Scrapy框架【爬虫】
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
普通爬虫
在前面的 Scrapy 项目中,爬虫文件中的 QuotesSpider 类继承自 scrapy.Spider 这个最简单、最基本的 Spider 类,整个网站的链接配置、抓取逻辑、解析逻辑也都是在 Spider 中配置的,这里我们再深入的学习 Spider 组件的使用。
属性方法
scrapy.Spider 类有一些基础属性,下面对其进行详解:
name爬虫名称,定义 Spider 的字符串名称,是 Spider 最重要的属性。它定义了 Scrapy 如何定位并初始化 Spider,所以它必须是唯一的。不过我们可以生成多个相同的 Spider 对象,这没有任何限制。allowed_domains允许爬取的域名,是一个可选的配置,不在此范围的链接不会被跟进爬取。start_urls起始URL列表,即种子链接,当我们启动爬虫开始爬取时,默认会从这个列表开始抓取。custom_settings爬虫配置,是当前 Spider 的专属配置,此配置会覆盖项目中settings.py文件针对所有爬虫的全局设置,而且此配置必须在初始化前被更新,所以它必须定义成类属性。crawler此属性是由from_crawler方法设置,代表 Spider 类对应的 Crawler 对象。Crawler 对象中包含了很多项目组件,利用它我们可以获取项目的一些配置信息,常见的就是获取项目的设置信息,即Settings。settings一个 Settings 对象,利用它我们可以直接获取项目的全局设置变量。
scrapy.Spider 类还有一些常用方法,下面对其进行详解:
start_requests初始请求方法,该方法会默认使用start_urls里面的 URL 来构造 Request 请求对象。parse默认的回调解析方法,当 Response 响应对象没有指定callback回调方法时,默认将其交由给该方法进行解析,并从中提取想要的数据和下一步的请求。需要注意的是,该方法是起始解析方法,在scrapy.Spider类中必须存在,且需要返回 Request 请求对象、ltem 数据对象或 None 其中之一。closed关闭爬虫,当 Spider 关闭时,该方法会被调用,这里一般会定义释放资源的一些操作或其他收尾操作。
Request
在 Scrapy 中,Request 实际上是 scrapy.http.Request 的一个实例化的请求对象,它里面包含了 HTTP 请求的基本信息。这个 Request 请求对象会被 Engine 交给 Downloader 进行处理执行,返回一个 Response 响应对象。它的构造参数如下:
url请求的链接。callback回调方法,解析 Response 响应对象的方法,默认使用 Spider 类里面的parse方法。method请求类型,默认是 GET,还可以设置为 POST、PUT、DELETE 等。meta参数传递,字典的形式,向回调方法传递信息,包含的信息不受限制。需要注意的是,在默认情况下,Scrapy 预留了一些 key 作为特殊处理,比如request.meta['proxy']设置请求时使用的代理,request.meta['max_retry_times']设置请求的最大重试次数等。body请求体,常用于 POST 请求。当然我们也可以使用FormRequest类或JsonRequest类来实现 POST 请求。headers请求头,字典形式。cookies请求 Cookie,可以是字典或列表形式。需要注意的是,如果将 Cookie 写在headers参数里面,那么在后续的请求中 Cookie 可能会断,因此就必须将 Cookie 赋值给该参数,这样在后续的所有请求中都会携带该 Cookie,这就类似于 requests 中的 session 会话。encoding请求编码,默认是 UTF-8 。prority请求优先级,默认是 0,这个优先级是给 Scheduler 对 Request 调度使用的,数值越大,就越被优先被调度。dont_filter过滤器,Scrapy 可以会根据 Request 的指纹信息进行去重,默认False代表去重,若设置True代表忽略 Request 去重。errback错误处理方法,如果在请求处理过程中出现了错误,就调用这个方法。flags请求的标志,可以用于记录类似的处理。cb_kwargs回调方法的额外参数,可以作为字典传递。
初始请求
前面说过 parse 方法中的参数 response 默认是 start_url 里面的链接爬取后的 Response 响应对象,这是因为我们继承的 scrapy.Spider 类中默认为我们实现了一个 start_requests 方法,该方法就是一个遍历 start_urls 生成 Request 请求对象的生成器,生成的 Request 请求对象都会作为初始请求加入调度队列,由于 start_requests 方法并没有指定 callback 回调方法,因此初始 Request 请求对象执行后的 Response 响应对象就默认传递给 parse 方法的 response 参数。以下是 scrapy.Spider 类中 start_requests 方法的源码:
python
def start_requests(self):
if not self.start_urls and hasattr(self, "start_url"):
raise AttributeError(
"Crawling could not start: 'start_urls' not found "
"or empty (but found 'start_url' attribute instead, "
"did you miss an 's'?)"
