简单访问逻辑
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
保持会话
题目难度:非常简单
进入题目获取任务,往后翻2页,发现每次翻页后服务器都会要求带上新的 sign 值和新的 sessionid 值:
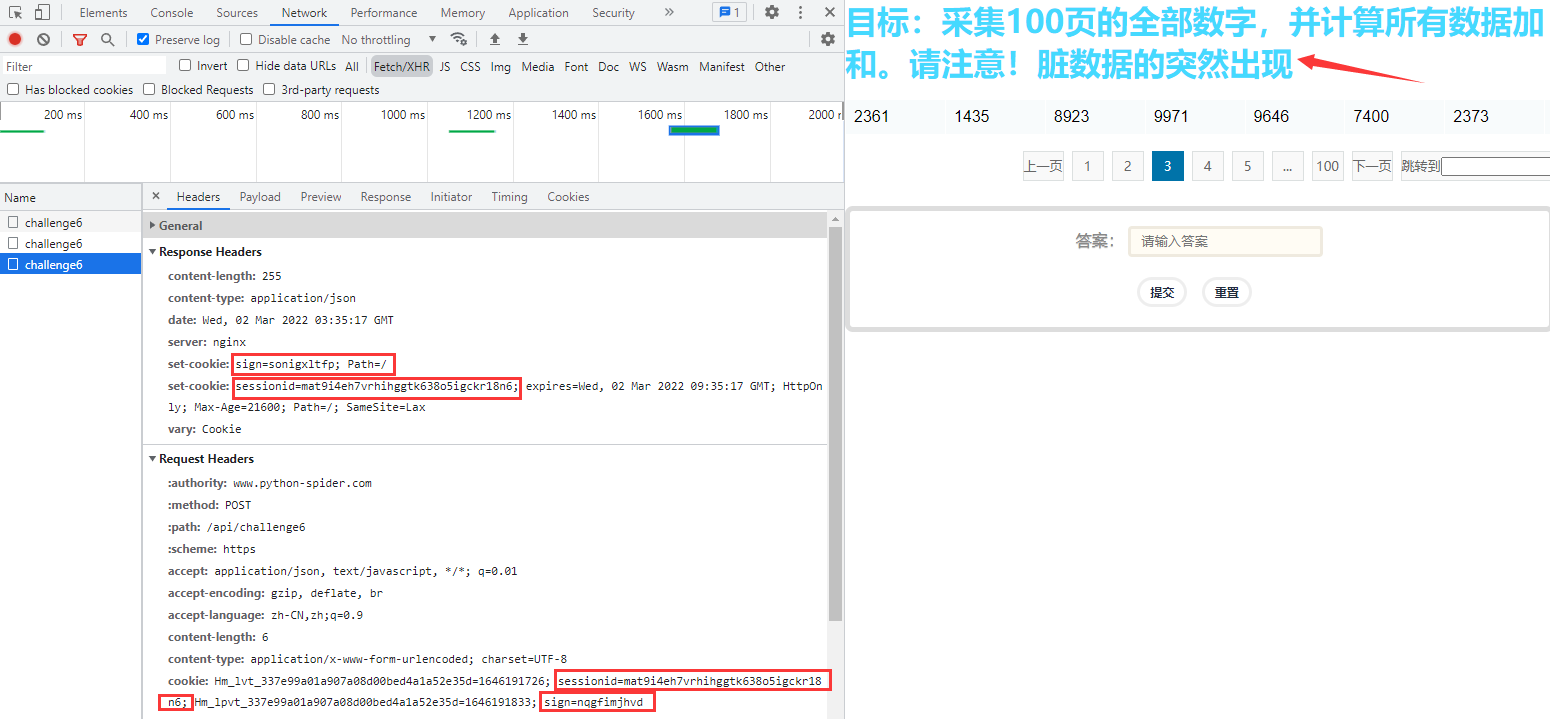
解题方法:结合题目的标题和请求分析总结得出,每次请求都要沿用上一个请求响应头返回的 sign 值和 sessionid 值,通过验证 Cookie 的 sign 值和 sessionid 值来判断是否返回脏数据。
访问逻辑检测
题目难度:非常简单
访问题目获取题目信息后,往后翻2页,发现每次翻页前都会有一个 cityjson 请求:
