数据提取方法
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
网页结构
讲到网页数据提取,首先我们要了解网页结构。现在的网页基本是 HTML 静态网页,此类网页可以分为三大部分 —— HTML、CSS 和 JavaScript。如果把网页比作一个人,那么 HTML 相当于骨架(基础)、CSS 相当于皮肤(外观)、 JavaScript 相当于肌肉(动态),这三者结合起来才能形成个完整的网页。
HTML
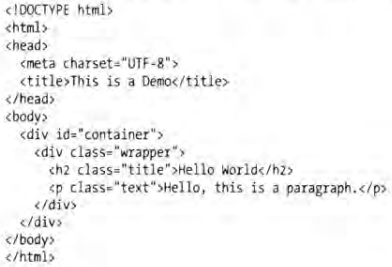
HTML(Hypertext Markup Language)是一种用来描述网页的超文本标记语言,它通过不同类型的节点来表示不同类型的元素,如用 img 节点表示图片、用 video 节点表示视频、用 p 节点表示文本段落,这些节点之间常由 div 节点嵌套组合形成布局,各种节点通过不同的排列和嵌套形成最终的网页框架。例举一个简单的HTML实例如下:html 节点内嵌套 head 节点和 body 节点,head 节点内定义网页的配置和引用,body 节点内定义网页的正文,这个实例便是一般网页的标准结构。
CSS
HTML 定义了网页的架构,但是只有 HML 的页面布局并不美观,为了让网页更好看一些,可以借助 CSS 来实现。CSS(Cascading Style Sheets),即层叠样式表。“层叠”是指当 HTML 中引用了多个样式文件,并且样式发生冲突时,浏览器能够按照层叠顺序处理这些样式。“样式”指的是网页中的文字大小、颜色、元素间距、排列等格式。CSS 是目前唯一的网页页面排版样式标准,有了它的帮助页面才会变得更为美观。例举一个简单的 CSS 实例如下:
- 大括号前面是一个 CSS 选择器,意思是首先选中
id为head_wrapper且class为s-ps-islite的节点,然后选中此节点内部的class为s-p-top的节点。 - 大括号的内部是一条条样式规则,
position指定了这个节点的布局方式为绝对布局,bottom指定节点的下边距为 40 像素,width指定了宽度为 100%,表示占满父节点,height则指定了节点的高度。

JavaScript
HTML 和 CSS 组合使用,提供给用户的只是一种静态信息,缺乏交互性。为了让网页具有交互性,可以借助 JavaScript 来实现。JavaScript 简称 JS,是一种脚本语言。我们在网页里还可能会看到一些交互和动画效果,如下载进度条、提示框、轮播图等,这通常就是 JavaScript 的功劳。JavaScript 的出现使得用户与信息之间不只是一种浏览与显示的关系,还实现了一种实时、动态,交互的页面功能。例举一个引入 JS 文件的实例:在网页中,JavaScript 通常是单独的后缀为 .js 的文件形式,通过 HTML 中的 script 节点引入的。
提取方案
了解完了网页的组成,现在来讲讲数据的提取。因为网页中的内容并不都是我们所需要的,例如网页中的 HTML 节点源代码、广告内容等,这时候就需要利用一些库,从网页中提取出我们需要的内容。在网页组成中,只有 HTML 能通过节点将里面的数据展示在最终的网页上,因此爬虫所爬取的网页内容,更多的是网页中的 HTML 部分,最后以字符串的形式将网页的 HTML 结果返回回来。
正则提取
首先,网页内容的数据类型是字符串,我们很容易就能想到使用 re 正则库来提取网页中的内容,这样做确实可以的,但是不建议,因为存在以下几个问题:
- 其一,正则每次匹配对应的字符串时,都是从头开始匹配,如果网页整体比较大时,而且我们需要提取的字段数量比较多,每个字段都去从头匹配的话,是比较耗费算力的,效率是比较低下的。
- 其二,正则写错了可能会导致匹配失败,甚至程序错误,如果正则的匹配范围过大,还会造成程序运行卡顿。
- 其三,正则的匹配过程当中,有可能会将 HTML 标签匹配进去,最后提取数据时,还需要加一道去除 HTML 标签过程,显得费时繁琐。
节点提取
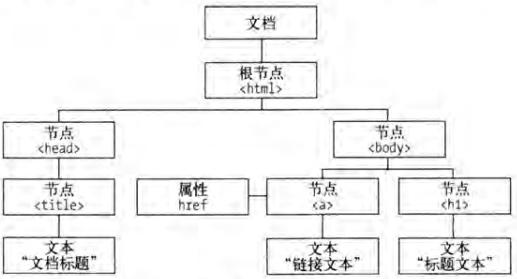
对于网页内容的提取,其实有更好方案。上面讲过,网页的 HTML 部分是由一个个不同属性、不同的功能的节点所组成,这些节点定义的节点相互嵌套和组合形成了不同的层次关系构成了一个 HTML 节点树,也叫 HTML DOM 树。
建议
DOM 是 W3C(万维网联盟)的标准,英文全称是 Document Object Model,即文档对象模型。它定义了访问 HTML 和 XML 文档的标准。
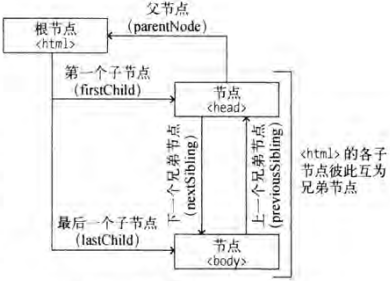
节点树中的所有节点均可被修改、创建或删除。节点树中的节点彼此拥有层级关系。我们常用父(parent)、子(child)和兄弟(sibling)等术语描述这些关系。父节点拥有子节点,同级的子节点被称为兄弟节点。在节点树中,顶端节点称为根(root)。除了根节点之外,每个节点都有父节点,同时可拥有任意数量的子节点或兄弟节点。
在 Python 中,如何提取网页中的节点呢?主要是以下三步:
- 首先,我们会使用到”解析库“,将网页内容解析为适合选择器选择定位的样式。
