文件路径、文件管理操作
更新: 2025/2/24 字数: 0 字 时长: 0 分钟
这一节我们要通过 Python 来操作文件的读写、复制、移动、重命名、删除、压缩等,这些操作也是操作系统中文件管理部分的核心功能,因此这节内容需要熟记。
文件路径
首先我们来了解一下文件的路径,文件路径就是文件在文件系统中所在位置的标识,表示方式有如下两种:
- 绝对路径:指从盘符开始到文件所在位置的路径。
python
# 表示方式一:反斜杠'\'用作转义符,所以如果路径中要使用反斜杠,可以使用双反斜杠'\\'。
'C:\\Users\\Administrator\\Desktop\\image\\cork.jpg'
# 表示方式二:如果路径中必须使用单反斜杠'\',可以加上r阻止转义来表示路径。
r'C:\Users\Administrator\Desktop\image\cork.jpg'
# 表示方式三:直接用斜杠'/'作为路径分割符号的。
'C:/Users/Administrator/Desktop/image/cork.jpg'- 相对路径:指由这个文件所在路径引和其它文件(或文件夹)路径的相对关系。
python
'/' # 表示根目录,在windows系统下表示某个盘的根目录,如“E:\”;
'./' # 表示当前目录
'../' # 表示上级目录。
'./test.txt' # 表示在当前文件在同一目录的test.txt文件
'../test.txt' # 表示在当前文件的上级目录的test.txt文件
# 绝对路径1:D:\Program Files
# 绝对路径2:D:\Program Files\Red\xxx.exe
# exe文件的相对路径:./Red/xxx.exe文件管理操作
现在我们开始学习通过 Python 来管理文件,包括文件的读写、解压缩、移动删除等。
读取写入
通过 Python 读写文件的整个流程主要包含如下三个部分:
- 获取对象:根据路径打开文件,获取到该文件的文件对象。
- 读写操作:选择读或写的操作,来读取或者写入文件内容。
- 关闭对象:读写操作完成之后,必须关闭打开的文件对象。
读写方法
Python 提供了两种读写文件的方法,一种是使用内置的 open 函数,另一种是使用上下文管理器。
- 内置的
open函数是 Python 中专门用于打开文件并获取文件对象的函数。
python
# 获取对象
文件对象 = open(文件路径, 读写模式, 编码方式)
'''
文件路径 ————> 决定打开哪个文件
绝对路径:文件在磁盘中的完整位置,一般放在工程外面的文件使用绝对路径。
C:\酌\Desktop\新建文本文档.txt
相对路径:相对于当前进行操作的文件的位置./或../,一般文件在工程目录下的某个位置使用相对路径(推荐)。
./test1.txt 注释:表示test1文件和操作文件在同一文件夹下
../test1.txt 注释:表示test1文件和操作文件在不同一文件夹下
读写模式 ————> 针对不同的文件进行怎样的操作
文本读写:只针对文本文件。
'r': 读操作(默认,读出来是字符串)
'w': 写操作(清空原有数据,将文本数据写入文件)
'a': 追加操作(保留以前的数据,将新的数据写入文件)
'r+': 可读、可写,文件不存在会报错,写操作时会覆盖
'w+': 可读、可写,文件不存在先创建,会覆盖
'a+': 可读、可写,文件不存在先创建,不会覆盖,追加在末尾
字节读写:可针对所有文件。
'rb'/'br' - 读操作(读出来的是字节数据)
'wb'/'bw' - 写操作(清空原有数据,将字节数据写入文件)
'ab'/'ba' - 追加操作(保留以前的数据,在末尾写入新字节数据)
编码方式 ————> 只针对文本读写设置字符编码
utf-8、gbk、gb2312...
