消息队列MQ
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
消息队列(Message Queue,简称 MQ)是一种应用间的通信方式。我们可以将消息队列视为一个消息的列表,发送和接收的消息都存储在这个列表中,这样独立的应用程序可以通过读写出入列表中的消息(针对应用的数据)进行通信。消息队列不仅可以提供消息的高效传递,还能在高并发环境下缓解系统压力,提高系统的吞吐量和响应速度,实现请求的异步处理,而不用担心请求发生堵塞。一句话总结:消息队列可以提供高效的消息传递机制和异步处理能力。
前言介绍
消息队列的本质还是队列,在大多数情况下我们聊到队列的时候,指的是先进先出(First in-First out,FIFO),最先放进去的数据,被最先拿出来。当然我们也偶尔会用到它广义的意思,一个可以逐个往里放数据,然后按照一定的顺序输出的数据结构。所以,一个最基础的队列只需要支持两个功能“放”和“拿”。
生活场景
有人会问,队列这个数据结构有什么用呢?最常见的用法是用来有序地安排任务。我们可以想象在生活中的队列,比如说火车站的售票大厅,如果没有队列的存在,来一个人就直接冲到售票窗口去买票,那可能会造成很多问题:
- 售票窗口可能会拥堵,一堆人吵着要买票,导致售票本身的效率下降。
- 身材弱小的人可能一辈子也买不到票,因为是谁最强壮,谁嗓门最大,谁就先买票。
于是就发明了队列,大家按照来的先后顺序排成一队,然后一个一个的去售票窗口买票,如果发现队列太长了,我们可以多开几个售票窗口,如果队列里没有人了,我们可以少开几个售票窗口,同时避免了有人可能来的很早,但是始终买不着票的情况发生。
建议
在编程的时候,队列的有序性,经常是保证我们算法正确的基础。
生产消费
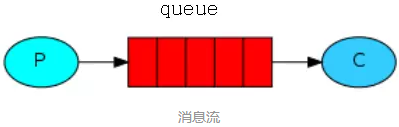
在这个世界上有任务的生产者,还有任务的完成者,比如在学校化学、物理、数学老师布置作业,它们就是任务的生产者,而学生们就是任务的完成者。在实际的生活中,生产者和完成者的比例可能是各种各样的,有可能是 100 : 1,也可能是 1 : 100。这个时候队列就起到了它的效果,因为生产者不需要关心把任务交给谁去解决,只需要把任务放到队列里就可以了。同样完成者也不需要关心要处理谁的任务,只需从队列里拿任务就可以了。对应到编程中,就是一种经典的并发编程模型叫“生产者消费者模型”,用于解决生产者和消费者之间的数据交换和协作问题。该模型主要由三部分组成:
- 生产者(Producer):负责任务的生产和发布。
- 队列(Queue):负责任务的存储和共享。
- 消费者(Consumer):负责任务的监听和处理。
在该模型中,单个或多个生产者负责生成任务并放入共享队列中,而单个或多个消费者则负责从共享队列中取出任务进行处理。
实现消息队列
这里介绍常见的消息队列实现方式:Queue 模块、Redis 数据库、RabbitMQ 框架。
Queue模块
Python 内置的 queue 模块是一个用于多线程的队列模块,它可以指定缓冲区大小的阻塞队列,但数据无法在多个进程之间共享。
参数和方法
首先回顾一下前面我们学习使用 queue 模块里面的一些参数和方法:
python
import queue
# 创建一个线程队列,Queue先进先出模式,maxsize设置队列最大长度(默认0,表示长度没有限制)。
q = queue.Queue(maxsize=4)
# 通过put方法向队列q中插入变量i,每次只能插一个数据
for i in range(3):
q.put(i)
# full判断队列是否饱和,empty判断队列是否为空,qsiz获取队列的长度
print(q.full(), q.empty(), q.qsize()) # 输出:False False 3
# 通过get方法从队列q中获取数据,每次只能取一个数据
for _ in range(q.qsize()):
print(q.get(), end=', ')
'''
输出:0, 1, 2
注释:当插入的数据达到队列长度上限后,继续插入就会发生阻塞,如果饱和后进行消费,所以不会发生阻塞,可以执行下面的print语句。
'''建议
在 q.get()、q.put() 方法中有 block、timeout 两个参数。其中 block 默认为 True,写入是阻塞式的,阻塞时间由 timeout 确定。当 block 为 False 时,写入是非阻塞式的,当队列满时会抛出 exception Queue.Full 的异常。
多线程消费
看下面的多线程消费代码案例:可以看到,消费处理的结果并不是按顺序打出来的,这是因为队列只能保证任务被开始执行的顺序,并不能保证任务被完成的顺序。
python
import queue
import threading
# 消费者
def consumer(q):
while True:
item = q.get()
print('Consume:', item)
# 生产者
def producer(q):
for i in range(10):
q.put(i)
