数组Array
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
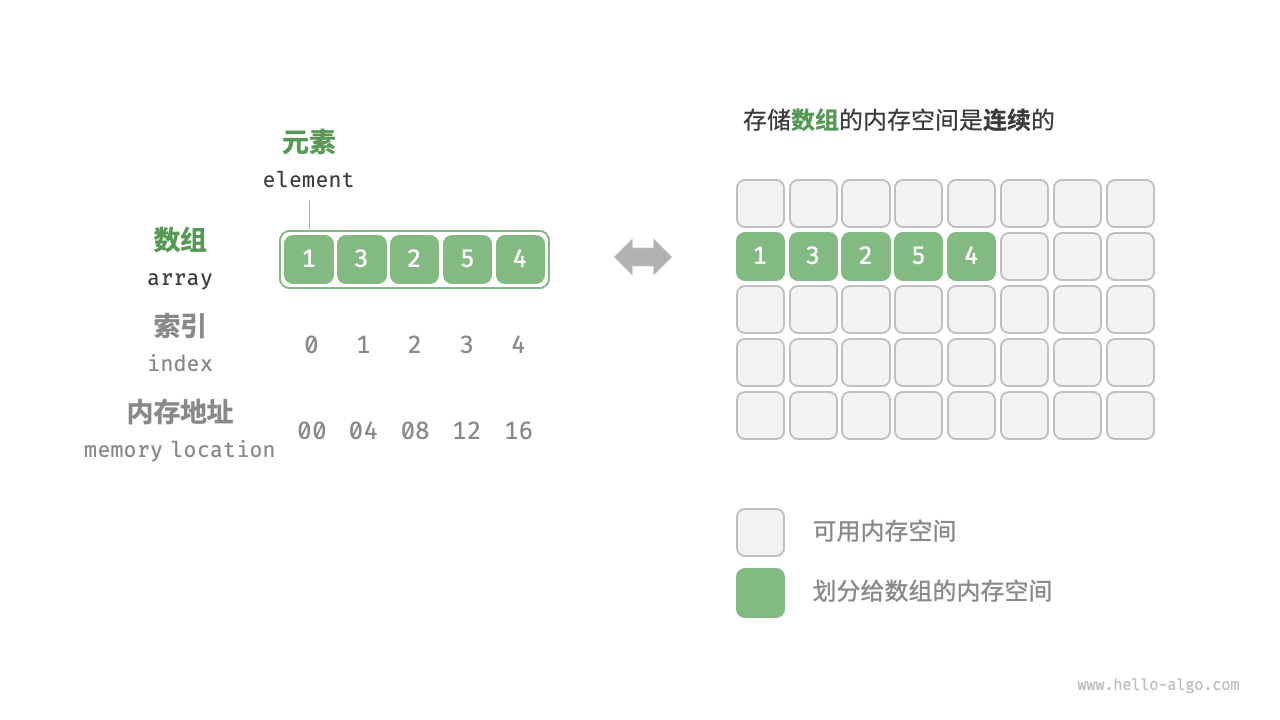
数组(Array)是将相同类型的元素存储于连续内存空间的数据结构,数组中的每个元素都会被分配一个唯一的数组索引,该索引是一个从 0 开始连续自增的整型数值,通过索引可以访问数组中任何的元素。
数组类型
在初始化数组时,必须要通过一个类型代码(单个字符)用来约束数组中元素的数据类型。具体含义如下:
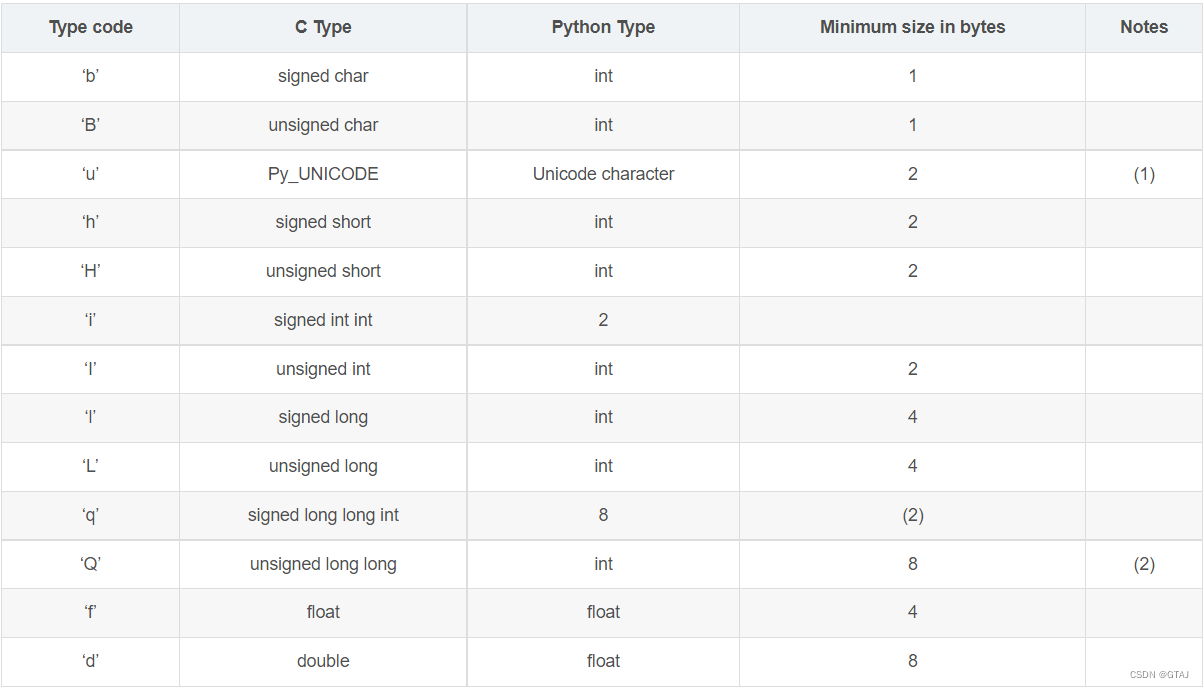
- 小写
b:表示有符号字符(signed char),用于存储有符号的字节值,范围从 -128 到 127(在大多数系统上)。 - 大写
B:表示无符号字符(unsigned char),用于存储无符号的字节值,范围从 0 到 255。 - 小写
u:表示 Unicode 字符,用于存储 Unicode 字符。 - 小写
i:表示有符号整数(signed integer),可以存储正整数、负整数和零,适合需要存储负整数和零的场景。 - 大写
I:表示无符号整数(unsigned integer),只能存储非负整数,适合需要存储更大的正整数的场景。
数组操作
在 Python 中 array 模块提供了数组支持,它提供了类似于 C 语言中数组的功能,元素在内存中是连续存储的。
python
# 引入array数组模块
import array
# typecodes属性返回所有可用类型代码的字符
print(array.typecodes) # 输出:bBuhHiIlLqQfd创建数组
python
# 引入array数组模块
import array
# 创建一个空数组,I表示数组的类型代码。
my_array = array.array('I')
print(my_array) # 输出:array('I')
print(type(my_array)) # 输出:<class 'array.array'>。注释:对象是数组类型。
# typecode属性返回当前数组的类型代码字符。
print(my_array.typecode) # 输出:I。注释:表示该数组只能存放无符号整数类型的数据。
# 创建一个非空数组
my_array = array.array("i", [0, 1, 2])
