DQL语言:基础查询
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
DQL语言:即数据查询语言,主要作用是查询检索数据库中的数据的SQL语言。
语法特点
sql
/*
语法:
SELECT 查询列表 FROM 表名;
特点:
1.查询列表可以是:表中的字段、常量值、表达式、函数。
2.查询的结果是一个虚拟的表格,不是真实存在的。
*/基础查询
查询单个字段
检索表中的单个列:SELECT 字段名称 FROM 表名;
| 类别 | 详细解释 |
|---|---|
| 基本语法 | SELECT 字段 FROM 表; |
| 示例 | SELECT id, name, money FROM star; |
| 示例说明 | 查询star表中id, username, money字段 |
!> 注意:如果查询的表在其他数据库,需要先指定数据库 USE 数据库名;
sql
-- 因为Navicat默认指定了表所在的数据库,就不用再次指定数据库了
SELECT last_name FROM employees;
查询多个字段
检索表中的多个列:SELECT 字段名称, 字段名称... FROM 表名;
!> 注意:查询时,要在表所在的数据库中查询。如果查询的表在其他数据库,需要先指定数据库 USE 数据库名;
sql
-- 因为Navicat默认指定了表所在的数据库,就不用再次指定数据库了
SELECT
last_name,
salary,
email
FROM
employees;
查询所有字段
检索表中的所有列:SELECT * FROM 表名
| 类别 | 详细解释 |
|---|---|
| 基本语法 | SELECT * FROM 表; |
| 示例 | SELECT * FROM star; |
| 示例说明 | 查询star表中所有字段中的所有结果 |
?> 提示:* 表示通配符,匹配所有列。
sql
SELECT
*
FROM
employees;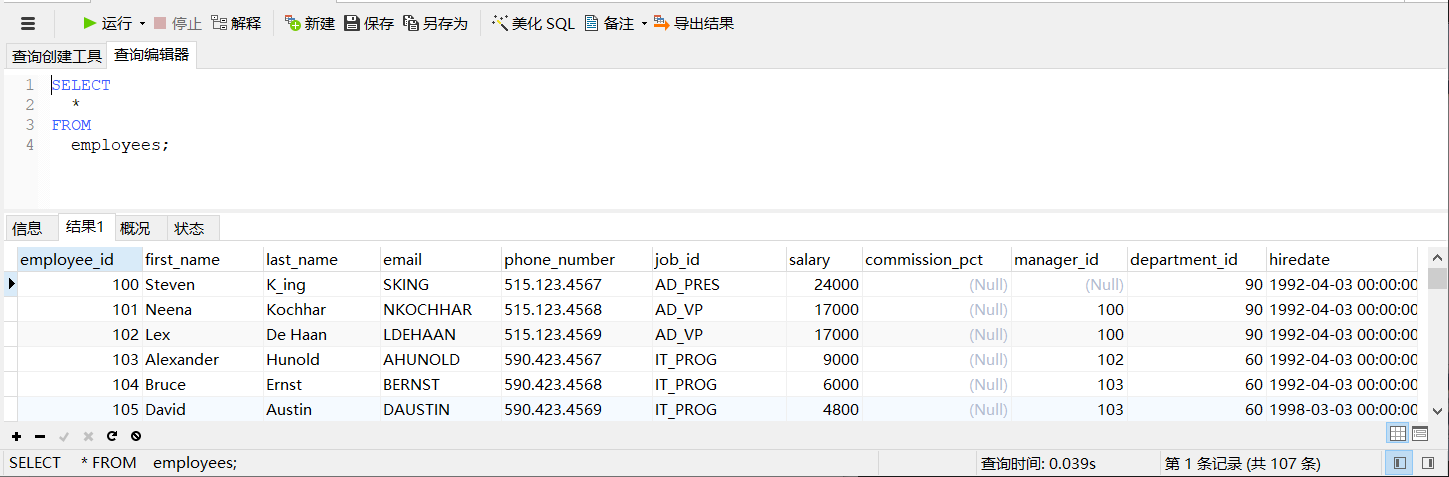
查询常量值
SQL语句可以查询常量值,只不过查询结果的字段名称和字段内容都是查询值。
sql
SELECT 100;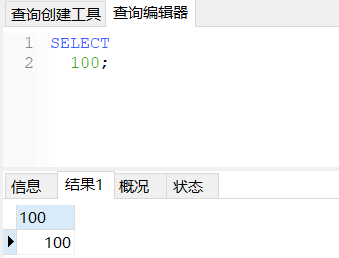
sql
SELECT 'john';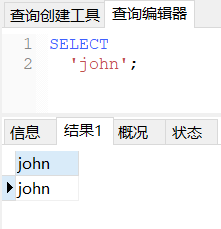
查询表达式
SQL语句还可以执行加减乘除的表达式,字段名称就是查询名称,内容就是计算结果。
sql
SELECT
100*98;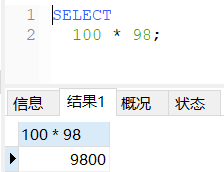
!> 注意:在SQL语言中"+"号仅仅只有一个功能:运算符。
sql
-- 两个操作数都为数值型,则做加法运算(下方结果为:190)
SELECT