# 建立队列
q = queue.Queue()
# 建立消费者线程
t1 = threading.Thread(target=consumer, args=(q,))
t2 = threading.Thread(target=consumer, args=(q,))
# 启动消费者
t1.start()
t2.start()
# 启动生产者
producer(q)
'''
输出:
Consume:0
Consume:2
Consume:3
Consume:1
Consume:4
Consume:5
Consume:7
Consume:8
Consume:9
Consume:6
'''建议
在实际应用中,不同的任务需要的完成时间可能是不一样的,例如有 10 个任务,给消费者 A、B 各分配 5 个任务,就有可能导致任务不均衡,因为消费者 A 的任务可能很简单,而消费者 B 的任务可能很复杂,这就会导致消费者 A 可能很快完成任务,而消费者 B 则需要花很长的时间来完成任务。而队列这种完成一个再拿下一个的任务分配方式,可以保证所有消费者都有任务可做,不至于一个闲得慌,另一个忙得慌,可以说是一种负载均衡。
阻塞与安全
有细心的小伙伴会发现,执行上面的代码,程序不会停下来,即使队列里面的任务都被取完了,也不会停。这是因为 consumer 中的 q.get() 是一个阻塞操作,当队列里面没有任务的时候,程序就会停在这里,直到队列里面有任务,才会继续运行。但现实是 producer 已经运行结束了,队列里面不会再有任务产生了,难道程序要一直卡在这里吗?这时有小伙伴会说,先判断一下队列是否为空,再从里面获取任务,于是 consumer 代码变为这样:
python
# 消费者
def consumer(q):
while True:
if not q.empty():
item = q.get()
print('Consume:', item)
else:
break我们注意上面第 4、5 行代码,在单线程的时候,这两行代码没有任何问题。但是在多线程里面,当一个线程在进行完第 4 行的判断后,CPU 可能会把操作移交给另外一个线程,而另外一个线程恰好也完成了第 4 行的判断,这就有可能导致在队列里面只有一个任务的情况下,两个线程都开始执行 q.get() 获取任务操作,这就必然会导致一个线程能拿到任务,而另一个线程发现没有任务就一直阻塞。又由于在默认情况下,Python 进程会等所有的线程结束后再退出,所以程序还是会一直卡在这里。这时又有小伙伴会说,在创建线程时加一个 daemon=True 将其设置为守护线程(所谓“守护线程”就是在主线程结束的时候,不值得再保留的执行线程。简单的说,守护线程会跟随主线程一起挂掉,而主线程的生命周期就是一个进程的生命周期),代码就变为这样:
python
# 建立消费者线程
t1 = threading.Thread(target=consumer, args=(q,), daemon=True)
t2 = threading.Thread(target=consumer, args=(q,), daemon=True)我们运行程序会发现什么都没有输出,这是因为 producer 运行完成之后主线程就结束了,顺带还把两个什么都没来得及做的 consumer 子线程给干掉了,所以什么输出都没有。这时又有小伙伴会说,在最后面加一个判断进行延时阻塞,最后添加如下代码:
python
# 延时阻塞
while not q.empty():
time.sleep(1)运行上面添加后的代码,确实能达到我们想要的效果,但是这里有两个问题:
到底
sleep时间多久合适?上面sleep时间是我们自己设定的 1 秒,这个时间不一定是最合适的,如果sleep时间过短,程序就一直在这里吭呲吭呲循环,也就是说你一直在浪费 CPU。队列为空就代表任务完成了吗?在
consumer拿完最后一个任务的时候,队列里面就空了,程序就会判断结束,但这个时候consumer可能还没有做完这个任务。所以,队列为空只代表所有的任务都被认领了,不代表所有的任务都被完成了。
内部计数器
针对以上问题,queue 模块提供了一个内部计数器。剖析源码如下:
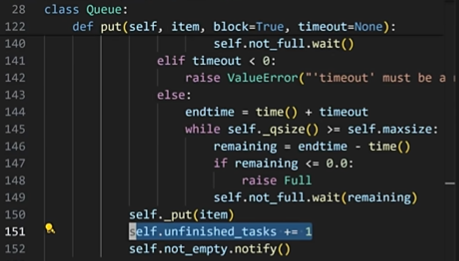
- 在
put()函数中,每一次往队列里面放一个任务,queue的内部计数器里面就会加个一。
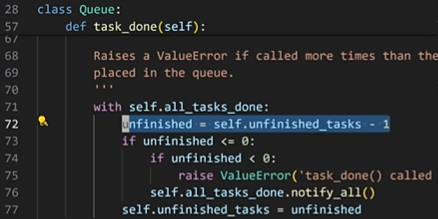
- 在
task_done()函数中,每次调用,queue的内部计数器里面就会减个一。
这样 consumer 在每一次完成任务之后,只要调用一下 task_done() 函数,就可以告诉队列有多少任务已经完成了。在最下面我们加一个 q.join() 队列阻塞,该操作会一直阻塞,直到队列里面的 put 和 task_done 一样多。最后代码如下:
python
import queue
import threading
import time
# 消费者
def consumer(q):
while True:
item = q.get()