- 接着,使用“选择器”,根据节点的id、class或其他属性,去定位一个或多个符合匹配规则的节点。
- 最后,使用提取”方法“,当节点提取出来后,我们还需要使用相应的方法将需要的内容(属性、文本等)提取出来。
lmxl+XPath
lmxl 解析库+XPath 选择器:节点自动补全,解析速度快,表达式易写易定位。另外提供了 100 多个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,选择功能十分强大。
lmxl解析库
lxml 是 Python 的一个支持 HTML 和 XML 解析的第三方库,支持 XPath 解析方式,而且解析效率非常高。
pip install lxml安装完成后,我们来简单使用一下:
python
# 导入lxml库中的etree模块
from lxml import etree
# 网页代码
html_text ='<li class="1"><a class="" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" target="_blank" rel="">面对常见皮肤问题,黄金万能膏让你高枕无忧</a></li>' \
'<li class="2"><a class="" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" target="_blank" rel="">功能强大全自动晴雨伞,反向收伞干净不湿车</a>'
# 解析网页代码
res = etree.HTML(html_text)
print(f'直接输出:{res}')
print(f'字符输出:{etree.tostring(res)}')
'''
直接输出:<Element html at 0x13e22fbe888>
注释:这里输出了一个Element对象。
字符输出:b'<html><body><li class=""><a class="" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" target="_blank" rel="">面对常见皮肤问题,黄金万能膏让你高枕无忧</a></li><li class=""><a class="" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" target="_blank" rel="">功能强大全自动晴雨伞,反向收伞干净不湿车</a></li></body></html>'
注释:以bytes类型输出,自动补全了上面内容尾部缺失的</li>,还自动添加了<html><body>节点,修正了文本。
'''提醒
如果需要解析 .html 文件中的 HTML 文本的话,可以使用 etree.parse('./文件.html', etree.HTMLParser()) 方法进行解析。
XPath定位采集
XPath 全称是 XML Path Language,即 XML 路径语言,它是一门查找信息的语言,它最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索。当 lxml 完成对对网页的解析后,接下来用 XPath 选择器来定位我们需要的节点,常用的定位规则有 7 种:
| 表达式 | 描述 |
|---|---|
nodename | 选取此节点的所有子节点 |
/ | 从当前节点选取直接子节点 |
// | 从当前节点选取子孙节点 |
. | 选取当前节点 |
.. | 选取当前节点的父节点 |
@ | 选取属性 |
* | 所有节点 |
python
# 选取所有节点元素
print(res.xpath('//*'))
# 获取全部的li节点
print(res.xpath('//li'))
# 获取全部的li节点中的第一个li节点(序号以1开头,而非0)
print(res.xpath('//li[1]'))
# 获取全部的li节点中的前两个li节点
print(res.xpath('//li[position()<3]'))
# 获取全部的li节点中的倒数第一个li节点
print(res.xpath('//li[last()]'))
# 获取全部的li节点中的倒数第二个li节点
print(res.xpath('//li[last()-1]'))
# 获取全部的class属性为1的li节点
print(res.xpath('//li[@class="1"]'))
# 获取全部的class属性不等于"1"的li节点
print(res.xpath('//li[@class!="1"]'))
# 获取全部的li节点所有直接a子节点
print(res.xpath('//li/a'))
# 获取全部的li节点所有直接a子节点的href属性
print(res.xpath('//li/a/@href'))
# 获取全部的li节点所有直接a子节点的文本内容
print(res.xpath('//li/a/text()'))
# 获取全部的li节点所有直接a子节点的父节点(上一级节点),即li节点
print(res.xpath('//li/a/..'))
