认识LUA脚本、性能调优
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
认识LUA脚本
Lua语言是在1993年由巴西一个大学研究小组发明,其设计目标是作为嵌入式程序移植到其他应用程序,它是由C语言实现的,虽然简单小巧但是功能强大,所以许多应用都选用它作为脚本语言,尤其是在游戏领域,例如大名鼎鼎的暴雪公司将Lua语言引入到“魔兽世界”这款游戏中,Rovio公司将Lua语言作为“愤怒的小鸟”这款火爆游戏的关卡升级引擎,Web服务器Nginx 将Lua语言作为扩展,增强自身功能。**Redis将Lua作为脚本语言可帮助开发者定制自己的Redis命令。**Lua语言提供了如下几种数据类型:booleans(布尔)、numbers(数值)、strings(字符串)、tables(表格),和许多高级语言相比,相对简单。
简单语法
lua
-- "--"是Lua语言的注释
-- local代表val是一个局部变量,如果没有local代表是全局变量。
local strings val = "world"
print(val) -- 打印字符串"world"
-- 在Lua中,如果要使用类似数组的功能,可以用tables类型。
-- 定义了一个tables类型的变量 `myArray`,但和大多数编程语言不同的是,Lua的数组下标从1开始计算。
local tables myArray = {"redis", "jedis", true, 88.0}
print(myArray[3]) -- 输出true
-- 使用for和while可以遍历这个数组,关键字for以end作为结束符。
-- 遍历myArray,首先需要知道tables的长度,只需要在变量前加一个 `#` 号即可
for i = 1, #myArray
do
print(myArray[i])
end
-- 使用for循环计算1到100的和
local int sum = 0
for i = 1, 100
do
sum = sum + i
end
print(sum) -- 输出结果为5050
-- 使用while循环计算1到100的和
local int sum = 0
local int i = 0
while i <= 100
do
sum = sum +i
i = i + 1
end
print(sum) -- 输出结果为5050
-- Lua还提供了内置函数ipairs可以遍历出所有的索引下标和值
for index,value in ipairs(myArray)
do
print(index)
print(value)
end
-- if判断,then紧跟,end结尾
-- 要确定数组中是否包含了jedis,有则打印true
local tables myArray = {"redis", "jedis", true, 88.0}
for i = 1, #myArray
do
if myArray[i] == "jedis"
then
print("true")
break
else
--do nothing
end
end
-- 哈希,使用类似哈希的功能,同样可以使用tables类型。
-- 定义了一个tables,每个元素包含了key和value,其strings1..string2是将两 个字符串进行连接:
local tables user_1 = {age = 28, name = "tome"}