print('Consume:', item)
q.task_done()
# 生产者
def producer(q):
for i in range(10):
q.put(i)
# 建立队列
q = queue.Queue()
# 建立消费者线程
t1 = threading.Thread(target=consumer, args=(q,), daemon=True)
t2 = threading.Thread(target=consumer, args=(q,), daemon=True)
# 启动消费者
t1.start()
t2.start()
# 启动生产者
producer(q)
# 队列阻塞
q.join()警告
提醒一下,前面讲过 queue 模块是一个用于多线程的队列模块,也就说该模块只能在同一个进程下进行数据交互,如果是两个独立的进程是无法通过该模块交互的。
Redis数据库
Redis 是一个简单高效的内存数据库,具有丰富的数据类型,常用于缓存数据,也支持队列,所以我们可以将其作为消息队列,其优点如下:
- 极低延迟:得益于内存高速读写,消息可以极低延迟传递。
- 上手容易:只需组合使用两三个命令,即可完成消息传递。
- 单线程锁:Redis 本身是一个单线程的,相当于所有操作都有一把天然的排他锁,因此我们不用担心在并发下同一条消息会传递给多个使用者。
可靠消息队列
前面讲过,消息队列是完成一个再拿下一个的任务分配方式,假如说在传递 A 任务的过程中,网络出现了问题,导致 A 任务没有被正常传递,想再次传递 A 任务就没有办法了。因此我们需要建立一个可靠消息队列,他的主要特点在于提供了额外的功能和保障,以确保消息传递的可靠性和稳定性。它和普通的消息队列的区别如下:
- 消息持久化:可靠消息队列会将消息持久化存储到磁盘中,以防止消息丢失。而普通的消息队列可能不会对消息进行持久化存储,一旦系统出现故障或者重启,未被处理的消息可能会丢失。
- 消息确认机制:可靠消息队列会等待消息的接收方对消息进行确认,只有在接收方成功接收并处理了消息后,才会向发送方发送确认消息。而普通的消息队列可能不会提供消息确认机制,消息发送后就认为发送成功。
- 消息重试机制:可靠消息队列会自动进行消息重试,如果消息发送失败或者接收方未能及时确认消息,会进行多次重试,直到消息成功发送并被确认。普通的消息队列可能不会提供消息重试机制。
总的来说,普通的消息队列适用于简单的、对消息的可靠性要求不高的应用场景,而可靠消息队列在功能和保障上更加强大和可靠,适用于对消息传递的可靠性有较高要求的应用场景。
启动配置服务
通过 Redis 实现来可靠消息队列,首先要确保本机已经安装了 Redis 数据库,接着按以下步骤修改 Redis 的 redis.windows.conf 配置文件:
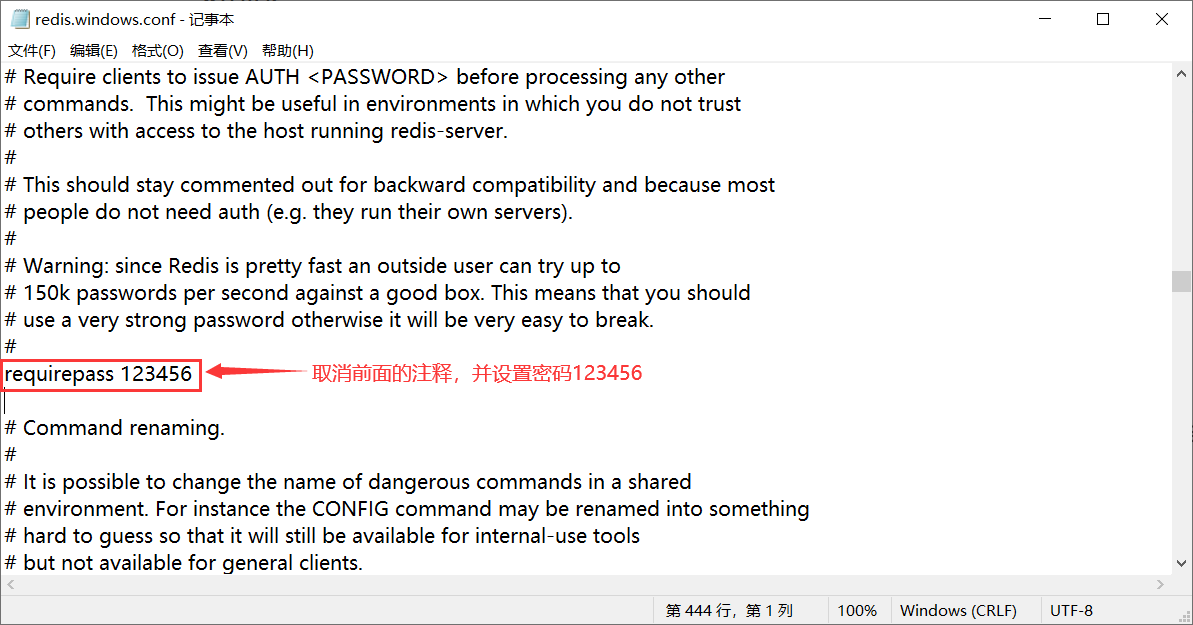
- 注释绑定,在
bind 127.0.0.1前面加上一个#注释该行,或者修改为bind 0.0.0.0让其监听所有网络接口的地址。

- 设置密码,取消
requirepass前面的#注释,在后面加上自己的密码 。
- 配置启动,在命令行通过配置文件来启动 Redis 服务使配置生效。
redis-server "Redis安装路径\redis.windows.conf"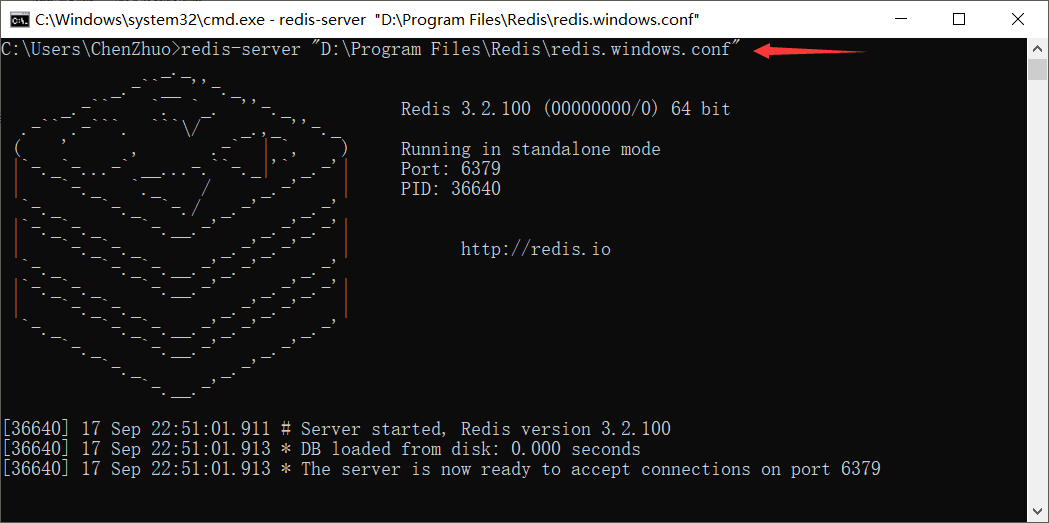
重要
只有进行了上面三个步骤的操作,局域网内的其他机器才能连接到指定 IP 的 Redis 数据库,并且需要提供正确的密码进行连接。
任务处理流程
在 Redis 中使用两个列表就可以实现可靠消息队列,一个列表存储待处理(pending)的任务,另一个列表存储处理中(processing)的任务。通过这种方式,可以确保消息在处理过程中的可靠传递,即使出现故障也可以保证消息不会丢失。流程及实现代码如下:
- 导入连接:导入
redis模块连接局域网内指定 IP 的 Redis 数据库。
python
# 导入Redis模块
from redis import StrictRedis
# 连接局域网内IP为192.168.0.3上密码为123456的Redis的0号数据库
client = StrictRedis(host='192.168.0.3', port=6379, db='0', password='123456')- 添加任务:生产者通过
lpush方法将所有需要处理的任务添加至待处理列表(pending)里面;
python
# 循环添加任务
for message in ['任务1', '任务2', '任务3']:
# 通过lpush命令将任务添加到pending待处理列表左侧
print(client.lpush("pending", message))- 获取任务:通过
rpoplpush方法弹出待处理列表(pending)最右边的任务进行处理,并且将该任务添加到处理中列表(processing)最左边。
python