)
for url in self.start_urls:
yield Request(url, dont_filter=True)这里我们在 parse 方法中例举一些 response 参数的属性:

如果想要自定义初始请求以及回调函数,我们就可以在 Spider 中重写 start_requests 方法。具体代码如下:

POST 请求
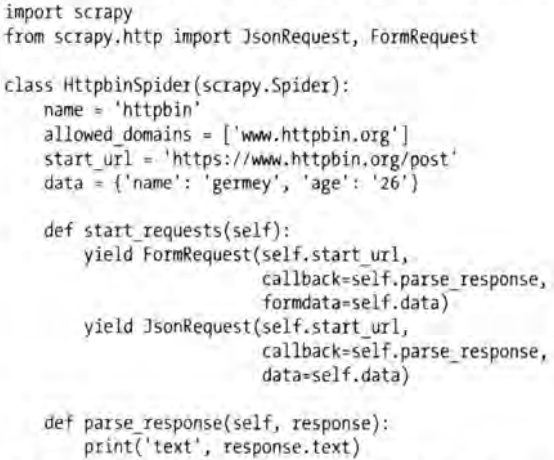
前面构造的 Request 请求对象默认发送的都是 GET 请求,当然我们也可以发起 POST 请求,常用如下两种方法:
- 通过
FormRequest设置formdata参数,发送Content-Type为application/x-www-form-urlencode的 POST 请求,实现发送 Form_data 表单数据。 - 通过
JsonRequest设置data参数,发送Content-Type为application/json的 POST 请求,实现发送 JSON 数据。
具体的代码实现如下:
这里要注意的是,使用 FormRequest 方法发起 POST 请求时,需要保证方法中传递的表单数据必须是 Unicode 编码、字符数据、字节对象三者之一,否则发起 POST 请求会错误提示:TypeError: to_bytes must receive a unicode, str or bytes object, got int。解决错误的方法也很简单,只需要把 int 类型转换为 str 类型就行了。
python
# 报错请求(formdata表单数据包含int类型)
yield FormRequest(url=self.url, formdata={"page": 1}, dont_filter=True)
# 正确请求(formdata表单数据全是str类型)
yield FormRequest(url=self.url, formdata={"page": str(1)}, dont_filter=True)另外,有的 Scrapy 版本中没有 scrapy.JsonRequest 类,可以使用普通的 scrapy.Request 对象来发送 JSON 请求。当你向服务器发送 JSON 请求时,通常需要设置请求头的 Content-Type 为 application/json,并将 JSON 数据作为请求体发送。以下是一个示例,演示如何在 Scrapy 中发送 JSON 请求:
python
import scrapy
import json
class MySpider(scrapy.Spider):
name = 'my_spider'
start_urls = ['http://example.com']
def parse(self, response):
# 定义要发送的JSON数据
json_data = {'key1': 'value1', 'key2': 'value2'}
# 将JSON数据转换为字符串
json_string = json.dumps(json_data)
# 设置请求头,指定Content-Type为application/json
headers = {'Content-Type': 'application/json'}
# 返回创建的JSON请求
yield scrapy.Request(
url='http://example.com/api/endpoint',
method='POST', # 使用POST请求,默认为GET请求
body=json_string,
headers=headers,
callback=self.parse_json_response
)
def parse_json_response(self, response):
# 处理服务器返回的JSON响应
json_response = json.loads(response.text)
self.log(json_response)提醒
上面介绍的 FormRequest 、 JsonRequest 都是 Request 类的子类,其参数和 Request 基本是一致的,利用这些参数,我们可以灵活地实现 Request 请求对象的构造。
Rsponse
Request 请求对象由 Downloader 下载器执行处理之后,得到的就是 Response 响应对象了,它代表了 HTTP 请求得到的响应结果。同样地我们可以梳理一下其可用的属性和方法:
url响应链接,如果链接存在跳转,那么响应链接不一定等同于请求链接。status响应状态码。headers响应头,字典格式。body字节(bytes)类型的响应体。request对应的 Requsts 请求对象。certificate是twisted.internet.ssl.Certificate类型的对象,通常代表一个 SSL 证书对象。ip_address是一个ipaddress.IPv4Address或ipaddress.Ipv6Address类型的对象,代表服务器的 IP 地址。urljoin处理 URL 方法,传入当前页面的相对 URL,返回当前页面的绝对 URL。follow/follow_all是一个根据 URL 来生成后续 Request 的方法,和直接构造 Request 不同的是,该方法接收的 URL 可以是相对URL。
