X-Auth']) # 输出:from-client
print(r.request.headers['X-Custom']) # 输出:from-request钩子事件
**HTTPX 库允许您向客户机写入“事件挂钩”,每次特定类型的事件发生时都会调用这些挂钩,以便您日志记录、监视或跟踪。**当前现有两个事件挂钩:
request在请求完全准备好后,但在发送到网络之前调用。response在从网络获取响应之后,但在将响应返回给调用方之前调用。
python
def log_request(request):
print(f"Request event hook: {request.method} {request.url} - Waiting for response")
def log_response(response):
request = response.request
print(f"Response event hook: {request.method} {request.url} - Status {response.status_code}")
with httpx.Client() as client:
# 事件挂钩必须为可调用的列表,通过event_hooks属性进行注册,并且可以为每种类型的事件注册多个事件挂钩。
client.event_hooks['request'] = [log_request]
client.event_hooks['response'] = [log_response]HTTP2爬虫
前面讲过 requests 库不支持 HTTP2.0,而 HTTPX 库支持,但要安装可以选用支持 HTTP2.0 的 HTTPX 库:
pip install httpx[http2]例如下面的这道题的名称为:天杀的 http2.0(提示本题采用的http2.0),爬虫代码如下:
python
import re
import httpx
# 数值
values = 0
# 请求头
headers = {
'cookie': '自己当前的cookie',
'user-agent': 'yuanrenxue.project',
'x-requested-with': 'XMLHttpRequest'
}
# 实例化启动支持http2的client会话对象
with httpx.Client(http2=True) as client:
# 共5页数据
for page in range(1, 6):
url = f'https://match.yuanrenxue.com/api/match/17?page={page}'
response = client.get(url=url, headers=headers)
# 输出服务器使用的HTTP协议版本
print(response.http_version)
for v in re.findall(r'{"value": (-?\d+)}', response.text):
values += int(v)
# 总值
print(values)警告
请求和响应通过 HTTP/2 传输,意味着客户机和服务器都需要支持 HTTP/2。如果连接到仅支持 HTTP/1.1 的服务器,则客户端将使用标准 HTTP/1.1 连接。