Scrapy框架【分布式】
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
一个爬虫运行在一个主机上,就算效率再怎么高,面对需要采集量巨大的任务时,仍然会显得力不从心。假如,我们将爬虫分布到多台主机上,再共享一个消息队列,那么采集效率就会翻倍,这就是“分布式爬虫”。
分布式原理
在 Scrapy 单机爬虫中,有一个本地爬取队列 Queue,这个队列是利用 deque 模块实现的。新生成的 Request 就会被放到队列里,随后被调度器 Scheduler 调度,交给 Downloader 执行爬取。

如果有三个 Scheduler 同时从队列里面取 Request,且每个 Scheduler 都有其对应的 Downloader,那么在带宽足够、正常爬取且不考虑队列存取压力的情况下,爬取效率会翻三倍。这样,虽然每台主机还是有各自的 Scheduler 和 Downloader 来分别完成调度和下载功能,但不用再各自维护本地爬取队列 Queue,而是共享一个爬取队列 Queue,也就是所谓的共享爬取队列。同时也保证了 Scheduler 从队列里调度某个 Request 后,其他 Scheduler 不会重复调度此 Request,就可以做到多个 Scheduler 同步爬取,这就是分布式爬虫的基本雏形。
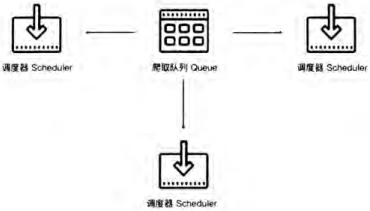
共享队列
**单机爬虫和分布式爬虫和最大的区别就是,单机爬虫是独立的本地任务队列,分布式爬虫是共享的网络任务队列。**那么我们如何搭建一个共享的网络任务队列呢?**首先我们知道,计算机执行程序会在内存中会生成一个该程序的进程,也就是说执行爬虫程序在内存中会生成一个该爬虫的进程,如果多台主机上同时运行爬虫任务,那么就会在多个不同主机上的生成不同的爬虫进程,要让这些进程毫无关联的进程进行通信最重要的前提是指定同一个外部服务。这个服务可以是消息队列框架,也可以是数据库,这里我们就使用我们最熟悉的数据库来提供网络任务队列的服务。**接下来我们就要考虑性能问题,什么数据库存取效率高?爬取队列怎样维护比较好呢?于是我们自然能想到基于内存存储的 Redis,而且 Redis 支持多种数据结构,例如列表(List)、集合(Set)、有序集合(Sorted Set)等,存取的操作也非常简单,所以在这里我们采用 Redis 来维护爬取队列。
- 使用列表,列表数据结构有
lpush、lpop、push、rpop方法,我们可以用它实现一个先进先出式的爬取队列,也可以实现一个先进后出的栈式爬取队列。 - 使用集合,集合的元素是无序且不重复的,这样我们可以非常方便地实现一个随机排序的不重复的爬取队列。
- 有序集合带有分数表示,而 Scrapy 的 Request 有优先级的控制,所以用有序集合我们可以实现一个带优先级调度的队列。
任务去重
**前面我们构造 Request 请求对象的时候,介绍了构造该对象其中一个 dont_filter 过滤器参数,这个参数默认值是 False,也就是说默认是开启任务去重。**那么该对象的去重逻辑是怎么样的呢?我们知道每个 Request 请求对象使用的 Method、URL、Body、Headers 这几部分内容都不尽相同,因此我们首先是要计算出每个 Request 这几部分内容整个的指纹,这几部分内容只要有一点不同,计算得到的指纹就会不一样。这样每个 Request 都有独有的指纹,指纹就是一个字符串,判定字符串是否重复比判定 Request 对象是否重复容易得多,所以指纹可以作为判定 Request 是否重复的依据。
任务指纹
在下面 Scrapy 源代码中:request_fingerprint 就是计算 Request 指纹的方法,其方法内部使用的是 hashlib 的 sha1 方法。计算的字段包括 Request 的 Method、URL、Body、Headers 这几部分内容,计算得到的字符串结果就是”指纹“。
python
import hashlib
def request_fingerprint(request, include_headers=None):
if include_headers:
headers = tuple(to_bytes(h.lower()) for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]警告
如果在框架中我们实现了随机 User-Agent 池,那么源码就不能将请求头作为计算指纹的一部分。因此 Request 就只有 Method、URL、Body 这三部分被纳入指纹计算,但爬虫主要使用 GET、POST 这两种类型的请求,也就是说对于 GET 请求,只会根据 URL 请求链接来判定请求指纹是否相同,对于 POST 请求,则会根据 URL 请求链接、Body 请求体来判定请求指纹是否相同。
集合去重
现在 Scrapy 计算出了 Request 指纹,接下来如何判定指纹重复呢?在下面 Scrapy 源代码中:在去重类 RFPDupeFilter 中初始化了一个 fingerprints 对象属性为 set() 空集合,这个集合就是用来保存 Request 指纹的。在下面还有一个 request_seen 方法,该方法中调用了 request_fingerprint 方法也就是上面计算 Request 指纹的代码 ,接着判断指纹是否存在于 fingerprints 集合当中,集合的元素都是不重复的,如果指纹存在,就返回 True,说明该 Request 是重复的,否则就将这个指纹加入集合。如果下次还有相同的 Request 传递过来,指纹也是相同的,指纹就已经存在于集合中了,那么 Request 对象就会直接判定为重复,并且如果你开启了 Debug 日志,还会在日志中输出 Filtered duplicate request: ... 这样一条日志,表示 Request 对象重复。这样,去重的目的就实现了。