print("user_1 age is " .. user_1["age"]) -- user_1 age is 28
-- 函数定义,在Lua中,函数以 `function` 开头,以 `end` 结尾,`funcName` 是函数名,中间部分是函数体:
function funcName()
...
end
-- contact函数将两个字符串拼接:
function contact(str1, str2)
return str1 .. str2
end
print(contact("hello ", "world")) -- "hello world"执行脚本
**Redis当中可以使用 redis-cli --eval 选项用于执行指定Lua脚本。**Lua脚本功能为Redis开发和运维人员带来如下三个好处:
- Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
- Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在Redis内存中,实现复用的效果。
- Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
在Redis中执行Lua脚本还可以使用 eval 命令,其本质 --eval 选项是一样的,客户端如果想执行Lua脚本,首先在客户端编写好Lua脚本代码,然后把脚本作为字符串发送给服务端,服务端会将执行结果返回给客户端。
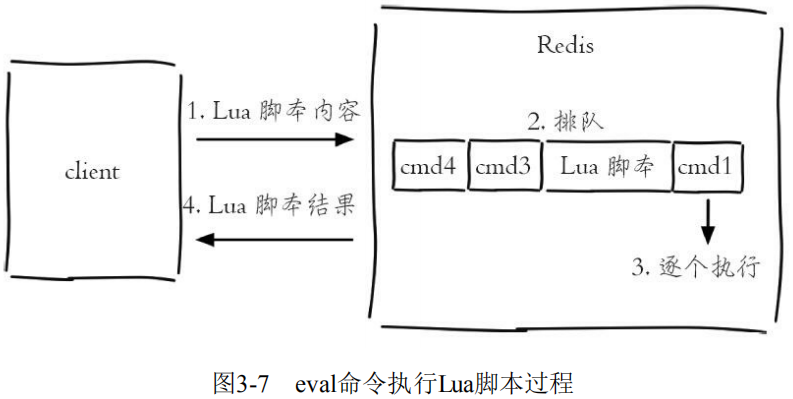
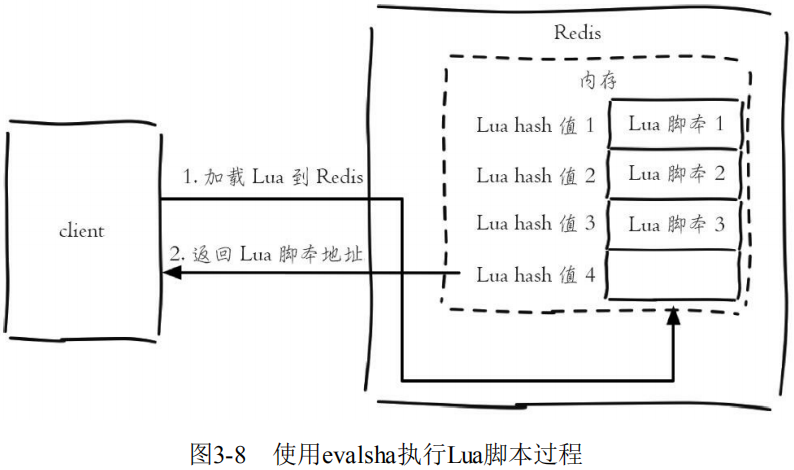
Redis还提供了 evalsha 命令来执行Lua脚本。首先要将Lua脚本加载到Redis服务端,得到该脚本的SHA1校验和,evalsha 命令使用SHA1作为参数可以直接执行对应Lua脚本,避免每次发送Lua脚本的开销。这样客户端就不需要每次执行脚本内容,而脚本也会常驻在服务端,脚本功能得到了复用。
脚本命令
加载脚本:script load 命令可以将Lua脚本内容加载到Redis内存中。
script load script将 lua_get.lua 加载到Redis中,得到SHA1 为:"7413dc2440db1fea7c0a0bde841fa68eefaf149c"
# redis-cli script load "$(cat lua_get.lua)"
"7413dc2440db1fea7c0a0bde841fa68eefaf149c"是否加载:script exists 命令用于判断sha1是否已经加载到Redis内存中。返回结果代表sha1[sha1…]被加载到Redis内存的个数。
127.0.0.1:6379> script exists a5260dd66ce02462c5b5231c727b3f7772c0bcc5
1) (integer) 1清除脚本:script flush 命令用于清除Redis内存已经加载的所有Lua脚本。
127.0.0.1:6379> script exists a5260dd66ce02462c5b5231c727b3f7772c0bcc5
1) (integer) 1
127.0.0.1:6379> script flush
OK