另外,还有几个常用的子类,如 TextResponse、HtmlResponse,其中 HtmlResponse 又是 TextResponse 的子类。在回调方法中的 response 参数接收的 Response 响应对象,实质就是一个 HtmlResponse 对象。它还有几个常用的方法或属性:
text字符串类型的响应体。encoding响应编码,默认 UTF-8 。selector根据 Response 的内容构造而成的 Selector 对象。xpath调用 XPath 选择器提取内容,等同于调用selector的xpath方法。css调用 CSS 选择器提取内容,等同于调用selector的css方法。json方法将 JSON 格式的响应内容解析为 Python 对象(例如列表、字典等),等同于json.loads(response.text)效果。
内置 Selector
获取到响应内容之后就可以提取数据了,之前介绍了利用 XPath、CSS、以及正则表达式来提取网页数据的方法,确实非常方便。不过 Scrapy 也提供了自己的数据提取方法,即内置的 Selector,它支持 XPath 选择器、CSS 选择器以及正则表达式,功能全面,解析速度和准确度非常高。其实 Selector 并不一定非要在 Scrapy 中使用,它也是一个可以独立使用的模块。例如,针对一段 HTML 代码,我们可以用如下方式构建 Selector 对象来提取数据:这里直接把 Scrapy 中的 Selector 单独拿出来使用了,构建 Selector 对象的时候,传入 text 参数,然后就可以调用 XPath、CSS 等解析方法来提取数据了。
python
from scrapy import Selector
text = '<html><head><title>Hello world</title></head><body></body></html>'
selector = Selector(text=text)
title = selector.xpath('//title/text()').extract_firstr()
print(title) # 输出:Hello world在前面讲过,之前项目的爬虫文件中 parse(self, response) 方法里面的 response 参数就是 Response 响应对象。该对象的 selector 属性所返回的内容,就相当于上面例子中用 response 的 text 构造了一个 Selector 对象。通过这个 Selector 对象就可以调用 XPath、CSS 等解析方法来提取数据了。例如下面的例子:
python
def parse(self, response):
selector = response.selector
title = selector.xpath('//title/text()').extract_firstr()
print(title) # 输出:Hello worldScrapy 提供了一个两个快捷方法 response.xpath 和 response.css,二者的功能完全等同于 response.selector.xpath 和 response.selector.css。因此上面的例子可以写为:
python
def parse(self, response):
title = response.xpath('//title/text()').extract_firstr()
print(title) # 输出:Hello world同时这里也说明了,前面项目中爬虫文件提取数据的如下写法:
python
def parse(self, response):
# 这里用CSS选择器来提取内容
quotes = response.css('.quote')XPath 选择器
接下来演示的实例都将页面的源码作为分析目标,页面源码如下图:
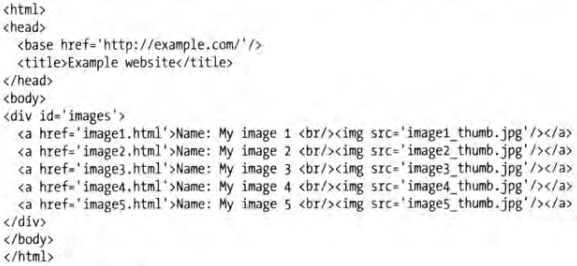
如果我们想提取网页中所有的 a 节点,代码如下:下面的所得到的是一个由 Selector 组成的 SelectorList 类型结果,我们可以像列表一样通过下标获取里面的单个 Selector。
python
response.xpath('//a')
如果我们想提取 a 节点元素,就可以利用 extract 方法,返回一个只包含 a 节点元素的列表。代码如下:
python
response.xpath('//a').extract()
我们还可以提取 a 节点中的文本和属性。代码如下:
python
response.xpath('//a/text()').extract()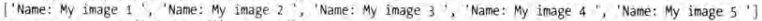
python