python
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path: Optional[str] = None, debug: bool = False) -> None:
self.file = None
self.fingerprints: Set[str] = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls: Type[RFPDupeFilterTV], settings: BaseSettings) -> RFPDupeFilterTV:
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request: Request) -> bool:
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + '\n')
return False
def request_fingerprint(self, request: Request) -> str:
return request_fingerprint(request)
def close(self, reason: str) -> None:
if self.file:
self.file.close()
def log(self, request: Request, spider: Spider) -> None:
if self.debug:
msg = "Filtered duplicate request: %(request)s (referer: %(referer)s)"
args = {'request': request, 'referer': referer_str(request)}
self.logger.debug(msg, args, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request: %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
spider.crawler.stats.inc_value('dupefilter/filtered', spider=spider)建议
总结来说,Scrapy 的自动去重功能,使用了 Python 中的集合,这个集合记录了 Scrapy 中每个 Request 的指纹。整个去重过程就是,利用集合元素的不重复特性来实现 Request 的去重。
共享指纹
对于分布式爬虫来说,我们肯定不能再让每个爬虫各自的集合来去重了。因为这样还是每个主机单独维护自己的集合,如果多台主机生成了相同的 Request 还是无法去重。因此要实现多台主机的去重,这个指纹集合也是需要共享的。Redis 正好有集合数据结构,我们可以利用 Redis 的集合作为指纹集合,这样指纹集合也可以利用 Redis 进行共享的。每台主机新生成 Request 后,把该 Request 的指纹与 Redis 的指纹集合比对,如果指纹已经存在,说明该 Request 是重复的,否则将 Request 的指纹加入这个集合。这样,我们就实现了分布式 Request 去重。
防止中断
**在 Scapy 中,爬虫运行时的 Request 队列是放在内存中的。当爬虫运行中断后,这个队列的空间就被释放,此队列就销毁了。所以一旦爬虫运行中断,爬虫再次运行就相当于全新的爬取过程。想要做到中断后继续爬取,我们可以将队列中的 Request保存起来,下次爬取直接读取保存数据即可获取上次爬取的队列。**在 Scrapy 中指定一个爬取队列的存储路径即可,这个路径使用 JOB_DIR 变量来标识,可以用如下命令来实现:它实际是把爬取队列保存到本地,第二次爬取直接读取并恢复队列。
scrapy crawl spider -s JOBDIR=crawls/spider那么在分布式架构中,我们还用担心这个问题吗?不需要。因为爬取队列本身就是用数据库保存的,如果爬虫中断了,数据库中的 Request 依然存在,下次启动就会接着上次中断的地方继续爬取所以,当 Redis 的队列为空时,爬虫会重新爬取;当 Redis 的队列不为空时,爬虫便会接着上次中断之处继续爬取。
Scrapy-Redis
经过上面的分布式原理的学习,我们接下来就需要在程序中实现这个架构了。**首先实现一个共享的爬取队列,还要实现去重的功能。另外,重写一个 Scheduer 的实现,使之可以从共享的爬取队列中存取 Request。幸运的是,已经有人实现了这些逻辑和架构,并发布成叫 Scrapy-Redis 的 Python 包。**接下来,我们看一下 Scrapy-Redis 的源码实现,以及它的详细工作原理。执行下面的额命令安装 Scrapy-Redis 库:
pip install scrapy-redis爬取队列
从爬取队列入手,源码文件为 queue. py,它有三个队列的实现,首先它实现了一个 Base 类,提供一些基本方法和属性,代码如下所示:首先看一下 _encode_request 和 _decode_request 方法,这两个方法分别是序列化和反序列化的操作,因为数据库无法直接存储 Request 对象,所以需要将 Request 序列化转成字符串再存储,而这个过程利用 pickle 库来实现。一般在调用 push 方法将 Request 存入数据库时,会调用 _encode_request 方法进行序列化,在调用 pop 取出 Request 的时候,会调用 _decode_request 进行反序列化。另外,在这个类中 _len_、push 和 pop 方法都是未实现的,会直接抛出 Notimplementederror,因此这个类是不能直接被使用的,必须实现一个子类来重写这三个方法,而不同的子类就会有不同的实现,也就有着不同的功能。