# 弹出pending待处理列表最右边的任务,并且将任务添加到处理中的processing任务列表中
message = client.rpoplpush('pending', 'processing')- 删除任务:消费者处理完任务后,通过
lrem方法将任务从处理中任务列表(processing)删除。
python
# 删除处理中任务列表processing中从左至右与message内容相同的第一条任务
client.lrem('processing', 1, message)- 回填任务:消费者如果在消费任务的过程中出现错误,在删除任务的基础上进行任务的回填。
python
# 将任务回填至pending待处理列表当中
client.lpush("pending", message)下面是用 Python 操作 Redis 实现简单可靠消息队列的示例代码:在这个示例中我们增加了一个键值对结构存储每个任务的重试次数。
python
import random
import redis
import time
class ReliableMessageQueue:
def __init__(self, host, port, db, password):
# 待处理队列名称
self.pending_queue = 'pending_queue'
# 正在处理队列名称
self.processing_queue = 'processing_queue'
# 重试次数键名
self.retry_count_key = 'retry_count'
# 最大重试次数
self.max_retries = 3
# redis连接对象
self.connect = redis.StrictRedis(host=host, port=port, db=db, password=password)
def enqueue(self, message):
# 将消息添加到待处理队列
self.connect.lpush(self.pending_queue, message)
def dequeue(self):
# 从待处理队列中取出消息,并将其移动到正在处理队列
message = self.connect.rpoplpush(self.pending_queue, self.processing_queue)
return message
def complete(self, message):
# 将消息从正在处理队列移除
self.connect.lrem(self.processing_queue, 1, message)
def process(self, message):
try:
# 这里假设处理成功的条件是随机数大于0.5
if random.random() > 0.5:
# 模拟处理消息的过程,这里可以是你的具体业务逻辑
print("Processing message:", message)
# 如果处理成功,则将消息从正在处理队列中移除
self.complete(message)
else:
raise Exception("Processing failed: ")
except Exception as e:
print(e, message)
self.retry(message)
def retry(self, message):
# 建立键值对结构存储每个任务的重试次数
retries = self.connect.hincrby(self.retry_count_key, message, 1)
if retries > self.max_retries:
# 重试次数超过最大重试次数,放弃重试,将消息从正在处理队列中移除
self.connect.lrem(self.processing_queue, 1, message)
print("Max retries exceeded. Message discarded: ", message)
else:
# 未达到最大重试次数,则将消息重新放回待处理队列
self.enqueue(message)
# 处理失败的消息也需要从正在处理队列中移除,否则会添加两次
self.complete(message)
if __name__ == "__main__":
# 创建可靠消息队列对象
queue = ReliableMessageQueue(host='192.168.0.3', port=6379, db=0, password='123456')
# 生产者将消息添加到待处理队列
for message in ['Message_1', 'Message_2', 'Message_3', 'Message_4', 'Message_5']:
queue.enqueue(message)
# 循环处理任务
while True:
# 消费者从待处理队列取出消息,并将其移动到正在处理队列
message = queue.dequeue()
# 如果待处理队列为空,则等待一段时间后继续
if not message:
print("No messages available. Waiting...")