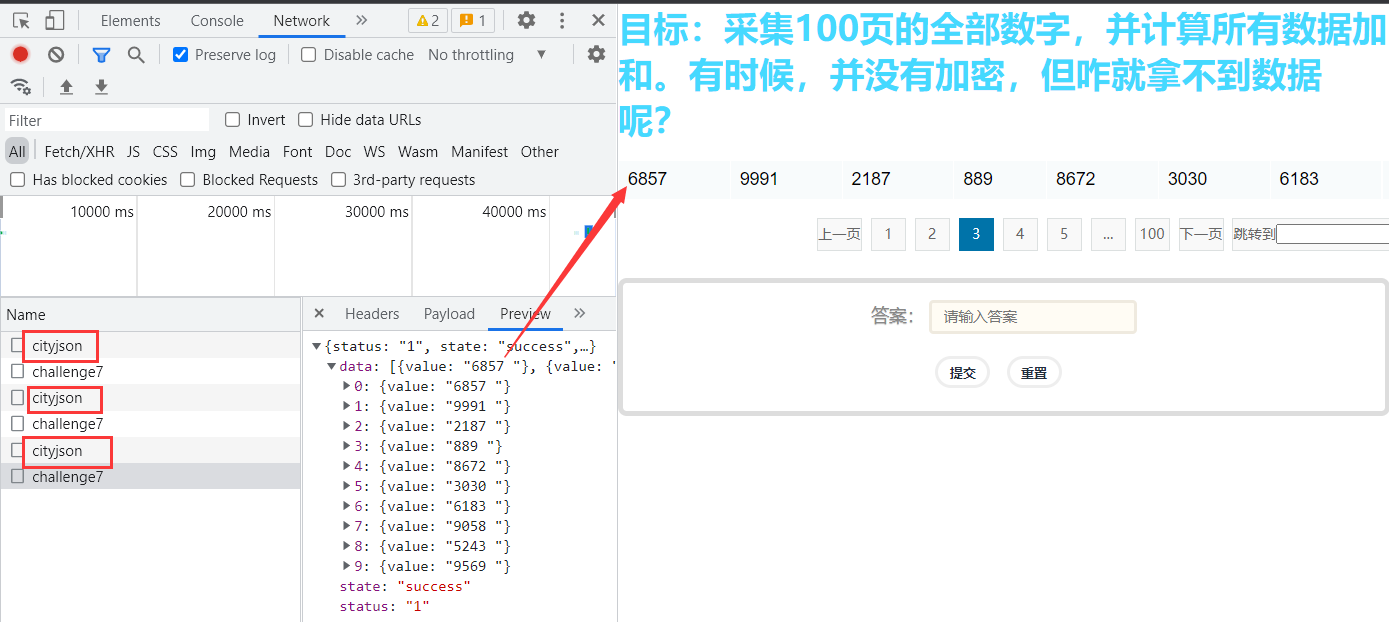
查看Fiddler的抓包,一模一样:
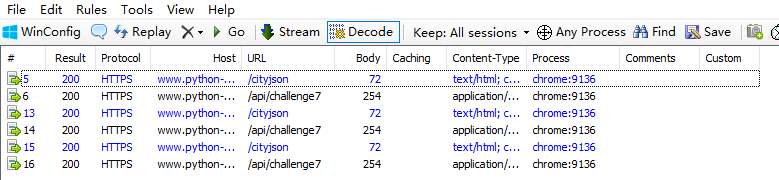
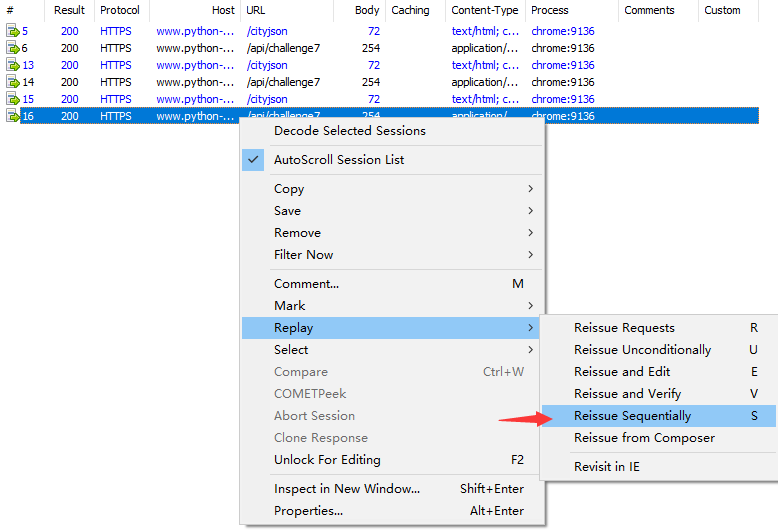
接下来,我们只选中 /api/challenge7 进行重放(重新请求访问),选中请求右键选择 Replay 选中 Reissue Sequentially 点击:
输入重放次数,我们输入3,点击OK:
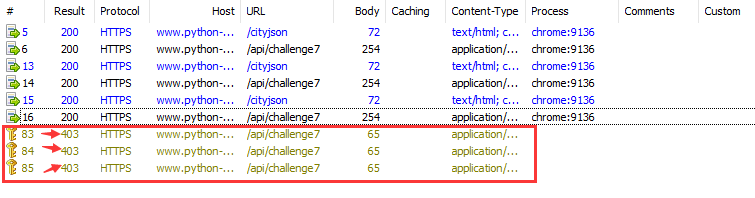