# 获取全部的li节点所有直接a子节点的父节点的class属性
print(res.xpath('//li/a/../@class'))
# 获取全部的li节点所有的没有class属性直接a子节点
print(res.xpath('//li/a[not(@class)]'))
# 获取全部的li节点中所有直接a子节点中文本内容包含"皮肤问题"的a子节点
print(res.xpath('//li/a[contains(text(), "皮肤问题")]'))
# 获取全部的class属性包含"1"或者class属性等于"2"的li节点
print(res.xpath('//li[contains(@class, "1") or @class="2"]'))
# 获取全部的class属性等于""并且rel属性等于""的a节点
print(res.xpath('//a[@class="" and @rel=""]'))
# 获取第一个a节点的全部祖先节点
print(res.xpath('//a[1]/ancestor::*'))
# 获取第一个a节点的body祖先节点
print(res.xpath('//a[1]/ancestor::body'))
# 获取第一个li节点后续所有的同级节点
print(res.xpath('//li[1]/following-sibling::*'))
# 获取第一个li节点后续同级的第一个li节点
print(res.xpath('//li[1]/following-sibling::li[1]'))
'''
输出:[<Element html at 0x24e3d073e08>, <Element body at 0x24e3d1bcc88>, <Element li at 0x24e3d1bcd08>, <Element a at 0x24e3d1bcd48>, <Element li at 0x24e3d1bcd88>, <Element a at 0x24e3d1bcfc8>]
注释:返回形式是一个列表,每个元素是一个Element类型,中间显示了节点的名称,这里两个li节点、两个a节点、一个html节点和body节点,最后的html节点和body节点是在解析的时候补全的。
输出:[<Element li at 0x18df104adc8>, <Element li at 0x18df104aec8>]
注释:返回了全部的li节点。
输出:[<Element li at 0x18df104adc8>]
注释:返回了第一个li节点。
输出:[<Element li at 0x18df104adc8>, <Element li at 0x18df104aec8>]
注释:返回了全部的li节点中的前两个li节点。
输出:[<Element li at 0x18df104aec8>]
注释:返回了全部的li节点中的倒数第一个li节点。
输出:[<Element li at 0x18df104adc8>]
注释:返回了全部的li节点中的倒数第二个li节点。
输出:[<Element li at 0x18df104adc8>]
注释:返回了class属性为1的li节点。
输出:[<Element li at 0x18df104aec8>]
注释:返回了class属性不为1的li节点。
输出:[<Element a at 0x24e3d1bcc88>, <Element a at 0x24e3d1bcd08>]
注释:返回了全部的li节点所有直接a子节点。
输出:['https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1','https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1']
注释:返回了全部的li节点所有直接a子节点的href属性。
输出:['面对常见皮肤问题,黄金万能膏让你高枕无忧', '功能强大全自动晴雨伞,反向收伞干净不湿车']
注释:返回了全部的li节点所有直接a子节点的文本内容。
输出:[<Element a at 0x24e3d1bcc88>, <Element a at 0x24e3d1bcd08>]