100 + 90;
-- 一方操作数是纯数字字符型,转换成数值型,做加法运算(下方结果为:213)
SELECT
'123' + 90;
-- 一方操作数不是纯数字字符型,转换成数值型的0,做加法运算(下方结果为:90)
SELECT
'john' + 90;
-- 只要一方操作数为NULL,则结果肯定为NULL(下方结果为:NULL)
SELECT
NULL + 90;查询函数
sql
-- 查询当前数据库版本
SELECT
VERSION();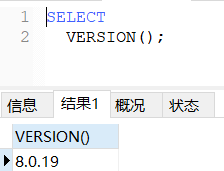
基础功能
AS别名
上面的查询有一个不方便的地方,就是查询结果的字段名称不直观,这里就可以使用“起别名”功能:
- 方便理解查询字段的意思;
- 查询的字段有重名的情况,使用别名可以区分开来。
as关键字:将一个字段或值的名称替换成另一个名称。
sql
SELECT
100 * 98 AS 结果;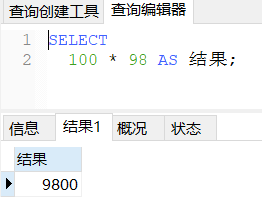
as关键字是可以用空格代替的。
sql
SELECT
100 * 98 结果;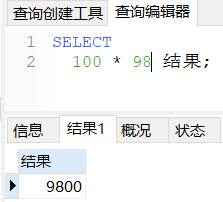
需要注意的是,如果更名后的名称中本身带有空格,需要加上单引号或双引号。
sql
SELECT
salary "out put"
FROM
employees;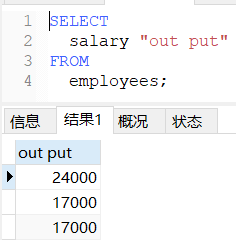
DISTINCT去重
去重检索表中的单个列:SELECT DISTINCT 字段名称 FROM 表名;
| 类别 | 详细解释 |
|---|---|
| 基本语法 | SELECT DISTINCT 字段 FROM 表; |
| 示例 | SELECT DISTINCT age FROM star; |
| 示例说明 | 查询star表中age字段不重复结果; |
sql
-- 查询员工表中涉及到的所有的部门编号
SELECT DISTINCT
department_id
FROM
employees;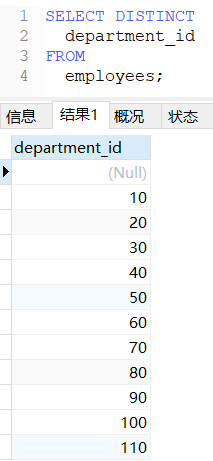
LIMIT分页
LIMIT用于分页限制查询结果返回的数量。
应用场景:当要显示的数据,一页显示不全,需要分页提交SQL请求。
返回结果前m行数据:SELECT 字段名称 FROM 通用认证信息 LIMIT m;
| 类型 | 说明 |
|---|---|
| 基本语法 | SELECT 字段 FROM 表 LIMIT 数量; |
| 示例 | SELECT * FROM star LIMIT 5; |
| 示例说明 | 显示前5条记录; |
返回结果第m行后n行数据:SELECT 字段名称 FROM 通用认证信息 LIMIT m,n;
| 类型 | 说明 |
|---|---|