time.sleep(30)
continue
# 将字节任务编码后进行处理
queue.process(message.decode())RabbitMQ框架
RabbitMQ 是由 Erlang 语言开发基于 AMQP 协议(高级消息队列协议)实现的队列框架。相比较基于的 Redis 队列,在性能方面要更好,支持的功能会更多,消息的可靠性更强,且支持 Python、Java、JavaScript、PHP、Ruby、Go 等多种语言。
下载安装
在安装 RabbitMQ 之前,我们先看看RabbitMQ官网声明的依赖项:
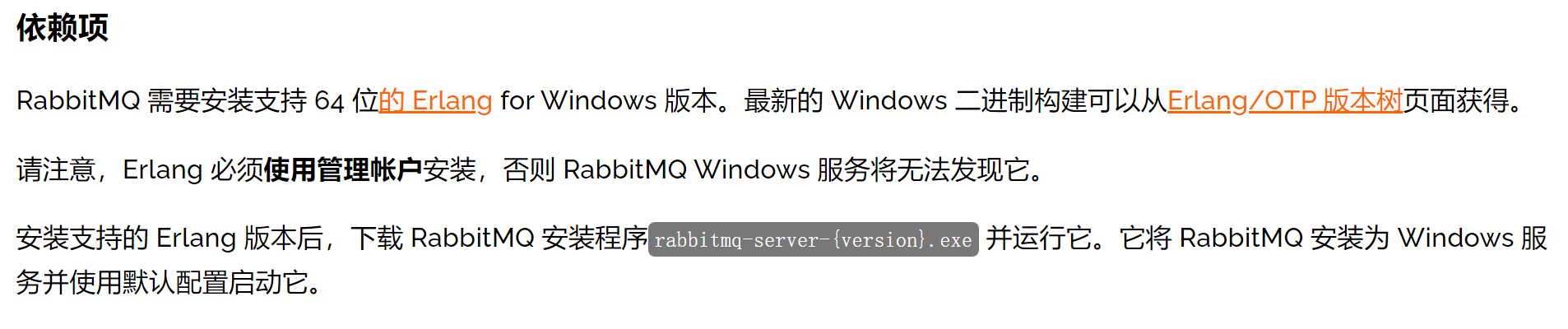
因为 RabbitMQ 使用 Erlang 语言开发,所以首先我们需要安装一个 Erlang 的语言环境,下载好了我们进行安装,注意要按照官网说明的“以管理员身份运行”安装:

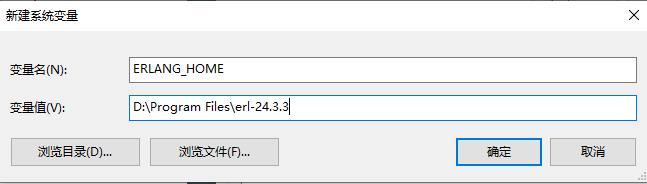
安装好后,我们将 Erlang 的安装路径添加到系统变量当中:
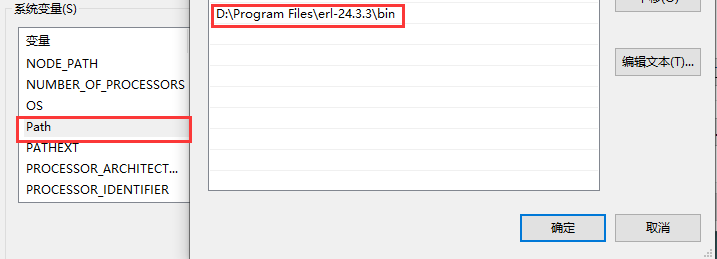
接着修改 Path 变量的值,添加 Erlang 安装路径下的 bin 路径:
保存修改,我们打开命令行,执行 erl 命令,出现下图说明安装成功:

接下来我们“以管理员身份运行”安装 RabbitMQ 框架:

安装好后,我们将 RabbitMQ 安装路径添加到系统变量当中:
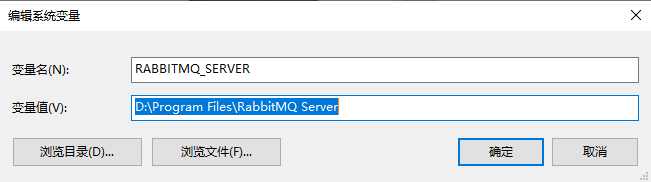
接着修改 Path 变量的值,添加 RabbitMQ 安装路径下的 sbin 路径:
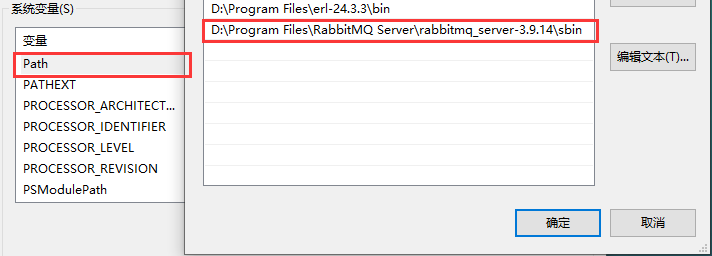
