Scrapy框架【管道】
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
项目管道(Item Pipeline),当 Spider 解析完 Response 响应对象,将提取的数据放到一个类似字典结构的 Item 对象当中,返回给 Engine,然后 Engine 将其传递到 Item Pipeline 中,被定义的 Item Pipeline 组件依次调用,完成一连串的处理。

管道介绍
在 Scrapy 框架中,项目管道(Item Pipeline)起到的主要功能如下:
- 清洗 HTML 数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复内容。
- 将爬取结果存储到数据库。
使用说明
与中间件类似,Scrapy 也有内置的管道,所有的管道它们都可以在 Scrapy 的 pipeline 文件夹下看到,注意在默认配置文件 default_settings.py 中的 ITEM_PIPELINES_BASE 变量是空的,也就是说这些内置的管道都是关闭的。
与中间件一样,管道组件的整个配置也是一个字典格式,说明如下:
键名,由路径的和类名组成,和中间件一样。
键值,一个整形数字,代表了不同的
Item Pileline到Engine的距离,键值越小则越靠近Engine,当Spider生成 Item 返回给Engine,Engine再转发给Item Pileline处理时,肯定是距离Engine越近的Item Pileline,越先对 Item 进行处理。
重要方法
自定义一个 Item Pipeline 很简单,只需要在 pipelines.py 文件中定义一个类,并在类中实现如下一个核心方法:
process_item(item, spider)其中item即被处理的 Item 对象,spider即生成该 Item 的 Spider 对象。当 Item 从Engine过来后,被定义的Item Pipeline就会调用这个方法对Item进行处理,比如进行数据处理或者将数据写入数据库等操作。该方法必须返回 Item 类型的值或者抛出一个 DropItem 异常。- 返回 Item 对象,那么此 Item 会接着被低优先级的
Item Pipeline的process_item方法处理,直到所有的方法被调用完毕。 - 抛出 Dropltem 异常,此 Item 将会被丢弃,不再进行处理。
- 返回 Item 对象,那么此 Item 会接着被低优先级的
自定义管道
去重功能
假如 Item 中有一个 id 属性,且属性值是唯一的,但是我们的 Spider 返回的多个 Item 中包含有相同的 id 属性,这时就可以定义一个去重功能的 Item Pipeline,丢弃那些已经被处理过的 Item。在项目文件的 pipelines.py 文件,新建 DuplicatesPipeline 类,添加去重方法:
python
# 导入DropItem异常
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
# 这里定义一个空集合,因为集合能自动去重
self.ids_seen = set()
# 参数item:每次Spider生成的Item都会作为参数传递过来
# 参数spider:就是Spider实例
def process_item(self, item, spider):
# 判断Item的id是否再集合中
if item['id'] in self.ids_seen:
# 在集合中,抛出DropItem异常,丢弃当前Item
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item长度处理
在项目文件的 pipelines.py 文件,新建 Test1Pipeline 类,添加处理方法:
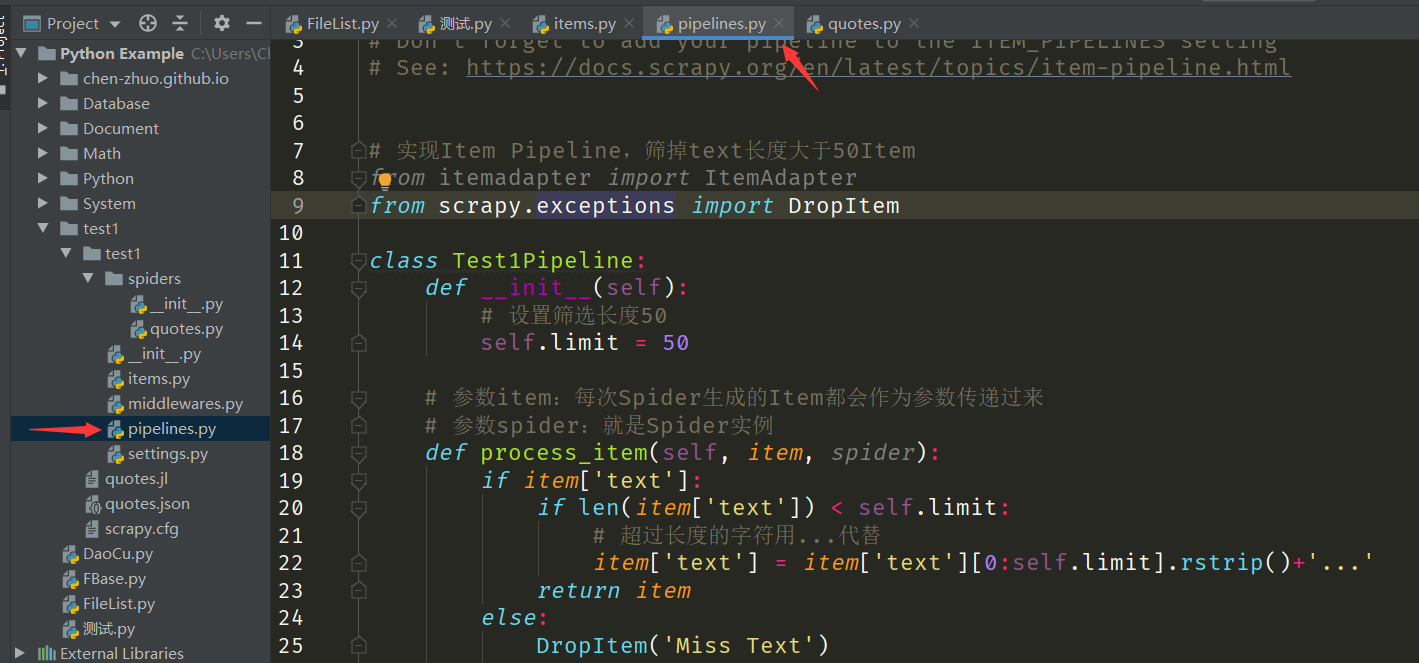
python
# 引入DropItem
from scrapy.exceptions import DropItem
class Test1Pipeline:
def __init__(self):
# 设置筛选长度50
self.limit = 50
# 参数item:每次Spider生成的Item都会作为参数传递过来
# 参数spider:就是Spider实例
def process_item(self, item, spider):
if item['text']:
if len(item['text']) < self.limit:
# 超过50长度的字符用...代替
item['text'] = item['text'][0:self.limit].rstrip()+'...'
return item
else:
DropItem('Miss Text')数据持久