response.xpath('//a/@href').extract()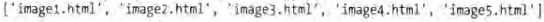
如果我们要同时提取 a 节点中的文本和属性,或者说有的 a 节点要么只有文本,要么只有属性,那我们就可以将两部分的 XPath 写在一起,中间用 | 进行连接。代码如下:
python
response.xpath('//a/text()|//a/@href').extract()很多时候我们想要的数据其实就是第一个元素内容,如果我们通过下标 0 来获取的话,会有产生风险。一旦 XPath 有问题,extract 方法返回的可能是一个空列表,这个时候使用下标就会导致越界错误。所以,我们可以使用 extract_first 方法来专门提取单个元素。代码如下:
python
# XPath正确(返回匹配符合要求的第一个值)
print(response.xpath('//a/text()').extract_first()) # 输出:Name: My image 1
# XPath错误(没有元素符合要求返回None)
print(response.xpath('//a[@href="123"]/text()').extract_first()) # 输出:None
# XPath默认值(没有元素符合要求返回默认值)
print(response.xpath('//a[@href="123"]/text()').extract_first('error')) # 输出:error另外,SelectorList 和 Selector 一样,都可以继续调用 XPath、CSS 等解析方法进一步提取数据。如果我们要提取网页中所有 a 节点内包含的 img 节点,代码如下:
python
response.xpath('//a').xpath('./img')
CSS 选择器
这里我们还是已这个源码为例,页面源码如下图:
这里以 CSS 为例,提取网页中所有的 a 节点,代码如下:
python
response.css('a')
同样调用 extract 方法就可以提取节点:
python
response.css('a').extract()
不管是 XPath 选择器,还是 CSS 选择器都可以嵌套使用,我们可以先用 XPath 选择器选中所有的所有 a 节点,再用 CSS 选择器选中 img 节点,然后用 XPath 选择器获取 src 属性。代码如下:
python
response.xpath('//a').css('img').xpath('@src').extract()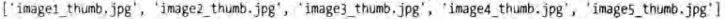
CSS 选择器可以使用 extract_first 方法提取列表的第一个元素,例如:
python
response.css('a[href="image1.html"] img').extract_first() # 输出:<img src="image1_thumb.jpg">获取节点的内部文本和属性时,和 Beautiful Soup 写法不同,具体如下:
python
response.css('a[href="image1.html"]::text').extract_first() # 输出:Name: My image 1
response.css('a[href="image1.html"] img::attr(src)').extract_first() # 输出:image1_thumb.jpg正则匹配
Selector 还支持正则匹配,在前面我们提取 a 节点中的文本和属性。代码如下:
python
response.xpath('//a/text()').extract()
现在我们想提取 a 节点中 Name: 后面的内容,就可以借助 re 方法,其中 (.*) 就是要匹配的内容,输出的结果就是正则表达式匹配的分组。代码如下:
python
response.xpath('//a/text()').re('Name:\s(.*)')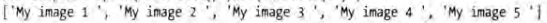
如果同时存在两个分组,就可以使用两个 (.*) 匹配内容。代码如下:
python
response.xpath('//a/text()').re('(.*?):\s(.*)')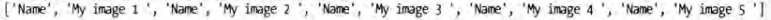
还有与类似 extract_first 方法的 re_first 方法可以选取列表的第一个元素。代码如下:
python
response.xpath('//a/text()').re_first('Name:\s(.*)') # 输出:Name
response.xpath('//a/text()').re_first('(.*?):\s(.*)') # 输出:My image 1提醒
Response 响应对象可以直接调用 re 和 re_first 方法,但通常在实际的爬虫开发中,更推荐使用选择器(XPath 或 CSS)进行数据提取,因为它们提供了更强大和灵活的功能,尤其在处理复杂的 HTML 结构时。