127.0.0.1:6379> script exists a5260dd66ce02462c5b5231c727b3f7772c0bcc5
1) (integer) 0执行脚本:evalsha 的使用方法如下,参数使用SHA1值,执行逻辑和 eval 一致。
evalsha 脚本SHA1值 key个数 key列表 参数列表调用 lua_get.lua 脚本:
127.0.0.1:6379> evalsha 7413dc2440db1fea7c0a0bde841fa68eefaf149c 1 redis world "hello redisworld"杀掉脚本:script kill 命令用于杀掉正在执行的Lua脚本。
script kill!> 注意:有一点需要注意,如果当前Lua脚本正在执行写操作,那么 script kill 将不会生效。要么等待脚本执行结束要么使用 shutdown save 停掉Redis服务。可见Lua脚本虽然好用,但是使用不当破坏性也是难以想象的。
性能调优
在使用Redis过程中,免不了大量数据或命令在Redis中的快进快出,因此我们需要进行性能上的调优学习。
输入缓冲区
Redis为每个客户端分配了输入缓冲区,它的作用是将客户端发送的命令临时保存,同时Redis从会输入缓冲区拉取命令并执行,输入缓冲区为客户端发送命令到Redis执行命令提供了缓冲功能。
Redis没有提供相应的配置来规定每个缓冲区的大小,输入缓冲区会根据输入内容大小的不同动态调整,只是要求每个客户端缓冲区的大小不能超过1G,超过后客户端将被关闭。
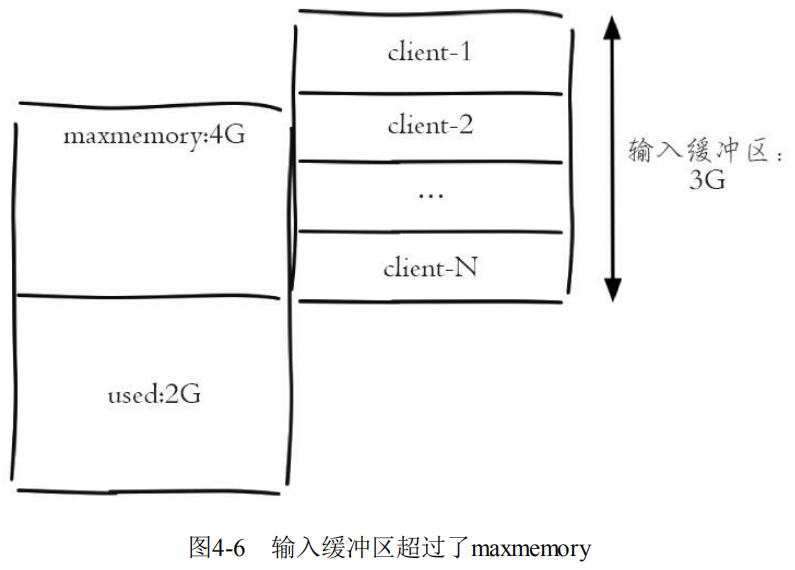
输入缓冲区不受maxmemory控制,假设maxmemory为4G,已经存储了2G数据,但是如果此时输入缓冲区使用了3G,已经超过maxmemory限制,可能会产生数据丢失、键值淘汰、OOM等情况。
输入缓冲区过大主要是因为Redis的处理速度跟不上输入缓冲区的输入速度,并且每次进入输入缓冲区的命令包含了大量bigkey,从而造成了输入缓冲区过大的情况。还有一种情况就是Redis发生了阻塞,短期内不能处理命令,造成客户端输入的命令积压在了输入缓冲区,造成了输入缓冲区过大。
监控输入缓冲区的方法有两种:
定期执行 client list 命令,收集qbuf和qbuf-free找到异常的连接记录并分析,最终找到可能出问题的客户端。
- qbuf:缓冲区的总容量。
- qbuf-free:缓冲区的剩余容量。
**info clients 命令:输出内容中 client_biggest_input_buf 代表最大的输入缓冲区。**可以设置最大的输入缓冲区超过10M就进行报警:
127.0.0.1:6379> info clients
# Clients
connected_clients:1414
client_longest_output_list:0
client_biggest_input_buf:2097152
blocked_clients:0
输出缓冲区
Redis为每个客户端分配了输出缓冲区,它的作用是保存命令执行的结果返回给客户端,为Redis和客户端交互返回结果提供缓冲。
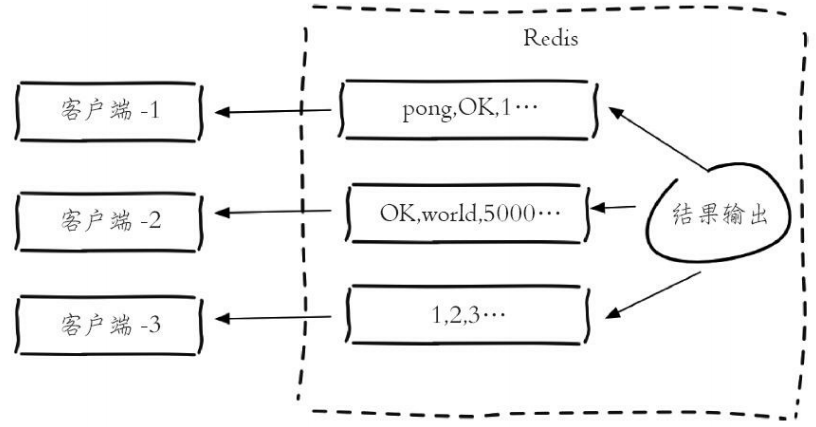
输出缓冲区由两部分组成:固定缓冲区(16KB)和动态缓冲区,其中固定缓冲区返回比较小的执行结果,而动态缓冲区返回比较大的结果,例如大的字符串、hgetall、smembers命令的结果等。