进行3次重放攻击,发现请求的状态码都是403,说明只访问 /api/challenge7 行不通:
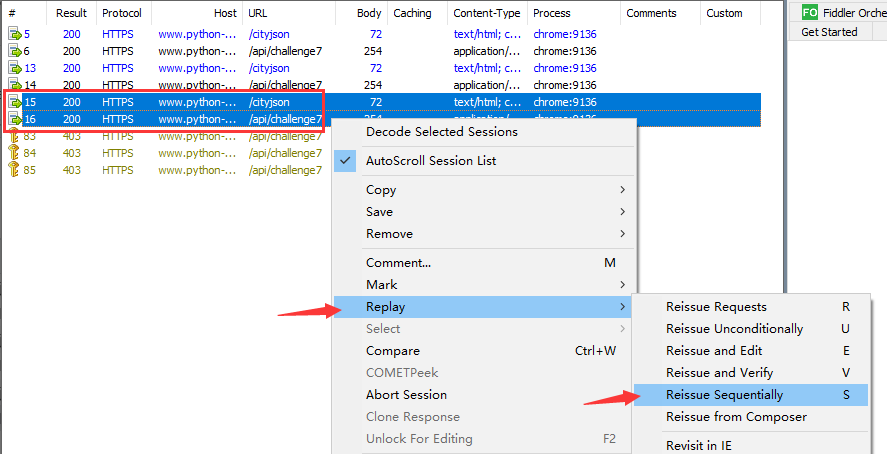
同时选中 /cityjson 和 /api/challenge7 两个请求进行重放攻击:
这里可以看到当两个请求一起重放就成功获取到数据了:
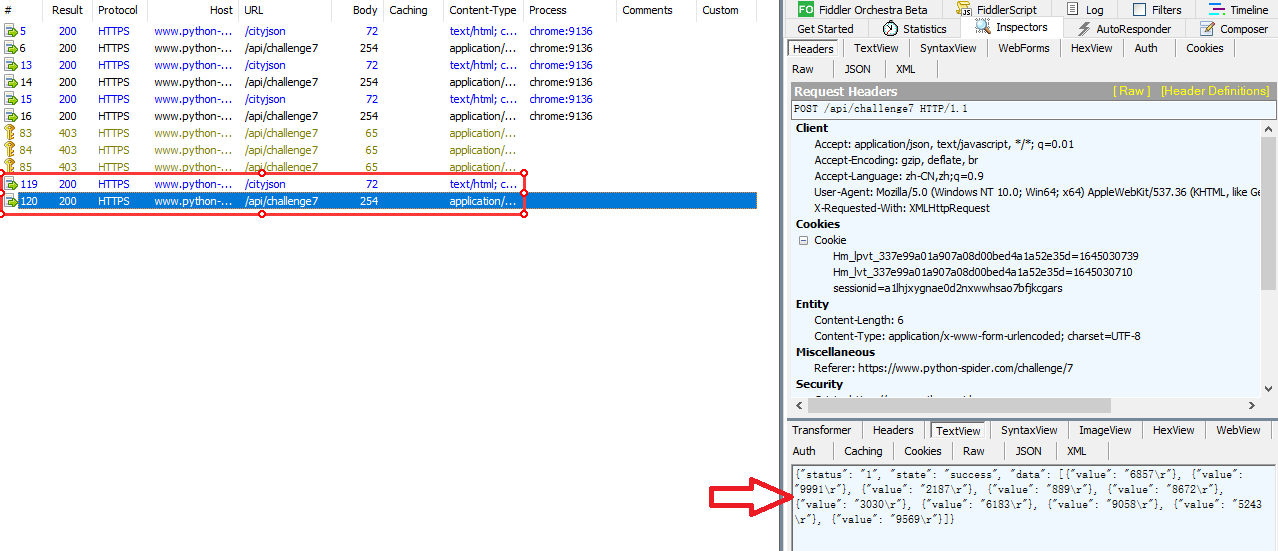
解题方法:必须先访问一次 /cityjson 接口,再访问 /api/challenge7 接口才能拿到数据。
头部顺序检测
题目难度:非常简单
首先访问题目获取题目信息后,往后翻2页:
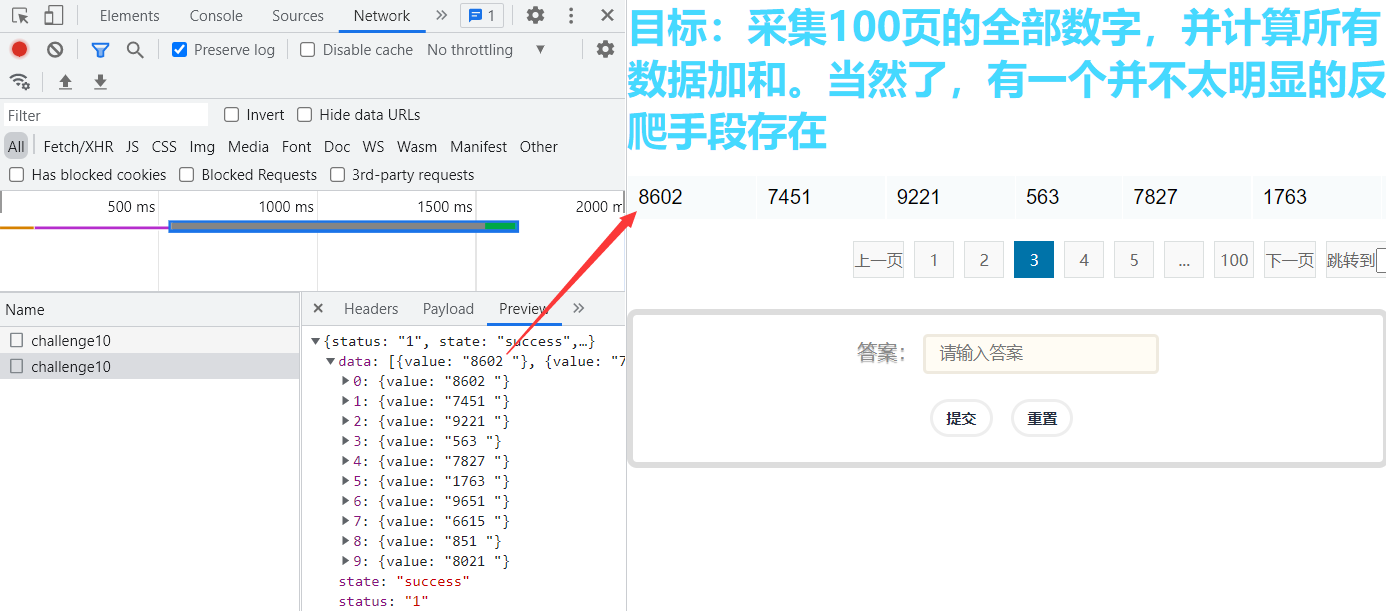