'''
# 读写操作
文件对象.read(n) # 注释:n为读取的字节长度,n为空代表读取全部内容。
文件对象.readline() # 注释:读取文本中的一行的内容,以字符串的形式返回结果,可循环逐行读取整个文件内容。
文件对象.readlines() # 注释:一次性读取文本全部内容,以列表的形式返回结果,每行信息为一个元素。
文件对象.write('内容') # 注释:写入内容的操作。
# 关闭对象
文件对象.close()警告
以写的方式 w 或 wb 打开文件,如果这个文件不存在,就会创建这个文件。以读的方式 r 或 rb 打开文件,如果这个文件不存在,则会报错。
- 上下文管理器是 Python 中用于管理资源的一种机制,它通过
with语句提供了一种简洁的方式来获取和释放资源,结合open函数来打开文件会更快捷。在文件操作结束后,上下文管理器会自动销毁文件对象,避免了忘记手动关闭文件而导致资源泄漏的问题,同时省去了close()关闭文件的操作。
python
with open(文件路径, 读写操作, 编码方式) as 文件对象:
文件读写操作提醒
上下文管理器常用于处理文件、网络连接、数据库连接等需要手动释放资源的情况,确保资源在使用后能够正确地被释放。
读写模式
Python 提供了两种读写文件的模式,一种是文本读写,另一种是字节读写。
- 文本读写:这是一种针对文本文件的读写方式,因为它处理的是字符数据,因此这种读写方式必须要设置与文本文件相对应的字符编码才能正确读写文本,否则打开文本文件可能会出现乱码情况。另外,在写文件的过程中,我们可以随意修改字符内容。
python
# 设置编码格式utf-8,以写的方式'w'打开当前路径下的test1.txt文件。
with open('./test1.txt', 'w', encoding='utf-8') as f:
f.write('12\n34') # 注释:向文件里面写入'12\n34'
# 设置编码格式utf-8,以读的方式'r'打开当前路径下的test1.txt文件。
with open('./test1.txt', 'r', encoding='utf-8') as f:
content1 = f.read() # 注释:读取文本全部内容。
print(content1) # 输出:12\n34
with open('./test1.txt', 'r', encoding='utf-8') as f:
content2 = f.readline() # 注释:读取文本第一行内容。
print(content2) # 输出:12\n
content2 = f.readline() # 注释:读取文本第二行内容。
print(content2) # 输出:34
with open('./test1.txt', 'r', encoding='utf-8') as f:
content3 = f.readlines() # 注释:读取文本全部内容以列表形式返回。
print(content3) # 输出:['12\n', '34']- 字节读写:这是一种针对所有文件都通用的读写方式,因为它处理的是字节数据而不是字符数据,因此这种读写方式不需要设置字符编码,因为返回的内容是字节类型数据。另外,在写文件的过程中,不要改动字节内容,否则可能导致文件出现未知错误。
python
# 以'rb'读字节的方式打开当前路径下的old.jpg图片文件
with open('./old.jpg', 'rb') as f:
image_date = f.read() # 注释:读取old.jpg图片中的字节数据赋值给变量image_date。
# 以'wb'写字节的方式打开当前路径下的new.jpg图片文件
with open('./new.jpg', 'wb') as f:
f.write(image_date) # 注释:将变量image_date中字节数据写入new.jpg图片当中,这样old.jpg和new.jpg两个图片文件的图像就一模一样了。文件指针
有细心的小伙伴会发现,我们每次读取 test1.txt 文件时,都会重复调用 open 函数来打开文件,这么做的原因是因为每次打开文件时,文件指针都默认会在文件的开头位置,因此我们就能从头开始读取文件内容了。如果文件对象调用了 read()、readlines() 方法读取了文件的全部内容后,再调用读文件的方法就会发现没有内容可读取了,原因就是文件指针已经在文件末尾了。所以,上述读文件的方法可以进行如下解释:
文件对象.read()读取文本全部内容,文件指针移动至文件末尾。文件对象.readline()读取一行的内容,文件指针移动至下一行开头。文件对象.readlines()读取所有行的内容,文件指针移动至文件末尾。
假如文件指针已经在文件末尾了,想要从头开始读取文件内容,但又不想重新调用 open 函数来打开文件话,该怎么办呢?好在 Python 的文件对象提供了用于移动文件指针位置的 seek() 方法,具体使用及参数设置如下:
python
文件对象.seek(offset, whence=0)
'''
offset表示偏移量,即要移动的字节数(在文本模式下,Python中的文件对象使用的是Unicode编码,因此负数的offset值会无法正确解释。如果需要精确的字节偏移,最好在字节模式下操作文件)。
whence是可选参数,表示相对位置的起始点。0表示文件开头,可用于字节模式、文本模式(默认值)。1表示当前位置,可用于字节模式。2表示文件末尾,可用于字节模式。
'''
# 举例说明
f.seek(5, 0) # 从文件开头向后移动5个字节(字节模式、文本模式)
f.seek(3, 1) # 从当前位置向后移动3个字节(字节模式)
f.seek(-2, 2) # 从文件末尾向前移动2个字节(字节模式)明白了 seek 方法如何移动文件指针后,我们就可以重写上面文本方式读文件的例子:
python
# 设置编码格式utf-8,以文本读的方式'r'打开当前路径下的test1.txt文件。
with open('./test1.txt', 'r', encoding='utf-8') as f:
content1 = f.read() # 注释:读取文本全部内容。
print(content1) # 输出:12\n34
f.seek(0, 0) # 注释:文件指针置于开头。
content2 = f.readline() # 注释:读取文本第一行内容。
print(content2) # 输出:12\n
content2 = f.readline() # 注释:读取文本第二行内容。
print(content2) # 输出:34
f.seek(0, 0) # 注释:文件指针置于开头。
content3 = f.readlines() # 注释:读取文本全部内容以列表形式返回。
print(content3) # 输出:['12\n', '34']除此之外,Python 的文件对象还提供了 tell() 方法,该方法返回一个整数,表示文件指针的当前位置,即文件中当前读/写位置距离文件开头的字节数。以下是一个简单的例子:在这个例子中每次调用 f.seek() 方法后,文件指针都改变位置,再调用 f.tell() 会显示文件指针的当前位置,因此 tell() 可以用于跟踪文件指针的位置。
python
# 以文本读的方式'r'打开当前路径下的test1.txt文件。
with open('./test1.txt', 'r', encoding='utf-8') as f:
f.seek(1, 0) # 注释:从文件开头向后移动1个字节
print("当前位置:", f.tell()) # 输出:当前位置: 1
f.seek(2, 0) # 注释:从文件开头向后移动2个字节
print("当前位置:", f.tell()) # 输出:当前位置: 2
# 以字节读的方式'r'打开当前路径下的test1.txt文件。
with open('./test1.txt', 'rb') as f:
f.seek(1, 0) # 注释:从文件开头向后移动1个字节
print("当前位置:", f.tell()) # 输出:当前位置: 1
f.seek(2, 0) # 注释:从文件开头向后移动2个字节
print("当前位置:", f.tell()) # 输出:当前位置: 2
f.seek(-1, 1) # 注释:从文件当前向前移动1个字节
print("当前位置:", f.tell()) # 输出:当前位置: 1
f.seek(-1, 2) # 注释:从文件末尾向前移动1个字节
print("当前位置:", f.tell()) # 输出:当前位置: 5大文件读写
在上面读写模式的例子中,我们通过字节读写的方式完成了一个文件的复制,但如果文件的体积过大,一次性将文件的全部内容都读入到内存中可能会造成非常大的内存开销。这种情况选下,我们可以向 read 方法中传入每次读取的字节数,文件指针也会每次往后移动指定读取的字节数,通过循环读取和写入的方式来完成复制文件的操作。代码如下:
python
try:
# 以'rb'读字节的方式打开old.jpg文件,以'wb'写字节的方式打开new.jpg文件
with open('old.jpg', 'rb') as file1, open('new.jpg', 'ab') as file2:
while True:
data = file1.read(512) # 注释:每次读取长度不超过512字节的数据。
if not data: # 注释:判断字节数据为空就退出。
break
file2.write(data) # 注释:将512字节的数据写入新文件。
except FileNotFoundError:
print('指定的文件无法打开')
except IOError:
print('读写文件时出现错误')
print('程序执行结束')
'''
注释:每次执行file1.read(512)都会从上一次读取的末尾再读取长度不超过512字节的数据,直到读取完为止。如果中途使用file1.read()会一次性将未读取的数据全部读取,此时再使用file1.read(512)就会返回空数据,因为文件指针已经到文件末尾了。
'''BOM 的影响
在 Base 的《如何显示字符》部分有讲解记事本保存文件的过程,其中在专业版 Win10 系统中,会有两个 UTF-8 选项,分别是 [UTF-8、带 BOM 的 UTF-8],而企业版 Win10 系统中,就只有一个 UTF-8 选项,就是 [带 BOM 的 UTF-8]。
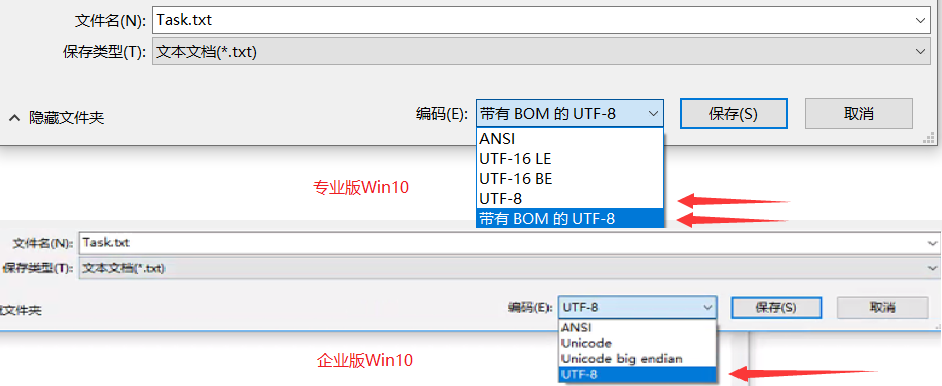
这里我们做一个测试,将“编码”两字存入不同的编码文本,再查看十六进制编码分析得出下表:可以看到,带 BOM 的 UTF-8 比不带 BOM 的 UTF-8 多了一个开头的字节流 EF BB BF。
| 文档编码 | 十六进制编码 | BOM | 解释 |
|---|---|---|---|
| 带有 BOM 的UTF-8 | EF BB BF E7 BC 96 E7 A0 81 | EF BB BF | UTF-8 编码的 BOM 只用来表明编码方式。 |
| UTF-8 | E7 BC 96 E7 A0 81 | 无 | UTF-8 不需要 BOM 来表明字节顺序。 |
接着我们通过下面的代码案例来说明 BOM 在文本读取中的影响,代码案例如下:例子中带 BOM 的 UTF-8 比不带 BOM 的 UTF-8 多了一个 ·,这个 · 在列表中内容为 \ufeff,在编码中内容为 \xef\xbb\xbf,恰好对应了上面表格中带 BOM 的 UTF-8 开头的字节流 EF BB BF。
python
# UTF-8文本文件
with open("Task.txt", "r", encoding='utf-8')as f:
print(f.read()) # 输出:编码
print(len(f.read())) # 输出:2
print(f.readlines()) # 输出:['编码']
print(f.read().encode()) # 输出:b'\xe7\xbc\x96\xe7\xa0\x81'
# 带BOM的UTF-8文本文件
with open("Task.txt", "r", encoding='utf-8')as f:
print(f.read()) # 输出:编码
print(len(f.read())) # 输出:3
print(f.readlines()) # 输出:['\ufeff编码']
print(f.read().encode()) # 输出:b'\xef\xbb\xbf\xe7\xbc\x96\xe7\xa0\x81'通过上面的例子可以看到,带 BOM 的 UTF-8 附带了标识 BOM 的字节内容,而且在输出内容上也比不带 BOM 的 UTF-8 多一位,这可能会影响在某些情况下的处理结果。因此有必要移除 BOM 带来的影响,具体有如下两种方法:
- 打开文本文件,将其另存为不带有 BOM 的 UTF-8(最好是在专业版 Windows 系统中能显示有两个 UTF-8 编码选项下操作)。
- 以
utf-8-sig编码方式读取有 BOM 的 UTF-8 编码的文本文件。
python
# 以utf-8-sig编码方式读取为带BOM的UTF-8的文件
with open("Task.txt", "r",encoding='utf-8-sig')as f:
n_bom = f.read()
print(n_bom, len(n_bom)) # 输出:编码 2压缩解压
这里我们通过 Python 内置的 zipfile 和 tarfile 模块来说明文件的解压缩过程。
ZIP 解压缩