返回内容
限制内容
在前面的爬虫项目中,我们看到在 Spider 中可以返回 Item 数据,也可以返回 Resquest 请求对象。架构图也是如此:
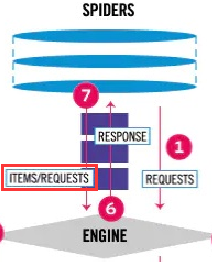
如果我们使用返回了一个包含 Item 数据的列表,就会出现下面的报错:这是因为框架对 Spider 的返回内容进行了硬性要求,只能返回 Item 数据、Resquest 请求、None 当中的一个。

yield 返回
另外,还可以看到 Spider 中不管是返回 Item 数据,还是返回 Resquest 请求都是用的 yield 返回,如果使用 return 返回,那么函数在返回一个 Item 数据或者一个 Resquest 后就结束掉了,有可能会导致数据漏抓。另外,使用 yield 也是为了支持异步和延迟处理的模型,以提高爬虫的效率。关于 Scrapy 中使用 yield 的一些要点:
支持异步处理: Scrapy 使用异步框架 Twisted,而
yield的使用使得可以在发起请求后不阻塞等待响应,而是在接收到响应时再继续处理。这样可以更充分地利用网络资源,提高爬虫的效率。支持延迟处理: 通过使用
yield,可以在处理过程中延迟生成 Item 数据或者发送新的请求。这对于需要根据当前页面内容动态生成请求或者进行某些处理后再生成 Item 数据非常有用。数据流控制:
yield提供了一种数据流控制的机制,可以将数据通过管道传递,从而实现数据的处理和存储。
注意
在任何情况下,都不要写阻塞的代码。例如:访问文件、数据库或者Web;产生新的进程并需要处理新进程的输出,如运行shell命令;执行系统层次操作的代码,如等待系统队列。
逻辑优化
转发响应
在写爬虫的时候,我们可能会遇到这样的情况,就是同一个响应对象需要经过不同的解析方法来提取内容,这种该怎么办呢?有人会说,请求两次,然后分别回调不同的解析方法,具体代码如下:
python
def parse(self, response):
url = 'https://www.baidu.com'
yield scrapy.Request(
url=url,
callback=self.parse_one
)
yield scrapy.Request(
url=url,
callback=self.parse_two
)
def parse_one(self, response):
"""解析逻辑代码一"""
def parse_two(self, response):
"""解析逻辑代码二"""可以看到同一个 URL 被请求了两次,这显然是不合理的。本着节约资源的精神,我们可以通过 yield from 关键词将 Response 响应对象复制并转发至其他的解析方法。具体代码如下:
python
def parse(self, response):
url = 'https://www.baidu.com'
yield scrapy.Request(
url=url,
callback=self.parse_one
)
def parse_one(self, response):
# 将Response响应对象复制并转发至parse_two方法
yield from self.parse_two(response)
# parse_one方法可以继续解析Response响应对象
"""解析逻辑代码一"""
def parse_two(self, response):
# response接收的就是parse_one方法转发的Response响应对象
"""解析逻辑代码二"""代码复用
使用 yield from 不仅可以转发 Response 响应对象给其他的解析方法,它还可以帮助我们实现代码复用。举个例子,在爬虫中有一些分支判断下存在相同的逻辑处理代码:
python
def parse(self, response):
if 'aaa' in response.text:
string = 'aaa' + '111'
result1 = '''处理逻辑'''
result2 = '''处理逻辑'''
yield result1 + result2 + string
elif 'bbb' in response.text:
string = 'bbb' + '222'
result1 = '''处理逻辑'''
result2 = '''处理逻辑'''
yield result1 + result2 + string
elif 'ccc' in response.text:
string = 'ccc' + '333'
result1 = '''处理逻辑'''
result2 = '''处理逻辑'''
yield result1 + result2 + string这时我们就可以将处理逻辑单独提取出来,形成一个新的处理逻辑方法,使用 yield 返回值,在调用该方法的时候使用 yield from 进行调用,在括号里面传递实参:
python
def logic(string):
result1 = '''处理逻辑'''