注释:返回了全部的li节点所有直接a子节点的父节点(上一级节点),即li节点。
输出:['1', '2']
注释:返回了全部的li节点所有直接a子节点的父节点的class属性。
输出:[]
注释:返回了全部的li节点所有的没有class属性直接a子节点。
输出:[<Element a at 0x24e3d1bcc88>]
注释:返回了全部的li节点中所有文本内容包含"皮肤问题"的直接a子节点。
输出:[<Element li at 0x18df104adc8>, <Element li at 0x18df104aec8>]
注释:返回了全部的class属性包含"1"或者class属性等于"2"的li节点。
输出:[<Element a at 0x24e3d1bcc88>, <Element a at 0x24e3d1bcd08>]
注释:返回了全部的class属性等于""和rel属性等于""的a节点。
输出:[<Element html at 0x24e3d073e08>, <Element body at 0x24e3d1bcc88>, <Element li at 0x24e3d1bcd08>]
注释:返回了第一个a节点的全部祖先节点。
输出:[<Element body at 0x24e3d1bcc88>]
注释:返回了第一个a节点的body祖先节点。
输出:[<Element li at 0x18df104aec8>]
注释:返回了第一个li节点后续所有的同级节点。
输出:[<Element li at 0x18df104aec8>]
注释:返回了第一个li节点后续同级的第一个li节点。
'''建议
一个节点的 class 属性可以包含多个类名,它们之间用空格隔开,例如 <li class="li li-first"> 中的 li 节点的 class 属性就有 li 和 li-first 两个类名。
警告
例子中使用 //li/a/text() 提取文本,意思是先选取 li 节点,再选取其直接 a 子节点,最后提取文本。如果写为 //li/text() 格式,就是选中 li 节点,再提取文本,会发现 a 子节点内部文本是提取不到的,因为这里提取的是 li 节点和 a 子节点之间的文本内容。如果我们需要提取 li 节点以及下面的所有节点所包含的全部文本内容,可以写为 //li//text() 格式。
重要
在提取目标节点的过程中,一般优先定位有 id 属性的目标节点、父节点或祖先节点,因为在 HTML 网页中 id 的属性值基本是唯一,这样我们就可以用最短的 XPath 路径快速定位到目标节点。
if '»' in response.text:
href = response.xpath('//a[contains(text(), "»")]/@href').extract_first()<div class="item">
<div class="label">
<i class="iconfont icon-lianxiren"></i>联系地址
</div>
<div class="info">
山东省梁山县拳铺镇工业园区
</div>
</div>
使用response.xpath('//div[@class="label" and contains(text(), "联系地址")]')提取为空
使用response.xpath('//div[normalize-space(text()[2])="联系地址"]').extract_first('').strip()能提取
使用response.xpath('//div[.//text()[contains(., "联系地址")] and @class="label"]').extract_first('').strip()能提取
浏览器XPath
Chrome 浏览器是支持拷贝 XPath 定位的,有两种定位模式:
Copy XPath通过一些 HTML 节点属性来快速定位到元素的 XPath 精简路径。Copy full XPath从 HTML 第一个节点一层一层定位到元素的 XPath 完整路径。
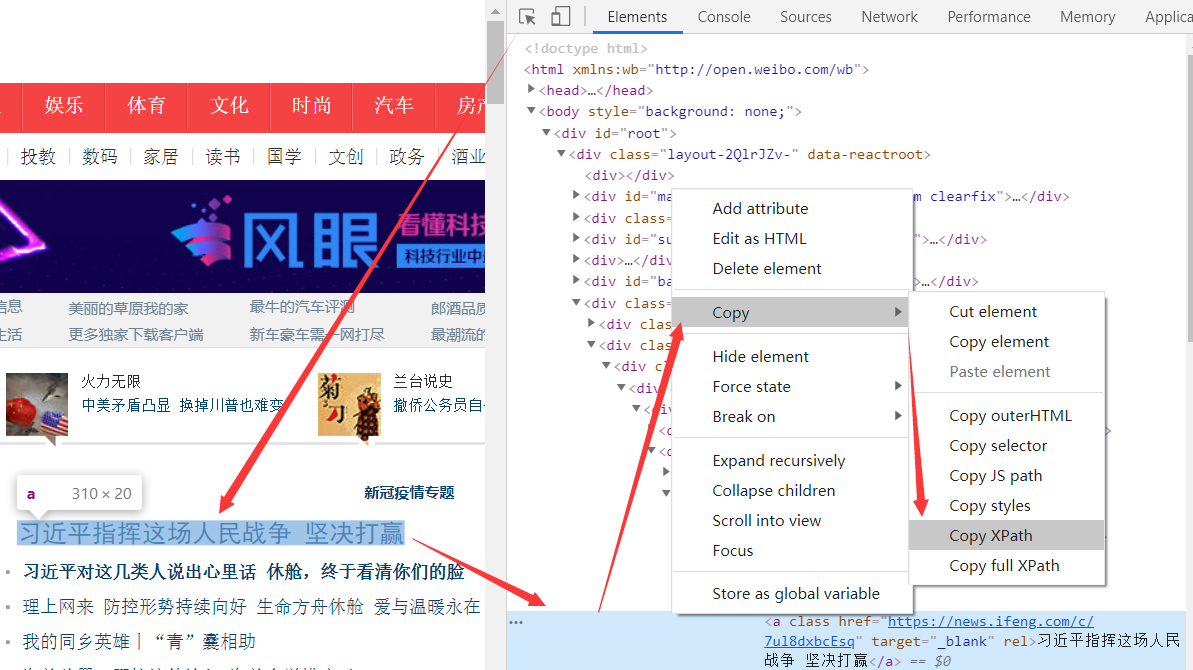