print(my_array) # 输出:array('i', [0, 1, 2])
print(type(my_array)) # 输出:<class 'array.array'>。注释:对象是数组类型。
# typecode属性返回当前数组的类型代码字符。
print(my_array.typecode) # 输出:i。注释:表示该数组只能存放有符号整数类型的数据。访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(首元素内存地址)和某个元素的索引,我们可以使用下图所示的公式计算得到该元素的内存地址,从而直接访问该元素。这里有两点需要说明的是:
- 数组里面的元素都是相同数据类型,也就是说每个元素的字节长度是一样的,这样才能通过计算偏移量来获取对应元素位置。例如,数组同时包含
int和long两种类型,单个元素分别占用 4 字节 和 8 字节 ,此时就不能用下图公式计算偏移量了,因为数组中包含了两种“元素长度”。 - 数组里面的每个元素的字节长度是一样的,这也意味着数组里面的元素不能是字符串,因为不同长度的字符串,它的字节长度是不一样的,因此只能是单个字符,而且通常由 Unicode 字符编码表示。
python
import array
# 一个存放整数(int)元素的数组
my_array = array.array("i", [1, 3, 2, 5, 4])
# itemsize返回数组中单个元素的字节长度
print(my_array.itemsize) # 输出:4。注释:数组中单个元素的字节长度为4。
print(my_array[3]) # 输出:5。注释:通过索引访问数组元素。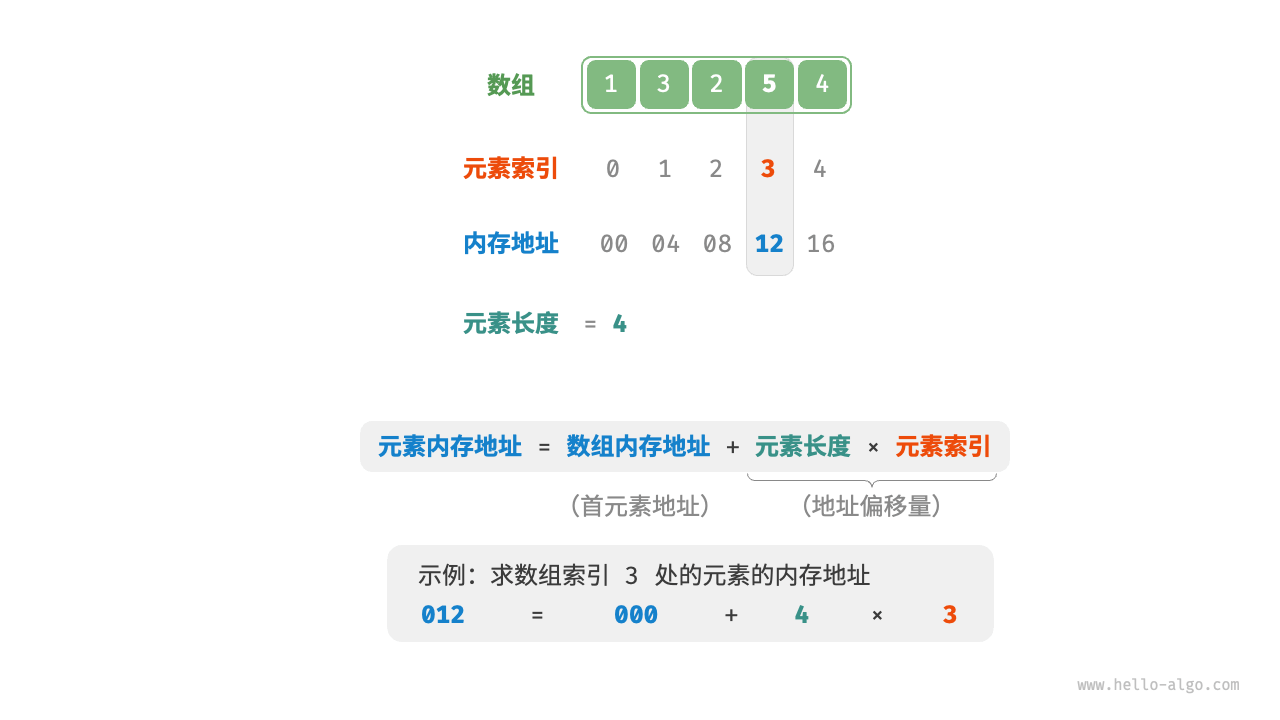
建议
数组首个元素的索引为 0 ,这似乎有些反直觉,因为从 1 开始计数会更自然。但从地址计算公式的角度看,索引本质上是内存地址的偏移量。首个元素的地址偏移量是 0 ,因此它的索引为 0 是合理的。
遍历元素
在 Python 中,我们既可以通过索引遍历数组,也可以直接遍历获取数组中的每个元素:
python
import array
my_array = array.array("i", [1, 3, 2, 5, 4])
# 通过索引遍历数组
for index in range(len(my_array)):