python
class Base(object):
"""Per-spider base queue class"""
def __init__(self, server, spider, key, serializer=None):
if serializer is None:
serializer = picklecompat
if not hasattr(serializer, 'loads'):
raise TypeError(f"serializer does not implement 'loads' function: {serializer}")
if not hasattr(serializer, 'dumps'):
raise TypeError(f"serializer does not implement 'dumps' function: {serializer}")
self.server = server
self.spider = spider
self.key = key % {'spider': spider.name}
self.serializer = serializer
def _encode_request(self, request):
"""Encode a request object"""
try:
obj = request.to_dict(spider=self.spider)
except AttributeError:
obj = request_to_dict(request, self.spider)
return self.serializer.dumps(obj)
def _decode_request(self, encoded_request):
"""Decode an request previously encoded"""
obj = self.serializer.loads(encoded_request)
return request_from_dict(obj, spider=self.spider)
def __len__(self):
"""Return the length of the queue"""
raise NotImplementedError
def push(self, request):
"""Push a request"""
raise NotImplementedError
def pop(self, timeout=0):
"""Pop a request"""
raise NotImplementedError
def clear(self):
"""Clear queue/stack"""
self.server.delete(self.key)**接下来就需要定义一些子类来继承 Base 类,并重写这几个方法,刚好在 queue.py 源码文件中就有三个子类的实现,它们分别是 FifoQueue 先进先出队列、LifoQueue 先进后出队列、PriorityQueue 优先级队列。**我们分别来来看一下它们的实现原理。
FifoQueue先进先出队列:这个类继承了Base类,并重写了__len__、push、pop这三个方法,它们都是对server对象的操作,而server对象就是一个 Redis 连接对象,我们可以直接调用其操作 Redis 的方法对数据库进行操作。可以看到这里的操作方法有llen、lpush、rpop等,这就代表此爬取队列使用了 Redis 的列表。序列化后的 Request 会被存入列表,就成为了列表的其中一个元素;__len__方法中调用了llen操作,获取列表的长度;push方法中调用了lpush操作,这代表从列表左侧存入数据;pop方法中调用了rpop操作,这代表从列表右侧取出数据。Request 在列表中的存取顺序是左侧进、右侧出,这是有序的进出,即先进先出(first input firstput-FIFO),此类的名称就叫作 FifoQueue。
python
class FifoQueue(Base):
"""Per-spider FIFO queue"""
def __len__(self):
"""Return the length of the queue"""
return self.server.llen(self.key)
def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request))
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.brpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.rpop(self.key)
if data:
return self._decode_request(data)LifoQueue先进后出队列:与FifoQueue不同的是,它的pop方法在这里使用的是lpop操作,也就是从左侧出,而push方法依然是使用的lpush操作,是从左侧入。那么这样达到的效果就是先进后出、后进先出(last in firstout-LIFO),此类名称就叫作 LifoQueue。同时这个存取方式类似栈的操作,所以其实也可以称作 Stackqueue。
python
class LifoQueue(Base):
"""Per-spider LIFO queue."""
