Scrapy框架【对接】
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
**之前我们都是使用 Scrapy 中的 Request 对象来发起请求,其实这个 Request 发起的请求和 requests 是类似的,均是直接模拟 HTTP 请求。因此,如果一个网站的内容是由 JavaScript 渲染而成的,那么直接利用 Scrapy 的 Request 请求对应的 URL 是无法进行抓取的。**不过前面我们也讲到了,应对 JavaScript 渲染而成的网站可以直接用 Selenium、Splash、Puppeteer 等模拟浏览器进行抓取,在这种情况下,我们不需要关心页面后台发生的请求,也不需要分析渲染过程,只需要关心页面的最终结果即可。所以,如果我们能够在 Scrapy 中实现 Selenium 的对接,就可以实现 JavaScript 渲染页面的爬取了。
实现对接
经过前面的学习,我们已经了解了 Downloader Middleware 的用法,只要实现 process_request、process_response、process_exception 中的任意一个方法即可,同时不同方法的返回值不同,其产生的效果也不同。
使用方案
在 process_request 方法中,当返回为 Response 对象时,优先级更低的 Downloader Middleware 的 process_request 和 process_exception 方法不会被继续调用,转而被依次调用每个 Downloader Middleware 的 process_response 方法。调用完之后,直接将 Response 对象发送给 Spider 来处理。那也就是说,如果我们实现一个 Downloader Middleware,在 process_request 方法中直接返回一个 Response 对象,那么 process_request 所接收的 Request 对象就不会再传给 Downloader 处理了,而是经由 process_response 方法处理后交给 Spider,Spider 直接解析 Response 中的结果。
定制功能
**所以,我们可以自定义一个 Downloader Middleware 并实现 process_request 方法,在 process_request 中,我们可以直接获取 Request 对象的 URL,然后在 process_request 方法中完成使用 Selenium 请求 URL 的过程,获取 JavaScript 渲染后的 HTML 代码,最后把 HTML 代码构造为 HtmlResponse 返回即可。这样 HtmlResponse 就会被传给 Spider,Spider 拿到的结果就是 JavaScript 渲染后的结果了。**具体代码如下:
python
from scrapy.http import HtmlResponse
from selenium import webdriver
import time
class SeleniumMiddleware(object):
# 信号类方法
@classmethod
def from_crawler(cls, crawler):
s = cls()
# 注册spider_opened方法
crawler.signals.connect(s.spider_opened, signals.spider_opened)
# 注册spider_closed方法
crawler.signals.connect(s.spider_closed, signals.spider_closed)
return s
# 爬虫启动的时候,生成一个browser对象
def spider_opened(self, spider):
self.browser = webdriver.Chrome()
# 使用process_request方法,最后返回HtmlResponse对象
def process_request(self, request, spider):
url = request.url
self.browser.get(url)
time.sleep(5)
html = self.browser.page_source
return HtmlResponse(url=url, body=html, request=request, encoding='utf-8', status=200)
# 爬虫结束的时候,关闭browser对象
def spider_closed(self, spider):
browser.close()启用中间件