查看Fiddler的抓包,一模一样:
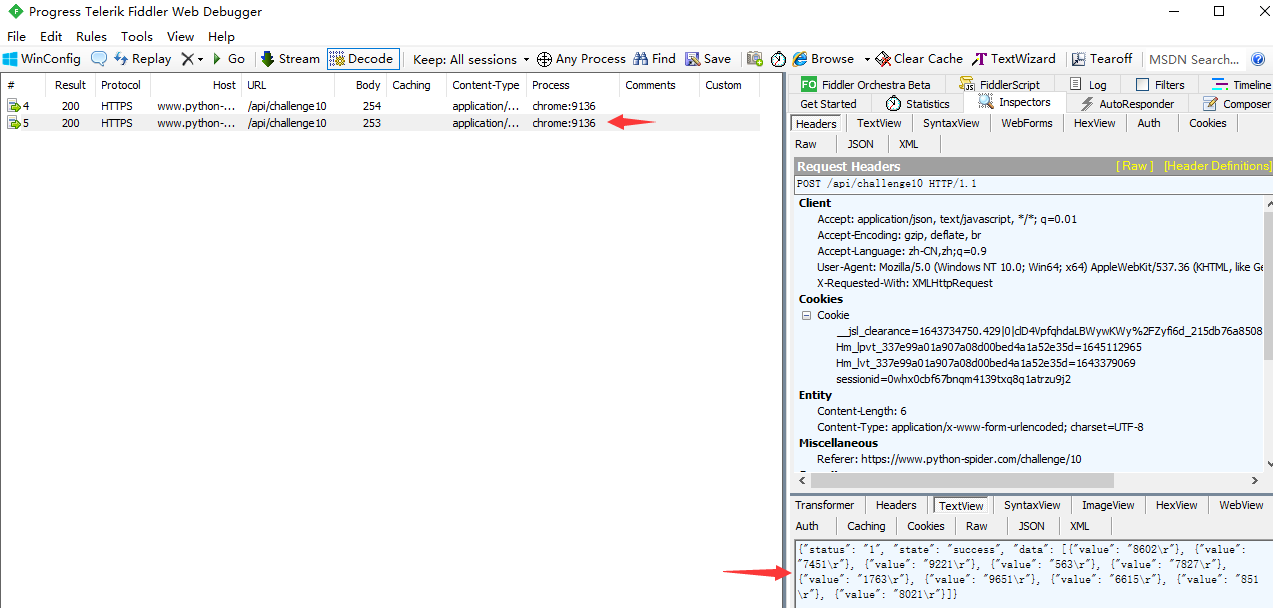
接下来,我们只选中 /api/challenge10 进行重放(重新请求访问),选中请求右键选择 Replay 选中 Reissue Sequentially 点击:
输入重放次数,我们输入3,点击OK:
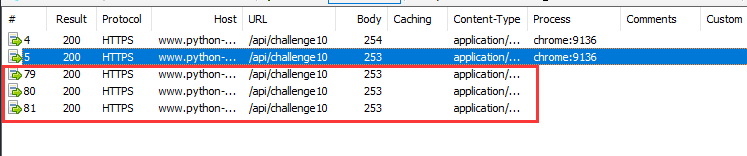
进行3次重放攻击,发现能成功获取到数据:
现在我们拷贝Fiddler里面的请求头参数到爬虫程序中,选中数据包——点击右侧“header”——右键“Copy All Headers”:
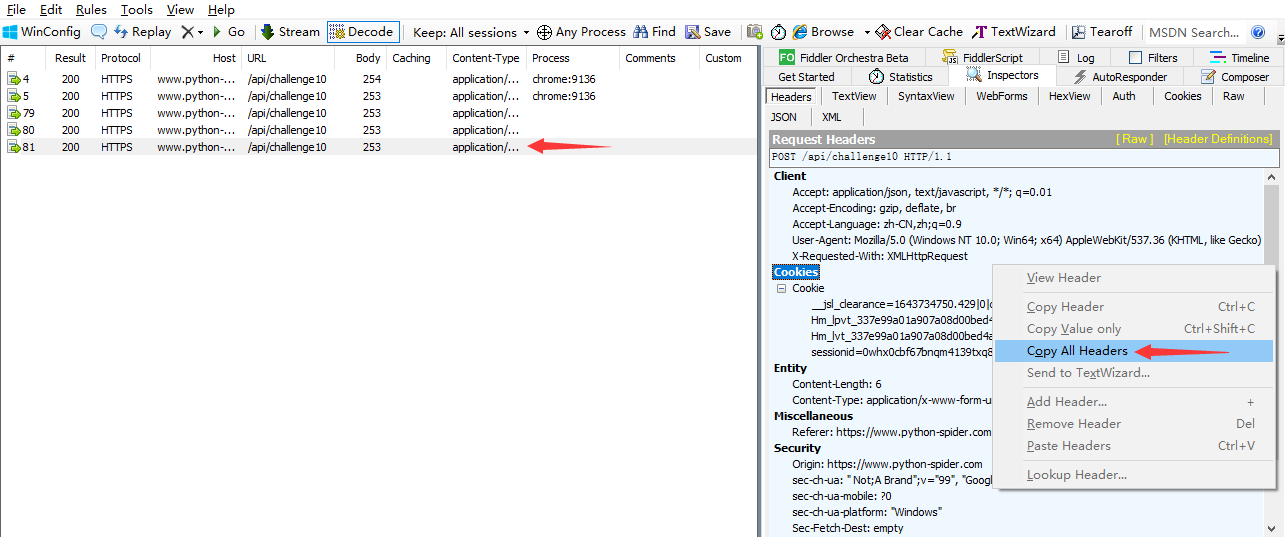