print(my_array[index], end=', ') # 输出:1, 3, 2, 5, 4,
print()
# 直接遍历数组元素
for element in my_array:
print(element, end=', ') # 输出:1, 3, 2, 5, 4,查找元素
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。这里可以发现一个问题就是,假如我们要查找的元素在数组的最后一位,由于是按顺序查找元素,也就是说前面的所有元素都会被访问了一遍。假如说列表的体量很大而我们所要查找的元素在列表中的位置比较靠后时,这样查找的效率就会很低,因为这是一种线性时间复杂度的方法,也就是得到结果所花费的时间随着问题规模的增大而线性增加。又因为数组是线性数据结构,所以上述查找操作被称为“线性查找”。
python
import array
my_array = array.array("i", [1, 3, 2, 5, 4])
search_element = 3
# 通过索引遍历数组
for index in range(len(my_array)):
if my_array[index] == search_element:
print(index) # 输出:1
break
else:
print("Element not found")
# index方法从下标从0开始,返回元素在数组中第一次出现的下标,如果没有找到该元素会抛出异常。
print(my_array.index(search_element)) # 输出:1插入元素
数组元素在内存中是“紧挨着的”,它们之间没有空间再存放任何数据。如果想在数组“中间位置”插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。
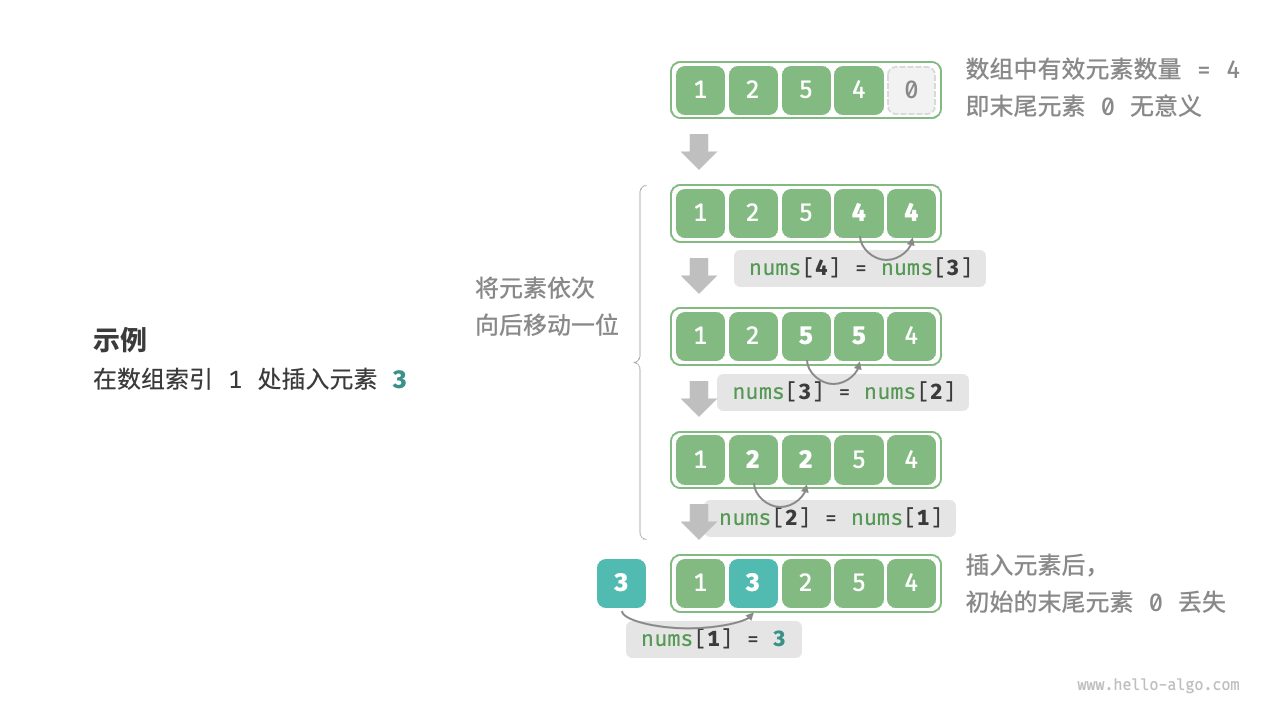
我们可以看到上图的结果中,向数组中插入一个元素后,导致了最后数组的末尾元素 0 丢失,原因就是初始化后的数组长度不可变。也就是说,在数组数组初始化的那一刻,数组的长度就已经固定了,且不可改变。但是我们看一下代码演示,会发现和上图的结果有所不同:代码中向数组插入了元素 3,在输出的结果中却仍然存在末尾元素 0。
python
import array
my_array = array.array("i", [1, 2, 5, 4, 0])