**中间件写好以后,我们还需要在 settings.py 文件中启用该中间件,这里需要注意的是,现在我们的下载器是 Scrapy 中的 Downloader,启用这个中间件后,我们的下载器就变成了 Selenium,前面讲过 Scrapy 中内置许多默认的下载中间件,这些下载中间件对于 Selenium 是没什么用的,就比如 UserAgentMiddleware 请求头中间件就没用,因为 Selenium 是驱动浏览器采集的。**那么现在要禁用让内置的默认中间件,具体有两种做法:
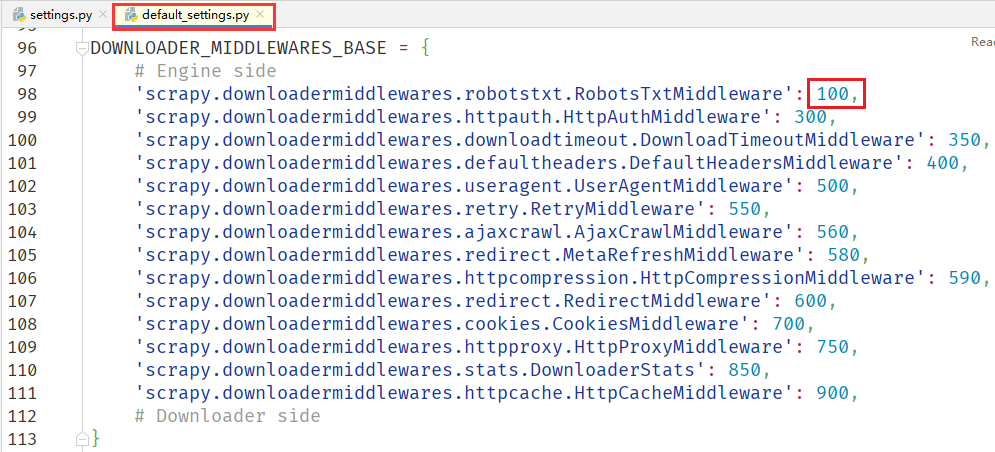
- 列出所有的默认中间件,优先级置为
None,即不启用; - 将我们这个中间件的优先级设置为最高,因为该中间件会直接返回请求,所以后续中间件就不会参与调用了。默认中间件的最高优先级是 100,因此该中间件的优先级我们置为 99 即可。
python
DOWNLOADER_MIDDLEWARES = {
'项目.downloadermiddlewares.SeleniumMiddleware': 99,
}优化对接
细心的读者也许会发现,上面实现的 SeleniumMiddleware 功能太粗糙了,例如:
- Chrome 初始化的时候没有指定任何参数,比如
headless、proxy等,而且没有把参数可配置化。 - 没有实现异常处理,比如出现
TimeException后如何进行重试。 - 加载过程简单指定了固定的等待时间,没有设置等待某一特定节点。
- 没有设置 Cookie、执行 Javascript、截图等一系列扩展功能。
- 整个爬取过程变成了阻塞式爬取,同一时刻只有一个页面能被爬取,爬取效率大大降低。
安装优化包
针对以上流程,我们可以使用一个叫作 GerapySelenium 的优化包,该包的安装命令以及优化细节如下:
pip install gerapy-selenium- Chrome 的初始化参数可配置,可以通过全局
settings配置或 Request 对象配置。 - 实现了异常处理,出现了加载异常会按照 Scrapy 的重试逻辑进行重试。
- 加载过程可以指定特定节点进行等待,节点加载出来之后立即继续向下执行。
- 增加了设置 Cookie、执行 JavaScript、截图、代理设置等一系列功能并将参数可配置化。
- 将爬取过程改为非阻塞式,同一时刻支持多个浏览器同时加载,并可通过
CONCURRENT_REQUESTS控制。 - 增加了 SeleniumRequest,定义 Request 更加方便而且支持多个扩展参数。
- 增加了 Webdriver 反屏蔽功能,将浏览器伪装成正常的浏览器防止被检测。
构造请求
之前我们通过 scrapy.Request 来构造 Request 请求对象:
python
yield Request(url=url, callback=self.回调函数)现在我们需要改为 SeleniumRequest 请求对象,同时还可以增加一些其他的配置,比如通过 wait_for 来等待某一特定节点加载出来,通过 proxy 来设置代理:
python
yield SeleniumRequest(url=url, callback=self.回调函数, wait_for='.item .name', proxy='127.0.0.1:7890')实用配置
另外,我们还可以控制爬取时并发的 Request 数量,这里我们将并发量修改为了 6,这样在爬取的过程中就会同时使用 Chrome 渲染 6 个页面了,如果电脑性能更好的话,可以将这个数字调得更大一些:
python
CONCURRENT_REQUESTS = 6不仅如此,在 GerapySelenium 中提供了很多实用配置,我们可以在 settings.py 文件中配置如下代码:
python
# 关闭Headless模式
GERAPY_SELENIUM_HEADLESS = True
# 忽略HTTPS错误
GERAPY_SELENIUM_IGNORE_HTTP_ERRORS = True
# WebDriver反屏蔽功能,将当前浏览器伪装成正常的浏览器,隐藏WebDriver的一些特征(默认True开启)
GERAPY_SELENIUM_HEADLESS = True
# 设置加载超时时间(默认30秒)
GERAPY_SELENIUM_DOWNLOAD_TIMEOUT = 60启用中间件
最后,我们只需要启用对应的 Downloader Middleware 即可:
python
DOWNLOADER_MIDDLEWARES = {
'gerapy_selenium.downloadermiddlewares.SeleniumMiddleware': 99,
}