保存后,在重启命令行加载新的信息,执行 rabbitmq-plugins.bat enable rabbitmq_management 命令安装插件,出现下面信息说明安装成功:
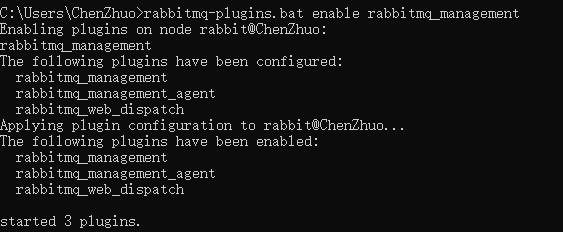
现在我们去访问本机的 15672 端口地址,出现如下登录页面,初始的用户名和密码都为 guest,点击Login登录:
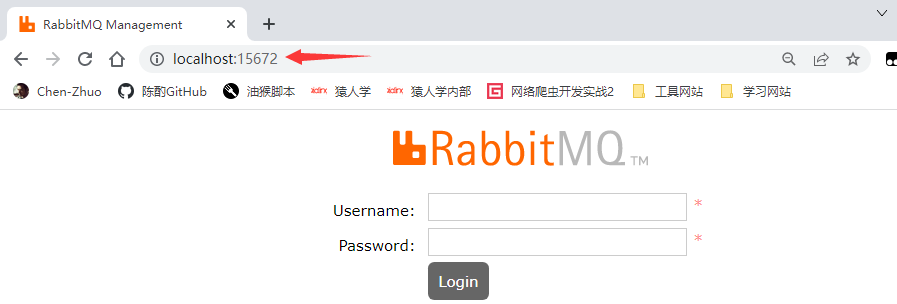
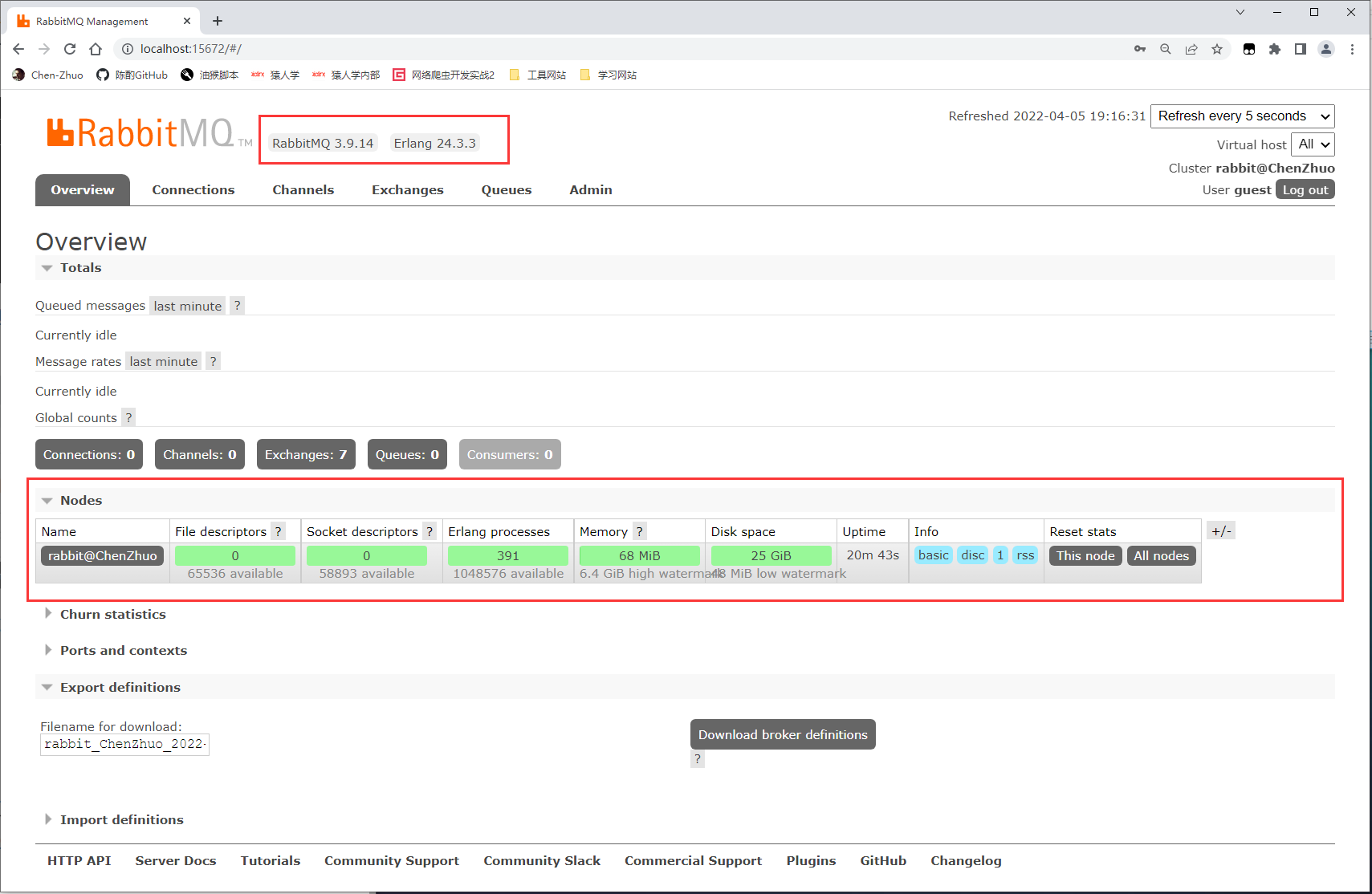
进到如下页面,该页面展示了一些基本的信息,例如 RabbitMQ 版本、Erlang 版本、Nodes 节点状态等。
简单操作
现在我们回看官网提到通过 Python 操作 RabbitMQ 有下面几种模块选择:

安装第三方库,我们安装最简单的 pika 第三方库:
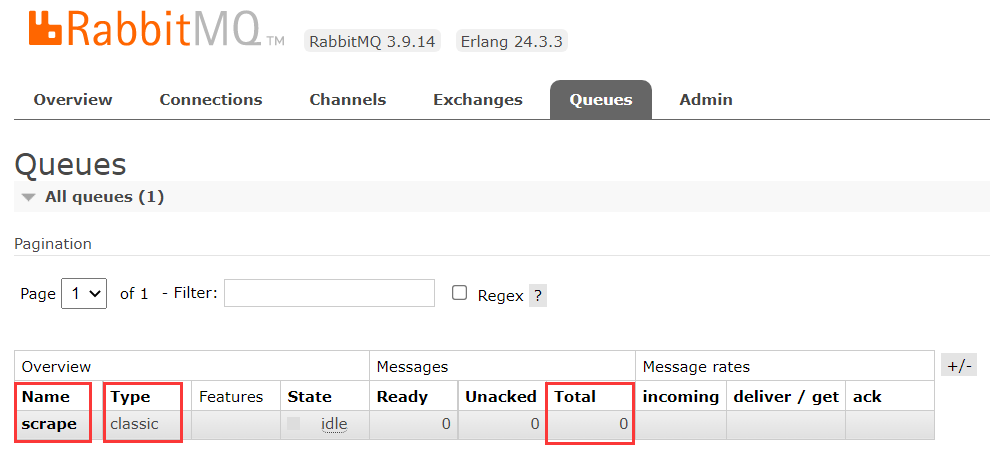
pip install pika定义一个消息队列,执行后就会生成一个名称为 scrape 的队列,回到管理页面上,就会看到 Queues 的值变为了 1,下面还展示了队列的名称、类型、长度等各种属性:
python
import pika
# 连接本地的RabbitMQ服务
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
# 声明一个频道,即channel
channel = connect.channel()
# 声明一个名称为scrape的队列
channel.queue_declare(queue='scrape')