# 在数组索引1的位置移插入元素3
my_array.insert(1, 3)
print(my_array) # 输出:array('i', [1, 3, 2, 5, 4, 0])造成结果的差异的原因就是,Python 解释器自动进行了安全扩容。详细的讲就是,数组的长度在初始化时是固定的,当向数组中添加元素时,当前数组没有足够的空间来容纳新元素,这时 Python 解释器会自动分配一个新的、更大的内存空间,并将现有元素复制到新的内存空间中,再把新元素纳入到数组当中。这个过程称为内存重新分配(reallocation),它可能会导致数组元素在内存中的地址发生改变。具体我们看下面的例子:向数组中添加了一个元素 3 后,数组元素的个数增加了 1 个,其次是数组的内存地址发生了改变,这说明 Python 解释器为这个数组分配了一个更大的内存空间用来存放数组中的元素。
python
import array
my_array = array.array("i", [1, 2, 5, 4, 0])
# buffer_info方法返回当前数组的内存地址、元素个数
print(my_array.buffer_info()) # 输出:(1956840789232, 5)
# 在数组索引1的位置移插入元素3
my_array.insert(1, 3)
print(my_array.buffer_info()) # 输出:(1956839919552, 6)提醒
Python 解释器的安全扩容机制,使得数组可以动态地增长,而不会导致错误或异常,保证了数组的高效操作效率。
建议
Python 解释器新分配的内存空间是数组现内存空间的固定倍数,比如 1.5 倍左右,继续向数组添加元素就会发现,达到当前数组最大空间时,Python 解释器就会再分配更大的,是数组现内存空间固定倍数的内存空间。如果你需要固定大小的数组,并且希望避免内存重新分配的开销,你可能需要在创建数组时预先指定足够大的大小。
删除元素
数组元素在内存中是“紧挨着的”,它们之间没有空间,也不能存在空间,这个是由其本身结构所限定的。如果想删除数组中的一个元素,则需要将该元素之后的所有元素都向前移动一位,之后再把元素赋值给该索引。
python
import array
# 通过索引移除数组元素
my_array = array.array("i", [1, 3, 2, 5, 4])