zipfile 模块压缩和解压文件的格式都是 .zip 的压缩包。
python
import zipfile
# 压缩
z = zipfile.ZipFile('dream.zip', 'w')
z.write('test.log') # 注释:将test.log压缩为dream.zip文件
z.close()
# 解压
z = zipfile.ZipFile('dream.zip', 'r')
z.extractall(path='解压路径') # 注释:将dream.zip文件解压出来,文件名以压缩包中的为准。
z.close()RAR 解压缩
tarfile 模块压缩和解压文件的格式都是 .rar 的压缩包。
python
import tarfile
# 压缩
tar = tarfile.open('dream.tar','w')
# 将dream1.zip添加进dream.tar中并取别名bbs2.zip
tar.add('./dream1.zip', arcname='bbs2.zip')
# 将dream2.zip添加进dream.tar中并取别名cmdb.zip
tar.add('./dream2.zip', arcname='cmdb.zip')
tar.close()
# 解压
tar = tarfile.open('dream.tar','r')
# 解压dream.tar,分别解压出两个文件bbs2.zip、cmdb.zip
tar.extractall(path='解压地址') #
tar.close()其他操作
Python 内置的 shutil 模块提供了一系列对文件和文件集合的高级操作,如复制、移动、重命名、删除等。这些操作都是基于更底层的文件操作(如 os 模块提供的操作)构建的,但 shutil 提供了更简洁、更易于使用的接口。
python
import shutil
# copy(文件及路径,目标路径):复制文件(目标文件要是不存在会自动创建)
shutil.copy('路径\文件名.后缀名', '目标路径')
# copy2(文件及路径,目标路径):复制文件,保留原有文件的信息(操作时间和权限等)
shutil.copy2('路径\文件名.后缀名', '目标路径')
# copytree(来源路径,目标路径):拷贝整个文件夹
shutil.copytree('来源路径', '目标路径')
# copyfile直接通过文件名,将1.txt内容以覆盖形式拷贝到2.txt中
shutil.copyfile("1.txt", "2.txt")
# copymode仅拷贝1.txt权限给2.txt,但内容、组、用户均不变
shutil.copymode("1.txt", "2.txt")
# copystat拷贝1.txt状态的信息给2.txt,包括:mode、bits、atime、mtime、flags
shutil.copystat("1.txt", "2.txt")
# 以“r读方式”打开文件1.txt,以“w写方式”打开文件2.txt
with open("1.txt",'r',encoding="utf-8") as f1, open("2.txt","w",encoding="utf-8") as f2:
# copyfileobj通过打开的文件对象,将1.txt内容以覆盖形式拷贝到2.txt中
shutil.copyfileobj(f1, f2)
# 将指定路径下的文件或文件夹递归移动到目标路径下(慎用)
shutil.move('路径\文件夹或文件名.后缀名', '目标路径')
# 递归删除指定路径下的文件或文件夹,不是原子操作(如同rm -rf一样危险,慎用)
shutil.rmtree('路径\文件夹或文件名.后缀名')
# 将/data下的文件打包为data_bak.zip文件放置/tmp/目录
shutil.make_archive(base_name="/tmp/data_bak", format="zip", root_dir="/data")
'''
参数详解:
base_name:保存压缩文件的路径和名称。
format:压缩包算法,“zip”, “tar”, “bztar”,“gztar”。
root_dir:被压缩文件的所在路径(默认当前目录)。
'''
# disk_usage(盘符):查看磁盘使用量(参数如果是路径,那么结果仍然是路径所在盘符的使用量)
print(shutil.disk_usage('C:')) # 输出:usage(total=120031539200, used=78561628160, free=41469911040)