def __len__(self):
"""Return the length of the stack"""
return self.server.llen(self.key)
def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request))
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.blpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.lpop(self.key)
if data:
return self._decode_request(data)PriorityQueue优先级队列:在前面,我们构造 Request 请求对象时,提到一个prority请求优先级参数,这个参数就是在优先级队列起作用的,赋值的优先级越高,那么该 Request 就越先被请求。在这里我们可以看到__len__、push、pop方法中使用了server对象的zcard、zadd、zrange操作,可以知道这里使用的存储结果是有序集合,这也是爬取队列默认使用的队列。在有序集合中,每个元素都可以设置一个分数,这个分数就代表优先级。__len__方法调用了zcard操作,返回的就是有序集合的大小,也就是爬取队列的长度。push方法调用了zadd操作,就是向集合中添加元素,这里的分数指定成 Request 优先级的相反数,因为分数低的会排在集合的前面,所以这里高优先级的 Request 就会存在集合的最前面。pop方法首先调用了zrange操作取出了集合的第一个元素,因为最高优先级的 Request 会存在集合最前面,所以第一个元素就是最高优先级的 Request,然后再调用zremrangebyrank操作将这个元素删除,这样就完成了取出并删除的操作。
python
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
data = self._encode_request(request)
score = -request.priority
self.server.execute_command('ZADD', self.key, score, data)
def pop(self, timeout=0):
"""Pop a request"""
pipe = self.server.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])另外,在源文件的末尾,将上面三种队列分别赋值给了不同的变量,如果爬虫要使用其中的一种队列,可以在 settings.py 全局配置文件中或者在 custom_settings 爬虫配置添加如下配置:
python
# 配置调度队列(可选配置,若不配置,默认使用PriorityQueue)
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"过滤去重
前面说过,Scrapy 去重是利用集合来实现的,而 Scrapy 分布式中的去重需要利用共享的集合,这里使用的是 Redis 中的集合数据结构。我们来看一看去重类是怎样实现的。源码文件是 dupefilter.py,其内实现了一个 RFPDupeFilter 类,代码如下所示:这里同样实现了一个 request_seen 方法,与 Scrapy 中的 request_seen 方法实现极其类似,不过这里集合使用的是 server 对象的 sadd 操作,也就是集合不再是一个简单数据结构了,而是直接换成了数据库的存储方式。鉴別重复的方式还是使用指纹,指纹同样是依靠 request_fingerprint 方法来获取的。获取指纹之后直接向集合添加指纹,如果添加成功,说明这个指纹原本不存在于集合中,返回值为 1。代码最后的返回结果是判定添加结果是否为 0,如果刚才的返回值为 1,那么这个判定结果就是 False,也就是不重复,否则判定为重复这样我们就成功利用 Redis 的集合完成了指纹的记录和重复的验证。
python
class RFPDupeFilter(BaseDupeFilter):
"""Redis-based request duplicates filter."""
logger = logger
def __init__(self, server, key, debug=False):
"""Initialize the duplicates filter."""
self.server = server
self.key = key
self.debug = debug
self.logdupes = True
@classmethod
def from_settings(cls, settings):
"""Returns an instance from given settings."""
server = get_redis_from_settings(settings)
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
"""Returns instance from crawler."""
return cls.from_settings(crawler.settings)
def request_seen(self, request):
"""Returns True if request was already seen."""
fp = self.request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request."""
return request_fingerprint(request)
@classmethod
def from_spider(cls, spider):
settings = spider.settings
server = get_redis_from_settings(settings)
dupefilter_key = settings.get("SCHEDULER_DUPEFILTER_KEY", defaults.SCHEDULER_DUPEFILTER_KEY)
key = dupefilter_key % {'spider': spider.name}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
def close(self, reason=''):
"""Delete data on close. Called by Scrapy's scheduler."""
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
def log(self, request, spider):
"""Logs given request."""
if self.debug:
msg = "Filtered duplicate request: %(request)s"
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False调度器
Scrapy-Redis 还帮我们实现了配合 Queue、DupeFilter 使用的调度器 Scheduler,源文件名称是 scheduler.py。接下来我们看两个核心的存取方法,代码如下所示:enqueue_request 可以向队列中添加 Request,核心操作就是调用 Queue 的 push 操作,还有一些统计和日志操作。next_request 就是从队列中取 Request,核心操作就是调用 Queue 的 pop 操作,此时如果队列中还有 Request,则 Request 会直接取出来,爬取继续;如果队列为空,则爬取会重新开始。
python
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
def next_request(self):
block_pop_timeout = self.idle_before_close
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request实用配置
学习 Scrapy-Redis 的源码后,我们还需要在 settings.py 文件中进行一些配置才能实现分布式爬虫。常用的具体配置如下:
- 配置调度器,将调度器的类替换为 Scrapy-Redis 提供的类;
python
SCHEDULER = "scrapy_redis.scheduler.Scheduler"- 配置持久化,**Scrapy-Redis 默认会在爬取全部完成后清空爬取队列和去重指纹集合。**如果不想自动清空爬取队列和去重指纹集合,可以增加如下配置(可选配置,默认
False,即自动清空);
python
SCHEDULER_PERSIST = True- 如果配置了持久化或者强制中断爬虫,那么爬取队列和指纹集合不会被清空,爬虫重新启动之后就会接着上次爬取。如果想重新爬取,我们可以配置重爬的选项,将
SCHEDULER_FLUSH_ON_START设置为True之后,爬虫每次启动时,爬取队列和指纹集合都会清空。所以要做分布式爬取,我们必须保证只能清空一次,否则每个爬虫任务在启动时都清空一次,就会把之前的爬取队列清空,势必会影响分布式爬取。注意,此配置在单机爬取的时候比较方便,分布式爬取不常用此配置(配置重爬,此配置是可选的,默认是False);
python
SCHEDULER_FLUSH_ON_START = True- 配置调度队列(可选配置,若不配置,默认使用
PriorityQueue);
python
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"- 将去重的类替换为 Scrapy-Redis 提供的类;
python
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"