del_element = my_array.pop(1) # 注释:移除指定的元素,当未指定索引时,默认移除最后一个元素,最后返回被移除的元素。
print(del_element) # 输出:3。注释:被删除的元素是3。
print(my_array) # 输出:array('i', [1, 2, 5, 4])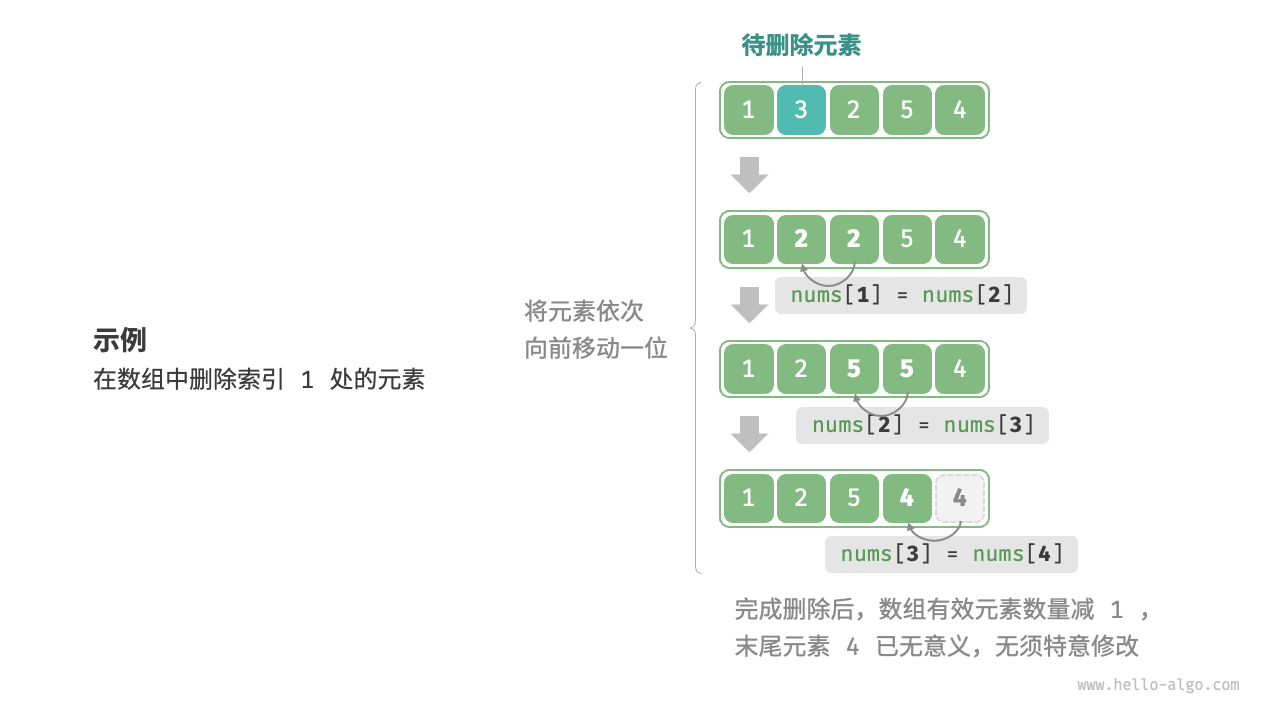
重要
数组的长度在初始化时是固定的,说的是数组在内存中占用空间是固定的,当删除数组中的元素后,只会让数组中的元素个数减少,并不会减少数组在内存中的占用空间,可以理解为这块内存空间就算不存放数据,数组也要占用着。另外 Python 解释器也不会为其分配新的内存空间,也就不会改变数组的内存地址,这样做的好处是避免频繁地进行内存分配和释放,提高了数组的性能,对应的坏处就是如果数组删除了很多元素,会有很多内存空间的不到使用,造成内存资源浪费。
其它方法
这里在介绍一些 array 模块的常用方法:
array.append(x)默认在数组尾部添加元素x。array.extend(可迭代对象)通过一个可迭代对象向数组中添加元素。array.fromlist(list)通过一个列表向数组中添加元素。array.count(x)返回x元素在数组中出现的次数,没有出现则返回 0。array.remove(x)从左至右删除数组中第一次出现的x元素,如果删除的元素的不在数组中,则会抛异常。array.sorted()对数组中的元素进行排序。array.reverse()对数组中的元素进行反序。array.tolist()把array对象转换成list对象。array.tobytes()把array对象转换成bytes对象。array.frombytes(bytes)把bytes对象转换成array对象。
数组特点
优点缺点
数组存储在连续的内存空间内,且元素类型相同,其结构优点如下:
- 空间效率高:数组为数据分配了连续的内存块,无须额外的结构开销。
- 快速访问更新:数组中访问或更新元素非常高效,允许在 时间内访问或更新任何元素。
- 缓存局部性:当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下局限性:
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素,平均时间复杂度均为 ,其中 为数组长度。在数组尾部添加元素的时间复杂度为 ,如果添加元素时超出列表长度,则需要先扩容列表再添加。系统会申请一块新的内存,并将原列表的所有元素搬运过去,这时候时间复杂度就会是 。
- 长度不可变:数组在初始化后长度就固定了,因此在插入元素后,超出数组长度范围的元素会丢失。如果有数组扩容机制,则需要将原数组所有元素依次复制到新数组,这是一个时间复杂度为 的操作,在数组很大的情况下非常耗时。
- 空间浪费:如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。
总结来说,数组访问快,增删慢,适用于频繁访问,增删较少的场景。
区别列表
首先,列表(List)其实是一个抽象的数据结构概念,它表示元素的有序集合,可以存储任意类型的元素,支持元素访问、修改、添加、删除和遍历等操作,并且可以根据需要动态改变大小,使用者无须考虑容量限制的问题。
其次,列表可以基于链表或数组实现,不过更多时候,列表是基于数组实现的,但由于数组长度不可变的性质会导致列表的实用性降低。这是因为我们通常无法事先确定需要存储多少数据,从而难以选择合适的列表长度。若长度过小,则很可能无法满足使用需求;若长度过大,则会造成内存空间浪费。为解决此问题,我们可以使用动态数组(Dynamic Array)来实现列表。它继承了数组的各项优点,并且可以在程序运行过程中进行动态扩容。在许多编程语言中的标准库提供的列表是基于动态数组实现的,例如 Python 中的 list 、Java 中的 ArrayList 、C++ 中的 vector 和 C# 中的 List 等。在某种程度上,列表(List)可以被视为动态数组(Dynamic Array)。当列表需要增长时,Python 解释器会自动分配更大的内存空间,并将现有元素复制到新的内存空间中。这种实现使得列表在大多数情况下具有良好的性能,特别是对于随机访问操作。
最后,列表底层实现是数组,只是实现方式比较特殊。它们之间还是有一些区别的:
- 创建方式不同,列表(List)是 Python 的基础数据类型,不用引入任何库包,直接使用
[]创建即可。创建数组需要引入array模块才能创建。 - 存储方式不同,列表(List)中所有元素的内存地址是不连续的,这是由于 Python 列表中的每个元素实际上是一个指向对象的指针,这意味着列表存储的是指针的集合,这些指针指向存储在其他地方的实际数据对象。数组是一个连续的内存空间,每个元素都按照先后顺序排列在内存中。