# 确认完成后,可以将连接关闭
connect.close()
点进去,就就可以看到该消息队列的详细信息,例如名称、类型、消息数量等:
定义一个生产者,执行后将消息 b'Hello world!' 放入队列中,在管理页面上也能看到,消息的总数量也变成了 1,且有 1 个消息准备好被使用了,消息使用速率是每秒 0 个:
python
import pika
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connect.channel()
# exchange先赋值一个空字符串(后面讲),routing_key队列名称,body放入的消息体(byte类型数据)
channel.basic_publish(exchange='', routing_key='scrape', body='Hello world!'.encode())
connect.close()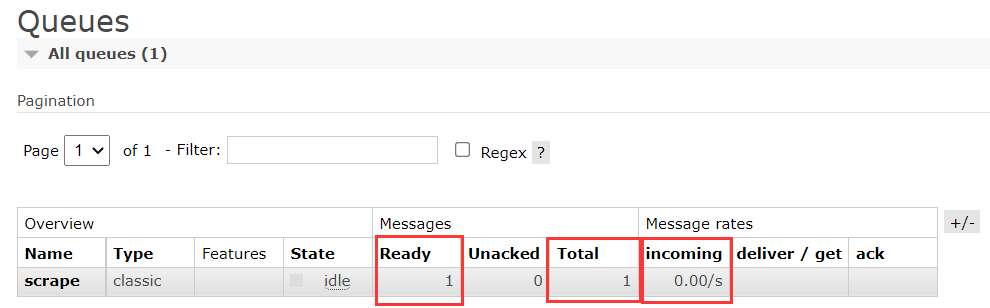
定义一个消费者,启动后会监听 scrape 队列的变动,如果有消息进入,就获取并消费,回调 callback 方法,打印输出结果,回看管理页面,队列状态由 running 变为 idle,而且 Ready 和 Total 的数量也变为了 0 个:
python
import pika
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connect.channel()
def callback(ch, method, properties, body):
print(f'Get {body}') # Get b'Hello world!'