**如果想将 Item 对象数据保存到数据库,也需要在 pipelines.py 文件里面定义 Item Pipeline 来实现。**首先,在 settings.py 文件中添加数据库的配置信息:
python
# 设置MySQL数据库
MYSQL_HOST = '127.0.0.1'
MYSQL_DATABASE = '...'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '...'
MYSQL_PORT = 3306
# 设置MongoDB数据库
MONGO_URI = '127.0.0.1'
MONGO_DB = '...'**接着,我们在 pipelines.py 文件定义两个 Item Pipeline,负责将 Item 处理后的数据保存到 MySQL 数据库、MongoDB 数据库中。**首先我们定义一个 MysqlPipeline 负责将数据保存到 MySQL 数据库:
python
# 导入pymysql
import pymysql
# 导入全局配置文件
import test1.settings
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
# 当Spider开启时,这个方法被调用,主要进行了一些初始化操作。
def open_spider(self, spider):
self.db = pymysql.connect(MYSQL_HOST, MYSQL_USER, MYSQL_PASSWORD, MYSQL_DATABASE, port=MYSQL_PORT, charset='utf8')
self.cursor = self.db.cursor()
# 最主要的process_item()方法则执行了数据插入操作,参数item就是Spider生成传递过来的Item数据,参数spider就是Spider实例。
def process_item(self, item, spider):
# 定义数据表名
teble = 'Test1Item'
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
# 返回item对象保证后面的管道能继续使用它
return item
# 当Spider关闭时,这个方法会被调用
def close_spider(self, spider):
# 提交所有的数据操作
self.db.commit()
# 关闭数据库连接
self.db.close()接着我们定义一个 MongoPipeline 负责将数据保存到 MongoDB 数据库,这里的大体结构和上面的 MysqlPipeline 差不多,但这我们使用 from_crawler 方法来获取全局配置信息:
python
# 导入pymongo
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
# @classmethod标识from_crawler是类方法,方法的参数是crawler,通过crawler我们能获取到全局配置文件settings.py中的所有配置信息
@classmethod
def from_crawler(cls, crawler):
# 拿到配置信息之后返回类对象即可
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
# 当Spider开启时,这个方法被调用,主要进行了一些初始化操作。
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
# 最主要的process_item()方法则执行了数据插入操作,参数item就是Spider生成传递过来的Item数据,参数spider就是Spider实例。
def process_item(self, item, spider):
# 定义数据表名
name = 'Test1Item'
self.db[name].insert(dict(item))
return item
# 当Spider关闭时,这个方法会被调用
def close_spider(self, spider):
# 关闭数据库连接
self.client.close()内置管道
Scrapy 内置了专门处理文件、图片下载的 Pipeline,其实下载文件和图片的原理与抓页面的原理一样,因此下载过程支持异步和多线程,十分高效。
核心方法