固定缓冲区使用的是字节数组,动态缓冲区使用的是列表。当固定缓冲区存满后会将Redis新的返回结果存放在动态缓冲区的队列中,队列中的每个对象就是每个返回结果。
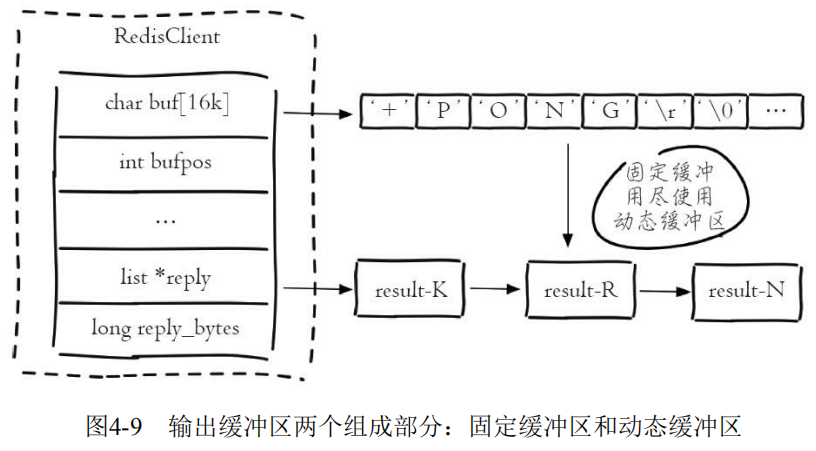
- obl:固定缓冲区的长度。
- oll:动态缓冲区列表的长度。
- omem:使用的字节数
当前客户端的固定缓冲区的长度为0,动态缓冲区有4869个对象,两个部分共使用了133081288字节=126M内存:
id=7 addr=127.0.0.1:56358 fd=6 name= age=91 idle=0 flags=O db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=4869 omem=133081288 events=rw cmd=monitor输出缓冲区的容量可以通过参数 client-output-buffer-limit 来进行设置,并且输出缓冲区做得更加细致,按照客户端的不同分为三种:普通客户端、发布订阅客户端、slave客户端。
对应的配置规则是:
client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds><class>:客户端类型,分为三种。a)normal:普通客户端;b)slave:slave客户端,用于复制;c)pubsub:发布订阅客户端。
<hard limit>:如果客户端使用的输出缓冲区大于<hard limit>,客户端会被立即关闭。<soft limit>和<soft seconds>:如果客户端使用的输出缓冲区超过了<soft limit>并且持续了<soft limit>秒,客户端会被立即关闭。
Redis的默认配置是:
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60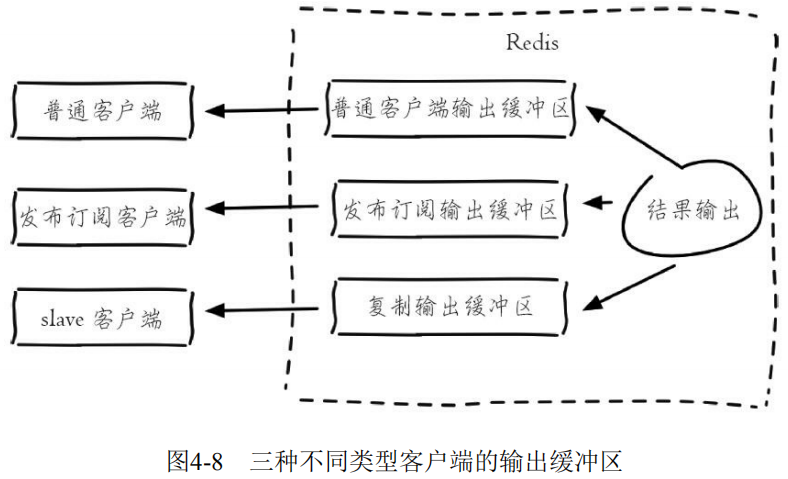
输出缓冲区也不会受到maxmemory的限制,如果使用不当同样会造成maxmemory用满产生的数据丢失、键值淘汰、OOM等情况。
监控输出缓冲区的方法依然有两种:
通过定期执行 client list 命令,收集obl、oll、omem找到异常的连接记录并分析,最终找到可能出问题的客户端。
info clients命令:找到输出缓冲区列表最大对象client_biggest_input_buf。
127.0.0.1:6379> info clients
# Clients
connected_clients:502
client_longest_output_list:4869
client_biggest_input_buf:0
blocked_clients:0预防输出缓冲区出现异常:
- 进行上述监控,设置阀值,超过阀值及时处理。
- 限制普通客户端输出缓冲区的,把错误扼杀在摇篮中。
client-output-buffer-limit normal 20mb 10mb 120- 适当增大slave的输出缓冲区的,如果master节点写入较大,slave客户端的输出缓冲区可能会比较大,一旦slave客户端连接因为输出缓冲区溢出被kill,会造成复制重连。