但是当我们从Fiddler拷贝请求头到爬虫程序中,进行访问时却行不通:
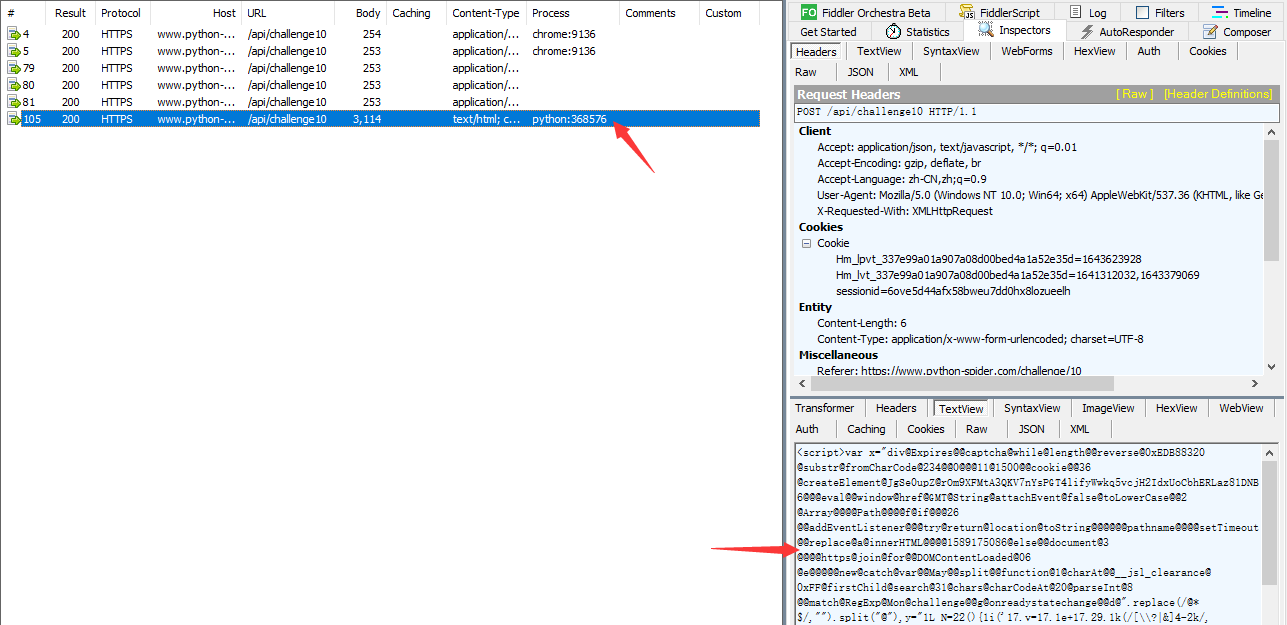
通过对比发现,爬虫请求的 headers 字段顺序和浏览器请求的 headers 字段顺序不一样,但爬虫的 headers 是来源于 Fiddler 的拷贝,为什么发送请求的时候 headers 字段顺序改变了呢?原因在于,通过会话对象的 headers 参数添加请求头会改变请求头的字段顺序,而通过会话对象的 headers 属性添加请求头会固化请求头的字段顺序。
python
import requests
# 链接
url = '...'
# 请求头
headers = '...'
# 建立一个会话对象
session = requests.session()
# 通过headers参数添加请求头,会改变请求头的字段顺序
response = session.post(url=url, headers=headers)
# 通过headers属性添加请求头,会固化请求头的字段顺序
session.headers = headers
# 下面请求自带请求头,且顺序也不会被打乱
response = session.post(url=url)注意
Chrome开发者工具的请求头参数顺序是经过调整了的,使用这个请求头是拿不到数据的,必须使用Fiddler里面的请求头参数顺序。