# queue='scrape'消息来源scrape队列;
# auto_ack=True获取消息后,通知消息队列移除该消息;
# on_message_callback=callback消息来临时,执行回调函数callback。
channel.basic_consume(queue='scrape', auto_ack=True, on_message_callback=callback)
channel.start_consuming()
警告
消息队列要先于生产者和消费者存在。
消息确认
在消费者处理任务的时候,我们需要考虑一个情况,就是如果消费者进程挂掉了,那么消费者已经接收但未被处理的消息和正在处理的消息就丢失了。为了保证任务不丢失,我们需要消费者在完成任务后告诉 RabbitMQ 这个任务已经干完了,让 RabbitMQ 把这个任务给释放掉。而当出现消费者宕机、掉线等情况时,RabbitMQ 会重新把这个任务发送给其他的消费者。刚好在上面我们就使用了 auto_ack 参数来控制消息确认的行为:
auto_ack=False(默认)代表着消费者需要在处理完消息后需要向 RabbitMQ 发送一个确认信号,RabbitMQ 才会将消息从队列里面移除。如果消费者在处理消息时崩溃或发生其他错误,而没有发送确认信号,那么 RabbitMQ 会重新将这条消息发送到其他消费者,或者将其保留在队列中等待后续处理。auto_ack=True代表消费者不会发送确认信号给 RabbitMQ。这意味着一旦消息被发送到消费者,RabbitMQ 就会立即将其从队列中移除,即使消费者还没有处理完这条消息。这种情况下,如果消费者在处理消息时崩溃或发生其他错误,那么这条消息就会丢失。
因此,我们这里就只需要改变消费者的代码。下面就实现了消息确认机制,一旦某个消费者宕机了,RabbitMQ 就会直接把任务派给下一个消费者。
python
import pika
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connect.channel()
def callback(ch, method, body):
print(f'Get {body}') # Get b'Hello world!'
# 因为下面没有设置auto_ack,默认为False,所以这里必须要通知RabbitMQ这个消息已经处理完,可以从队列里删了
ch.basic_ack(delivery_tag=method.delivery_tag)
# 和上面相比,这里就没有设置auto_ack参数。
channel.basic_consume(queue='scrape', on_message_callback=callback)
channel.start_consuming()建议
如果你希望确保每条消息都能被正确处理,那么应该使用 no_ack=False(或不设置该参数,使用默认值)。如果你对消息的丢失不敏感,或者你的应用能够容忍一定程度的消息丢失,那么可以使用 no_ack=True 来简化代码和提高性能。
持久化
RabbitMQ 还提供了队列持久化存储,如果不设置持久化存储,那么 RabbitMQ 重启后队列就没有了。实现队列持久化也很简单,只需要在声明队列时,添加一个 durable 参数等于 True 即可。我们删除以前的重名队列,重新声明持久队列,代码如下:
python
import pika
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connect.channel()
# durable=True声明持久队列
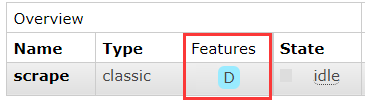
channel.queue_declare(queue='scrape', durable=True)声明后,可以看到队列的 Features 特征属性变成了 D 标识,表示该队列是一个持久化的队列:
除了保存队列持久化,我们还必须保存消息持久化,不然服务重启后消息还是会丢失。这时生产者的代码改为如下:
python
for data in ('world', '!', 'Hello'):
channel.basic_publish(
exchange='',
routing_key='scrape',
# 指定BasicProperties对象的delivery_mode为2,即保持消息持久化
properties=pika.BasicProperties(delivery_mode=2),
body=data.encode()
)负载均衡
最后一点,因为有可能每个消费者处理信息的能力不一样,如果按公平分发的化有可能导致负载不平衡,旱的旱死、涝的涝死。为避免这种情况发生,必须限制了消费者待处理信息的个数。消费者代码中加上如下设置:
python
# 限制消费者待处理任务个数为1
channel.basic_qos(prefetch_count=1)提醒
关于更多 RabbitMQ 操作参看Python之RabbitMQ的使用