**和其他的 Item Pipeline 一样,使用 Scrapy 内置的 Images Pipeline 也需要重写里面的方法。**在 Images Pipeline 里面有如下三个方法:
get_media_requests(self, item, info)负责图片下载,第一个参数Item是爬取生成的 Item 对象,我们要下载的图片链接就在Item对象当中。所以我们要将 URL 逐个取出,构造 Request 发起下载请求。file_path(self, request, response=None, info=None)返回保存的文件名,第一个参数request就是当前下载对应的 Request 对象。必须返回文件的保存路径和文件名称以及文件后缀名。item_completed(self, results, item, info)单个 Item 完成下载时的处理方法。因为并不是每张图片都会下载成功,所以我们需要分析下载结果并剔除下载失败的图片。如果某张图片下载失败,那么我们就不需要将此 Item 保存到数据库。第一个参数results就是该 ltem 对应的下载结果,它是一个列表,列表的每个元素是一个元组,其中包含了下载成功或失败的信息。这里我们遍历下载结果,找出所有成功的下载列表,如果列表为空,那么该 Item 对应的图片下载失败,那么我们就随即抛出 Dropltem 异常,忽略该 ltem,否则返回该 Item,说明此 Item 有效。
警告
Image Pipeline 和其他 Item Pipeline 有一点不同的是,Item Pipeline 是接收、处理、保存数据,而 Image Pipeline 会返回请求,从 Image Pipeline 发送 Request 到 Engine,Engine 转发给 Scheduler,Scheduler 再给到 Engine,Engine 再转发 Downloader,Downloader 返回 Response 给 Engine,Engine 再给到 Image Pipeline,整个过程不再经过 Spider 组件。
图片下载
首先在 settings.py 文件中定义一个 IMAGES_STORE 变量保存存储文件的路径,如果不定义 IMAGES_STORE 变量,则无法保存图片变量:
python
IMAGES_STORE = './images'接下来,我们在项目中的 pipelines.py 文件自定义 ImagePipeline 类,继承内置的 ImagesPipeline 类,重写需要重新定义下载的部分逻辑方法。代码如下:
python
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
# 继承内置的ImagesPipeline
class ImagePipeline(ImagesPipeline):
def get_medis_requests(self, item, info):
# 返回Request构造的下载请求,指定meta信息,方便构造图片的存储路径,以便在下载完成时使用。
yield Request(item['url'], meta={
'movie': item['movie'],
'name': item['name']
})
# 返回保存的路径和文件名,在这里获取了上面的Request的meta信息,将里面的元素拼合为图片路径,这个路径在IMAGES_STORE路径下。
def file_path(self, request, response=None, info=None):
movie = request.meta['movie']
name = request.meta['name']
file_name = f'{movie}/{name}.jpg'
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item配置启用
**我们已经写好了五个自定义的 Item Pileline 之后,接下来就要在 settings.py 启用 Item Pileline,实现将数据保存到数据库的目的。**配置如下:
Python
# test1项目名称,pipelines文件名称,...Pipeline定义的Pipeline类,键值代表调用的优先级,数字越小距离Engine越近,Item Pileline就越先被调用。
ITEM_PIPELINES = {
# 启用自定义的去重处理管道
'test1.pipelines.DuplicatesPipeline': 290,
# 启用自定义的长度处理管道
'test1.pipelines.Test1Pipeline': 300,
# 启用自定义的图片下载管道
'test1.pipelines.ImagePipeline': 301,
# 启用自定义的存入MySQL管道
'test1.pipelines.MysqlPipeline': 400,
# 启用自定义的存入MONGO管道
'test1.pipelines.MongoPipeline': 500,
}[!ATTENTION]
这里要注意
Item Pileline的调用顺序,首先是对 Item 进行去重处理,然后再进行长度处理,再对 Item 做下载后的筛选,最后存入 MySQL、MongoDB 中,千万不要颠倒,先存入 MySQL、MongoDB 中,再对 Item 进行处理,再对 Item 做下载后的筛选,这样存入的数据相当于没有处理。