警告
从浏览器里面拷贝出来的XPath通常会很长,不建议使用。
BeautifulSoup+CSS
2004 年 Beautiful Soup 发布,Beautiful Soup 常用于解析 HTML 和 XML 文档,并提供了一种方便的方式来查找和修改其中的数据,极大地简化了网页抓取和数据解析的任务。

BeautifulSoup(亮汤),
BeautifulSoup 解析库 + CSS 选择器:节点自动补全,输入文档自动转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码,可自由选择多种解析器和多种选择器。
BeautifulSoup解析库
BeautifulSoup 是 Python 的一个 HTML 或 XML 的解析库,其解析器是依赖于 lxml 库的,所以在此之前请确保已经成功安装好了 lxml 库。
pip install beautifulsoup4Beautiful Soup 支持多种解析器:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python 标准库 | BeautifulSoup(HTML,”html. parser ") | Python 的内置标准库、执行速度适中、文档容错能力强 | 容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(HTML,”lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(HTML,“xml") | 速度快、唯一支持 XML 解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(HTML,”html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成 HTML5 格式的文档 | 速度慢、不依赖外部扩展 |
通过对比可以看出, lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强,所以推荐使用它。
python
# 注意:这里是从bs4中导入BeautifulSoup
from bs4 import BeautifulSoup
def example():
# 网页代码
html_text = '<li class="1"><a class="" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" target="_blank" rel="">面对常见皮肤问题,黄金万能膏让你高枕无忧</a></li>' \
'<li class="2"><a class="" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" target="_blank" rel="">功能强大全自动晴雨伞,反向收伞干净不湿车</a>'
# 使用lxml解析器
soup = BeautifulSoup(html_text,'lxml')
print(soup)
if __name__ == '__main__':
example()
'''
# 解释:同样这里也和上面一样,自动补全了</li>节点,还添加了<html>和<body>节点
<html><body><li class="1"><a class="" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" rel="" target="_blank">面对常见皮肤问题,黄金万能膏让你高枕无忧</a></li><li class="2"><a class="" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" rel="" target="_blank">功能强大全自动晴雨伞,反向收伞干净不湿车</a></li></body></html>
'''CSS定位采集
BeautifulSoup 支持也多种选择器,节点选择器、CSS 选择器,这里重点讲述CSS 选择器。