| 基本语法 | SELECT 字段 FROM 表 LIMIT 偏移量,数量; |
| 示例 | SELECT * FROM star LIMIT 0,3; |
| 示例说明 | 显示从第一条开始的后三条记录; |
!> 注意:LIMIT位置始终在查询语句的末尾。
sql
/*
table_name:通用认证信息
+----+--------------+
| id | 公司名称 |
+----+--------------+
| 1 | 小白公司 |
| 2 | 小明公司 |
| 3 | 小红公司 |
+----+--------------+
*/
SELECT id, 公司名称 FROM 通用认证信息 LIMIT 1;
/*
返回结果第1行数据(包括第1行)
+----+--------------+
| id | 公司名称 |
+----+--------------+
| 1 | 小白公司 |
+----+--------------+
1 row in set (0.00 sec)
*/
SELECT id, 公司名称 FROM 通用认证信息 LIMIT 1,2;
/*
# 返回结果第1行的后2行数据(不包括第1行)
+----+--------------+
| id | 公司名称 |
+----+--------------+
| 2 | 小明公司 |
| 3 | 小红公司 |
+----+--------------+
2 rows in set (0.00 sec)
*/
-- 如果每页的查询条数固定,我们可以总结出查询公式
/*
显示的页数:page,每页的条目数:size
SELECT 查询列表
FROM 表名
LIMIT (page-1)*size,size;
*/UNION联合
sql
/*
UNION联合查询:将多个表的数据按照查询条件查询,并将结果合并到一起显示。
语法:
查询语句1
UNION
查询语句2
UNION
...
应用场景:
要查询的结果来自多个表,且多个表没有直接的连接关系,但查询的信息一致时,可以使用联合查询。
特点:
1、要求多条查询语句的查询列数是一致的
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、UNION关键字默认去重,如果使用UNION ALL可以包含重复项
*/?> 提示:关键字 union 、union all 两者主要的区别是, union 将 union all 后的结果进行一次 distinct 去除重复记录后的结果。
sql
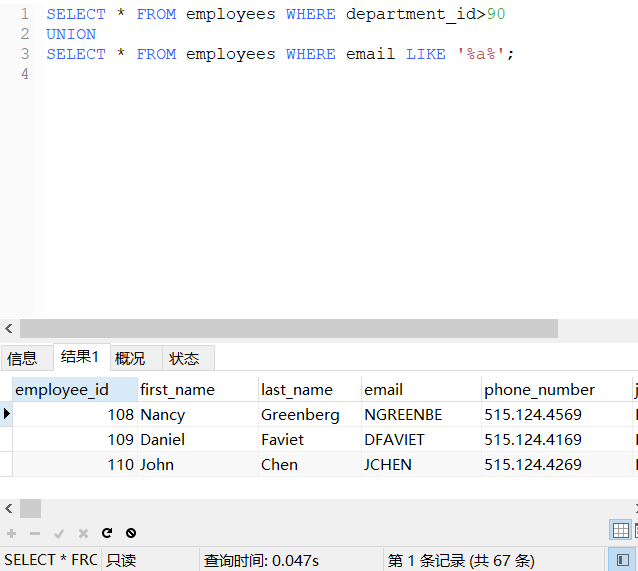
-- 查询部门编号大于90或邮箱中包含a的员工信息
SELECT * FROM employees WHERE department_id>90
UNION
SELECT * FROM employees WHERE email LIKE '%a%';