- 数据类型不同,列表(List)可以放任意类型的对象,而数组在创建时必须声明存储的元素类型,且之后放入的每个元素都必须是该类型。
- 操作性能不同,列表(List)可以存储不同类型的数据,而数组只能存储相同类型的数据,也正由于数组中的所有项都具有相同的数据类型,所以操作在每个元素上的行为方式相同。因此,在处理大量同类数据类型时,数组的存储效率和访问速度要比列表更快,并且使用的内存更少。
- 应用场景不同,列表(List)比数组更加灵活和易用,因此通常更常用列表而不是数组,除非需要特定的性能优势或者需要存储大量相同类型的元素时,才会考虑使用数组。
区别NumPy
在我们讨论数组的主题时,得提一下 NumPy 数组。NumPy 数组在数据科学领域中被广泛用于处理多维数组, 它们通常比列表(List)和数组(Array)更高效。在NumPy数组中读取和写入元素更快,并且它们支持“矢量化”操作,例如元素添加。 此外,NumPy 数组可以有效地处理大型稀疏数据集。
python
import numpy as np
numpy_array = np.array([1, 2, 3, 4, 5])
print(numpy_array) # 输出:[1 2 3 4 5]
print(type(numpy_array)) # 输出:<class 'numpy.ndarray'>建议
通常使用 NumPy 库提供的 NumPy 数组进行数值计算或者处理大量数据,这是因为数组是由相同类型的元素组成的多维网格,可以进行高效的数值计算和操作。
数组应用
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
- 随机访问:如果我们想随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现随机抽样。
- 排序和搜索:数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表:当需要快速查找一个元素或其对应关系时,可以使用数组作为查找表。假如我们想实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习:神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。