| 表达式 | 描述 |
|---|---|
.prettify() | 网页缩进格式化输出 |
.contents | 获取节点下面所有子节点 |
.descendants | 获取节点下面所有子孙节点 |
.parent | 获取节点的父节点 |
.parents | 获取所有祖先节点 |
.next_sibling | 同级下⼀节点 |
.previous_sibling | 同级上⼀节点 |
.next_siblings | 同级所有后面节点 |
.previous_siblings | 同级所有前面节点 |
ul li | 选择ul节点下面的所有li节点 |
.panel | 选择所有class属性为panel的节点 |
#list-1 | 选择所有id属性为list-1的节点 |
ul['id'] | 获取ul节点的id属性 |
li.string | 获取li节点的文本内容 |
使用 CSS 选择器时,只需要调用 select() 方法,传入相应的 CSS 选择器即可:
python
# 注意:这里是从bs4中导入BeautifulSoup
from bs4 import BeautifulSoup
# HTML文档
html_text = '<li class="a1"><a class="b2" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" target="_blank" rel="">面对常见皮肤问题,黄金万能膏让你高枕无忧</a></li>' \
'<li class="c3"><a class="d4" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" target="_blank" rel="">功能强大全自动晴雨伞,反向收伞干净不湿车</a>'
# 使用lxml解析器
soup = BeautifulSoup(html_text,'lxml')
# 输出li节点下的所有a节点
print(soup.select('li a'))
# 输出class属性为a1的li节点
print(soup.select('li.a1'))
# 输出li节点的所有下级节点中class属性为d4的节点
print(soup.select('li .d4'))
# 遍历li节点列表
for li in soup.select('li'):
# 输出li节点的class属性值
print(li['class'])
'''
输出:[<a class="b" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" rel="" target="_blank">面对常见皮肤问题,黄金万能膏让你高枕无忧</a>, <a class="d" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" rel="" target="_blank">功能强大全自动晴雨伞,反向收伞干净不湿车</a>]
注释:li节点下的所有a节点
输出:[<li class="a1"><a class="b2" href="https://health.ifeng.com/c/7ukXdtax7s8#_wth_sc1" rel="" target="_blank">面对常见皮肤问题,黄金万能膏让你高枕无忧</a></li>]
注释:输出class属性为a1的li节点
输出:[<a class="d4" href="https://health.ifeng.com/c/7ukXlZPltHE#_wth_sc1" rel="" target="_blank">功能强大全自动晴雨伞,反向收伞干净不湿车</a>]
注释:li节点的所有下级节点中class属性为d4的节点
输出:['a1'] ['c3']
注释:输出li节点的class属性值
'''浏览器selector
和 XPath 一样,浏览器也支持 CSS 选择器表达式:
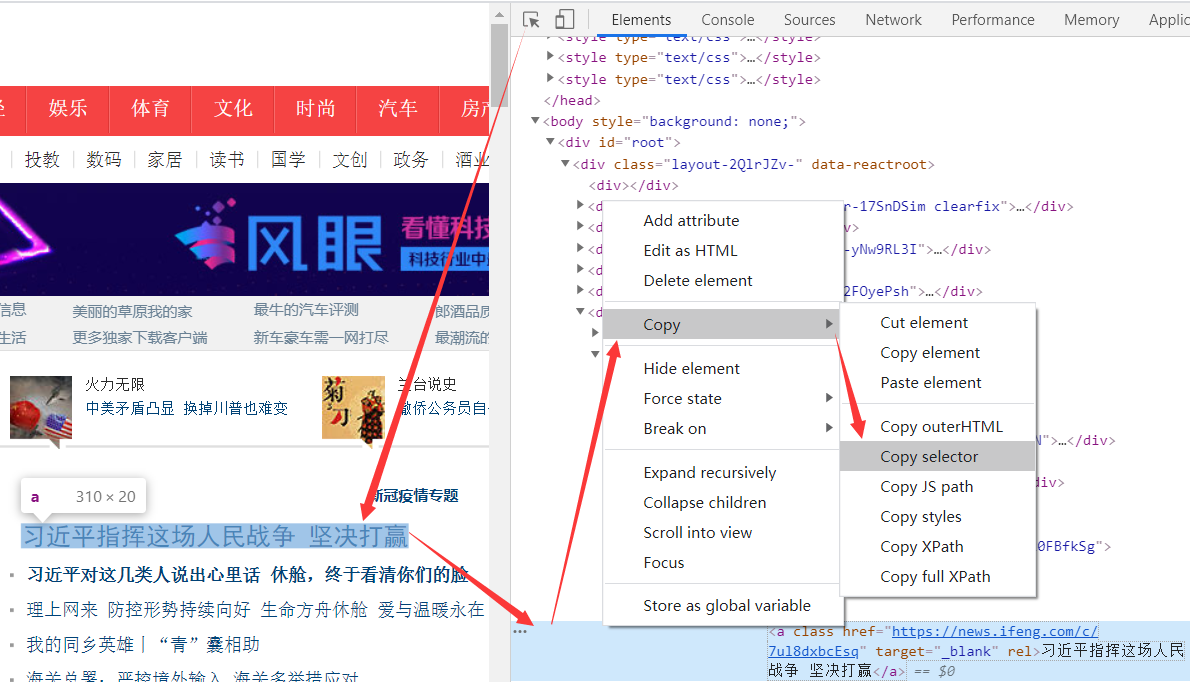
警告
从浏览器里面拷贝出来的CSS通常会很长,不建议使用。