result2 = '''处理逻辑'''
yield result1 + result2 + string
def parse(self, response):
if 'aaa' in response.text:
string = 'aaa' + '111'
yield from self.logic(string)
elif 'bbb' in response.text:
string = 'bbb' + '222'
yield from self.logic(string)
elif 'ccc' in response.text:
string = 'ccc' + '333'
yield from self.logic(string)规则爬虫
前文我们了解了 Spider 的用法,在实现 Spider 的过程中,我们需要定义特定的方法完成一系列操作,比如生成 Response、解析 Response、生成 Item 等。由于整个过程是由代码实现的,所以逻辑控制比较灵活,但是可扩展性和可维护性相对比较差。如果我们现在要同一类的多个站点进行爬取,即使这些站点十分类似,但仍然需要为每个站点单独创建一个 Spider,然后在 Spider 中定义爬取列表页、详情页的逻辑。其实这些 Spider 的基本实现思路是差不多的,可能包含很多重复代码,因此可维护性就变得比较差。如果我们可以保留各个站点的 Spider 的公共部分,提取不同的部分进行单独配置(如将爬取规则、页面解析方式等抽离出来,做成一个配置文件),那么我们在新增一个爬虫的时候,就只需要实现这些网站的爬取规则和提取规则,而且还可以单独管理和维护这些规则。
CrawlSpider
在实现规则化爬虫之前,我们需要了解一下 CrawlSpider 用法。它是 Spider 类的子类,利用它我们可以方便地实现站点的规则化爬取。**在 CrawlSpider 里,我们可以指定特定的爬取规则来实现页面的解析和爬取逻辑,这些规则由个专门的数据结构 Rule 表示。Rule 里包含提取和跟进页面的配置,CrawlSpider 会根据 Rule 来确定当前页面中哪些链接需要继续爬取,哪些页面的爬取结果需要用哪个方法解析等。CrawlSpider 除了继承自 Spider 类的所有方法和属性,它还提供了一个非常重要的 rules 爬取规则属性,是包含一个或多个 Rule 对象的列表。每个 Rule 对爬取网站的规则都做了定义,CrawlSpider 会读取 rules 的每一个 Rule 并执行对应的爬取逻辑。**具体代码如下:
python
class scrapy.spiders.Rule(link_extractor=None, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None, errback=None)link_extractor一个 LinkExtractor 对象。通过它,Spider 可以知道从爬取的页面中提取哪些链接进行后续爬取,提取出的链接会自动生成 Request,这些提取逻辑依赖 LinkExtractor 对象里面定义的各种属性。callback回调方法。和之前定义 Request 的callback有相同的意义。每次从link_extractor中提取到链接时,该方法将会被调用。该回调方法接收response作为其第一个参数并返回一个包含 Item 或 Request 对象的列表。需要注意的是,避免使用parse方法作为回调方法,因为 Crawlspider 使用parse方法来实现其解析逻辑,如果parse方法被重写了,CrawlSpider 可能无法正常运行。cb_kwargs一个字典类型。使用它我们可以定义传递给回调方法的参数。follow一个布尔值,它指定根据该规则从response提取的链接是否需要跟进爬取。跟进的意思就是将提取到的链接进一步生成 Request 进行爬取;如果不跟进的话,一般可以定义回调方法解析内容,生成 Item。如果callback参数为None,follow值默认设置为True,否则默认为False。process_links可以是一个callable方法,也可以是一个字符串(需要和 CrawlSpider 里面定义的方法名保持一致)。它用来处理该 Rule 中的link_extractor提取到的链接,比如可以进行链接的过滤或对链接进行进一步修改。process_request可以是一个callable方法,也可以是一个字符串(需要和 CrawlSpider 里面定义的方法名保持一致)。根据该 Rule 提取到每个后续 Request 时,该方法都会被调用,该方法可以对 Request 进行进一步处理,必须返回 Request 对象或者None。Errback是 Scrapy 2.0 版本之后新增的参数,它也可以是一个callable方法,也可以是一个字符串(需要和 CrawlSpider 里面定义的方法名保持一致)。当该 Rule 提取出的 Request 在被处理的过程中发生错误时,该方法会被调用,该方法第一个参数接收一个 TwistedFailure 对象。