优先队列PQ
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
优先队列(Priority Queue),简单说就是队列中的每个元素都有一个自己的优先级。其主要特性如下:
- 优先级排序:元素的出队顺序基于它们的优先级,而不是它们进入队列的顺序。通常高优先级的元素比低优先级的元素先出队列。
- 动态优先级:在某些实现中,元素的优先级可以在队列中动态地改变。
- 时间复杂度:插入和删除操作的时间复杂度通常是 ,其中 是队列中的元素数量。
前言介绍
在前面我们讲消息队列是一个按照入队顺序进行输出的先进先出(First in-First out,FIFO)数据结构。假如说,我们手上来了一个十分紧急的任务,希望优先处理,显然消息队列是无法满足的,因为消息队列是按照入队的顺序进行输出的,也就是说就是这个任务再紧急也只能排到消息队列的末尾,最后才会进行处理。所以,这时优先队列的作用就展现出来了。
生活场景
有人会问,优先队列有什么用呢?最常见的用法是用来安排任务的优先等级。我们可以想象在生活中的优先队列,比如说火车站的通道入口,如果没有优先队列的存在,来一个人就去通道排队进站,那可能会造成很多问题:
- 一旦人流量加大,所有通道都可能会出现拥挤,导致一些特殊人群无法快速进站造成损失。
- 假如队伍中有人突发特殊情况需要快速进站,没有优先队列也只一个一个的按队伍顺序进站。

于是就发明了优先队列,大家按照自己的优先等级来排一列,高优先级的排前面,低优先级的排后面,然后一个一个的进站。如果队列里面出现了紧急事务,我们也可以提高它的优先级,让它插队到低优先级前面。避免了因任务紧急,但无法快速处理的情况发生。
常见应用
优先队列的常见应用如下:
- 任务调度:在操作系统中,优先队列用于任务调度,确保高优先级的任务优先执行。
- 事件驱动系统:在事件驱动的系统中,优先队列用于根据事件的紧急程度或重要性来排序和处理事件。
- 数据流处理:在处理大量数据流时,优先队列可用于确保关键数据优先处理。
实现优先队列
这里介绍常见的优先队列实现方式:Redis 数据库、RabbitMQ 框架。
Redis数据库
创建队列
python
import redis
class PriorityQueue:
"""自定义优先级队列"""
def __init__(self, host, port, db, password, name):
# 优先队列名称
self.key = name
# redis连接对象
self.connect = redis.StrictRedis(host=host, port=port, db=db, password=password)
def __len__(self):
"""队列长度"""
return self.connect.zcard(self.key)
def push(self, data, score):
"""向队列中插入元素"""
self.connect.execute_command('ZADD', self.key, score, data)
def pop(self):
"""从队列中取出元素"""
pipe = self.connect.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return results[0].decode()
# 创建对象
priority_queue = PriorityQueue(host='localhost', port=6379, db=0, password='123456', name='priority_queue')插入元素
python
for data, score in (('爱', 100), ('你', 90), ('我', 110)):
priority_queue.push(data, score)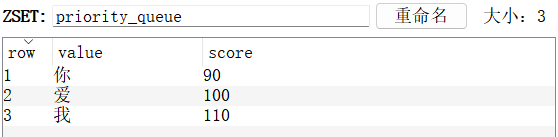
等级调整
python
priority_queue.push('我', 50)
priority_queue.push('你', 150)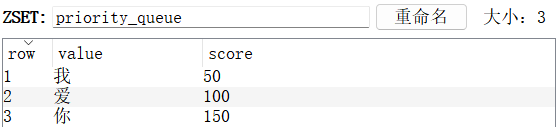
队列长度
python
print(priority_queue.__len__()) # 输出:3取出元素
python
while True:
element = priority_queue.pop()
if element is None:
break
print(element, end='') # 输出:我爱你重要
取出元素会导致优先队列中的元素减少,当优先队列中的元素个数为 0 时,优先队列也就不存在了。
RabbitMQ框架
创建队列
在 RabbitMQ 中实现优先级队列很简单,只需要在声明队列时,添加一个 x-max-priority 参数来指定最大优先级即可。创建队列的代码如下:
python
import pika
# 连接本地的RabbitMQ服务
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
# 声明一个频道,即channel
channel = connect.channel()
# 声明一个名称为scrape的队列,指定队列的最大优先级为100
channel.queue_declare(queue='scrape', arguments={'x-max-priority': 100})在 RabbitMQ 管理页面可以看到队列的 Features 特征多出了 Pri 标识,表示该队列是一个优先队列:
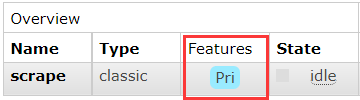
生产者代码
python
# data, priority分别代表消息的内容和消息的优先级
for data, priority in (('world', 80), ('!', 70), ('Hello', 90)):
channel.basic_publish(
exchange='',
routing_key='scrape',
properties=pika.BasicProperties(priority=int(priority),),
body=data.encode())填充后,可以看到队列里面的消息数量变为了 3 个:

消费者代码
python
import pika
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connect.channel()
def callback(ch, method, properties, body):
print(f'Get {body}')
ch.basic_ack(delivery_tag=method.delivery_tag)
# 和上面相比,这里就没有设置auto_ack参数。
channel.basic_consume(queue='scrape', on_message_callback=callback)
channel.start_consuming()运行消费者代码可以看到内容是按优先级的大小,从高到低进行了输出。
python
'''
输出:
Get b'Hello'
Get b'world'
Get b'!'
'''