- 限制容易让输出缓冲区增大的命令,例如,高并发下的monitor命令就是一个危险的命令。
- 及时监控内存,一旦发现内存抖动频繁,可能就是输出缓冲区过大。
慢查询分析
慢查询分析:通过慢查询分析,找到有问题的命令进行优化。
许多存储系统(例如MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来,Redis也提供了类似的功能。
需要注意的是,慢查询只统计步骤3,即命令的执行时间。
预设阈值命令 slowlog-log-slower-than :单位是微秒(1秒=1000毫秒=1000000微秒),默认值是10000,假如执行了一条“很慢”的命令(例如keys*),如果它的执行时间超过了10000微秒,那么它将被记录在慢查询日志中。
?> 提示:如果 slowlog-log-slower-than=0 会记录所有的命令,slowlog-log-slower-than<0 对于任何命令都不会进行记录,建议配置默认值超过10毫秒判定为慢查询。
慢查询日志长度 slowlog-max-len:实际上是一个列表来存储慢查询日志,slowlog-max-len 就是列表的最大长度。
如果慢查询日志列表已处于其最大长度时,最早插入的一个命令将从列表中移出,这样可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行 slow get 命令将慢查询日志持久化到其他存储中(例如MySQL)
?> 提示:slowlog-max-len 配置建议,设置为1000以上。
使用 config set 命令将 slowlog-log-slower-than 设置为20000微秒,slowlog-max-len 设置为1000,再执行 config rewrite 命令将配置持久化到本地配置文件:
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite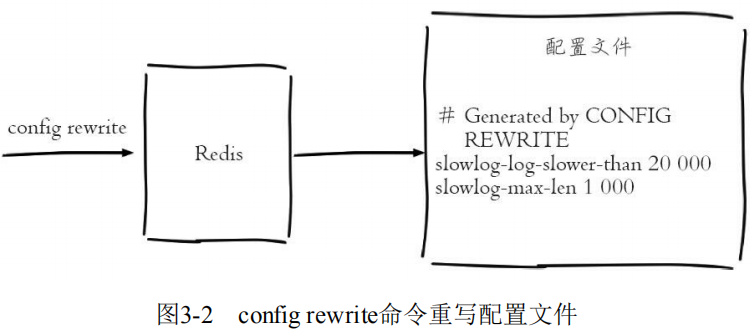
获取慢查询日志
slowlog get [n]- 参数n可以指定条数
127.0.0.1:6379> slowlog get
1) 1) (integer) 666
2) (integer) 1456786500
3) (integer) 11615
4) 1) "BGREWRITEAOF"
2) 1) (integer) 665
2) (integer) 1456718400
3) (integer) 12006
4) 1) "SETEX"
2) "video_info_200"
3) "300"
4) "2" ...每个慢查询日志有4个属性组成,分别是慢查询日志的标识 id、发生时间戳、命令耗时、执行命令和参数:
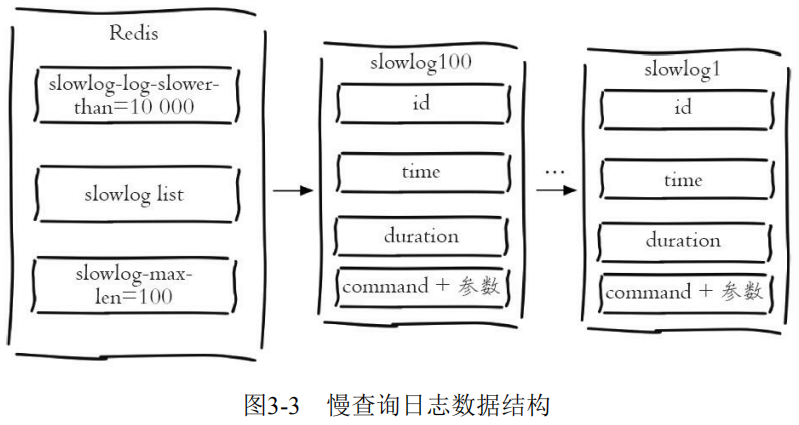
获取慢查询日志列表当前的长度
slowlog len当前Redis中有45条慢查询:
127.0.0.1:6379> slowlog len
(integer) 45慢查询日志重置
slowlog reset实际是对列表做清理操作:
127.0.0.1:6379> slowlog len
(integer) 45
127.0.0.1:6379> slowlog reset
OK
127.0.0.1:6379> slowlog len
(integer) 0